大数据日志采集最佳实践:从 SDK 埋点到 Flume + Kafka 高效入仓!
本文系统介绍了企业级日志采集全链路体系,从业务埋点设计到数据入仓的完整流程。核心内容包括:1)埋点规范与版本控制的重要性;2)日志采集典型架构(前端/服务日志→Agent→Kafka→存储计算);3)关键组件优化(Flume性能调优、Kafka分区设计);4)实时/离线双通道入仓策略;5)全链路质量监控与治理方案。文章强调日志采集是数据价值挖掘的基础,需要构建稳定高效的数据通道,为后续分析应用提供
🚀 日志采集全流程揭秘:从埋点到数据入仓,一文吃透大数据采集体系!
📊 在所有大数据体系中,“采集”是整个数据链路的起点。
没有稳定高效的日志采集,就谈不上精准分析、智能推荐或实时监控。
本文将带你从业务埋点出发,穿透日志采集、传输、落仓全流程,构建一个真正企业级的数据采集体系。
一、从业务到数据:为什么“埋点”才是一切的开始?
日志采集的起点,不是 Kafka,不是 Flume,而是——埋点设计。
一个优秀的数据采集系统,必须建立在清晰的业务场景与埋点规范之上:
| 埋点类型 | 示例 | 采集目标 |
|---|---|---|
| 页面曝光 | 首页曝光、详情页曝光 | 用户行为分析 |
| 按钮点击 | “立即购买”、“收藏” | 转化率、路径分析 |
| 接口调用 | 登录接口、下单接口 | 服务性能、异常监控 |
| 异常日志 | 报错、卡顿、崩溃 | 稳定性监控 |
🧠 经验总结:
埋点要“有度”——既不能全埋点导致日志爆炸,也不能少埋点导致分析失真。
在大型项目中,通常会有埋点规范文档 + 埋点版本控制系统(如 Git + 埋点配置 JSON)。
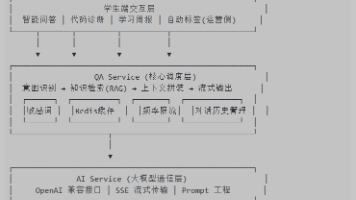
二、日志采集链路:从前端到数据中台的全流程
让我们看一眼企业级日志流转全景图👇
前端/后端应用 → 日志Agent → Flume/Kafka → HDFS/Hive → DWD/DWS/ADS
各环节的职责如下:
| 环节 | 工具/框架 | 职责 |
|---|---|---|
| 应用层 | SDK / Nginx 日志 | 日志采集入口 |
| Agent 层 | Flume / Filebeat / Logstash | 数据传输与缓冲 |
| 消息队列层 | Kafka / Pulsar | 异步解耦,高可用传输 |
| 存储层 | HDFS / Hive / HBase | 数据落仓与清洗 |
| 计算层 | Spark / Flink | 实时与离线计算 |
| 应用层 | Superset / StarRocks / BI 系统 | 数据消费与可视化 |
📦 实战建议:
-
前端日志 → Filebeat + Kafka
-
服务日志 → Flume + Kafka
-
实时业务 → Flink Stream
-
离线入仓 → Spark / Hive
三、Flume 在日志采集中的角色与优化
Flume 仍是企业日志采集中最稳定的老将之一,尤其在批量文件或日志流入 HDFS 时表现出色。
📘 Flume 架构简图
Source → Channel → Sink-
Source:读取数据(如 exec、avro、http)
-
Channel:缓存数据(memory / file)
-
Sink:写出数据(HDFS / Kafka / HBase)
⚙️ 性能优化要点
| 优化点 | 说明 |
|---|---|
| Channel 选择 | 高频日志选 memory,防止 IO 阻塞 |
| Sink 批量提交 | 调整 hdfs.batchSize 提高写入效率 |
| 异常重试 | 开启 failoverSinkProcessor 提高容错 |
| 监控指标 | 用 Ganglia/Prometheus 监控 event 数量与延迟 |
四、Kafka:日志流的“心脏”
Kafka 是日志采集体系的中枢。
它让数据生产与消费彻底解耦,并为实时与离线提供统一通道。
✅ Topic 设计建议
| 业务模块 | Topic 命名 | 分区数 | 备注 |
|---|---|---|---|
| 用户行为 | log_user_action | 6 | 高并发推荐类业务 |
| 系统监控 | log_system_event | 3 | 系统稳定性分析 |
| 交易日志 | log_order | 8 | 订单流实时处理 |
🎯 最佳实践:
-
分区数量 ≈ 集群 broker 数量 × 2~3
-
重要 Topic 启用多副本(replication.factor ≥ 2)
-
设置合理的
retention.ms,避免磁盘膨胀
五、入仓策略:实时 + 离线双通道
日志数据采集完成后,接下来就是入仓。
通常有两条主线:
🕐 离线入仓
Kafka → HDFS → Hive ODS → DW/ADS由 Spark / Hive 定时任务批量入库,常用于日报、月报类统计。
⚡ 实时入仓
Kafka → Flink → StarRocks / ClickHouse / Druid常用于实时大屏、告警系统、运营分析。
🧩 实践案例:
-
实时计算用户点击量、转化率
-
离线生成用户画像标签
-
实时异常检测(接口错误率 > 阈值告警)
六、日志采集全链路治理:质量、延迟与监控
日志采集不是“一次性工程”,而是持续治理体系。
🔍 常见问题
-
日志丢失 / 重复
-
Topic 堆积 / 消费延迟
-
Hive 表数据不对齐
-
异常日志量爆发(如死循环打印)
💡 治理手段
| 方向 | 工具/方案 |
|---|---|
| 数据质量 | 定期比对生产与消费数量 |
| 延迟监控 | Kafka Offset Lag + Flink Metrics |
| 采集可观测性 | Prometheus + Grafana |
| 告警机制 | 自定义钉钉/企业微信告警 |
七、结语:从“埋点”到“价值”,数据采集的终极目标
日志采集的意义,不只是“把数据送进仓库”,
而是让企业从每一个用户点击中洞察趋势,从每一条日志中发现问题。
构建一条高质量日志链路,
就是在为整个企业的数据智能体系铺设“信息高速公路”。
📌 如果你觉得这篇文章对你有所帮助,欢迎点赞 👍、收藏 ⭐、关注我获取更多实战经验分享!
如需交流具体项目实践,也欢迎留言评论

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)