7 大模型的位置编码
特性绝对位置编码学习型位置编码相对位置编码旋转位置编码 (RoPE)位置信息类型绝对位置绝对位置相对位置相对位置实现难度简单中等较复杂较复杂计算效率高中中高适应序列长度固定长度,泛化较差固定长度,泛化较差动态长度,泛化较好动态长度,泛化较好应用场景短文本,中短文本短文本,中短文本长文本,复杂任务长文本,复杂任务RoPE和相对位置编码在处理长文本上表现出色,而学习型位置编码更适合较固定长度的序列。
为了解决注意力机制中缺失时间序列的相对位置关系的信息,因此需要引入位置编码。
位置编码方法在Transformer模型中至关重要,几种常见的编码方法包括绝对位置编码(Absolute Position Embedding)、相对位置编码(Relative Position Encoding)、旋转位置编码(RoPE),以及一些最新的改进方法,如Learnable Position Embedding。这些编码方式在效果、实现方式和应用场景上各有差异。下面为你进行对比。
1. 绝对位置编码(Absolute Position Encoding)
- 定义:绝对位置编码是指为每个位置(例如句子中的每个词)赋予一个唯一的编码,通常通过正弦和余弦函数生成,类似于波形。
- 实现:Transformer原始论文中提出的正弦余弦位置编码公式:
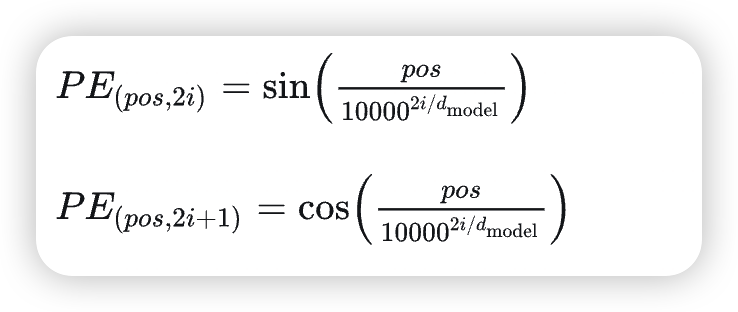
- 优点:
- 简单易实现,且对长度变化较小的序列有良好效果。
- 编码方式是静态的,不需要额外参数。
- 编码仅与位置序号相关。
- 缺点:
- 只能表示绝对位置,无法有效表达相对位置,因此在捕捉词之间的关系方面有一定局限。
- 应用场景:适用于中短文本,适合需要固定长度或较少依赖长距离依赖的任务。
为什么使用sin、cos 函数?而不是其他的函数。
- 在Transformer模型中,使用正弦(sin)和余弦(cos)函数作为位置编码的核心原因是为了让模型既能捕捉绝对位置信息,又能高效学习相对位置关系,同时支持处理任意长度的序列。
- 对于任意固定的偏移量 k ,位置 pos + k 的编码可以表示为位置 pos 编码的 线性组合。

-
正弦和余弦函数的输出范围是 [-1, 1],与词嵌入(通常经过归一化)的数值范围匹配,避免引入尺度差异。
为什不具备外推性?
