InternVLA-M1:用于通才机器人策略的空间引导视觉-语言-行动框架
25年10月来自上海AI 实验室的论文“InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy”。InternVLA-M1,这是一个统一的空间落地(spatial grounding)和机器人控制框架,旨在推动指令跟随机器人向可扩展的通用智能方向发展。其核心理念是空间
25年10月来自上海AI 实验室的论文“InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy”。
InternVLA-M1,这是一个统一的空间落地(spatial grounding)和机器人控制框架,旨在推动指令跟随机器人向可扩展的通用智能方向发展。其核心理念是空间引导的视觉-语言-动作训练,其中空间落地是指令与机器人动作之间的关键连接。InternVLA-M1 采用两阶段流程:(i) 使用超过 230 万个空间推理数据进行空间落地预训练,通过将指令与视觉的、与具身无关的位置对齐来确定“在哪里行动”;(ii) 使用空间引导的动作后训练,通过即插即用的空间提示生成具身-觉察的动作来决定“如何行动”。这种空间引导的训练方法取得了持续的提升:InternVLA-M1 在 SimplerEnv Google Robot、WidowX 和 LIBERO Franka 上的表现均优于没有空间引导的版本,分别高出 +14.6%、+17% 和 +4.3%,同时在框、点和轨迹预测方面展现出更强大的空间推理能力。为了进一步扩展指令跟踪能力,构建一个模拟引擎,用于收集 244,000 个可泛化的拾取放置场景,在 200 个任务和 3,000 多个物体上实现 6.2% 的平均提升。在现实世界的集群拾取放置任务中,InternVLA-M1 的性能提升 7.3%,并且在合成协同训练的帮助下,在未知物体和新配置上的性能提升 20.6%。此外,在需要进行长距离推理的场景中,它的性能比现有成果高出 10% 以上。这些结果凸显空间引导训练是可扩展且具有弹性的通用机器人的统一原则。
InternVLA-M1 如图所示:
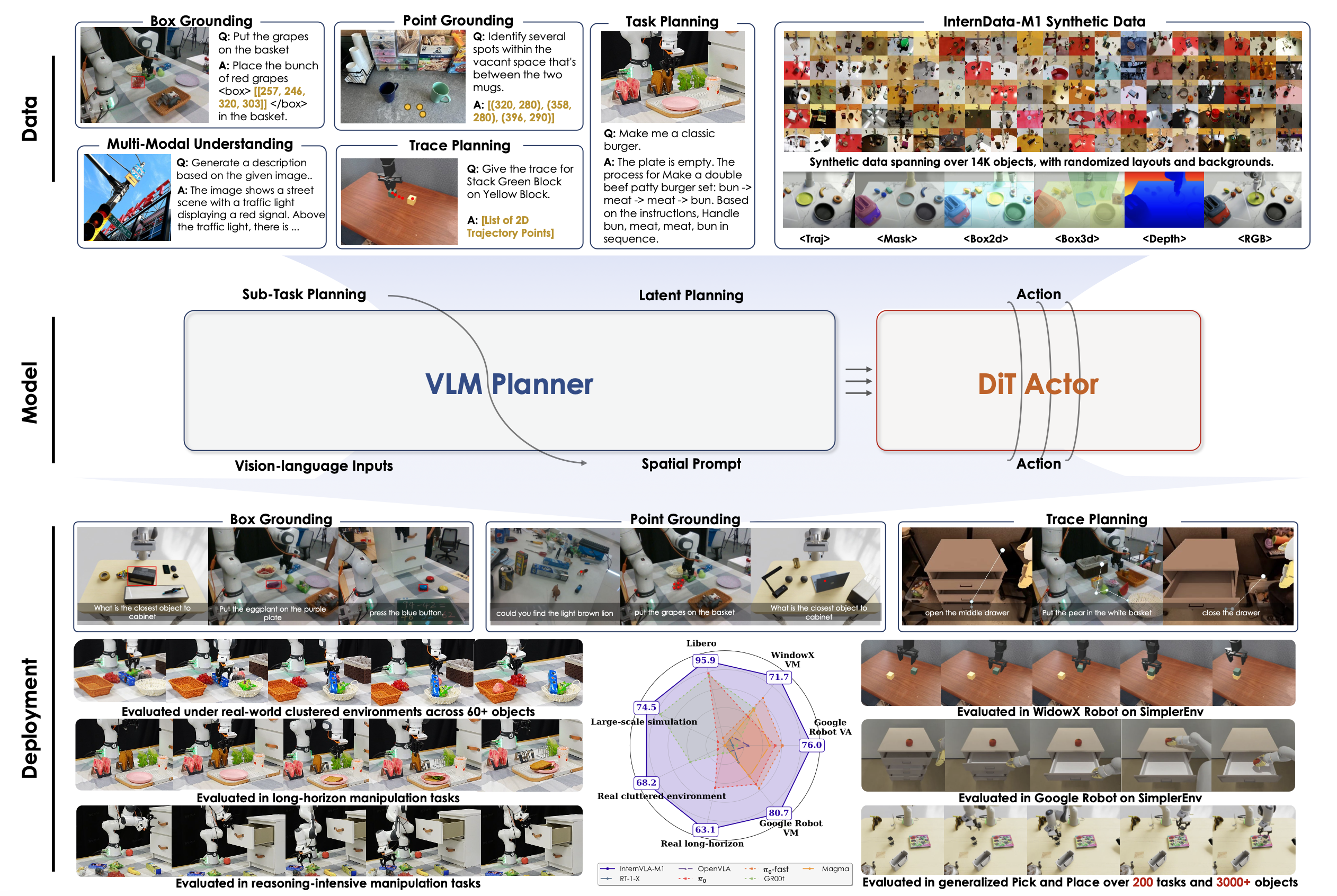
模型架构
双系统。InternVLA-M1 是一个双系统端到端 VLA 框架,基于从不同来源收集的大规模空间落地数据进行预训练。InternVLA-M1 采用 Bai (2025a) 的 Qwen2.5-VL-3B-instruct 作为系统 2 的多模态编码器,用于捕获空间先验。它采用 Chi (2023) (86 M) 的扩散策略作为动作专家(系统 1,快速执行器),有效地模拟具身控制。该专家基于 Oquab (2023) (21 M) 的 DINOv2 视觉编码器和一个轻量级状态编码器(0.4 M),构成一个紧凑的视觉-动作模型。InternVLA-M1 总共包含约 41 亿个参数。在推理过程中,该系统在单个 RTX 4090 GPU 上运行,占用约 12 GB 内存。借助 FlashAttention,VLM 组件的推理速度可达到约 10 FPS。动作执行速度可通过分块和KV缓存进一步加速。
