13张图解Transformer和混合专家(MoE)的差别 | 大型语言模型的架构对比
本文探讨了混合专家(MoE)架构在Transformer模型中的应用与优势。MoE通过引入多个专家网络和路由器机制,动态激活部分专家处理输入数据,在保持模型性能的同时显著提升推理效率。文章详细解析了MoE的技术实现,包括路由器的智能调度机制及其训练优化方法,并讨论了专家训练不均衡等挑战的解决方案。相较于传统Transformer,MoE展现出更快的推理速度、更高的灵活性和更大的模型容量,成为当前大
在自然语言处理(NLP)领域,Transformer模型因其卓越的表现能力已成为当前主导架构。
然而,随着模型参数量的持续增长,计算资源消耗与实时推理延迟逐渐成为关键限制因素。为突破这一瓶颈,混合专家(Mixture of Experts, MoE)架构被提出并发展。
该架构通过动态激活多个专业化"专家"子网络,在维持甚至增强Transformer模型性能的前提下,显著提升了推理效率。本文将从以下维度展开分析:
Transformer与MoE在大型语言模型中的核心差异
MoE技术实现机制的详细解析
该架构面临的实际应用挑战与潜在优势
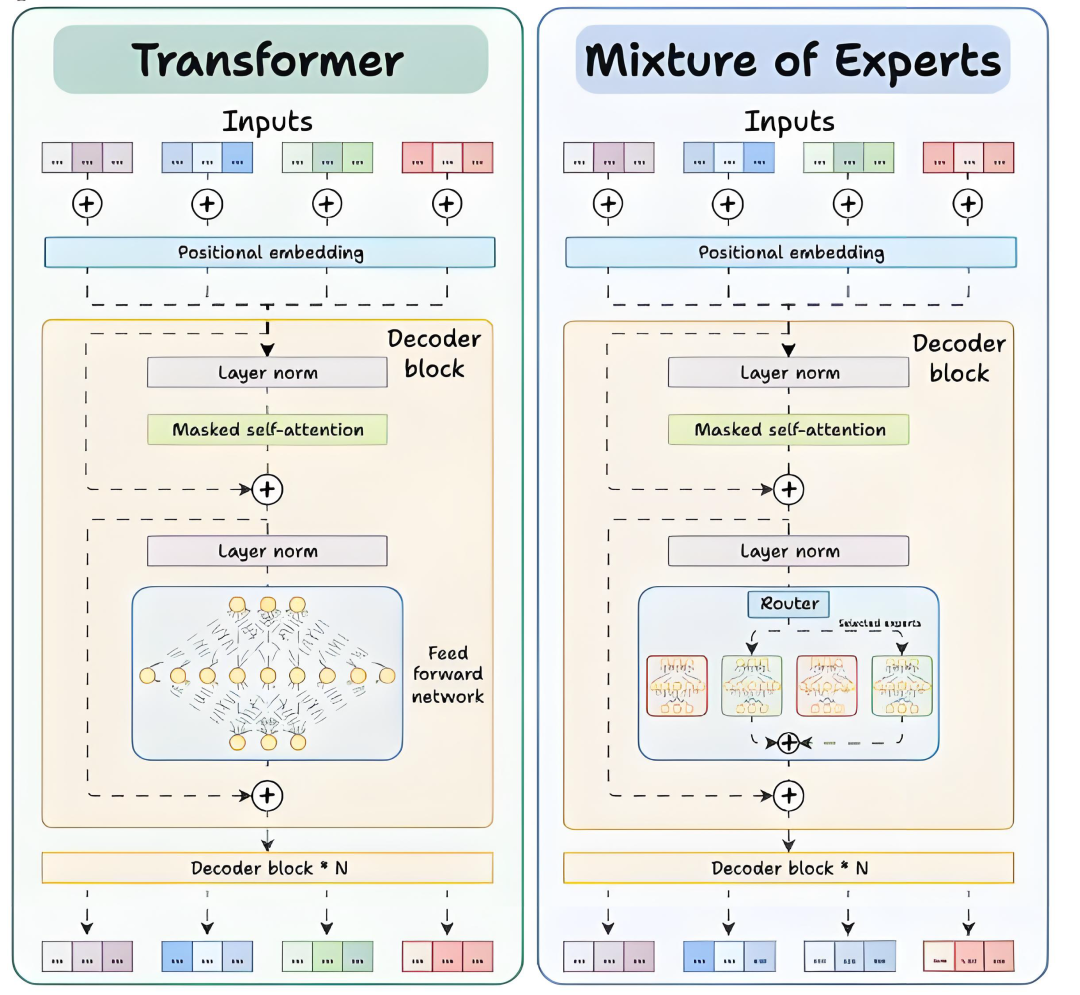
一、Transformer与MoE的基本概念
1.1 Transformer架构
