大模型应用开发--[后端开发快速学习]
本文介绍了大模型应用开发的基础知识,方便后端开发员快速了解大模型应用开发,解释了深度学习中的Transformer神经网络模型及其在大语言模型(LLM)中的核心作用。
目录
大模型应用开发
初识大模型
-
认识AI
-
大模型应用
-
部署大模型(ollama部署模型),掌握阿里云百炼平台使用
-
调用大模型,使用http方式调用大模型
-
大模型应用,与传统应用的区别
-
技术方案
-
-
SpringAI
-
基本使用
-
阻塞调用和流式调用大模型
-
会话记忆和会话历史问题
-
多模态、RAG、向量数据库、Prompt Engineer
-
认识AI
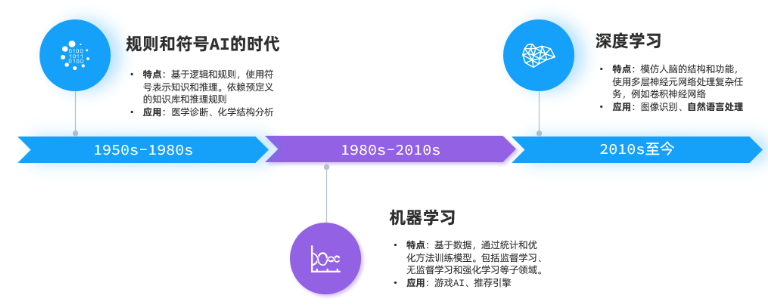
发展阶段
-
规则符号 -> 机器学习 -> 深度学习
-
机器学习: 基于数据,统计和优化方法训练模型。包括监督学习、无监督学习、强化学习等
-
深度学习:模仿人脑结构和功能使用多层神经元网络处理复杂任务,如卷积神经网络