双重监督。双系统架构在训练过程中同时支持多模态监督和动作监督。在每个训练步骤中,两种数据类型的批次会被联合处理,模型会根据两个监督信号计算损失。最终的梯度会被汇总并应用于单次优化更新,从而确保感知和控制能够协同适应,而非孤立地学习。具体而言,VLM 规划器会与广泛的空间落地数据(包括真实数据和合成数据)保持一致,涵盖物体检测、affordance 识别和视觉轨迹规划等任务。与此同时,动作专家会使用机器人演示数据进行训练,使其能够将这些先验知识专门化为特定于具身的运动指令。这种双重监督策略在高级语义感知和低级运动控制之间建立了紧密的联系,这对于在模拟和现实环境中实现稳健的指令遵循至关重要。
通过空间提示进行潜规划。为了将 VLM 规划器与动作专家连接起来,采用一个轻量级查询transformer (8.7 MB),该transformer以 VLM 规划器生成的潜规划嵌入为条件。查询transformer通过将可变长度的输入token映射到一组固定的可学习查询 token 来稳定专家的学习和推理。它被实现为一个 𝑘 层交叉注意模块,其中查询 token选择性地关注 VLM 的 𝑘 个中间层(例如,𝑘 = 1 仅关注最后一层)。
为了明确激活在空间落地预训练期间学习的空间感知能力,采用空间提示。例如,在一般的物体操作任务中,在任务指令后附加一些简单的提示,例如“弄清楚如何执行它,然后找到所需的关键物体。” 提取的特征嵌入为规划器提供了明确的空间线索,从而有助于更可靠地进行落地操作。受 Bjorck (2025)先前研究的启发,Driess (2025);Zhou(2025b)指出,动作模块和 VLM 模块之间的直接梯度流可能会扭曲多模态知识,因此在查询 Transformer 中引入一个梯度衰减因子。这会衰减从动作专家传播回 VLM 的梯度(例如,衰减 0.5 倍),从而在保留规划器的语义推理能力的同时,仍然能够实现有效的联合优化。
训练方案
为了利用空间先验知识在指令跟随中实现更强的针对具身的控制,InternVLA-M1 采用空间引导的两阶段训练流程:
第一阶段:空间落地预训练。如图所示,第一阶段仅优化 VLM。其目标并非通用的视觉语言预训练,而是机器人技术所必需的更强大的空间推理和规划能力。将互联网规模的多模态语料库与机器人专用数据集相结合,例如 RefCOCO、RoboRefIt(Lu 2023b)、A0 (Xu 2025b)、MolmoAct (Lee 2025) 和 Pixmo-Points (Deitke 2024)。所有机器人数据集均被重新格式化为统一的 QA 式结构,涵盖边框检测、轨迹预测、affordance 识别和思维链(CoT)推理。将它们与网络规模数据对齐,可以在与传统 VLM 相同的监督式微调框架下进行训练。