Transformer作为一种采用自注意力机制的神经网络结构,在机器翻译、文本生成等领域具有广泛应用。其架构主要由编码器与解码器两大模块构成,每个模块均包含若干层级。
在每一层级内部,前馈网络(Feed-Forward Network, FFN)作为核心组件,通过非线性变换处理输入数据,从而提升模型的表征能力。

最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
1.2 混合专家(MoE)架构
混合专家(MoE)是一种突破性的架构设计,它在Transformer框架中整合了多个"专家"模块以优化性能。
在MoE模型中,原有的单一前馈网络被重构为多个并行运行的专家网络。这些专家网络虽仍保持前馈网络的基本结构,但与Transformer中的FFN相比,其参数量更少、计算效率更高。
MoE的创新性体现在:系统不会激活全部专家,而是借助路由器(Router)的智能调度,针对每个输入单元(如文本token)实时匹配合适的专家进行处理。这种动态分配机制大幅提升了模型推理速度。
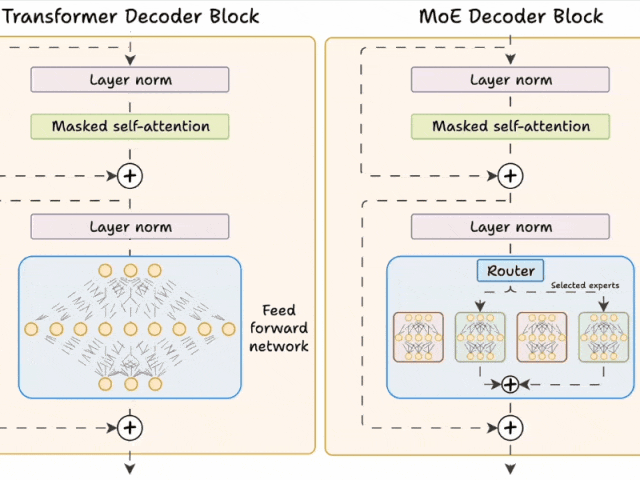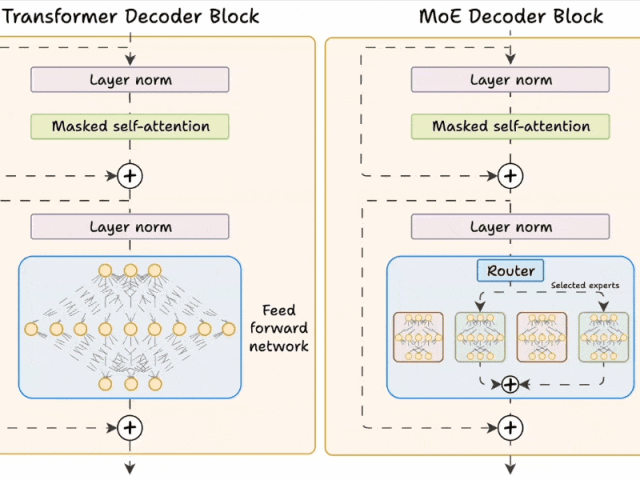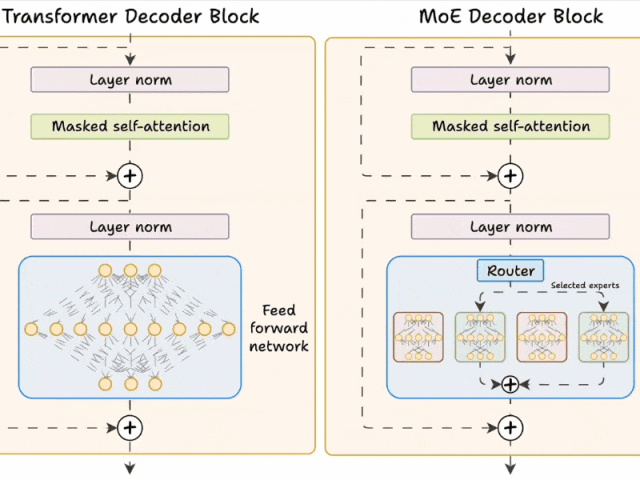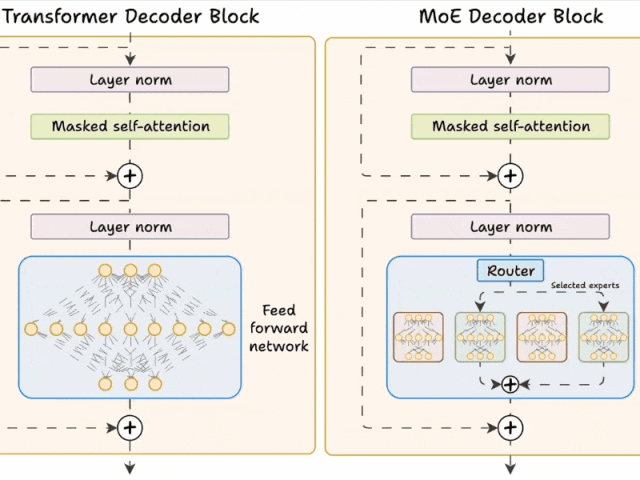