-
其中自然语言处理(NLP)有一个关键技术叫做Transformer,由多层感知机组成的神经网络模型
-
-
大模型(LLM)底层都是采用Transformer神经网络模型。如GPT(Generative生成式、Pre-trained预训练、Transformer)

大模型原理
-
Transformer是由Google在2017年提出的一种神经网络模型,一开始的作用是把它作为机器翻译的核心,底层使用的是注意力机制
-
voice-to-text 音频生成文本,或者文本生成音频
-
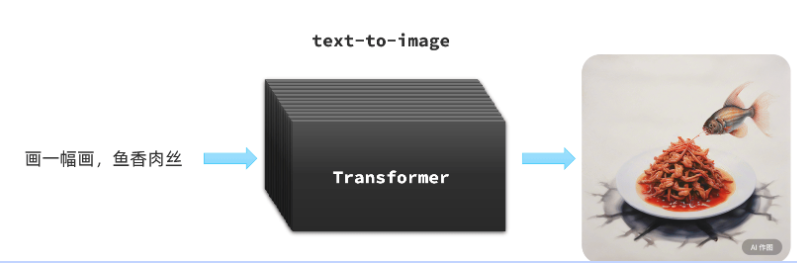
text-to-image 文本生成图片
-
-
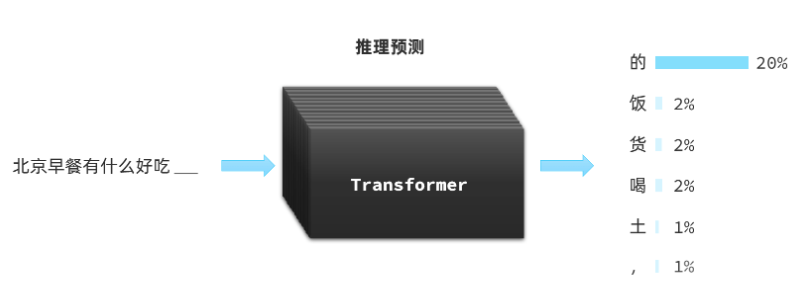
而大语言模型LLM对于Transformer是另一种用法推力预测
-
首先是P(Pre-trained),使用大量数据对模型进行预训练
