一文读懂大模型检索知识生成(RAG)
本文系统介绍了检索增强生成(RAG)技术框架。RAG通过将大规模语言模型与外部知识检索相结合,有效解决模型幻觉和知识更新问题。文章详细阐述了RAG的运作原理、应用流程,以及与模型微调的优缺点对比。重点介绍了五种语料分块方法(固定大小、语义、递归、文档结构、基于大模型),词嵌入技术、向量数据库的应用,以及rerank模型在结果重排序中的作用。RAG技术实现了语言模型与动态知识库的协同融合,在保持模型
目录
一、RAG基本介绍
RAG (Retrieval Augmented Generation,检索增强生成)是一种将大规模语言模型(LLM)与外部知识源的检索相结合,以改进问答能力的工程框架。它使用来自私有或专有数据源的信息来辅助文本生成,从而弥补LLM的局限性,特别是在解决幻觉问题和提升时效性方面。
检索负责从知识库中快速准确获取信息,生成根据检索结果和用户输入生成期望输出,增强则对信息进行额外处理以提高输出质量和多样性。
- 检索(Retrieval):负责从知识库中快速准确找到与输入查询相关的信息,通过关键词、向量或深度学习等方法提高检索效率。
- 生成(Generation):根据检索到的信息和用户输入生成符合期望的输出,采用模板、序列到序列模型或大型语言模型等技术,并进行后处理和微调以提高生成质量。
- 增强(Augmentation):在生成前后对信息进行额外处理或补充,通过知识增强、多样性增强和后处理增强等手段提高输出的质量和多样性。