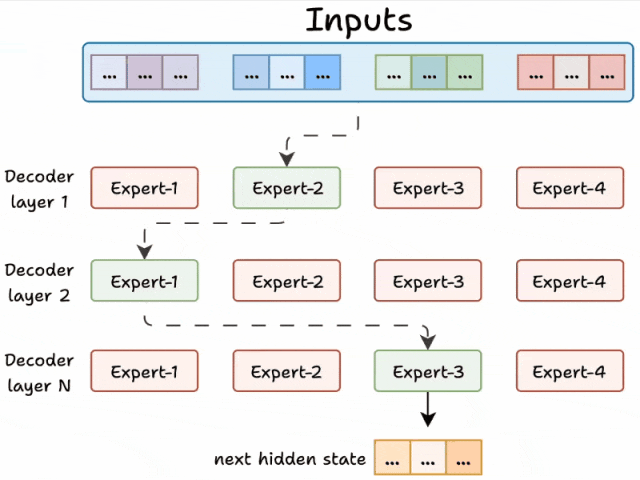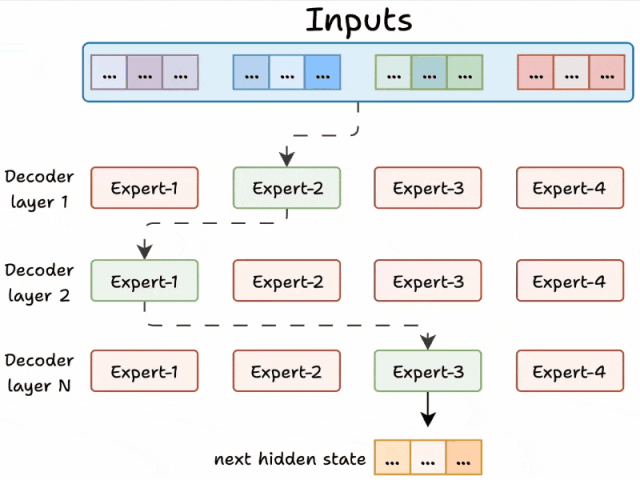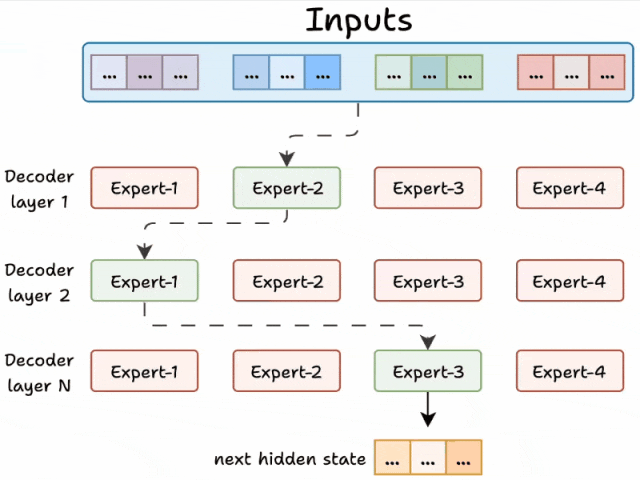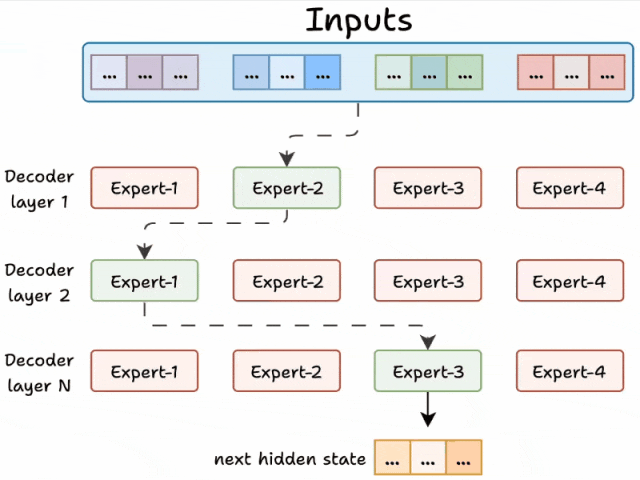
二、Transformer与MoE在解码器块上的区别
2.1 Transformer的解码器块
在标准的Transformer模型中,每个解码器块包含以下组件:
-
自注意力层:捕捉输入序列中的依赖关系。
-
前馈网络(FFN):对自注意力层的输出进行进一步处理。
这个FFN是一个全连接的神经网络,所有输入数据都会经过相同的计算路径。
2.2 MoE的解码器块
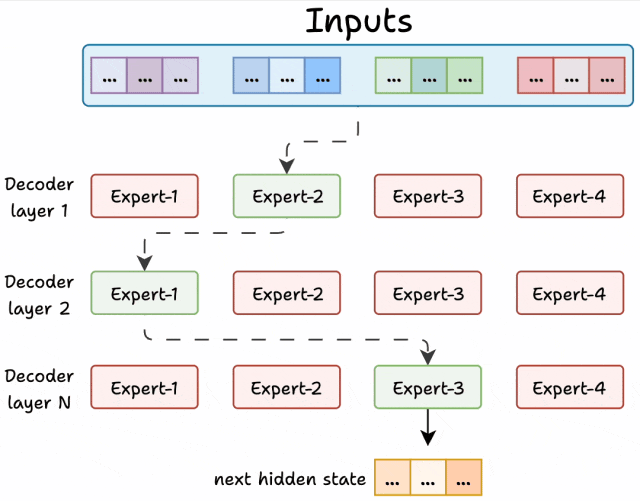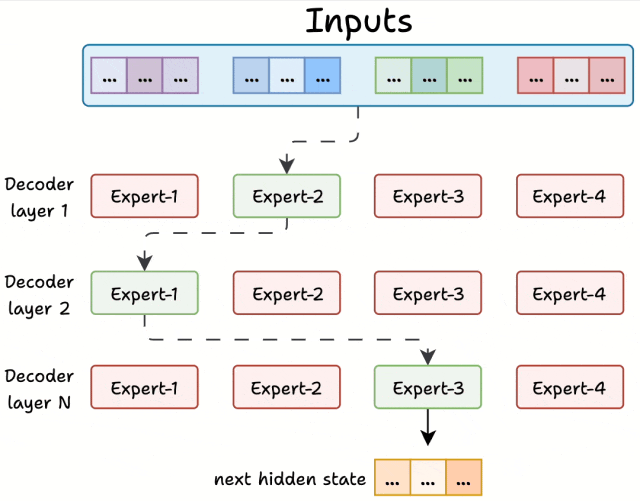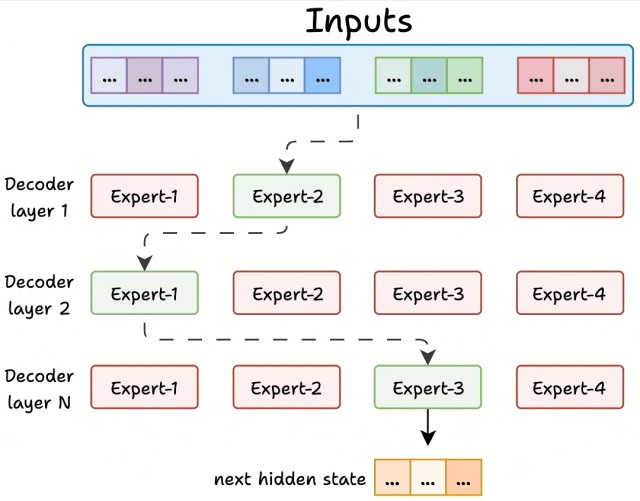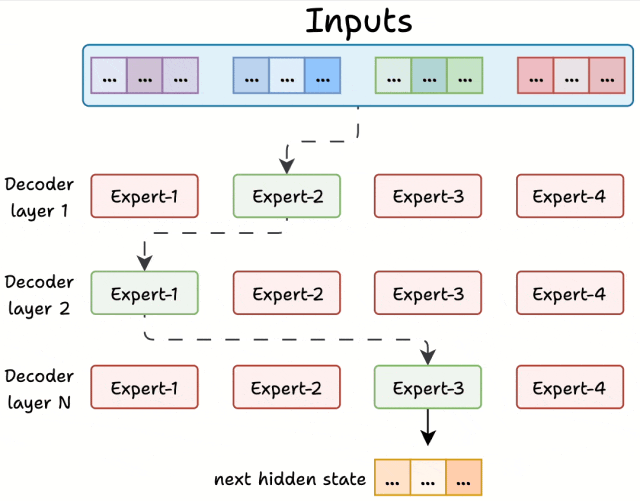
MoE对解码器结构进行了重构,核心改进体现在以下方面:
前馈网络被替换为多个专家网络:这些专家由小型前馈网络构成,具有数量多、单个体量小的特点。
新增路由器模块:在推理阶段,路由器会为每个token筛选部分专家(默认选取前K个)参与计算。