训练时模型只见到pos < L_train的位置
测试时pos > L_train的位置:
1 高频维度:角度值超出训练范围,模型从未见过
2 低频维度:角度值变化极小,无法提供有效位置信息。

2. 学习型位置编码(Learnable Position Embedding)
- 定义:学习型位置编码将位置编码看作可学习的向量,并随模型训练而动态更新。
- 实现:在模型初始化时,为每个可能的位置赋予一个随机向量,并让模型在训练中通过梯度下降优化这些向量。比如:BERT。
- 优点:
- 不依赖特定数学函数,因此在复杂任务中可以学习到更适合任务的位置信息。
- 缺点:
- 随着序列长度增加,可能需要更多的参数来表示不同位置,计算开销较大。
- 泛化能力有限,不适用于长度变化明显的序列。
- 应用场景:用于处理较固定长度的序列或更小的数据集。
3. 相对位置编码(Relative Position Encoding)
- 定义:相对位置编码通过编码相对位置(例如两个词的相对距离)而非绝对位置,增强模型对词序关系的理解。
- 实现:在Attention机制中加入相对位置信息,使模型在计算词间关联时能够考虑相对距离。
- 优点:
- 更好地捕捉词序关系,尤其适用于长文本或具有复杂上下文关系的任务。
- 能够处理动态长度序列,具有较好的泛化能力。
- 缺点:
- 实现上比绝对位置编码更复杂,且需要特定调整。
- 应用场景:长文本处理、复杂上下文依赖的任务(如问答系统)。
相对位置位置不是关注标记在句子中的绝对位置,而是关注标记对之间的距离。该方法不会直接向词向量添加位置向量。而是改变了注意力机制以纳入相对位置信息。
最经典得案例就是T5(Text-to-Text Transfer Transformer)是一种利用相对位置嵌入的著名模型。T5 引入了一种处理位置信息的微妙方式:
位置偏移的偏差: T5 使用偏差(浮点数)来表示每个可能的位置偏移。例如,偏差 B1 可能表示任意两个相距一个位置的标记之间的相对距离,无论它们在句子中的绝对位置如何。
自注意力层中的集成: 该相对位置偏差矩阵被添加到自注意力层中的查询矩阵和关键矩阵的乘积中。这确保了相同相对距离的标记始终由相同的偏差表示,无论它们在序列中的位置如何。
可扩展性: 该方法的一个显着优点是其可扩展性。它可以扩展到任意长的序列,这比绝对位置嵌入有明显的优势。
4. 旋转位置编码(RoPE - Rotary Position Embedding),不需要大模型学习
RoPE的核心是将绝对位置信息转化为向量的旋转角度,使得自注意力机制中的点积运算能够自然携带相对位置信息。
- 定义:RoPE利用 旋转变换 在二维空间中表达 相对位置,使模型能够理解词的相对顺序。直接建模词与词之间的相对距离(如 m-n ),而非绝对位置,更符合语言建模的直觉(例如"动词与主语的依赖关系与绝对位置无关")。
- 实现:对每个位置的词嵌入进行旋转操作,这种旋转角度随着位置变化,使得词之间的相对位置关系更加明确。将位置信息融入词向量本身,通过旋转矩阵变换 Query 和 Key。
- 优点:
- 相对位置敏感,对长文本和复杂语言模式的理解更佳。
- 计算效率较高,适合需要长距离依赖的任务。
- 缺点:
- 实现上较为复杂,尤其在不同模型架构中的适配需要调整。
- 应用场景:长序列处理、大型生成模型(如GPT系列)等对长距离关系敏感的任务。
这里想展开说一下RoPE,这个在面试里经常问,和绝对位置编码拿来比较。
RoPE:旋转编码
Roformer: Enhanced Transformer With Rotary Position Embedding
这个写的很好,把公式推的很清楚:
https://blog.csdn.net/weixin_43378396/article/details/138977299
从里面拿一张公式推的图,基本能讲清楚“相对位置”的概念:

5. 其他改进方法
- 近年来,随着Transformer模型的不断优化,还出现了一些新颖的编码方式,如T5中的Position-Bias Encoding,即利用偏差矩阵在Attention中加入相对位置信息,但不会显式对词进行编码。
对比总结
| 特性 | 绝对位置编码 | 学习型位置编码 | 相对位置编码 | 旋转位置编码 (RoPE) |
|---|---|---|---|---|
| 位置信息类型 | 绝对位置 | 绝对位置 | 相对位置 | 相对位置 |
| 实现难度 | 简单 | 中等 | 较复杂 | 较复杂 |
| 计算效率 | 高 | 中 | 中 | 高 |
| 适应序列长度 | 固定长度,泛化较差 | 固定长度,泛化较差 | 动态长度,泛化较好 | 动态长度,泛化较好 |
| 应用场景 | 短文本,中短文本 | 短文本,中短文本 | 长文本,复杂任务 | 长文本,复杂任务 |
RoPE和相对位置编码在处理长文本上表现出色,而学习型位置编码更适合较固定长度的序列。绝对位置编码虽然简单,但在应对复杂的语言依赖时可能显得不足。选择编码方式通常需要根据任务和模型复杂度决定。
一些可能常问的面试题:
1. 位置编码的介绍(包括RoPE和NTK系列位置编码)
位置编码在Transformer模型中起到了非常重要的作用,因为Transformer模型本身没有内置的顺序信息。而自然语言具有明显的词序,因此在模型输入中加入位置信息就显得尤为重要。几种位置编码方法在位置表示方式上各有不同的特点:
- 绝对位置编码:最早在Transformer中使用的正弦-余弦位置编码,是一种直接编码每个词的绝对位置。这样可以为每个位置生成唯一的编码,模型在处理时可以“识别”词的位置,但不能直接表示词之间的相对距离。
- 相对位置编码(Relative Position Encoding):该方法旨在为模型提供词与词之间的相对位置(如距离和方向)。例如,若两个词相隔两个位置,它们会得到相同的相对位置编码。相对位置编码在处理长序列时,尤其是在需要关注前后词序的任务中效果更佳。
- 旋转位置编码(RoPE):RoPE使用旋转变换来编码相对位置,它不是直接依赖绝对位置,而是通过对每个词向量按特定角度旋转来表示不同位置的信息。这样,两个词之间的相对位置关系可以通过旋转角度反映出来。
- NTK系列位置编码:NTK(Neural Tangent Kernel)位置编码是近年来的一类改进技术,通常用于使模型能够适应更长的输入序列,并在高效表示位置方面做了优化。这类编码方法倾向于保留模型的整体表达能力,并延长有效输入的序列长度,适合需要处理非常长文本的场景。