二、RAG运作原理
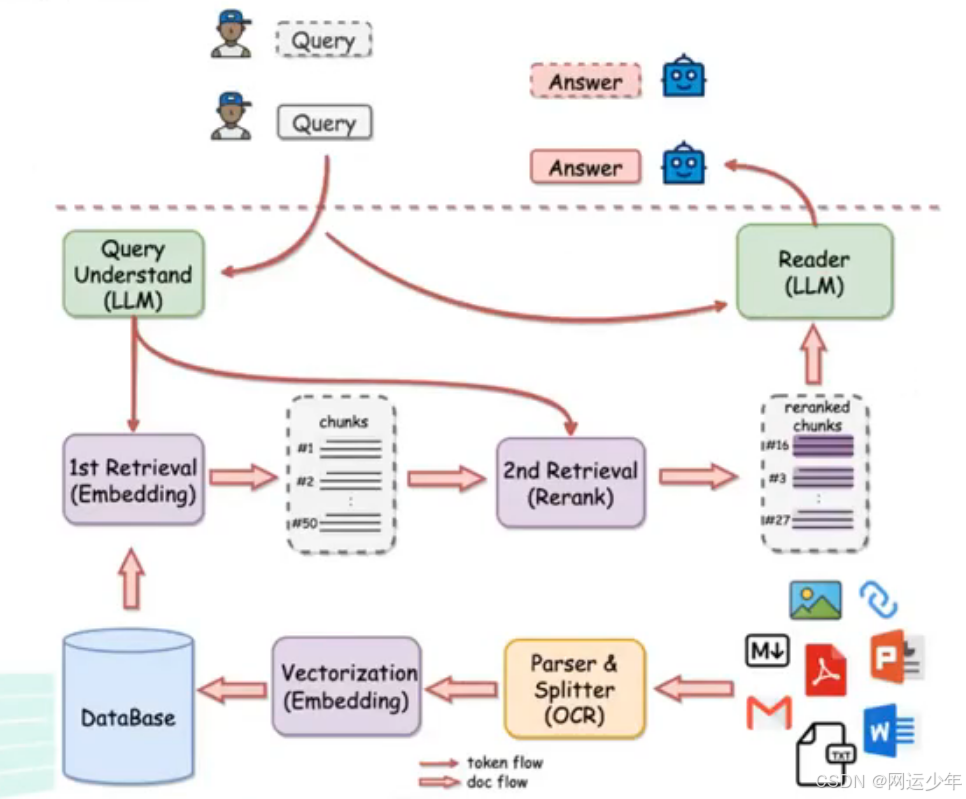
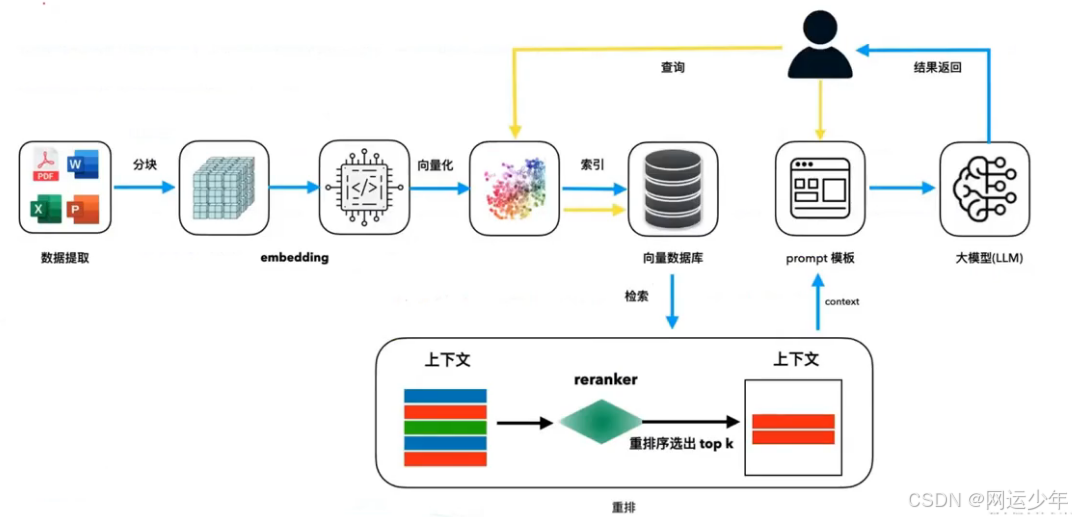 上图所示,RAG运作原理:
上图所示,RAG运作原理:
1、先提取数据,比如提取到一个PDF,需要对它的语料进行split(文本分割),然后通过词嵌入(embedding)模型将文本向量化,并以索引的方式加入到向量数据库。
2、用户提问问题,比如:“清华大学哪年成立的?”,然后会对问题进行文本向量化。
3、对向量化后的问题进行检索(相似度查找),检索出来的结果进行rerank(重排序)。
以上,重点需要了解:1、语料块是如何分块的?2、词嵌入模型是如何词嵌入的?3、有哪些常见的向量数据库?4、检索出来的结果如何进行rerank?
检索增强生成是一种利用来自私有或专有数据源的信息来补充文本生成的技术。
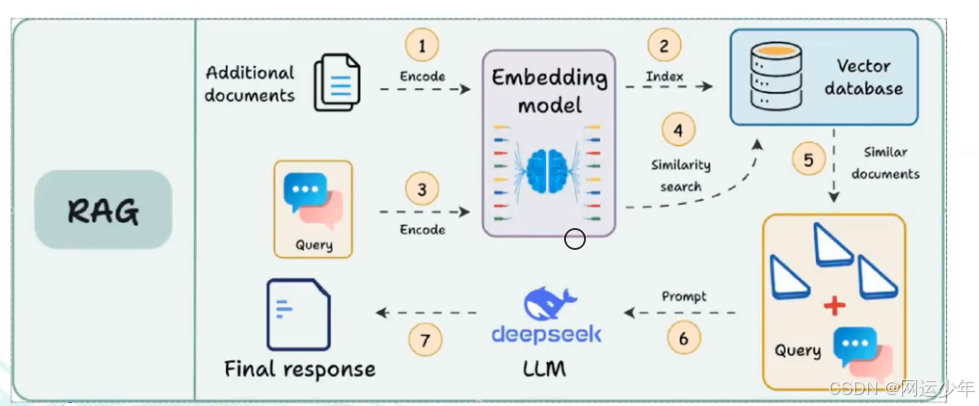
如上图所示,整个RAG过程中会主要用到两模一库,即两个模型:embedding模型(词嵌入模型,也叫向量转换模型)、rerank模型;一库:向量数据库。
RAG能让模型持续更新知识,并整合特定领域的信息,从而实现LLMs内在知识与外部动态数据库的协同融合。
知识图谱与向量数据库结合,是因为随着语料的丰富,需要图谱介入建立知识的关联度。
三、RAG与模型微调的对比
3.1、优缺点对比