-
然后是T,使用Transformer对输入的一些文本、音频、图片信息尝试进行推理接下来的内容,以概率发布形式出现
-
-
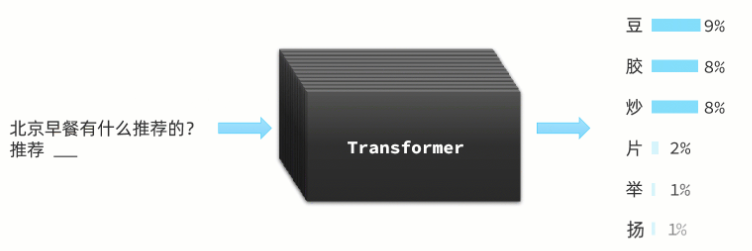
最后是G(Generative),持续生成;根据前文推测出接下来的词语后,拼接到前文,再次给大模型处理,推测下一个字,不断重复前面过程,最后生成大段内容(这就是为什么我们跟AI聊天的时候,它生成的内容总是一个字一个字的输出的原因了。)
-
模型部署
方案对比
-
大模型应用开发是通过访问模型对外暴露的API接口,实现大模型的交互
使用开发的大模型API
-
优点:没有部署和维护成本,按调用收费
-
缺点:依赖第三方,稳定性差;长期使用成本高;数据有隐私和安全问题(存储在第三方)
云部署
-
优点:前期投入成本低,部署和维护方便,网络延迟低
-
缺点:数据在第三方,有隐私和安全问题;长期使用成本高
本地部署
-
优点:数据完全自主掌控,安全性高;不依赖外部环境;长期来看成本会更低