2. RoPE 为什么能够表示相对位置?
RoPE的关键在于旋转变换的数学特性,它能够让模型通过旋转角度来理解词与词之间的相对位置关系。具体原因如下:
- 旋转角度随位置变化:RoPE为每个位置设计了一个特定的旋转角度,这个角度可以随着位置的变化而增加。假设两个词在序列中的位置分别为 p 和 q,它们在RoPE编码后的位置关系可以通过它们的旋转角度的差值来体现。角度差值自然反映了这两个词的距离。
- 旋转矩阵的相对性:RoPE中引入的旋转矩阵性质上是相对的。换句话说,词与词之间的相对位置信息在旋转编码的过程中保留了相对角度的特征。因此,RoPE不仅捕捉到每个词的绝对位置,还能使模型识别出词之间的相对位置。
- 自注意力机制的相对敏感性:在Transformer模型的自注意力机制中,RoPE编码后的向量通过Attention的点积操作,这使得Attention可以“注意”到词的相对位置关系,因为点积的值受相对旋转角度影响。
简单来说,RoPE在不同位置应用不同的旋转角度,通过这种旋转的累积差异,模型能够间接获取词的相对位置。
3. RoPE 是如何作用的?
RoPE在模型中主要通过对输入词嵌入进行旋转变换来作用。其具体过程如下:
- 输入词嵌入:假设输入一个词嵌入向量 f{x},维度为 d,RoPE会将其分解为多个二维向量对。
- 构建旋转矩阵:根据词的绝对位置 p,给每个二维向量对应用一个旋转矩阵。这一旋转矩阵的角度是 p \cdot \theta_0(其中 \theta_0 是基准角度),这个旋转角度随着位置 p 增加。
- 旋转变换的实现:假设我们取词嵌入向量的第 2k 和第 2k+1 维度作为一个二维向量对,将其表示为复数形式 z = x_{2k} + i x_{2k+1}。然后,对这个复数应用旋转,得到: 或者写为矩阵形式: 这样,每一个二维向量对都被旋转了特定角度,编码了该词的位置信息。
- 与自注意力机制结合:经过RoPE处理的词嵌入向量会送入自注意力机制,Attention机制在计算时会对这些旋转过的向量进行点积,这样每个词对的相对旋转角度直接影响了Attention分数。因此,模型能够利用旋转角度的差值来“关注”词与词的相对位置关系,从而使模型的表现更好。

好的!我们通过一个**具体数值例子**逐步拆解RoPE的实现过程,帮助直观理解其如何编码位置信息。
---
### **示例设定**
- **词向量维度**:`d = 4`(实际模型通常为768/1024等,此处简化)
- **位置**:`m = 2`(Query的位置)和 `n = 5`(Key的位置)
- **词向量**(随机初始化):
- Query向量:`q = [0.1, 0.2, 0.3, 0.4]`
- Key向量:`k = [0.5, 0.6, 0.7, 0.8]`
- **频率参数**:`θ_i = 10000^(-2i/d)`,其中 `i` 是维度组的索引(这里 `d=4`,所以 `i=0,1`)
---
### **步骤1:将词向量分组成复数**
将 `q` 和 `k` 的维度两两分组,视为复数:
- **Query向量分组**:
- 组0(i=0):`q0 = 0.1 + 0.2j`
- 组1(i=1):`q1 = 0.3 + 0.4j`
- **Key向量分组**:
- 组0(i=0):`k0 = 0.5 + 0.6j`
- 组1(i=1):`k1 = 0.7 + 0.8j`
---
### **步骤2:计算旋转角度**
根据位置 `m=2` 和 `n=5`,计算每组复数对应的旋转角度:
- **频率计算**:
- 组0(i=0):`θ_0 = 10000^(-0/4) = 1`
- 组1(i=1):`θ_1 = 10000^(-2/4) = 1/100`(简化计算,实际为 `10000^(-0.5) ≈ 0.01`)
- **旋转角度**:
- Query在位置2:
- 组0旋转角度:`2 * θ_0 = 2 * 1 = 2 弧度`
- 组1旋转角度:`2 * θ_1 = 2 * 0.01 = 0.02 弧度`
- Key在位置5:
- 组0旋转角度:`5 * θ_0 = 5 * 1 = 5 弧度`