由于模型包含多层解码器结构:
同一文本在不同解码层可能由不同专家处理
同一层内的不同token也可能被分配给相异专家
这种动态分配机制赋予MoE更强的任务适应能力,同时通过限制激活参数规模,显著提高了推理效率。
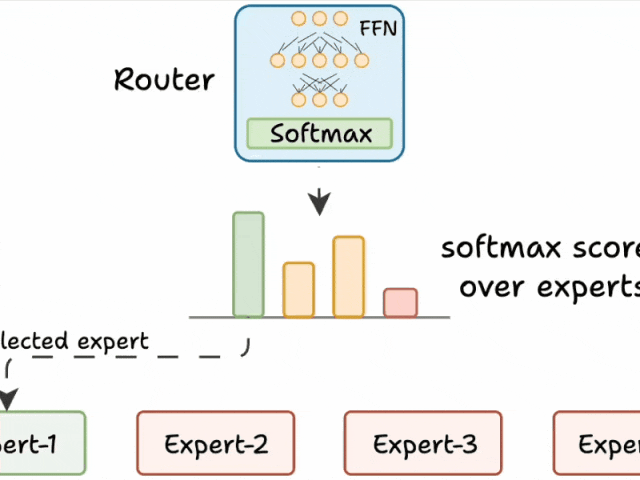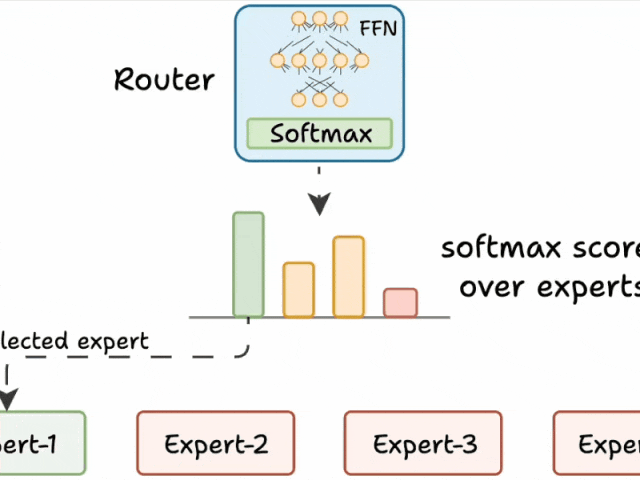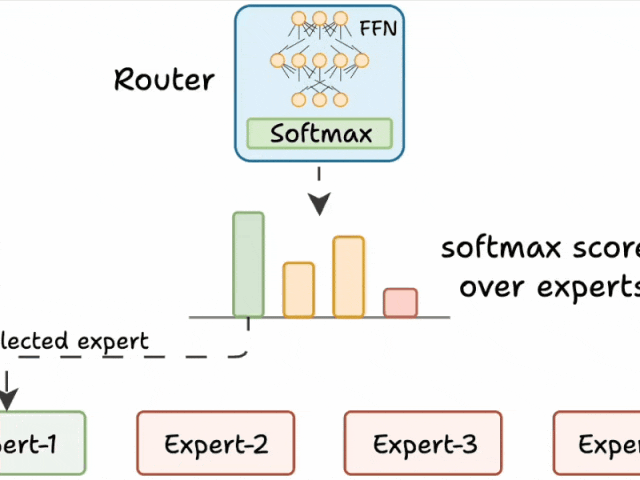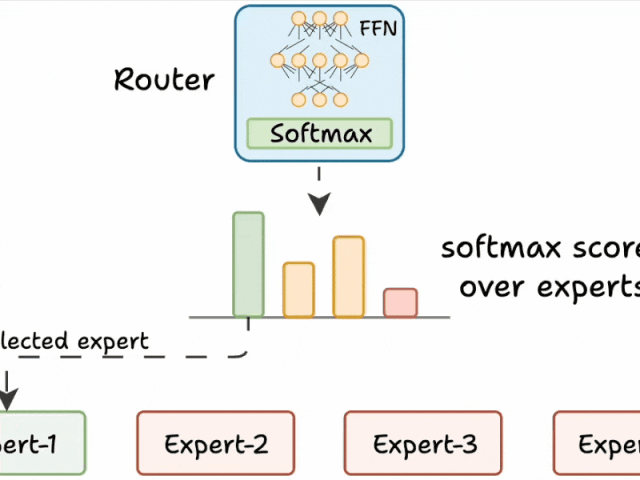
三、路由器的工作原理
路由器是MoE模型的“大脑”,负责决定每个token由哪些专家处理。其工作流程如下:
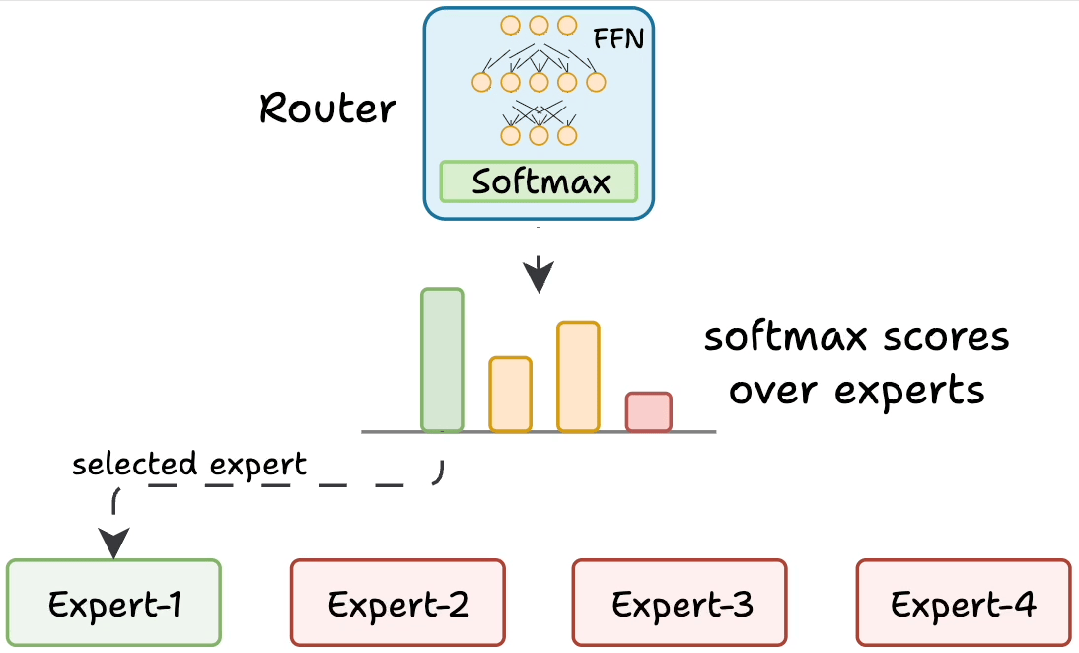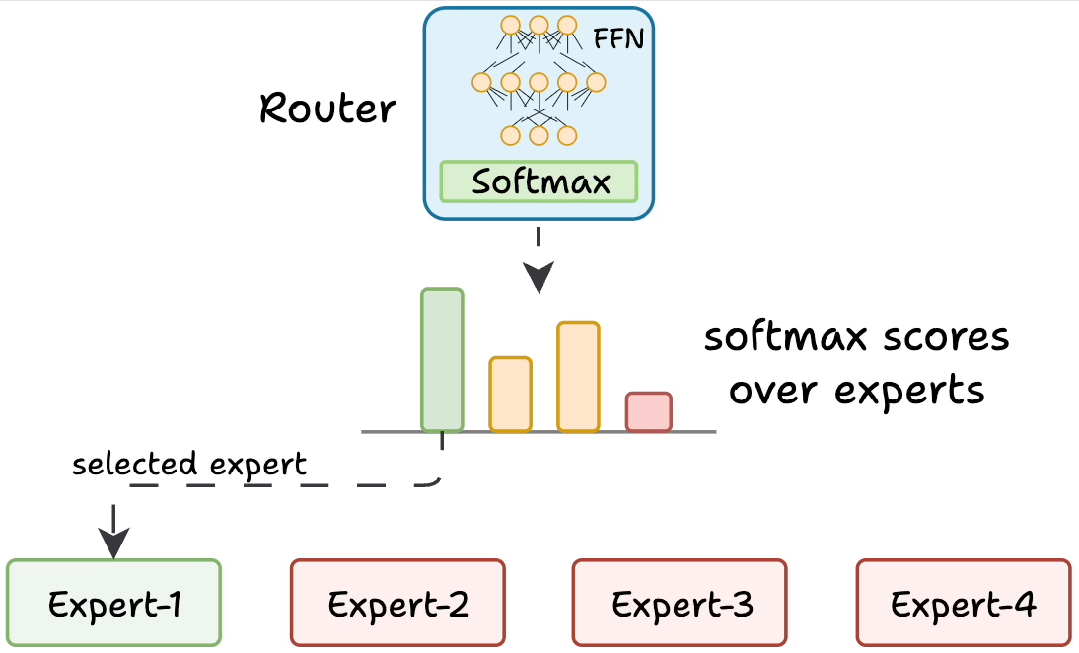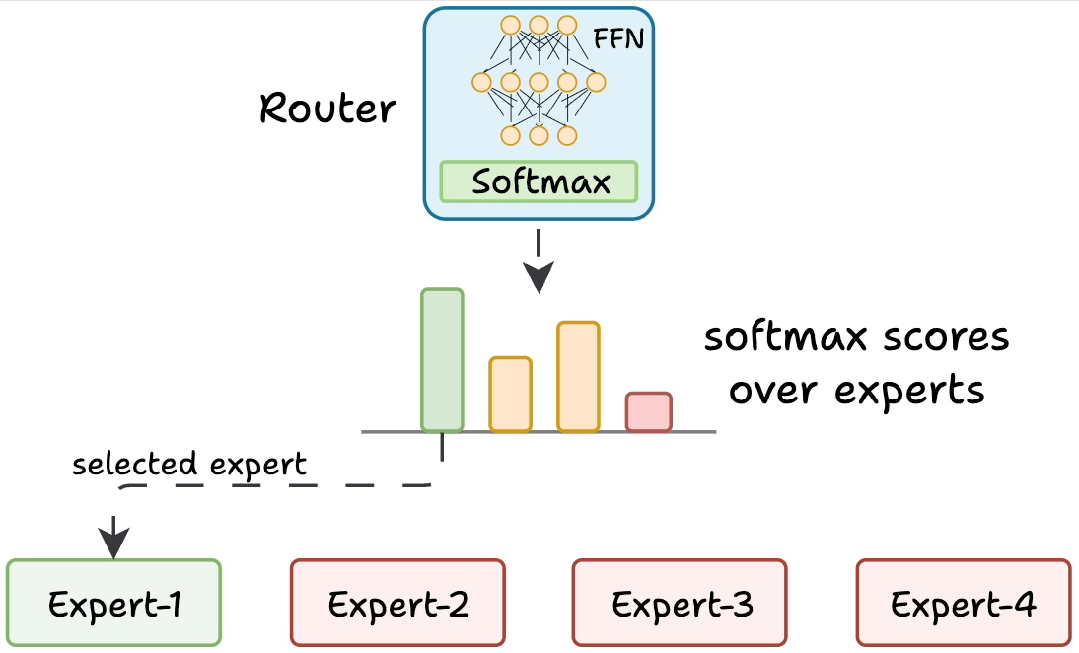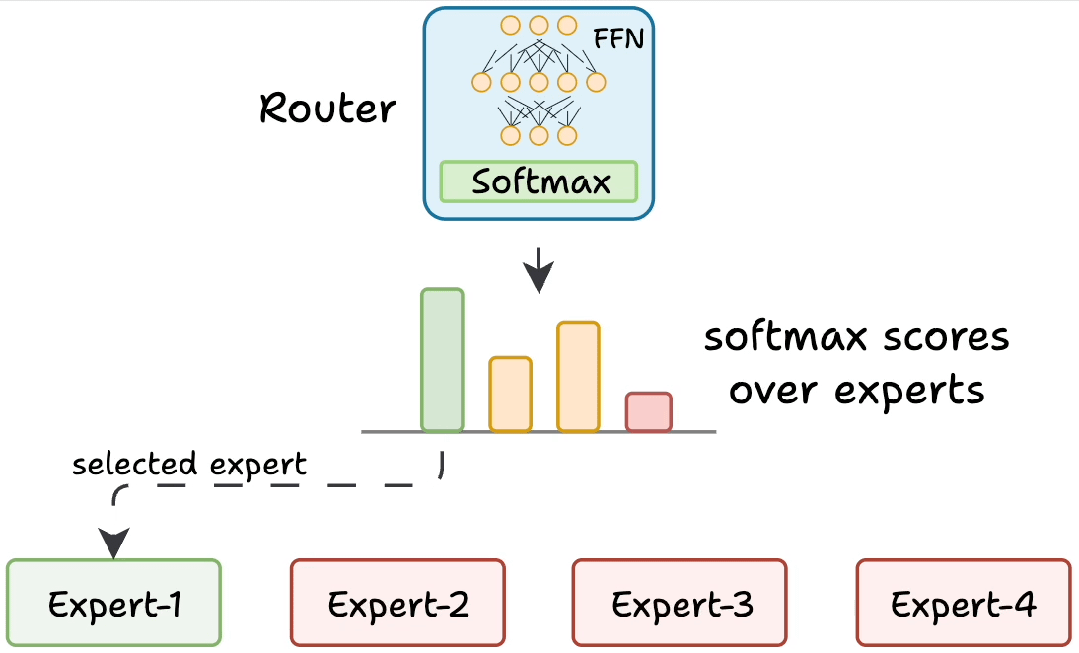
-
生成分数:路由器为每个专家生成一个未归一化的分数(logits)。
-
softmax归一化:将这些logits通过softmax函数转换为概率分布。
-
选择专家:根据概率分数,选择得分最高的前K个专家处理当前token。