-
缺点:初期部署成本高;维护成本高
云服务
-
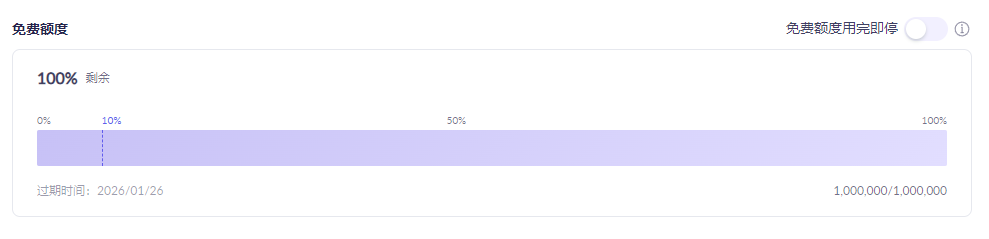
上线阿里的百炼平台就送百万token哇!各种模型任你选择
-
-
-
但是首先得获取API Key作为鉴权凭证(相当于密钥),平时我们访问的free AI基本用的是官方的api key,所以相当于免费嘛。
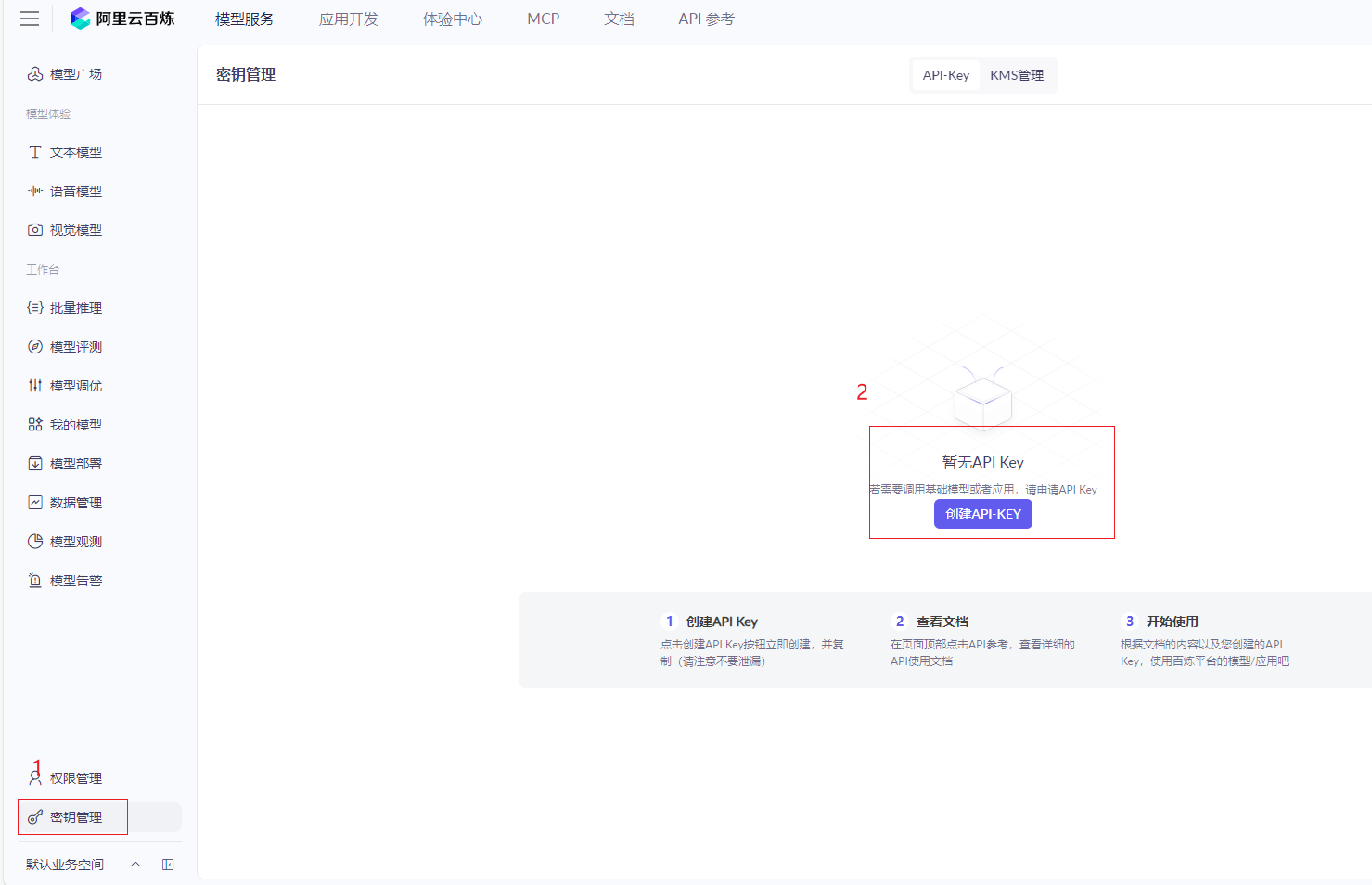
获取API-KEY
-
到密钥管理中,点击创建API-KEY即可
-
接着任意选择一个模型进行交流
本地部署
-
本地部署一般是在自己的服务器上部署,但这里以本地电脑进行部署为例,由于电脑配置远远无法支持大模型配置要求,届时部署下来的也是阉割版的。
-
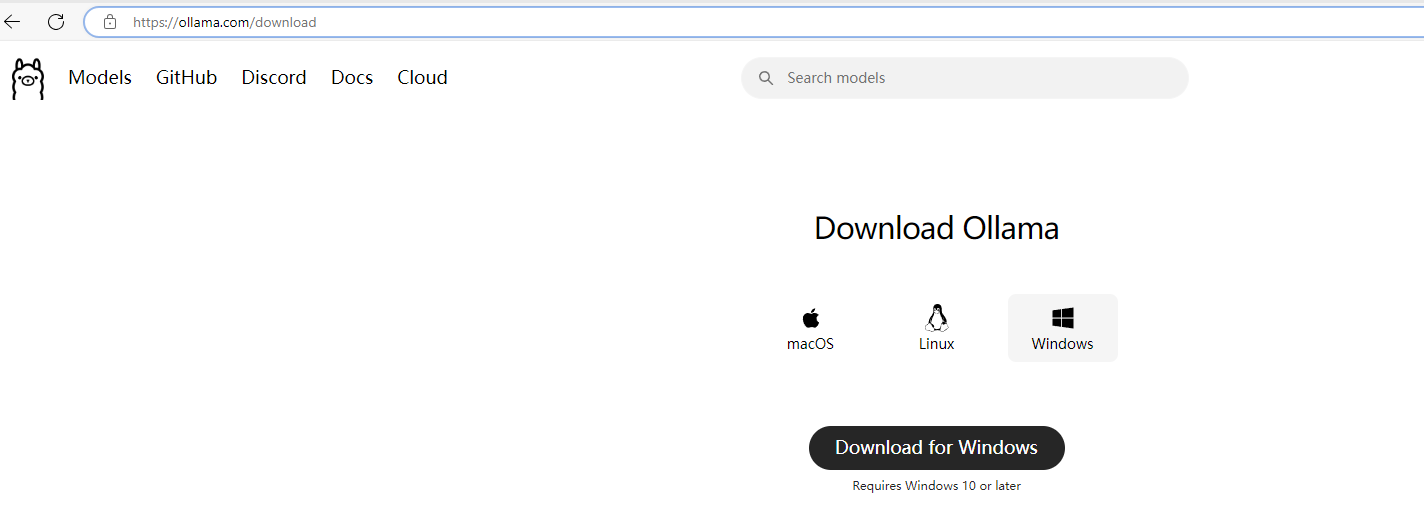
本地部署一种方案就是ollama,官方地址:https://ollama.com
-