- 组1旋转角度:`5 * θ_1 = 5 * 0.01 = 0.05 弧度`
---
### **步骤3:对每组复数进行旋转**
#### **(1) 旋转公式**
复数旋转公式:`旋转后复数 = 原复数 * e^(i * 旋转角度)`
#### **(2) 计算旋转后的Query**
- **组0(i=0)**:
- 原复数:`q0 = 0.1 + 0.2j`
- 旋转角度:`2 弧度`
- 旋转后:
```
e^(i*2) = cos(2) + i*sin(2) ≈ -0.4161 + 0.9093j
旋转后 q0' = (0.1 + 0.2j) * (-0.4161 + 0.9093j)
= (0.1*(-0.4161) - 0.2*0.9093) + (0.1*0.9093 + 0.2*(-0.4161))j
≈ (-0.0416 - 0.1819) + (0.0909 - 0.0832)j
≈ -0.2235 + 0.0077j
```
- 转换为实数向量:`[-0.2235, 0.0077]`
- **组1(i=1)**:
- 原复数:`q1 = 0.3 + 0.4j`
- 旋转角度:`0.02 弧度`
- 旋转后:
```
e^(i*0.02) ≈ cos(0.02) + i*sin(0.02) ≈ 0.9998 + 0.0200j
旋转后 q1' = (0.3 + 0.4j) * (0.9998 + 0.0200j)
≈ (0.3*0.9998 - 0.4*0.0200) + (0.3*0.0200 + 0.4*0.9998)j
≈ (0.2999 - 0.008) + (0.006 + 0.3999)j
≈ 0.2919 + 0.4059j
```
- 转换为实数向量:`[0.2919, 0.4059]`
- **旋转后的完整Query向量**:
```
q_rotated = [-0.2235, 0.0077, 0.2919, 0.4059]
```
#### **(3) 计算旋转后的Key**
- **组0(i=0)**:
- 原复数:`k0 = 0.5 + 0.6j`
- 旋转角度:`5 弧度`
- 旋转后:
```
e^(i*5) ≈ cos(5) + i*sin(5) ≈ 0.2837 - 0.9589j
旋转后 k0' = (0.5 + 0.6j) * (0.2837 - 0.9589j)
= (0.5*0.2837 - 0.6*(-0.9589)) + (0.5*(-0.9589) + 0.6*0.2837)j
≈ (0.1418 + 0.5753) + (-0.4795 + 0.1702)j
≈ 0.7171 - 0.3093j
```
- 转换为实数向量:`[0.7171, -0.3093]`
- **组1(i=1)**:
- 原复数:`k1 = 0.7 + 0.8j`
- 旋转角度:`0.05 弧度`
- 旋转后:
```
e^(i*0.05) ≈ cos(0.05) + i*sin(0.05) ≈ 0.9988 + 0.0500j
旋转后 k1' = (0.7 + 0.8j) * (0.9988 + 0.0500j)
≈ (0.7*0.9988 - 0.8*0.0500) + (0.7*0.0500 + 0.8*0.9988)j
≈ (0.6992 - 0.0400) + (0.0350 + 0.7990)j
≈ 0.6592 + 0.8340j
```
- 转换为实数向量:`[0.6592, 0.8340]`
- **旋转后的完整Key向量**:
```
k_rotated = [0.7171, -0.3093, 0.6592, 0.8340]
```
---
### **步骤4:计算注意力分数**
计算旋转后的Query和Key的点积:
```
q_rotated · k_rotated = (-0.2235 * 0.7171) + (0.0077 * -0.3093) + (0.2919 * 0.6592) + (0.4059 * 0.8340)
≈ (-0.1603) + (-0.0024) + (0.1924) + (0.3385)
≈ 0.3682
```