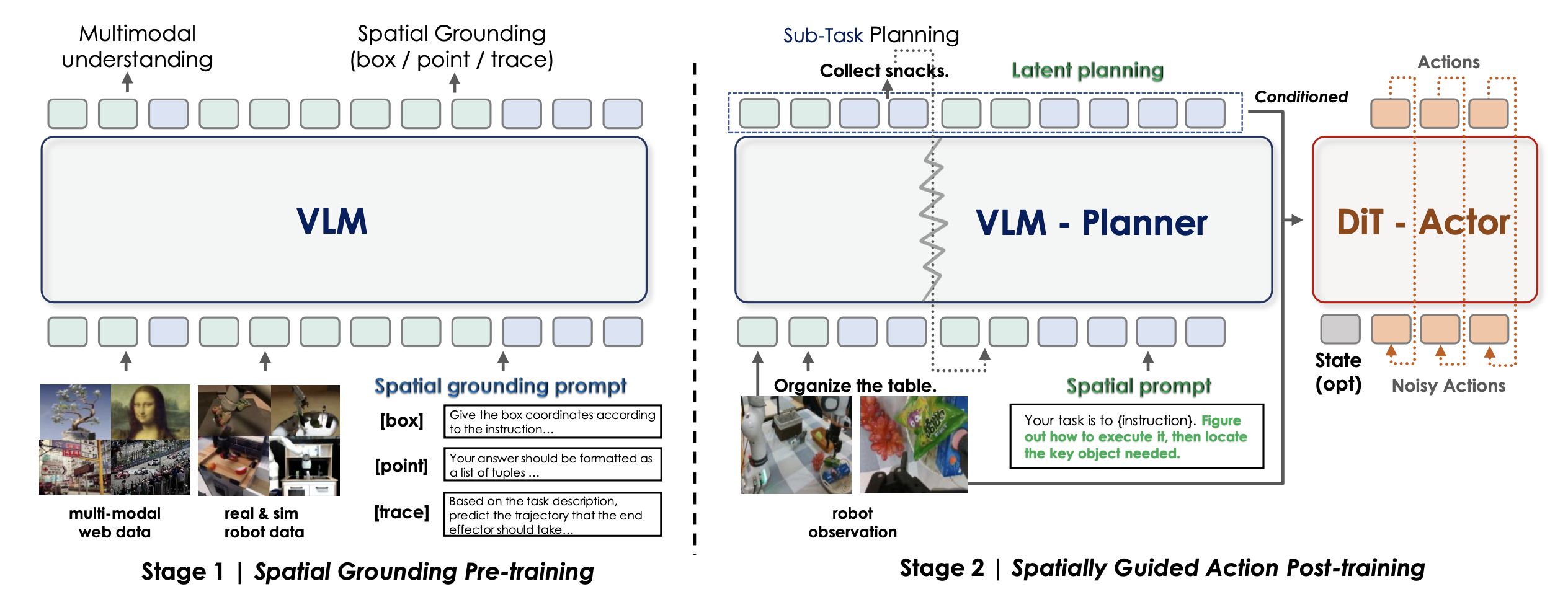
第二阶段:空间引导动作后训练。在此阶段,VLM 和动作专家将基于演示数据进行联合优化,确保语义理解和动作生成紧密结合。采用两种策略:
• 空间提示。在预测动作之前,在任务指令前添加一个空间提示,以引出关于目标关系和任务约束的结构化推理。例如,指令“将所有玩具放入玩具箱”可以增强为:“识别所有相关玩具及其与容器的空间关系”。虽然 VLM 不会明确输出对此辅助提示的响应,但其加入可以提高操作任务中的空间-觉察和泛化能力。
• 与空间落地数据协同训练。训练在机器人轨迹数据和基础数据之间交替进行。对于轨迹数据,VLM 主干网络和动作专家都使用预测噪声和真实噪声之间的 L2 损失进行优化。对于空间落地数据,仅通过下一个token预测来更新 VLM 主干网络。这种协同训练方案在支持高效的端到端优化的同时,强化空间推理能力。
InternVLA-M1 中使用的数据集,涵盖训练前、训练中和训练后阶段。在 VLM 预训练阶段,构建包含点、框和轨迹标注的大规模空间落地数据集,以增强空间感知和视觉-语言对齐。训练中阶段采用合成操作数据,将预训练知识与机器人执行连接起来。训练后阶段则使用模拟和真实世界的指令执行数据,包括大规模桌面任务和用于长视域操作的真实机器人演示。
用于预训练的空间基础数据
模型的多模态训练数据集包含超过 300 万个数据,分为四类:通用 QA、框 QA、轨迹 QA 和点 QA,如图所示。值得注意的是,其中超过 230 万个数据专用于空间推理数据集。这些类别确保了强大的多模态理解能力,同时支持适应桌面机器人场景中的具身任务。如下对每个类别进行描述:

• 通用问答。该类别的数据来源于 LLaVA-OneVision (Li 2024a) 和 InternVL3 (Chen 2024,Zhu 2025),样本涵盖了各种多模态任务,包括图像字幕制作、视觉问答 (VQA)、光学字符识别 (OCR)、知识落地和创意写作,总共约有 637,000 个样本。
• 盒子问答。整理丰富的多模态落地数据集,包括 RefCOCO Mao (2016);Yu (2016)、ASv2 Wang (2024) 和 COCO-ReM Singh (2024),这些数据来源于 InternVL3 Chen (2024);Zhu (2025)。此外,还整合 InternData-M1 数据集(该数据集通过可扩展的合成数据生成产生)和 RoboRefIt 数据集(Lu,2023b),后者是专门用于机器人接地的数据集,总共产生约 879K 个样本。
• 轨迹问答。此类别整合 Xu(2025a)的 A0 ManiSkill 子集、InternData-M1 航点数据集和 Lee(2025)的 MolmoAct 数据集,以实现精确的末端执行器轨迹预测。A0 ManiSkill 子集提供高质量的以目标为中心的轨迹数据,其中小物体与机械臂的夹持器协调移动。这些轨迹可以近似为桌面操作任务的末端执行器运动,总共产生了约 684K 个样本。