访问后点击下载,我这里是Windows版本(Linux可以直接通过指令下载)
-
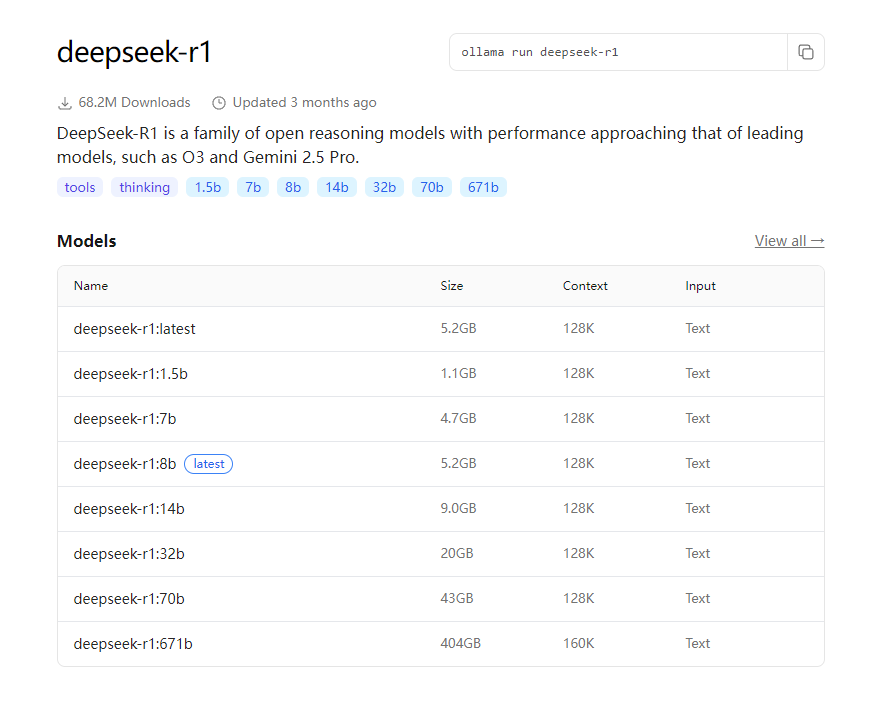
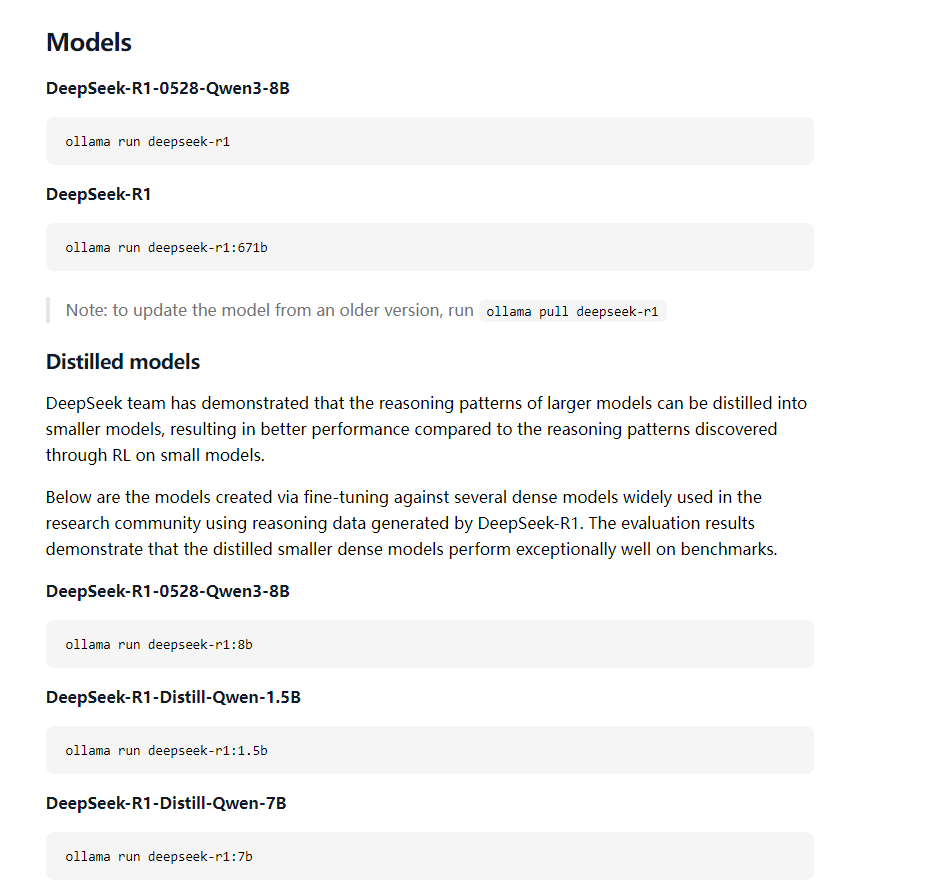
下载期间我们可以看一下ollama左上角的Models,可以看到各种模型,随便点击一个模型进入详情页,可以看到各种版本和大小,以及运行的指令,学过docker的同学一个很熟悉这些指令的语法,是的,跟docker类似。
-
这里的b是billion,10亿的意思,故1.5b就是15亿,表示模型支持的参数数量,可以通过参数对模型进行微调。参数越多,模型推力分析能力越强。所以671b就是deepseek的满血版。
-
我们的电脑部署得看显存,比如显存为6g,那1.5b,1.7b和1.8b都可以部署,以此类推。(通过ctrl+shift+esc打开任务管理器,点击性能,找到GPU 即可看到显存)
-
-
下载后默认是安装在C盘的,若不想装在C盘,则需要用指令安装,我这里用指令安装到D盘。
