LangChain 文档加载器:统一多源数据接入的基石
无论是企业内部知识问答、RAG(Retrieval-Augmented Generation)系统、还是法律文档分析、学术论文检索,模型都需要先“读懂”外部信息。而这些信息往往分散在各种来源:PDF 文件、网页、数据库、API、甚至云端文档系统。 如果每种数据源都需要独立解析,将导致极高的系统维护成本。为此,LangChain 提供了一个强大而优雅的组件:**文档加载器(Document Load
目录
前言
在构建基于大语言模型(LLM, Large Language Model)的智能应用时,一个常被忽略却极其关键的环节是:如何高效地让模型访问外部知识。
无论是企业内部知识问答、RAG(Retrieval-Augmented Generation)系统、还是法律文档分析、学术论文检索,模型都需要先“读懂”外部信息。而这些信息往往分散在各种来源:PDF 文件、网页、数据库、API、甚至云端文档系统。
如果每种数据源都需要独立解析,将导致极高的系统维护成本。
为此,LangChain 提供了一个强大而优雅的组件:文档加载器(Document Loaders)。
它的目标就是让开发者只需关注「数据内容」,而无需关心「数据来源」。
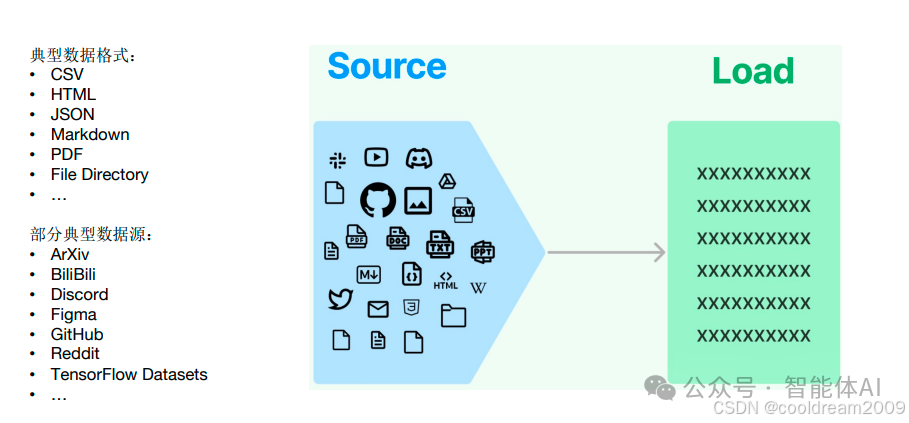
1. 设计理念:统一数据接入层
LangChain 的架构强调「模块化」和「标准化」。在整个 RAG 流程中,第一步就是文档接入(Document Ingestion)。
这一步的任务是:从不同来源读取文档内容,并将其统一为标准格式。
LangChain 通过定义一个抽象接口——DocumentLoader,实现了对多种数据源的统一封装。无论原始数据来自何处(文件、网页、数据库、API),最终都被转换为同一种结构:
from langchain.schema import Document
Document(
page_content="文档的纯文本内容",
metadata={"source": "文件路径或URL", "page": 3}
)
其中:
- page_content:存储文本内容;
- metadata:保存上下文信息,如文件名、URL、页码等。
这意味着,不论你的原始数据是 PDF 报告还是网页文章,LangChain 在加载完成后,都能以一致的方式处理,极大降低了后续处理复杂度。
2. 接口结构与核心机制
所有 LangChain 的文档加载器都继承自一个基类:BaseLoader。
它定义了统一的加载规范:
from langchain.document_loaders import BaseLoader
class BaseLoader:
def load(self) -> List[Document]:
"""同步加载文档"""
async def aload(self) -> List[Document]:
"""异步加载文档(可选实现)"""
无论是官方提供的加载器还是用户自定义的,都必须返回 List[Document] 对象。
这样的接口设计让整个生态极具可扩展性:你可以轻松组合或替换不同的数据源,而不影响下游处理逻辑。
3. 多种数据源支持:灵活与统一的结合
LangChain 官方与社区提供了数量庞大的加载器,几乎涵盖所有主流数据源。
这些加载器大体可分为以下几类:
| 类型 | 加载器示例 | 功能说明 |
|---|---|---|
| 本地文件 | TextLoader, PyPDFLoader, UnstructuredWordDocumentLoader, CSVLoader |
