基于深度强化学习的微网P2P能源交易研究:PPO算法与DDPG算法的仿真验证及经济效益评估
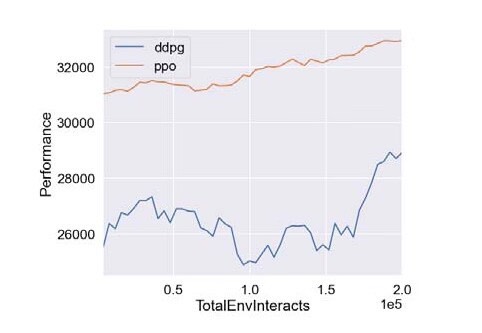
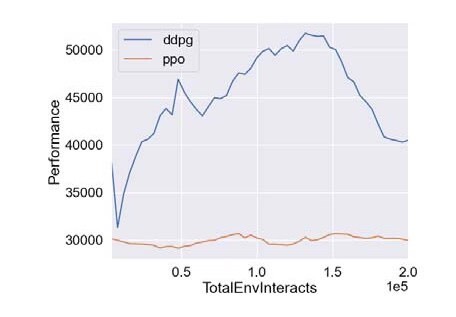
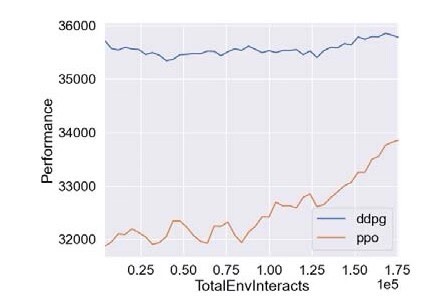
基于深度强化学习的微网P2P能源研究 摘要:代码主要做的是基于深度强化学习的微网P2P能源研究,具体为采用PPO算法以及DDPG算法对P2P能源模型进行仿真验证,代码对应的是三篇文献,内容分别为基于深度强化学习微网控制研究,多种深度强化学习优化效果对比,以及微网实施P2P经济效益评估 复现结果非常良好,结果图展示如下:
摘要
本文深入解析一个基于深度强化学习(Deep Reinforcement Learning, DRL)的微电网(Microgrid)点对点(Peer-to-Peer, P2P)能源交易系统。该系统通过智能体(Agent)在多微网环境中自主决策,优化本地能源供需平衡,并通过与其他微网进行动态能源买卖提升整体经济性与稳定性。项目实现了多种主流DRL算法(包括DDPG、PPO、VPG),并构建了一个贴近现实的微网仿真环境,为研究分布式能源市场机制提供了有力工具。
1. 系统整体架构
该系统采用典型的“智能体-环境”交互范式,其核心由两大部分构成:
- 智能体(Agent):负责学习和执行交易策略。系统集成了三种先进的深度强化学习算法:
- DDPG (Deep Deterministic Policy Gradient):适用于连续动作空间的策略梯度算法,能输出精确的能源交易量和价格。
- PPO (Proximal Policy Optimization):一种稳定高效的策略优化算法,对超参数不敏感,适用于复杂的决策场景。
- VPG (Vanilla Policy Gradient):作为策略梯度的基础实现,用于对比和验证。
- 环境(Environment):
MicrogridEnv,一个自定义的Gym兼容环境,模拟了包含多个微网的局部能源网络,提供了状态观测、动作执行和奖励计算的完整接口。
整个训练流程遵循标准的强化学习循环:智能体根据当前环境状态(State)选择一个动作(Action),环境接收动作后转移到新状态并返回一个奖励(Reward),智能体利用此反馈不断优化其策略。
2. 微网环境 (`MicrogridEnv`) 详解
MicrogridEnv 是整个系统的核心仿真器,其设计高度模拟了真实微网的物理和经济特性。
2.1 核心组件建模
环境由三个相互连接的微网(HamzaElsheikh、UmBader、Tannah)组成。每个微网包含以下关键组件:
- 负荷(Load):模型化了五种典型负荷(住宅、学校、清真寺、医疗中心、水泵)。每种负荷的用电量并非恒定,而是根据从
usage_trends.csv文件加载的日用电曲线动态变化,使得仿真更贴近现实。 - 发电(Generation):整合了太阳能和风能两种可再生能源。发电数据来源于对应微网的
Solar和Wind目录下的历史数据文件,确保了输入的真实性。 - 储能(Battery):每个微网配备一个电池,用于存储多余能源或在发电不足时释放能量。电池模型包含了最大容量、充电效率、放电系数等关键参数,并实现了充放电逻辑。
- 交易网络:微网之间通过预设的距离(
distances字典)相连,能源在传输过程中会产生损耗,损耗模型基于欧姆定律简化计算。
2.2 状态、动作与奖励设计
- 状态空间(Observation Space):智能体(以