路由器与整个网络一同训练,通过反向传播逐渐学会如何为不同的输入选择最佳专家。这种动态分配机制是MoE高效性的关键。
四、MoE面临的挑战与解决方案
尽管MoE架构设计巧妙,但在训练和实现过程中仍面临一些挑战。以下是两个主要问题及其解决方案:
4.1 挑战1:专家训练不均衡
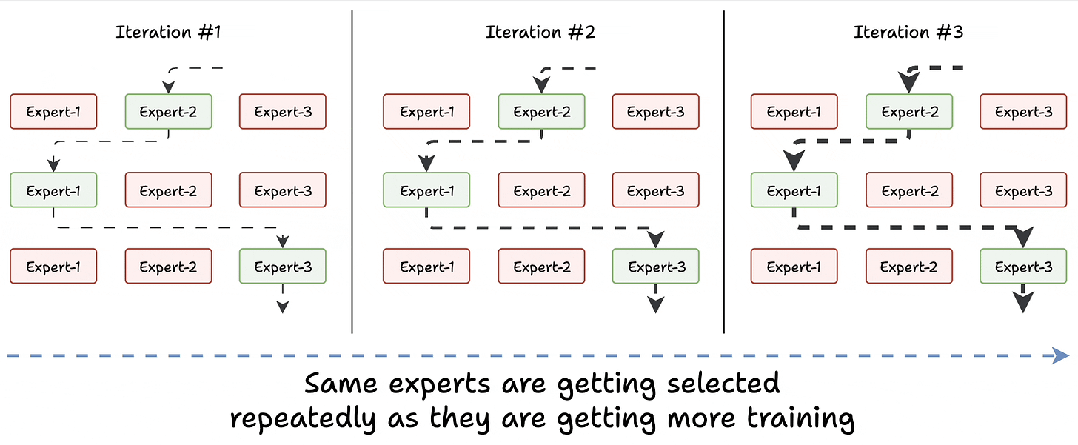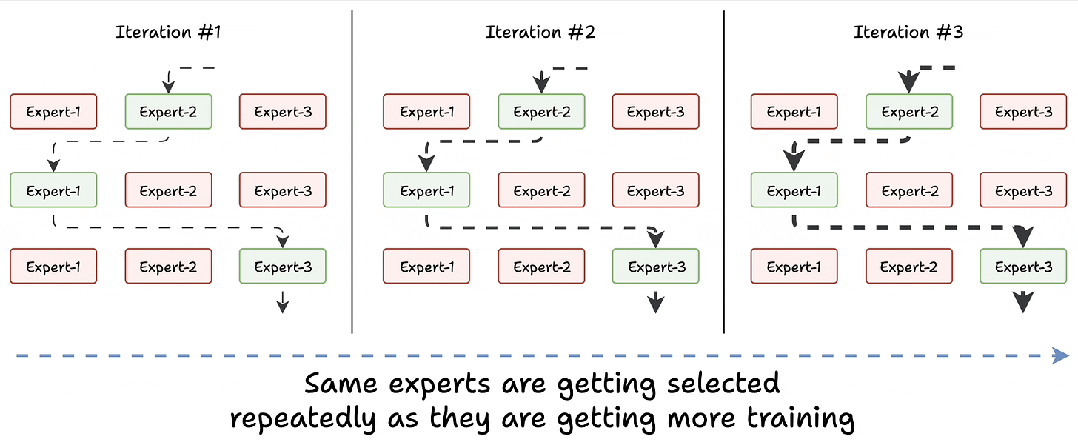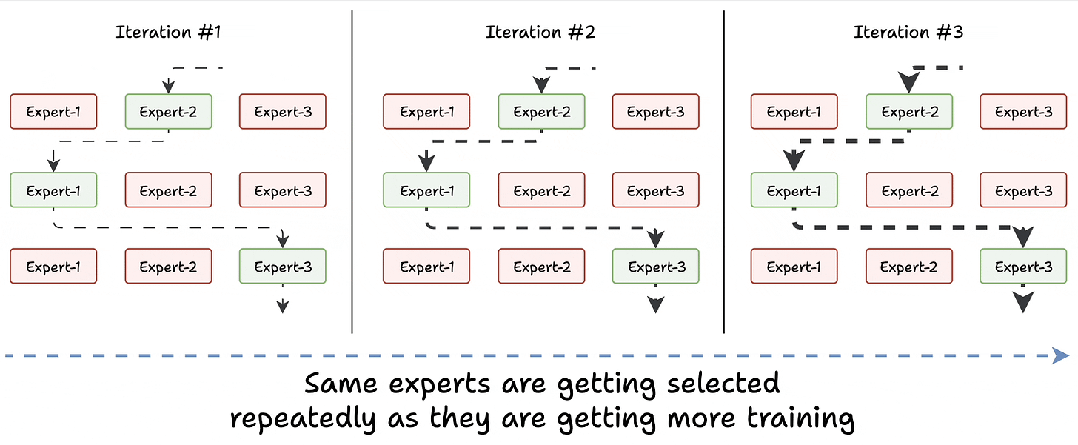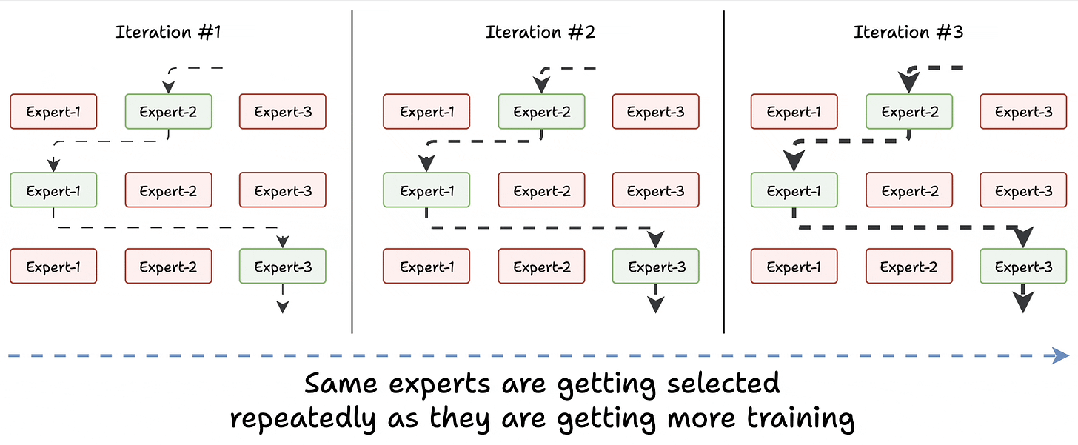
在训练初期,所有专家的能力相似,路由器可能会随机选择某个专家(例如“专家2”)。随着训练进行,这个专家会因频繁使用而变得更强,随后被更频繁地选中,形成恶性循环:
-
“专家2”被选中 → 变得更好 → 再次被选中 → 变得更强 → 反复如此。
-
其他专家则因缺乏训练机会而表现不足。
解决方案:
-
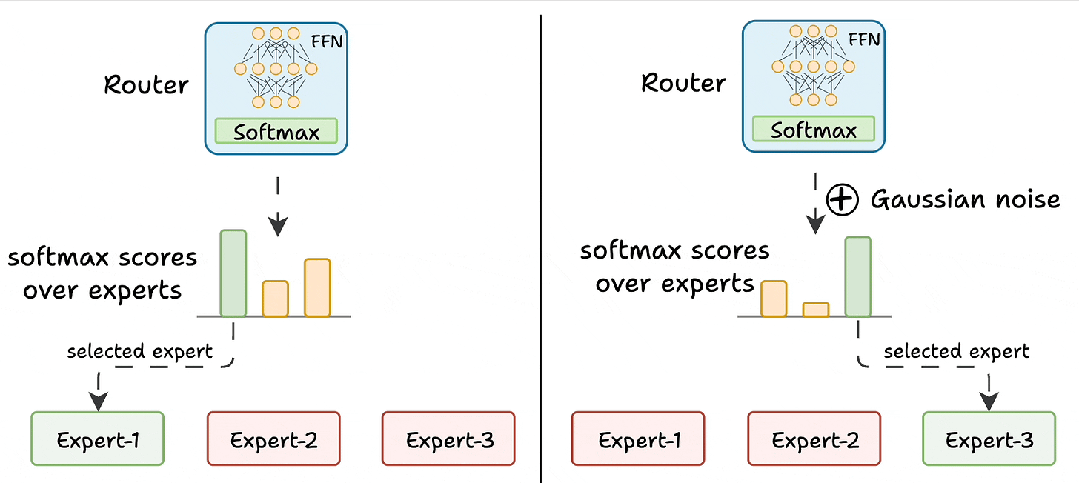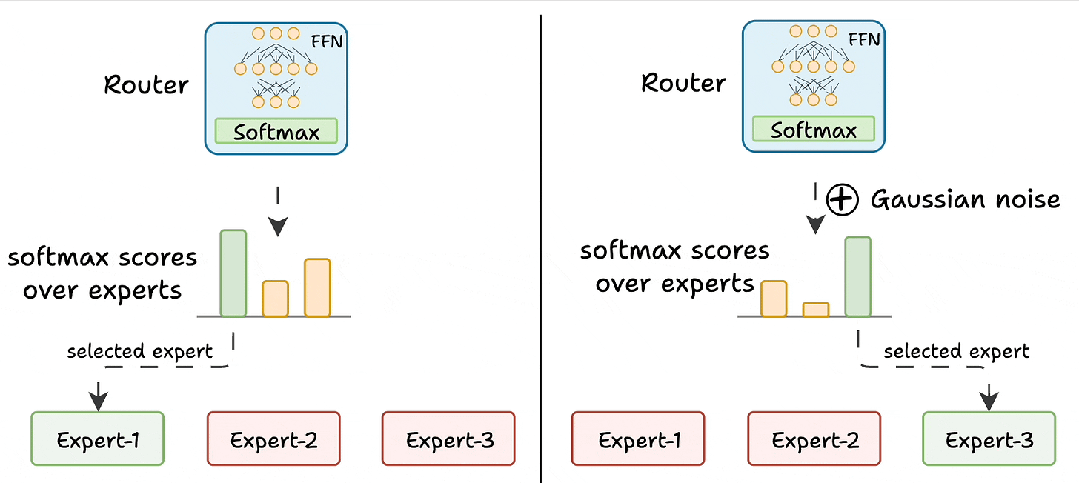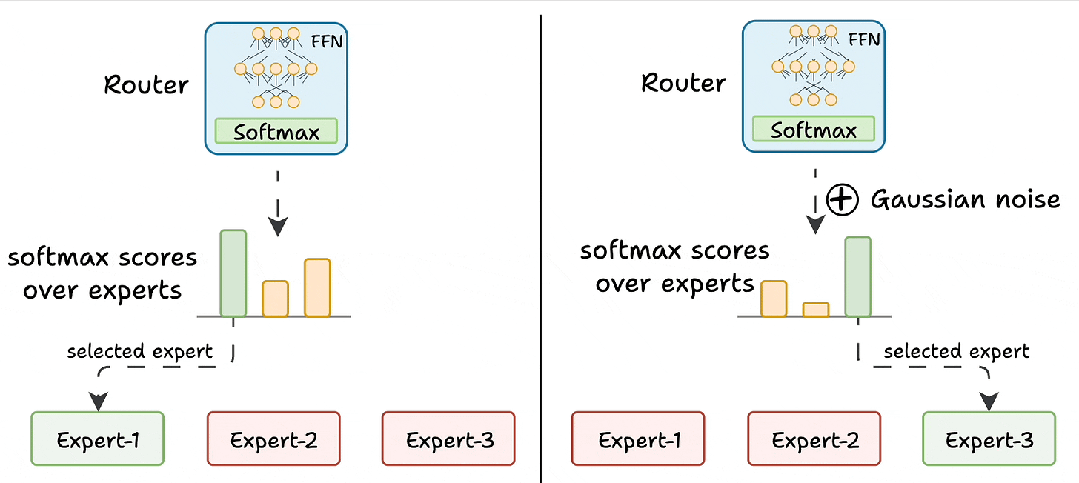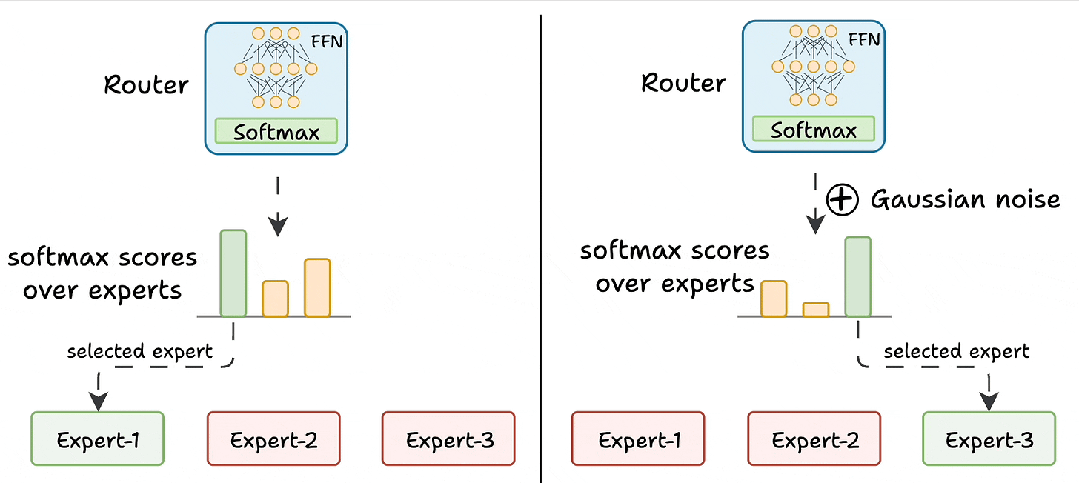