• 点问答。为了实现精确的点定位,整合多个数据集,包括 Pixmo-Points 数据集(Deitke,2024)、RoboPoint 数据集(Yuan,2024)、RefSpatial 数据集(Zhou,2025 a)以及从 InternData-M1 数据集中提取的点子集,并对每个数据集进行定制的预处理。具体而言,Pixmo-Points 数据集经过过滤,排除分辨率超过 1024 像素的图像,并且每幅图像最多只能包含 10 个点。此外,优先从 RoboPoint 和 RefSpatial 数据集中提取目标参考和区域参考数据,以提高接地精度,总共获得约 832K 个样本。
所有点坐标均转换为绝对坐标(Bai,2025 a)。预测坐标采用 JSON 和 XML 格式,以支持针对各种机器人任务的稳健学习和空间指令的自适应处理。
用于动作预训练后的合成数据
为了弥合 VLM 和 VLA 之间的差距,引入“后预训练”阶段,在 VLM 预训练后,使用大规模模拟数据对 VLA 进行预训练。此阶段初始化动作头并促进动作表征的学习。“后预训练”需要在指令和目标层面保持多样性。与 InternVLA-M1-Interface 数据一致,利用 GenManip 作为数据合成流水线,构建一个包含 244K 个闭环样本的大规模拾取和放置数据集——InternData M1 数据集。具体而言,采用与 InternVLA-M1-Interface 数据相同的目标集和位置分布,并通过可扩展的数据流水线进行处理。每个合成样本都经过严格验证,以确保其正确性和一致性。为了进一步增强视觉多样性,在光照条件和纹理映射中引入受控随机化。
用于指令跟踪的可扩展合成数据引擎
为了支持 VLM 预训练的大规模端到端数据生成,在 GenManip Gao (2025) 和 Isaac Sim Makoviychuk (2021) 的基础上构建一个高度可扩展、灵活且完全自动化的模拟流程。
用于可泛化的拾取和放置任务的自动任务合成。开发一个可扩展的模拟流程(如图所示),该流程可根据随机的物体布局和光照条件生成不同的操作轨迹。通过利用包括物体姿态、物体网格和机械臂状态在内的重要模拟信号,该系统通过场景图求解器快速生成场景布局,并基于物体网格计算候选抓取动作(Liang (2019))。然后,每个候选轨迹在物理系统中执行一次以进行闭环验证,之后由场景图验证器检查任务目标是否已实现。只有成功执行并通过验证的轨迹才会被接受,以确保所有收集的数据在物理上可行且任务完成。

