让机器人第一视角视频“懂人心”!EgoThinker:AI领会拍摄者意图,还能说清“怎么判断的”
EgoThinker是第一视角视频推理框架,通过构建EgoRe-5M数据集(500万QA对)和采用SFT+RFT两阶段训练,显著提升了拍摄者意图推断和手物/时间定位精度。该系统能理解"动作-意图"关系(如切洋葱后要放盐),并提供推理链解释判断依据,在第一视角推理任务上达到SOTA性能。实验显示其在EgoPlan等基准上准确率提升8.8%,手物定位mIoU从28.6%提升至53.
摘要:EgoThinker 是第一视角视频推理框架,基于 EgoRe-5M 数据集(500 万 QA 对)和 SFT+RFT 两阶段训练,提升拍摄者意图推断与手物 / 时间定位精度,在 EgoPlan 等基准达 SOTA,适配可穿戴设备与 embodied AI。
导语
想象一个场景:你戴智能眼镜记录做饭过程,事后想让 AI 帮你回忆 “刚才盐放哪了”—— 传统 AI 只会说 “视频里有盐罐”,却答不出 “放哪了”,更说不出 “怎么判断那是盐罐”;要是让它预测 “接下来要做什么”,它只会瞎猜 “可能关火”,完全没考虑 “刚才切了洋葱,通常下一步要放调料”。这就是传统多模态大模型(MLLM)在第一视角(egocentric)视频推理上的硬伤:只能看到 “表面动作”,猜不透拍摄者的 “隐藏意图”,也说不出自己的判断逻辑。
上海人工智能实验室&浙江大学&复旦大学&南京大学&东京大学联合研究的《EgoThinker: Unveiling Egocentric Reasoning with Spatio-Temporal CoT》技术:它像给 AI 装了 “第一视角思维镜”:不仅能看懂第一视角视频里拍摄者想干嘛(比如 “切洋葱后要放盐”),还能详细描述 “刚才看到白色碎末、左手按菜的动作,所以判断在切洋葱”,甚至能精准指出 “手在画面中间,洋葱在左手下方”。更厉害的是,它在复杂第一视角任务(比如听声辨位找目标)上的表现,直接刷新了现有最好成绩。本文将详解这项让 AI “读懂第一视角” 的技术!
一、先聊痛点:传统 AI 看第一视角视频,为啥 “又瞎又哑”?
第一视角视频(比如戴相机拍摄的做饭、维修视频)和普通第三视角视频最大的不同:拍摄者是场景的参与者,而不是旁观者。这就要求 AI 不仅要识别 “发生了什么”,还要推断 “拍摄者想做什么”“接下来要做什么”,但传统 MLLM 总有三个绕不开的坑:
1)“猜不透” 隐藏意图传统模型能识别 “切菜”“拿罐” 这类表面动作,却不知道 “切菜是为了做沙拉”“拿罐是要放盐”。比如在第一视角维修视频里,模型看到 “拧螺丝”,却猜不到 “接下来要拆面板”,因为它不会关联 “螺丝位置在面板边缘”“之前拆过类似设备” 这些上下文。
2)“说不出” 判断逻辑就算偶尔猜对了,模型也说不出 “为什么这么判断”。比如它知道 “在切洋葱”,却没法解释 “因为看到白色碎末、左手按菜的姿势、右手刀的运动轨迹,这些都是切洋葱的特征”—— 就像 “闭着眼做题,对了也不知道为啥”,完全是 “黑箱推理”。