从本地文件(TXT、PDF、Word、CSV)中读取文本 |
| 网页加载 | WebBaseLoader, AsyncHtmlLoader, SitemapLoader |
抓取网页正文内容或批量爬取整个网站 |
| 云端文档 | GoogleDriveLoader, NotionDBLoader, ConfluenceLoader |
从云端办公文档系统加载企业数据 |
| 数据库源 | SQLLoader, MongoDBLoader |
从关系型或非关系型数据库中加载数据 |
| API / 代码仓库 | GithubFileLoader, APIJSONLoader |
从 REST API 或代码仓库中提取内容 |
| 自定义源 | 自定义 BaseLoader |
适用于企业内部系统、自建知识库等私有数据源 |
这种统一接口的设计,让你可以像搭积木一样拼接各种数据源。例如,你可以同时加载公司知识库、部门共享文档和产品网页,然后统一索引、检索、问答。
4. 实战:多源文档加载示例
让我们通过一个简单示例,看看如何同时从多个来源加载数据。
from langchain.document_loaders import TextLoader, PyPDFLoader, WebBaseLoader
1. 从本地 TXT 文件加载
text_loader = TextLoader("data/intro.txt")
text_docs = text_loader.load()
2. 从 PDF 文件加载
pdf_loader = PyPDFLoader("data/AI_Whitepaper.pdf")
pdf_docs = pdf_loader.load()
3. 从网页加载
web_loader = WebBaseLoader("https://openai.com/research")
web_docs = web_loader.load()
合并所有文档
all_docs = text_docs + pdf_docs + web_docs
print(f"共加载文档数量:{len(all_docs)}")
print(all_docs[0].page_content[:200])
运行结果(示例):
共加载文档数量:6
Artificial intelligence research at OpenAI focuses on...
此时,这些文档都被标准化为 Document 对象,可以直接用于后续的文本切分(TextSplitter)与向量化(Embeddings)步骤。
这种“多源统一加载”机制,是 LangChain 构建企业知识检索、智能问答系统的基础能力之一。
5. 异步加载与高并发抓取
在网络爬取或批量处理网页时,LangChain 的异步加载能力非常实用。
许多加载器都提供了异步版本,例如 AsyncHtmlLoader。
示例代码如下:
import asyncio
from langchain.document_loaders import AsyncHtmlLoader
async def load_async():
urls = [
"https://openai.com/research",
"https://example.com/news"
]
loader = AsyncHtmlLoader(urls)
docs = await loader.aload()
return docs
docs = asyncio.run(load_async())
print(f"异步加载到 {len(docs)} 个网页文档。")