合成 VLM 数据和 VLA 数据用于空间定位。为了提高效率,框架将机器人规划和渲染完全解耦。规划器记录结构化的场景和轨迹数据,包括关节状态、物体位置和动作信息,这些数据随后由渲染器在随机光照、材质和视点下重放。为了使模拟结果与现实世界保持一致,用 ArUco 标记点标定所有摄像机,确保内外参与现实世界摄像机的参数匹配,从而保持一致的视点几何形状。除了高分辨率图像外,渲染器还会生成丰富的中间输出,例如物体边框和二维末端执行器轨迹。这些信号为行动学习提供密集的监督,并有助于创建用于空间定位、affordance 推理和轨迹预测等任务的辅助数据集。资产库包括 14K 个带注释的目标、211 个表、1.6K 个纹理和 87 个圆顶灯源,提供具有高度视觉和物理多样性的数据——这对于开发可通用模型至关重要。
在公共基准的实验
使用两个成熟的模拟套件:
• SimplerEnv 旨在探索视觉外观变化的鲁棒性。它包含 WidowX 和 Google Robot 平台、短视域原子任务以及受控的光照、颜色、表面纹理和相机姿态变化。报告三个任务集的结果:Google Robot-VM(视点和光照变化下的视觉匹配)、Google Robot-VA(不同纹理和颜色下的视觉聚合)和 WidowX-VM(跨机器人泛化)。
• LIBERO 是一个基于语言条件的操作套件,构建于 Franka 机器人上,具有丰富的场景和专家演示。评估四个任务集:LIBERO-Spatial(相同物体,不同空间布局)、LIBERO-Object(固定布局,不同物体)、LIBERO-Goal(固定物体和布局,不同目标)和 LIBERO-Long(也称为 LIBERO-10;涉及多个目标、布局和操作的较长任务)。
基线。与最先进的开放式 VLA 系统进行比较,包括 𝜋0 Black (2024)、GR00T Bjorck (2025)、OpenVLA Kim (2024)、CogACT Li (2024c) 等。还包含一个基于 QwenVL-2.5-3B-Instruct 构建的带有 DiT 动作头的原始VLA。如果可用,会使用官方报告的数字;否则,会重实现并用 ∗ 标记此类条目。将训练数据、观察空间和动作类型与 Li (2024c) 中最流行的设置保持一致,以确保公平比较。
SimplerEnv 基准测试
实验设置。在 Open-X 实例 (OXE) 的一个子集(包括 fractal_rt_1 和 bridge_v1)上对 InternVLA-M1 进行后训练,并在空间接地数据上进行协同训练。VLM 将主要观察图像、任务指令和辅助空间提示作为输入,而动作专家则使用大小为 16 的动作块来预测动作。对于多模态数据,该模型采用 SFT 风格的问答格式。训练在 16 块 NVIDIA A100 GPU 上进行,训练步长为 50k(约 2.5 个 epoch),机器人数据的总批次大小为 256,多模态数据的总批次大小为 64,并针对两种数据类型进行总损失优化。所有评估均在 SimplerEnv 中使用其官方评估协议进行。
LIBERO 基准测试
实验设置。遵循 Kim (2025) 的研究,过滤掉失败的演示并暂停帧。训练期间,该策略将腕戴式和第三人称摄像机视角作为输入。用 8 块 A100 GPU,批次大小为 128,动作块大小为 8,在每个套件上独立微调模型。训练运行约 3 万步,持续约 20 小时。每个套件进行 500 次试验评估。