添加噪声:在路由器的输出logits中加入随机噪声,使其他专家有机会获得更高的分数,从而被选中。
-
屏蔽低分专家:将除前K个logits外的所有logits设置为负无穷,经过softmax后这些专家的分数变为零,确保训练机会的公平分配。
4.2 挑战2:专家负载不均衡
某些专家可能会比其他专家处理更多的token,导致训练资源分配不均,部分专家得不到充分优化。
解决方案:
- 限制专家容量:为每个专家设置一个处理token的上限。一旦某个专家达到限制,新的token将被分配给下一个得分最高的专家,从而保证所有专家都能参与训练。
五、MoE的优势
MoE架构在大型语言模型中展现出显著优势:
-
更快的推理速度:尽管MoE模型加载的参数量比Transformer多,但在推理时只激活部分专家,计算量大幅减少,速度更快。
-
更高的灵活性:通过动态选择专家,MoE能更好地适应不同的输入数据和任务。
-
更大的模型容量:多个专家的引入提升了模型的表达能力,而不显著增加计算成本。
一个典型的例子是MistralAI的Mixtral 8x7B,它基于MoE架构,在保持高效推理的同时,展现了强大的语言生成能力。
专家混合(MoE)是一种流行的架构,比如前段时间火爆天的 DeepSeek V3 和 R1 就是这类模型。它利用不同的“专家”来改进 Transformer 模型。
下面的示意图展示了它们与 Transformer 的不同之处。