---
### **关键观察:相对位置编码**
- **绝对位置差**:`n - m = 5 - 2 = 3`
- **旋转角度差**:
- 组0:`5θ_0 - 2θ_0 = 3θ_0 = 3*1 = 3 弧度`
- 组1:`5θ_1 - 2θ_1 = 3θ_1 = 3*0.01 = 0.03 弧度`
- **若直接计算相对位置3的旋转**:
- 对Query在位置0,Key在位置3,结果应与上述点积相同(因为相对位置差同为3)。
---
### **几何解释**
- **词向量是二维平面上的向量**:每组复数对应一个二维向量。
- **旋转操作**:位置编码相当于将向量按位置序号旋转一定角度。
- **点积与夹角**:点积结果反映两个向量的夹角,而夹角由相对位置差决定。
---
### **总结:RoPE如何工作**
1. **分组旋转**:将词向量拆分为复数,每组独立旋转。
2. **角度与位置绑定**:旋转角度由绝对位置和频率共同决定。
3. **相对位置自然出现**:点积结果仅依赖相对位置差(`n - m`),无需显式设计相对位置编码。
通过这种设计,RoPE在计算注意力时**隐式编码了相对位置信息**,同时保持计算高效性和外推能力。
ref:https://zhuanlan.zhihu.com/p/5606856749
TransFormer:



做一个线性变换就可以得到相对的位置。


sin(wx)函数的波长和频率


横轴对应的是pos,随着pos的增大,周期变大,波长变长(频率变慢),波长变化表达唯一性质。



公式上说明,TransFormer 正余弦编码具有外推性 为什么实际不具备呢?
理论外推性的论点:
1. 公式是定义在任意实数pos上的,因此可以计算任意位置(超出训练长度)的编码。
2. 由于正弦和余弦函数的周期性,模型可能会学习到周期性的模式,从而泛化到更长的序列。 但实际中外推失败的原因:
原因1:高频维度的周期性导致位置混淆(Position Aliasing)
- 在高频维度(即i较小的维度,0,1,2,3维度),由于分母中的指数项较小,使得位置变化很快(即波长较短)。 - 例如,当i=0时,波长λ=2π * 10000^(0) = 2π ≈6.28,这意味着每6.28个位置就会重复一次周期。 - 在训练时时,模型只见过位置0到到L_trin,当测位置poos>L_tran时,对于高频维度,pos可能会落在与训练时同的周期相同位置上,或者与某个训练位置相差整数个周期而有相同的编码值值(混淆。 - 注意虽然然公式上连续,但模型在练时只见过有有限的位置且且每个位置编码是一的((在训练长度内)。一旦超出,频维维度的位置编码可能训练时的的某个位置编码相同(因为周期性),导模型无法法区分。
原因2:低频度的变化不足 - 在低频维(i接近d_model/2),分母中的指指数项较大,得位置变化缓慢(波长很长)。 - 训练时,这些维度的位置编码在练练长度内变化很小(如,从0到LL_tainn,角度变化能小于π/2)),因此模型主要将这维度视为一个个小的移量(几乎乎恒定。 - 当试位置pos>>L_trin时时,低维度的的角度值然会会继续加,但模型在练时从未见过过这些维度有较大的化。模型在训练练时只见过这些维度的微小化,而外推时这些维度开始有显著著变化例如如,角变化超过π/2)),但模型没有学习如何处理这些变化,导致外推失败。
总之问题在于:整个位置编码向量是各个维度的组合。在某个高频维度上,测试位置可能与某个训练位置在该维度上的值相近,但在其他维度上可能并不相近。所以,严格来说,整个位置编码向量不不会与训位置完全相同。但是,由于高频维度的周期性,测试位置与训练位置在高频维度上可能相似,而低频维度上由于位置超出训练范围,其角度值虽然不同,但变化很小(几乎可以忽略),这可能导致整个位置编码向量与训练范围内的某个位置编码向量相似。(由于在训练范围内低频维度变化很小,模型可能没有充分学习到低频维度上位置变化的模式,所以当测试位置超出训练范围时,低频维度提供的位置信息非常有限。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)