| 模型微调 | RAG | |
| 优点 | 针对特定任务调整预训练模型。优点是可针对特定任务优化; | 结合检索统和生成模型。优点是能利用最新信息,提高答案质量,具有更好的可解释性和适应性; |
| 缺点 | 但缺点是更新成本高(算力+数据语料+周期性长),对新信息适应性较差; | 是可能面临检索质量问题和曾加额外计算资源需求; |
一般来说,二者互补,大企业都是周期性的进行模型微调,短期性的进行RAG更新。
3.2、特性对比
| 特性 | RAG技术 | 模型微调 |
| 知识更新 | 实时更新检索库,适合动态数据,无需频繁重训 | 存储静态信息,更新知识需要重新训练 |
| 外部知识 | 高效利用外部资源,适合各类数据库 | 可对齐外部知识,但对动态数据源不够灵活 |
| 数据处理 | 数据处理需求低 | 需构建高质量数据集,数据限制可能影响性能 |
| 模型定制化 | 专注于信息检索和整合,定制化程度低 | 可定制行为,风格及领域知识 |
| 可解释性 | 答案可追溯,解释性高 | 解释性相对低 |
| 计算资源 | 需要支持检索的计算资源,维护外部数据源 | 需要训练数据集和微调资源 |
| 延迟要求 | 数据检索可能增加延迟 | 微调后的模型反应更快 |
| 减少幻觉 | 基于实际数据,幻觉减少 | 通过特定域训练可减少幻觉,但仍然有限 |
| 道德和隐私 | 处理外部文本数据时需要考虑隐私和道德问题 | 训练数据的敏感内容可能引发隐私问题 |
四、RAG的应用流程