Transformer 和 MoE 在 decoder 块中有所不同:
- Transformer 使用前馈网络。
- MoE 使用 experts,它们是前馈网络,但与 Transformer 中的网络相比更小。
在推理过程中,将选择专家的子集。这使得 MoE 中的推理速度更快。
由于网络包含多个解码器层:
- 文本会在不同的层中经过不同的专家。
- 每个 token 选择的专家也各不相同。
但是,模型如何决定哪些专家是理想的呢?
这由路由器(Router)来完成。接下来我们来讨论它。
路由器就像一个多分类分类器,它对专家生成 softmax 分数。根据这些分数,我们选择前 K 个专家。
路由器与网络一起训练,并学习如何选择最合适的专家。
但这并不简单。让我们来看看其中的挑战!
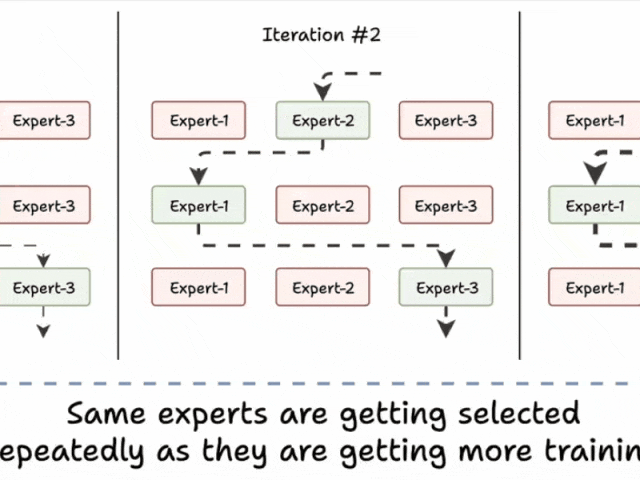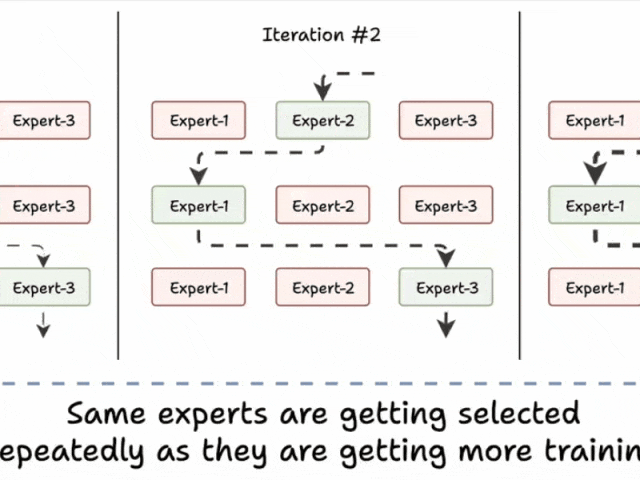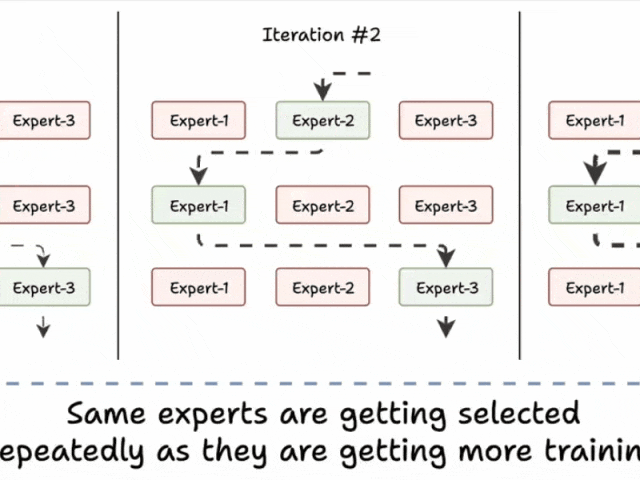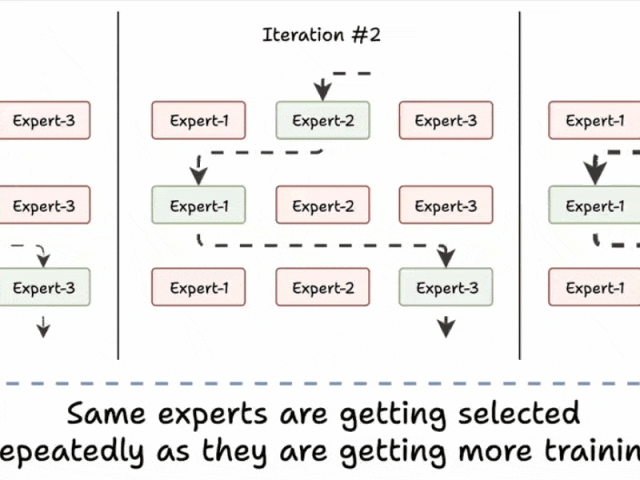
挑战 1)注意训练初期的这一模式:
- 模型选择“专家 2”
- 该专家变得稍微更好
- 可能会再次被选中
- 该专家学到更多知识
- 又被选中
- 学到更多知识
- 如此循环!