Hamza_Elsheikh为主)观测到的状态是一个四维向量,包含:
1. 电池剩余容量
2. 当前总负荷
3. 当前总发电量
4. 上一轮交易价格 - 动作空间(Action Space):智能体输出一个四维连续动作向量,用于定义一次交易:
1. 交易类型:0-1为买入,1-2为卖出,2-3为不交易。
2. 目标微网:0-1选择Um_Bader,1-2选择Tannah。
3. 交易量:希望交易的能源数量(kWh)。
4. 交易价格:报价(美分/kWh),介于本地成本价与主网电价之间。 - 奖励函数(Reward Function):奖励设计是引导智能体学习的关键。其核心逻辑是:
- 正向激励:成功以低于主网电价买入,或以高于本地成本价卖出,都能获得正奖励。最终能实现能源自给自足(无缺额)会获得高额奖励。
- 负向惩罚:无效操作(如电量不足时试图卖出)、违反市场规则(如报价不合理)、交易量超出实际需求等都会受到惩罚。
3. 深度强化学习智能体实现
系统为不同算法提供了模块化的实现,其核心在于策略网络(Actor)和价值网络(Critic)的设计。
3.1 DDPG 智能体
DDPG是一种Actor-Critic架构的离线策略(off-policy)算法。
- Actor网络:一个全连接神经网络,输入状态,输出确定性的连续动作(即交易决策)。其输出层使用
tanh激活函数,并通过缩放映射到动作空间的实际边界。 - Critic网络:另一个全连接网络,输入状态和动作,输出一个Q值,用于评估在该状态下执行该动作的长期价值。
- 训练机制:采用经验回放缓冲区(Replay Buffer)存储历史交互数据,并使用目标网络(Target Network)和软更新(Polyak Averaging)来稳定训练过程。
3.2 PPO/VPG 智能体
PPO和VPG属于在线策略(on-policy)算法,它们将动作视为从一个概率分布中采样得到。
- Actor网络:对于连续动作空间(如本项目),采用高斯分布(Gaussian Distribution)来建模策略。网络输出动作均值(
mu),并学习一个独立的标准差(log_std)。 - Critic网络:与DDPG不同,PPO/VPG的Critic网络仅输入状态,输出状态价值函数V(s),用于评估当前状态的好坏。
- 训练机制:PPO通过引入“近端”(Proximal)的裁剪机制,限制了策略更新的幅度,从而在保证性能的同时极大地提高了训练的稳定性,这也是其被广泛采用的原因。
4. 训练与实验管理
项目配备了完善的训练和日志记录工具。
- 日志系统:基于
EpochLogger,能够详细记录每个训练周期(Epoch)的关键指标,如回合奖励(EpRet)、Q值、损失函数等,并将配置参数和模型权重自动保存到磁盘。 - 实验配置:通过
userconfig.py和runutils.py,用户可以方便地设置实验超参数、数据保存路径,并支持通过ExperimentGrid进行大规模的超参数搜索。 - 结果可视化:内置的
plot.py脚本可以读取训练日志,自动生成性能曲线图,便于分析和比较不同算法的效果。
5. 总结
该代码库提供了一个功能完整、结构清晰的微网P2P能源交易研究平台。它不仅实现了前沿的深度强化学习算法,还构建了一个细节丰富、贴近实际的微网仿真环境。通过将复杂的能源市场决策问题转化为强化学习任务,该系统为探索去中心化、智能化的未来能源交易模式提供了强大的技术支撑和研究基础。开发者可以在此框架上轻松扩展新的微网模型、交易规则或强化学习算法,以应对更复杂的能源互联网挑战。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)