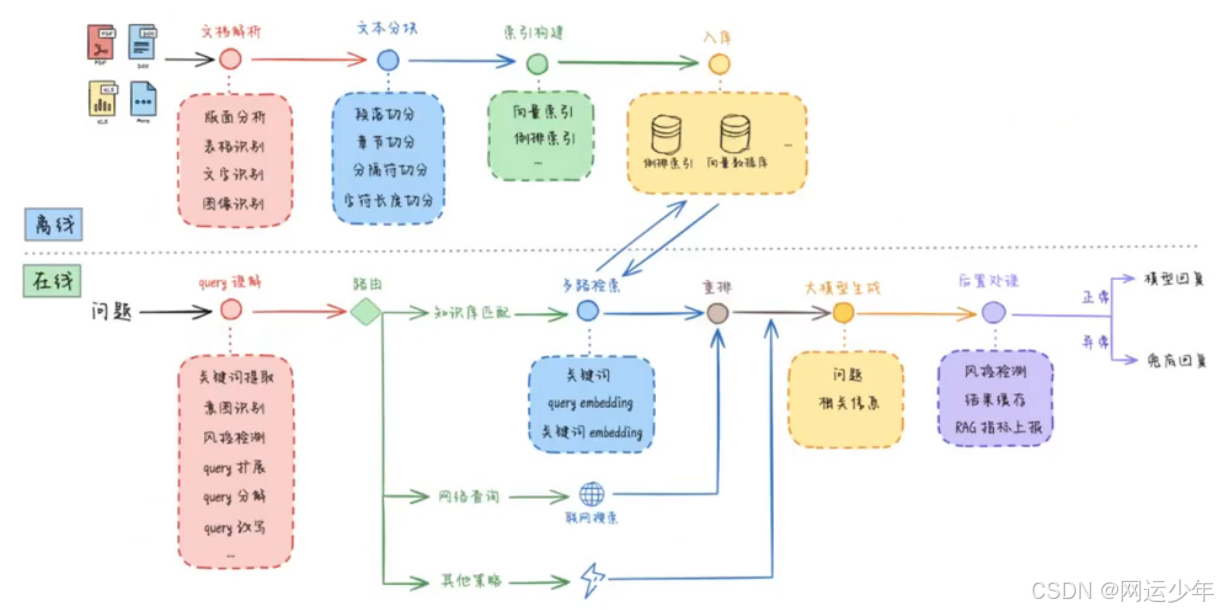
拿到一篇文章后,需要先做文档解析,比如识别文档的版面、表格、文字、图像;然后按照一定的标准对文档进行切分;其次,为分块添加索引;最后,入库。
用户发起提问,开始知识库检索匹配关键词,检索出符合条件的答案top-K(按相似度排序),然后将top-K的答案通过rerank模型转换成top-P(按概率排序),最后按照top-P的检索结果生成答案。
RAG 数据处理流程:
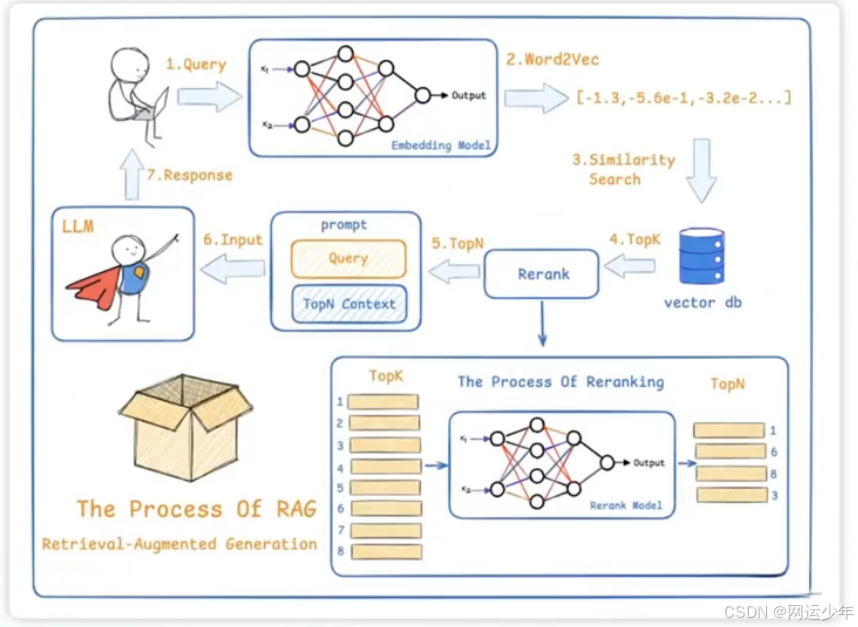
将用户提出的问题向量化,随后对问题向量与数据库中的向量进行相似度查找(余弦相似度或欧氏距离),查找完的排名结果,比如取K=3,取前三个,然后通过rerank模型转换成概率排名,最后输出。
五、语料分块方法
5.1、固定大小分块

1、按预设的字符数、单词数或Token数,把文本切成均匀的片段。
2、overlap:允许溢出。举个例子(图里的蓝色重叠部分):比如设定每块500字,那前一块的最后100字和下一块的前 100 字会有重叠。
优点:实现起来简单,而且所有块大小一致,方便批量处理。
缺点:容易切断句子或完整的意思,重要信息可能被拆到两个块里,比如一句话前半句在这块,后半句在那块。
5.2、语义分块
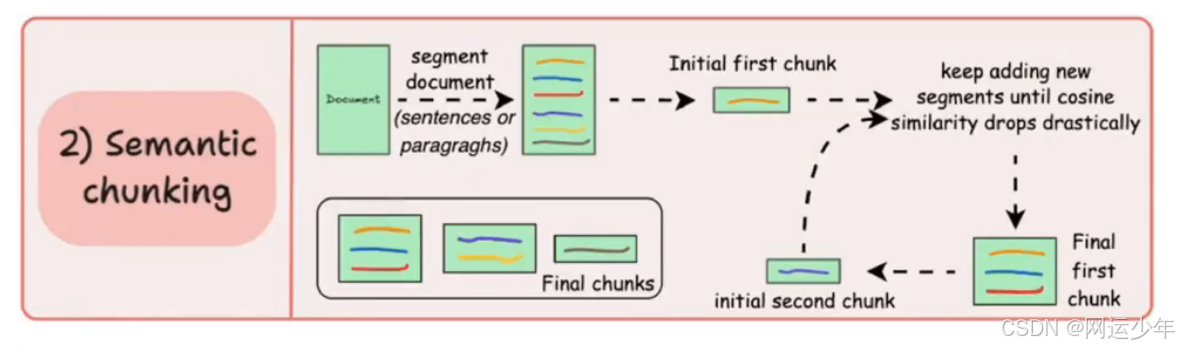
按有意义的单元来分段,比如句子、段落或主题章节。具体怎么做呢?