许多专家因此训练不足!
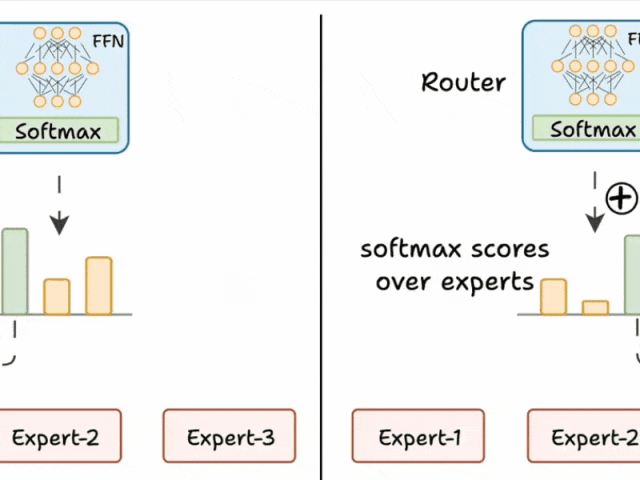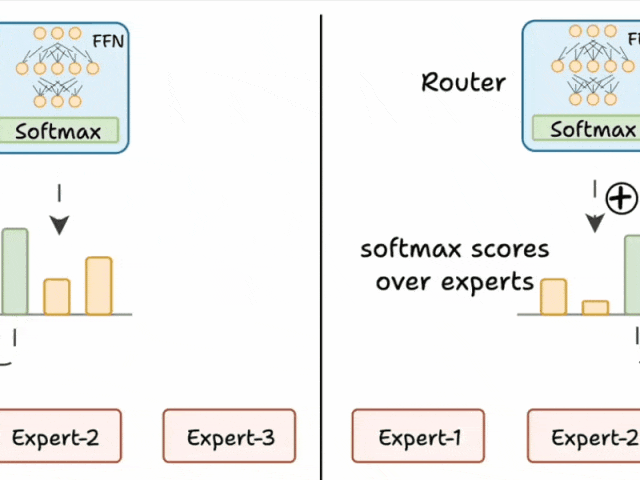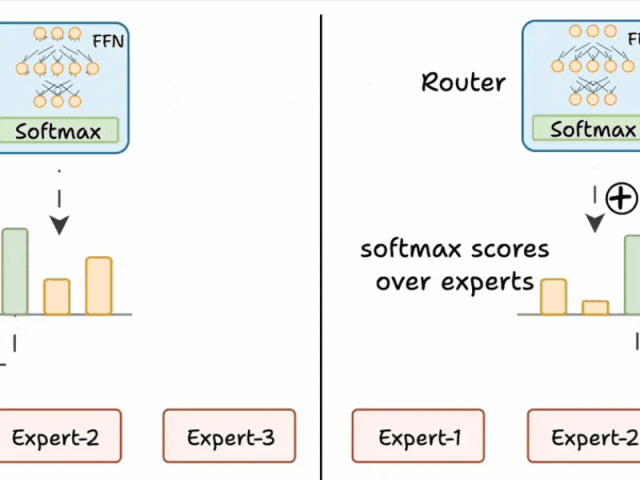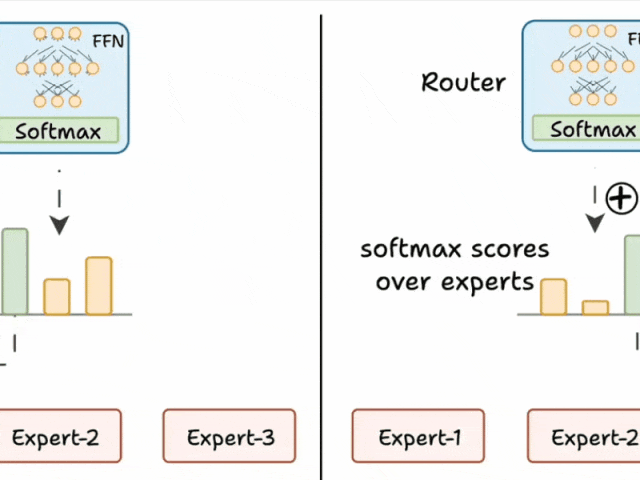
我们通过两个步骤来解决这个问题:
- 在路由器的前馈输出中添加噪声,使其他专家的 logits 更高。
- 将除前 K 个之外的所有 logits 设为负无穷大,这样在 softmax 之后,这些分数就变为零。
这样,其他专家也有机会参与训练。
挑战 2)某些专家可能会比其他专家处理更多的 token,导致部分专家训练不足。
我们通过限制每个专家可处理的 token 数量来避免这种情况。
如果某个专家达到上限,输入的 token 就会被传递给下一个最合适的专家。
MoE 具有更多的参数需要加载,但由于每次仅选择部分专家,因此只有一部分参数被激活。
这使得推理速度更快。@MistralAI 的 Mixtral 8x7B 就是一个基于 MoE 的知名大型语言模型(LLM)。
下面是对比 Transformer 和 MoE 的示意图!
六、总结
Transformer与混合专家(MoE)代表了大型语言模型发展的两个重要阶段。Transformer以其简洁高效的架构奠定了NLP的基础,而MoE通过引入专家机制,进一步突破了性能和效率的瓶颈。
尽管MoE在训练中面临专家均衡性等挑战,但通过路由器优化和容量限制等解决方案,它已成为构建更强大语言模型的重要工具。未来,随着技术的不断进步,MoE有望在更多场景中大放异彩,推动NLP领域迈向新的高度。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)