3)“定不准” 细粒度位置第一视角推理需要精准定位 “手在哪”“物体在哪”“动作发生在什么时候”,但传统模型要么找不到手的位置(把刀柄当手),要么定不准时间(说 “切洋葱在 10 秒”,实际在 15 秒)。比如在 “左手拿盐罐” 的场景里,模型预测的手的位置偏差超过 20%,根本没法辅助后续动作(比如 AR 眼镜提示 “左手边就是盐罐”)。
这些问题的根源,一是没有专门的第一视角推理数据集(传统数据集只有动作标签,没有意图和推理链),二是训练方式没兼顾 “推理” 和 “定位”—— 而 EgoThinker 的核心,就是用 “超大第一视角数据集 + 两阶段训练”,让 AI 既会 “想”,又会 “说”,还能 “定准”。
二、EgoThinker:给 AI 装 “第一视角思维三件套”
EgoThinker 的设计思路特别接地气:先给 AI “喂足第一视角推理素材”(EgoRe-5M 数据集),再让它 “先学推理打基础,再练定位提精度”(SFT+RFT 两阶段训练),就像先让学生背熟 “第一视角场景词典”,再教他 “边分析边写解题步骤,写对了给奖励”。
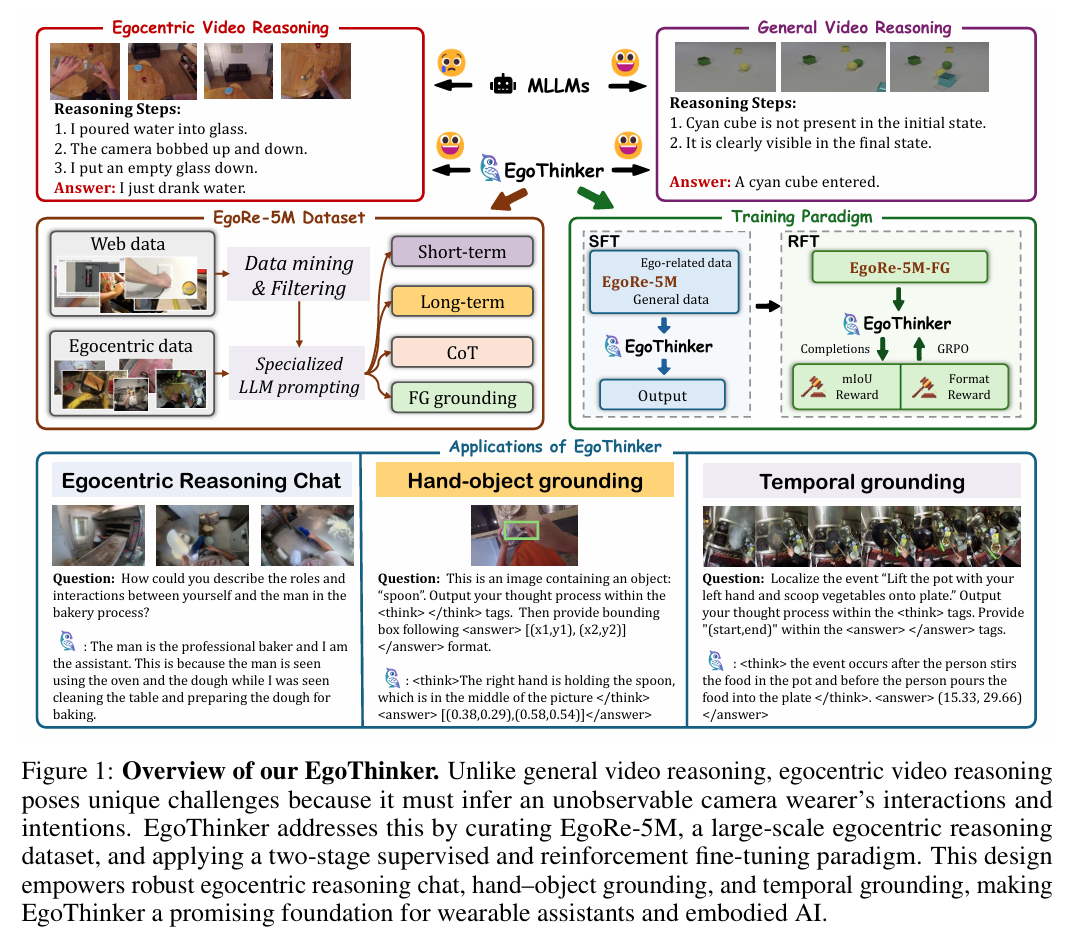
图 1:EgoThinker 的 “读懂第一视角” 核心
这个框架的厉害之处在于:把 “推理” 和 “定位” 绑在一起练——AI 学描述动作时,会更关注 “手的位置”“物体特征”,反过来又能提升定位精度,形成 “越推理越准,越准越会推理” 的正循环。
1. 第一件套:EgoRe-5M—— 给 AI 的 “第一视角推理课本”
EgoRe-5M 是 EgoThinker 的 “弹药库”,专门解决 “没素材学” 的问题。它从 1300 万条第一视角视频里筛选出 500 万条 QA 对,涵盖四种核心推理场景,相当于给 AI 准备了 “小学到大学” 的完整课程:
| 数据类型 | 学什么(通俗解释) | 例子(切洋葱场景) |
|
短期感知(1-10s) |
学 “当下在干嘛”,识别物体、动作 |
问题:“手里拿的是什么?”→回答:“右手拿的是菜刀,刀刃对着洋葱” |
|
长期推理(15-120s) |
学 “动作链和意图”,关联多步动作 |
问题:“切完洋葱要干嘛?”→回答:“要放盐,因为切菜后通常调味,台面上有盐罐” |
|
思维链(CoT) |
学 “分步推理”,说清判断理由 |
问题:“怎么判断在切洋葱?”→回答:“Step1:看到白色碎末;Step2:左手按扁圆形物体;Step3:右手刀上下动,所以是切洋葱” |
|
细粒度定位 |
学 “找手 / 物体位置、定动作时间” |
问题:“左手在哪?”→回答:“左手按在洋葱上,在画面左下方 [(0.2,0.5),(0.4,0.8)]”(坐标归一化到 0-1) |
这个数据集的特别之处:不是人工标的(成本太高),而是用 “web 视频过滤 + 预训练 VLM 生成”—— 先从 HowTo100M 等 web 数据里挑出 870 万条第一视角视频(比如做饭、维修),再用 VideoChat2-HD 生成描述,最后用 DeepSeek-V3 生成 QA 对,人工抽查准确率超 95%,既保证规模又保证质量。
2. 第二件套:SFT—— 给 AI “打推理基础”
第一阶段是监督微调(SFT),让 AI 先学会 “基本的第一视角推理”。简单说就是 “让 AI 模仿正确答案”:
-