1、先给每个段落生成嵌入向量,然后计算相邻段落的余弦相似度;
2、如果第一段和第二段的相似度很高,就把它们合并成一个块;
3、直到遇到相似度明显下降的段落,就新开一个块。
优点:保持语言的自然流畅,每个块都包含完整的观点,这样检索时更准,LLM生成的回答也更连贯相关。
缺点:需要设定一个相似度阈值,但不同文档的阈值可能不一样,得反复调参。
5.3、递归分块
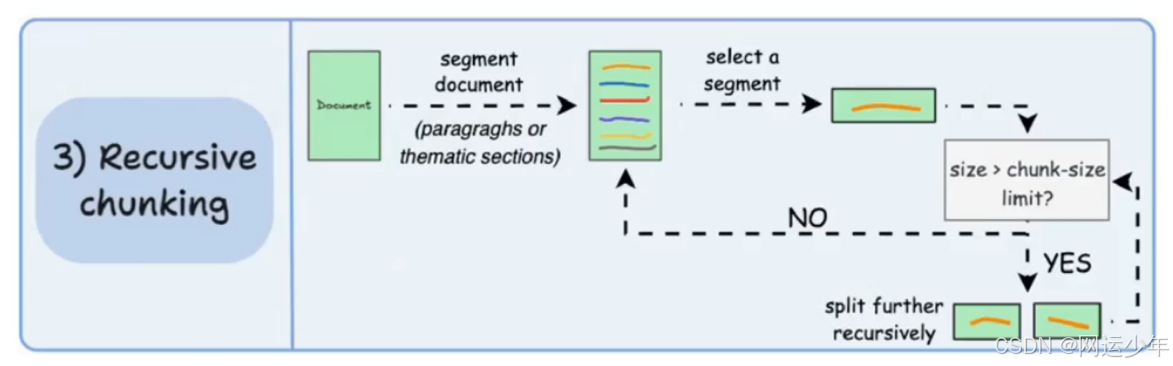
1、先按文档的天然分隔符(比如段落、章节)初步分块,然后检查每个块的大小;
2、如果超过预设的最大块大小,就进一步拆分成更小的块;
3、如果大小合适,就保持不变。
优点:和语义分块类似,能保留完整语义。
缺点:实现起来更复杂,计算量也更大,因为要多一步“检查是否需要拆分”的逻辑。
5.4、基于文档结构的分块
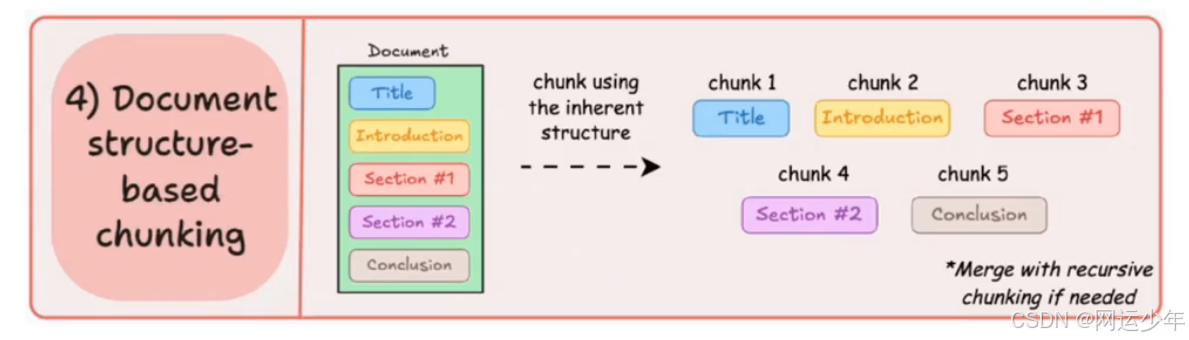
1、利用文档本身的结构来划分块,比如标题、章节、子标题等。比如:
2、一个一级标题下的所有内容作为一个块;
3、每个表格或图表的说明文字单独成块。
优点:贴合文档的逻辑结构,块的内容更完整。
缺点:依赖文档有清晰的结构,如果遇到结构混乱的文档(比如纯文本无标题),就不好用了。另外,块的长度可能不均匀,有些块可能超过模型的Token限制,这时候可以结合递归分块一起用。
5.5、基于大模型的分块

直接让 LLM 帮忙生成语义独立、有意义的块。比如给LLM 一个提示:“请将以下文本分成每个块约500 字的语义完整段落,确保每个块包含独立的主题。