室内环境下的指令跟踪实验
模拟大规模拾放任务的评估
现有基准测试集(例如 SimplerEnv 和 LIBERO)规模有限,限制了对多样化和复杂环境下指令跟踪操作的全面评估。为了更严格地评估泛化能力,开展一项大规模模拟评估实验,该评估增强目标多样性和布局变化。
实验设置:基于 Isaac-Sim Gao (2025) 的论文构建 200 个拾放任务,其中每个任务中操作的目标彼此不同。包括背景目标在内,该基准测试集总共涵盖超过 3000 个物品和容器。每个任务都通过数据生成流水线执行一次,以确保其可执行性。此外,对于这 200 个任务中的每一个,还额外收集 5 条具有相同目标集但布局随机化的轨迹,用于后训练。观察空间包含两张 RGB 图像:一张从固定的第三人称视角拍摄,另一张从安装在 Franka 末端执行器上的第一人称视角拍摄。两张图像在输入模型之前均调整为 224 × 224 的尺寸。用 16 块 A100 GPU 在每个套件上独立微调模型,总批次大小为 256,动作块大小为 16。训练步骤为 20,000 步。模型和所有基线模型均使用增量关节空间控制进行训练。
真实杂乱场景拾放任务评估
实验设置。为了评估模型在真实场景中的指令执行能力,用配备 Robotiq 2F-85 夹持器的 Franka Research 3 机械臂。该设置包含两个用于 RGB 视觉输入的英特尔 RealSense D435 摄像头——一个安装在末端执行器上,另一个位于后方第三人称视角。通过各种操作任务评估该模型,包括短距离拾放、长距离物体分类、抽屉开合和三明治组装。为了进行定量评估,设计一个真实世界物体分类基准测试,该基准测试由 60 × 90 厘米桌面工作空间内的单距离拾放任务组成。该基准测试包含 23 个可见物体和 5 个可见容器(如图所示)。在每个场景中,三个容器固定在指定位置,不同的物体随机散布在其中。模型必须遵循自然语言指令来拾取特定物体并将其放入正确的容器中。为了支持后训练的结果,收集 6 小时的远程操作演示,仅使用预定义“已见”集合中的物体和容器。将 InternVLA-M1 的两个变型(w/o co-train 和 w/ co-train)与 GR00T N1.5 和 𝜋0 进行比较,并在该基准的五种评估方案中进行测试。w/o co-train 的 InternVLA-M1 仅基于真实世界演示进行微调,而 w/ co-train 的 InternVLA-M1 则基于真实世界数据和模拟数据集 InternData-M1 进行联合训练。两个 RGB 视图均调整为 224 × 224 并用作模型输入。对于模型的两个变型,用 16 块 A100 GPU 在各个套件上独立进行微调,批处理大小为 256,动作块大小为 16。训练步骤为 20,000 步。所有模型(包括基线)均在实际实验中使用增量末端执行器空间控制进行训练和执行。