输入:第一视角的 RGB + 深度图 + 音频(比如切洋葱的画面和声音);
-
输出:AI 要模仿 EgoRe-5M 里的正确答案,比如 “在切洋葱,下一步放盐”,还要写出推理链;
-
关键:兼顾 “通用能力” 和 “ego 能力”—— 除了 EgoRe-5M,还混入普通视频 QA 数据(比如 MVBench),避免 AI 只会第一视角,不会其他场景。
比如训练后,AI 看到切洋葱的画面,能准确输出 “动作:切洋葱;推理:白色碎末 + 左手按菜 + 菜刀动作;下一步:放盐”,虽然定位还不够准,但推理逻辑已经通顺了。
3. 第三件套:RFT—— 让 AI“定位更准、格式更对”
第二阶段是强化微调(RFT),用 “奖励机制” 让 AI 在推理的同时,提升定位精度和输出格式规范性。核心是两个奖励:
1)格式奖励:AI 必须用指定格式输出(推理用...包起来,答案用...包起来),比如 “看到左手按洋葱 [(0.2,0.5),(0.4,0.8)]”,格式对给 1 分,错了给 0 分;
2)定位奖励:手物定位的 IoU(重叠度)越高,奖励越高(比如 IoU=0.8 给 0.8 分,IoU=0.3 给 0.3 分);时间定位同理,预测的时间区间和真实重叠高就给高分。
用 GRPO 算法优化(不用单独训评价模型,直接对比多个候选答案的好坏),比如 AI 生成两个手的位置,一个 IoU=0.7,一个 IoU=0.5,就优先让 AI 学 IoU 高的那个。训练后,AI 的手物定位 mIoU 能从 28.6% 涨到 53.7%,相当于 “从找不准手,到能精准框出手的位置”。
三、实验验证:EgoThinker 让第一视角推理 “又准又会说”
研发团队在 7 个第一视角基准测试、2 个细粒度定位任务上测了 EgoThinker,结果证明:它不仅推理能力强,定位也准,还能跨视角迁移(从第三视角学的能力用到第一视角)。
1. 第一视角推理:多个基准拿 SOTA,规划能力显著提升
在 EgoTaskQA(理解任务意图)、EgoPlan(规划下一步动作)等基准上,EgoThinker 全面超过传统 MLLM:
-
EgoPlan 准确率:比 baseline Qwen2-VL 高 8.8%(47.1% vs 38.3%)—— 意味着 AI 更懂 “接下来该干嘛”,比如在做饭视频里,能准确预测 “切完洋葱放盐”,而不是瞎猜 “关火”;
-
VLN-QA(导航问答)准确率:54.0% vs 42.0%—— 在第一视角导航视频里,能准确回答 “刚才经过的门在左边还是右边”,因为能回忆 “过去的动作描述”;
-
跨视角 RES 基准:比第二好的模型高 8.4%—— 能把第三视角学的 “切菜动作” 迁移到第一视角,比如看第三视角切菜视频,能对应到自己第一视角的动作。
2. 细粒度定位:手物和时间定位精度翻倍
在最考验细节的 “手物定位” 和 “时间定位” 任务上,EgoThinker 的提升更明显:
-
手物定位 mIoU:53.7% vs 28.6%( baseline)—— 之前框手偏差 20%,现在偏差不到 10%,AR 眼镜能精准提示 “手在画面左下方,按着洋葱”;
-
时间定位 R1@0.05:63.9% vs 7.8%( baseline)—— 之前找 “切洋葱” 的时间偏差 5 秒,现在偏差不到 1 秒,能准确回忆 “切洋葱在 15-16 秒之间”。