优点:语义准确性最高,LLM能理解上下文,比前四种基于规则的方法更智能。
缺点:计算成本最贵,每次分块都要调用LLM,而且LLM 本身也有上下文窗口限制,处理长文档可能需要多次调用。
六、词嵌入(embedding)
Embedding 的本质是一种将高维稀疏数据转换为低维稠密向量的技术,通过这种转换,能够捕捉数据中的语义或特征关系。
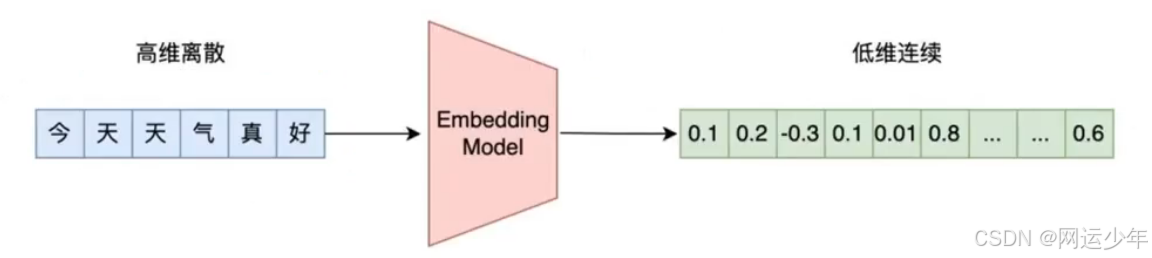
Embedding 可以捕捉到数据中的潜在关系,很多文本处理任务可以在文本相似性的基础上进行构建,比如:
内容审核:衡量社交媒体消息与已知的滥用案例的相似度有多高;
意图分析:识别用户的消息与已知意图的例子中哪个最为接近;
情感分析:衡量文本与已知情感标签的以度,从而判断情感倾向;
推荐系统:计算用户和物品的相似度,从而为用户推荐可能感兴趣的物品。
七、向量数据库
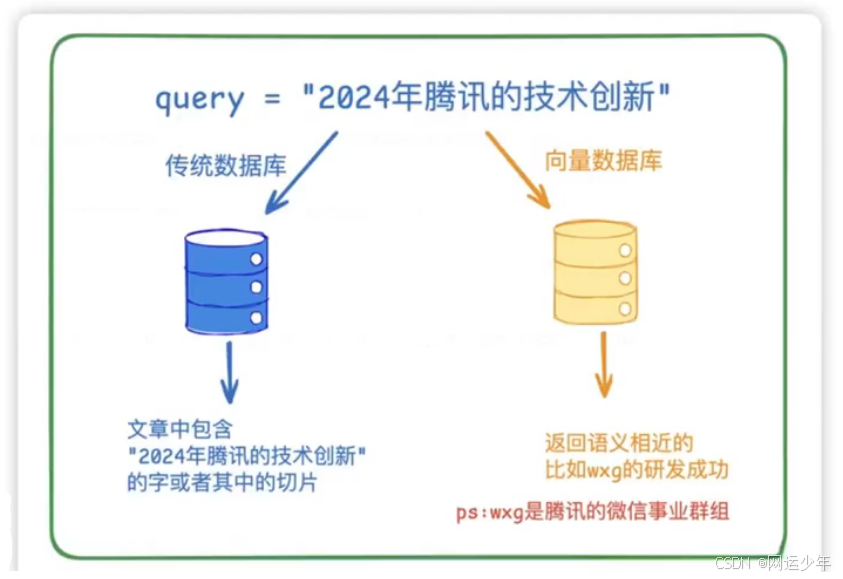
向量数据库是通过存储文本的向量化表示,支持基于语义相似度的快速检索,解决了传统关键词匹配无法捕捉上下文关联的问题。
传统数据库是精确匹配,向量数据库是相似度匹配。
八、rerank模型
ReRanker模型是对RAG检索返回的结果进行重新排序的模型。ReRanker模型在RAG Pipeline中扮演着第二阶段的角色,即在初始检索步骤之后,对检索出的文档块chunks进行重新排序,以确保相关的文档块优先被传递给LLM进行处理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)