【AI】为什么 Transformer 用“位置编码 + 词向量”,而不是相乘或拼接?
Transformer架构中位置编码(PE)采用"相加"而非其他方式融合词向量的原因可概括为:1)保持语义与位置信息的可分离性;2)不破坏词向量原有分布;3)天然兼容注意力计算;4)计算高效;5)经过实践验证。其本质是注入位置信息而不干扰语义表示,这一设计理念在RoPE等现代编码方案中得以延续。对于RAG开发者而言,理解PE原理有助于优化文档切分、检索和生成效果。
近年来,随着大语言模型(LLM)的爆发式发展,Transformer 架构已成为 AI 领域的基石。而在其设计中,有一个看似简单却极为精妙的细节:
为什么位置编码是“加”到词向量上,而不是“乘”、“拼接”或“除”?
这个问题初看不起眼,但深入思考后,你会发现它背后隐藏着 对向量空间、模型学习机制和工程效率的深刻权衡。
作为一名 RAG(Retrieval-Augmented Generation)系统开发者,我在开发时,反复与词向量、位置编码、注意力机制打交道。今天,我想从工程实践 + 几何直觉 + 数学逻辑三个维度,带你彻底搞懂这个经典设计。
一、问题背景:Transformer 为何需要位置编码?
Transformer 模型本身是无序的——它把输入序列当作一个集合,而不是有序序列。这意味着:
"我爱你" 和 "你爱我"在原始模型眼中,可能没有本质区别。
为了解决这个问题,我们必须引入位置信息。于是,Vaswani 等人在 2017 年的《Attention is All You Need》中提出了 位置编码(Positional Encoding),并将其与词向量相加作为最终输入。
但为什么是“加”?
二、为什么不选其他方式?对比分析
我们先来看看其他融合方式的问题:
| 融合方式 | 问题 |
|---|---|
| 相乘(Hadamard Product) | 会改变每个维度的尺度,可能导致语义被扭曲或压制 |
| 拼接(Concatenation) | 维度翻倍 → 参数量爆炸,计算开销大,需额外降维 |
| 相除 | 数值不稳定,易出现 NaN 或无穷大,不适合神经网络训练 |
| 位置作为独立输入 | 增加模型复杂度,难以与注意力机制自然融合 |
相比之下,“相加”显得格外简洁优雅。
三、为什么“相加”是最优解?五大核心原因
1. 信息可分离性:语义与位置“各走各的路”
这是最核心的原因。
设想:
- 词向量 w 携带“语义信息”
- 位置编码
表示“第 i 个位置”
如果它们在高维空间中近似正交(即 ≈0),那么:
这个新向量仍然可以“拆解”为两个独立部分。模型在训练过程中,可以通过注意力机制学会:
- 关注 w 部分来理解“这个词是什么意思”
- 关注 pi 部分来判断“它在句子中的位置”
这就像你在地图上给每个城市加一个小箭头,箭头方向代表顺序,但城市本身不变。
这正是我在开发 RAG 系统时的感受:检索到的文档片段语义不能被位置信息干扰,而“相加”完美实现了这一点。
2. 保持向量模长稳定,不破坏语义分布
词向量通常经过预训练(如 BERT、Qwen),已经形成了稳定的语义空间。
- 相加:小幅偏移,不改变整体分布
- 相乘:可能放大或归零某些维度,导致语义失真
在 RAG 系统中,我们经常将知识库文本切片后向量化存入 Milvus,如果位置编码改变了原始语义,检索精度就会下降。
3. 天然兼容注意力机制
Transformer 的注意力计算依赖于 QKT,其中:
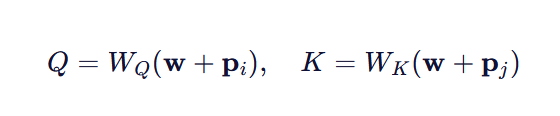
展开后,QKTQKT 会自动包含四种交互:
- 语义 × 语义
- 语义 × 位置
- 位置 × 语义
- 位置 × 位置
模型可以自主学习如何利用这些交互,比如在长距离依赖时更关注位置差异。
这在 RAG 的长文本检索中尤为重要——模型需要知道“关键信息出现在段落开头还是结尾”。
4. 计算高效,工程友好
- 不增加维度
- 不引入额外参数(如果是固定正弦编码)
- 易于实现和部署
在生产环境中,我们使用 LangChain 构建 RAG 流程时,每一步都要考虑性能。而“相加”这种轻量级操作,使得整个 pipeline 更加高效。
5. 已被广泛验证有效
从最初的正弦编码,到 BERT 的可学习位置编码,再到 LLaMA/Qwen 使用的 RoPE(旋转位置编码),“融合位置信息”的思想始终存在,只是形式在进化。
“相加”虽不是唯一方式(RoPE 是旋转),但其核心理念——优雅地注入位置信息而不破坏语义——始终未变。
四、现代演进:从“相加”到“旋转”(RoPE)
值得一提的是,当前主流大模型(如 Qwen、LLaMA)已采用 RoPE(Rotary Position Embedding)。
它不再是简单的“相加”,而是通过旋转向量来编码位置:
qm=q∘eimθqm=q∘eimθ
但这依然延续了“相加”的思想:
- 不改变向量模长
- 显式建模相对位置
- 支持超长上下文
可以说,RoPE 是“相加”理念的升级版,更加数学优美,也更适合长文本 RAG 场景。
五、对 RAG 开发者的启示
作为一名 RAG 工程师,理解位置编码的设计哲学,能帮助我们更好地:
- 设计文档切分策略:确保切片不破坏语义连贯性
- 优化检索效果:利用位置信息提升 top-k 文本的相关性
- 调试生成结果:当模型“记错顺序”时,反思是否位置信息未被充分学习
- 选择合适模型:优先选用支持长上下文(如 RoPE)的大模型
六、总结
| 为什么用“相加”? | 说明 |
|---|---|
| ✅ 信息可分离 | 语义与位置可在向量空间中解耦 |
| ✅ 模长稳定 | 不破坏预训练词向量分布 |
| ✅ 注意力友好 | 自动支持多种交互模式 |
| ✅ 计算高效 | 无需增加维度或参数 |
| ✅ 实验验证 | 被所有主流模型采用 |
“简单,才是最高级的复杂。”
Transformer 中“词向量 + 位置编码”的设计,正是这一哲学的完美体现。
喜欢这篇文章?欢迎点赞、收藏、分享!
有问题?欢迎在评论区留言讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)