评估设置。为了评估泛化能力,进一步将所有可用的物体和容器资产划分为不相交的可见集和不可见集,如上图所示。训练数据中仅包含可见集,而在测试期间会评估可见集和不可见集,以衡量模型泛化到新物体的能力。如下图 所示,在以下设置下评估各种模型在实际拾取任务中遵循指令的能力:分布内、未见过物体、未见过物体位置、未见过物体方向和未见过的指令。报告成功率,定义为将指定物体放入指定容器的试验比例。 SR 越高,性能越好。对于每个模型,总共进行 300 次 rollout 评估。每次试验对应一个或多个测试设置,确保每个设置至少评估 50 次。为了确保跨模型的公平比较,在测试期间固定每个任务中物体和容器的位置。

长范围推理操作评估
双系统框架的一大优势在于,它能够利用高级规划器(系统 2)将长周期、推理密集型任务分解为一系列原子操作,然后由低级操作模型(系统 1)稳健地执行。为了评估这一能力,设计一系列任务,这些任务不仅需要多步骤规划,还需要推理目标属性、监控进度和适应变化的能力。
实验设置。为了支持这些长视界任务的细粒度训练,总共收集 22 小时的高质量长视界和推理遥控演示,每个任务约 500 个演示。每个收集的轨迹都被细分为子任务,并标注相应的原子动作。例如,“制作经典三明治”任务分解为四个子任务:(1)“将一片面包放到盘子上。”→(2)“将一块肉放到盘子上。”→(3)“将一片生菜放到盘子上。”→(4)“将一片面包放到盘子上”。每个子指令都与演示的特定片段配对。为了实现子任务级别的转换,在每个子任务片段后引入零动作向量填充。这使得模型能够在子任务完成后停止,然后提示预测到下一个子任务的转换。此外,为了提高时间一致性并确保推理流畅,移除了机械臂出现明显停顿或空闲行为的帧。与以往依赖额外 VLM 作为长期或推理密集型任务的任务规划器 VLA 模型不同,统一模型架构基于多模态输入进行联合训练,涵盖任务分解、子任务识别、数值推理和动作监督。这种联合训练范式使单个模型能够以端到端的方式无缝集成任务规划、推理和动作预测。训练方案遵循现实世界中短期拾取放置任务的训练方法。如表所示,尽管 GPT-5 拥有强大的推理能力,但对统一模型进行额外的后训练显著提升其在长期和推理密集型任务上的性能,这凸显后训练对于有效的高级任务规划的必要性。
评估设置。在三种不同的设置下评估模型性能:分布内、物理干扰和任务重规划:
• 物理干扰。任务执行过程中会引入外部干扰。例如,在将物品分类放入抽屉的任务中,机器人打开抽屉后手动关闭抽屉,或者抓取过程中目标物体发生位移。这评估模型感知环境变化并进行相应调整的能力。
• 任务重规划。在执行过程中发出新的指令。例如,在将物体放入抽屉后、关闭抽屉之前,机器人被告知:“也把奶牛玩具放进最上面的抽屉。”这测试模型融入新子目标并动态调整规划的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)