图 4:手物定位对比
图 4 描述:
四张图对比不同模型定位 “菜板” 的效果:
-
①Qwen2-VL( baseline):框住了桌面,没精准框菜板;
-
②GPT-4o:推理链通顺,但把菜板错标成 “披萨盘”,框位偏右;
-
③Grounding-DINO(专业定位模型):能框准菜板,但分不清 “左手按菜的位置”;
-
④EgoThinker:推理链写 “菜板在画面右侧,上面有洋葱碎,左手按在菜板左侧”,框位精准覆盖菜板,还标注了手的位置)
从图里能直观看到:EgoThinker 不仅定位准,还能结合推理说明 “为什么这是菜板”,而其他模型要么定不准,要么不会解释。
3. 不丢通用能力:普通视频理解也没落下
很多模型专注第一视角后,普通视频理解会变差,但 EgoThinker 在 MVBench(通用视频基准)上准确率 70.0%,比 baseline 还高 1.8%—— 说明它学的第一视角推理能力,还能反过来提升通用视频理解,比如看第三视角做饭视频,也能更准判断 “下一步放调料”。
四、小缺点与未来:EgoThinker 还能更 “灵活”
EgoThinker 虽然表现好,但还有 3 个小遗憾,需要后续优化:
1)依赖大量标注数据:EgoRe-5M 虽然部分自动生成,但还是需要预训练 VLM 和人工抽查,未来可以用自监督学习,让 AI 自己从视频里学推理;
2)实时性不足:目前推理一帧要 0.5 秒,没法满足 AR 眼镜 “实时提示” 的需求,需要优化模型轻量化(比如剪枝参数);
3)场景适配有限:现在主要适配室内场景(做饭、维修),户外场景(比如第一视角爬山)表现稍差,因为户外光线变化大,物体识别难度高。
五、总结:EgoThinker 让第一视角 AI 更 “懂人”
以前的第一视角 AI 是 “只会看,不会想,不会说”;而 EgoThinker 让 AI 变成 “会看、会想、会说、会定位” 的 “第一视角助手”—— 它的价值不仅在于刷新了 SOTA,更在于打开了很多实用场景的大门:
-
可穿戴设备:AR 眼镜帮老人回忆 “刚才把药放哪了”,因为能描述 “10 秒前你打开过客厅抽屉,左手拿了个白色药瓶”;
-
Embodied AI:机器人用第一视角看人类做饭,能准确配合 “你切完洋葱后,我帮你拿盐罐”;
-
视频分析:第一视角教学视频自动生成 “步骤说明 + 动作定位”,学生能看到 “切洋葱时手的位置在画面左下方,刀要垂直下切”。
未来只要解决实时性和场景适配,EgoThinker 说不定能让我们的 AR 眼镜、智能相机,变成 “能读懂你意图的贴心助手”—— 再也不用纠结 “刚才把钥匙放哪了”“下一步该干嘛”。
(注:本文技术细节来自论文《EgoThinker: Unveiling Egocentric Reasoning with Spatio-Temporal CoT》,代码与数据已开源:https://github.com/InternRobotics/EgoThinker,感兴趣可直接体验~)
END




有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)