异步加载可以同时抓取多个网页,大幅提升性能,非常适合构建新闻聚合、舆情分析等实时系统。
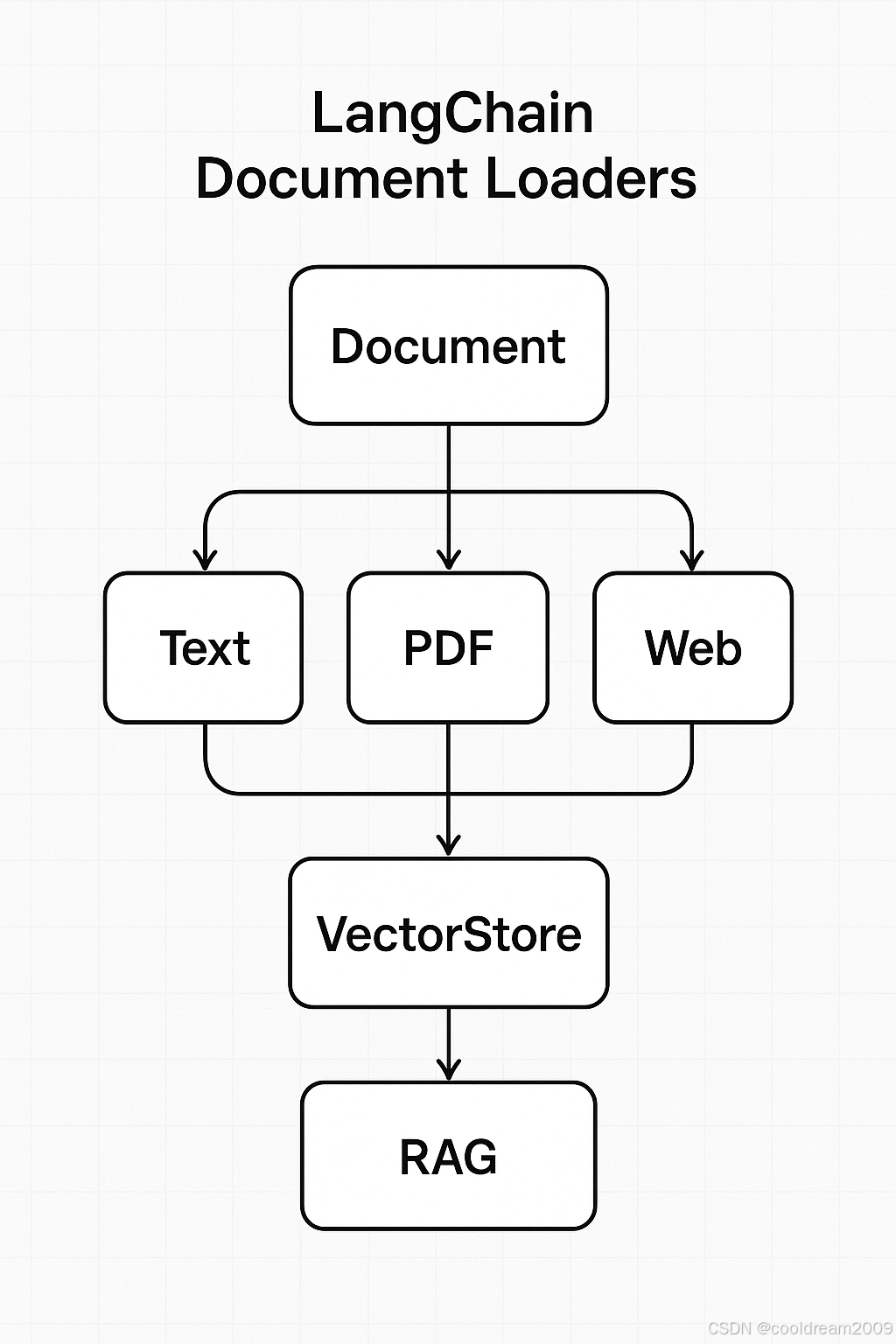
6. 自定义加载器:接入企业内部系统
如果官方加载器无法满足你的需求(例如你有一个企业内部 API 或私有数据库),
可以很容易地自定义加载器,只需继承 BaseLoader 并实现 load() 方法即可。
示例:自定义 API 加载器
from langchain.document_loaders import BaseLoader
from langchain.schema import Document
import requests
class APILoader(BaseLoader):
def __init__(self, endpoint):
self.endpoint = endpoint
def load(self):
response = requests.get(self.endpoint)
data = response.json()
return [
Document(page_content=item["content"], metadata={"id": item["id"]})
for item in data
]
使用示例
loader = APILoader("https://api.example.com/articles")
docs = loader.load()
print(f"加载到 {len(docs)} 篇文章")
这种方式尤其适用于企业知识库接入、SaaS 平台文档同步、内部系统集成等场景。
你可以轻松地让 LLM 访问公司业务数据,而不需改动核心逻辑。
7. 典型应用场景
文档加载器几乎是所有基于 LangChain 应用的起点。以下是几个典型应用场景:
7.1 企业知识问答系统
企业往往拥有大量文档(政策文件、流程手册、项目资料)。
通过 CSVLoader、PyPDFLoader 等加载器,可以批量导入公司知识,再结合向量检索(如 FAISS、Chroma),实现智能问答机器人。
7.2 学术论文或报告分析
研究人员可以用 PyPDFLoader 或 ArxivLoader 加载论文 PDF,然后通过 TextSplitter 切分,再交给大模型进行摘要、对比或引用分析。
7.3 网站智能检索与内容聚合
利用 WebBaseLoader 或 AsyncHtmlLoader 抓取新闻、博客或论坛内容,并结合语义检索,为用户提供内容聚合、舆情总结等功能。
8. 小结
LangChain 的 文档加载器(Document Loaders) 是整个知识增强系统的“入口”。
它让开发者能够在复杂的数据世界中,快速实现「多源输入、统一输出」。
它的核心价值可以总结为三点:
- 统一性:无论数据来自何处,格式一致,接口统一;
- 灵活性:支持本地文件、网页、数据库、API 等多种来源;
- 可扩展性:可轻松自定义加载逻辑,适配企业内部系统。
文档加载器就像“信息入口的标准接口”,为大模型系统提供了干净、规范的知识输入渠道。
掌握它,是你构建 RAG 系统、企业知识助手或智能检索平台的第一步。
结语
在智能系统的世界里,数据是知识的燃料,而 LangChain 的文档加载器 正是加油口。
它帮我们跨越不同数据格式与来源的壁垒,让模型真正具备“读懂世界”的能力。
如果你正在设计知识增强应用,不妨从这里开始,让 LangChain 替你打通数据接入的最后一公里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)