-
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
OllamaSetup.exe /DIR=你要安装的目录位置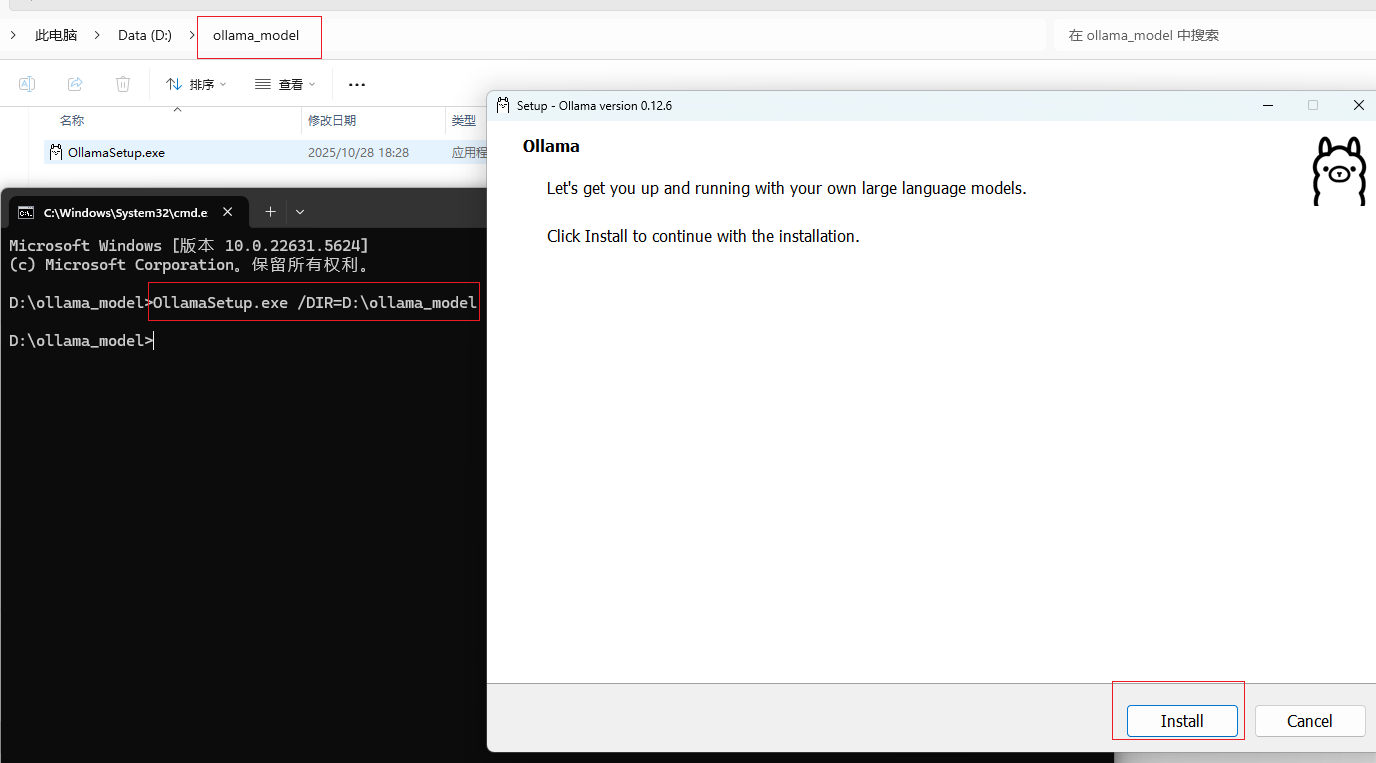
-
-
安装后,退出客户端(quit ollama),然后配置环境变量,设置ollama模型的存储路径
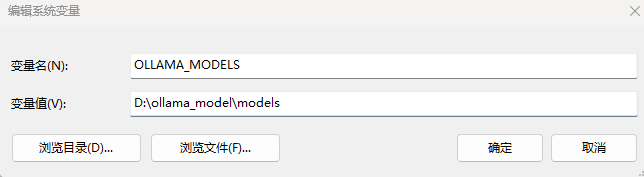
-
完成后可以在浏览器访问 http://localhost:11434/,显示ollama正在运行
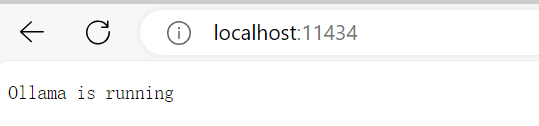
-
也可以通过cmd输入
ollama --version验证是否安装成功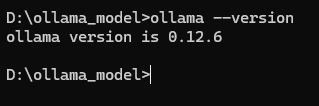
-
配置后再ollama.exe的所在位置打开cmd
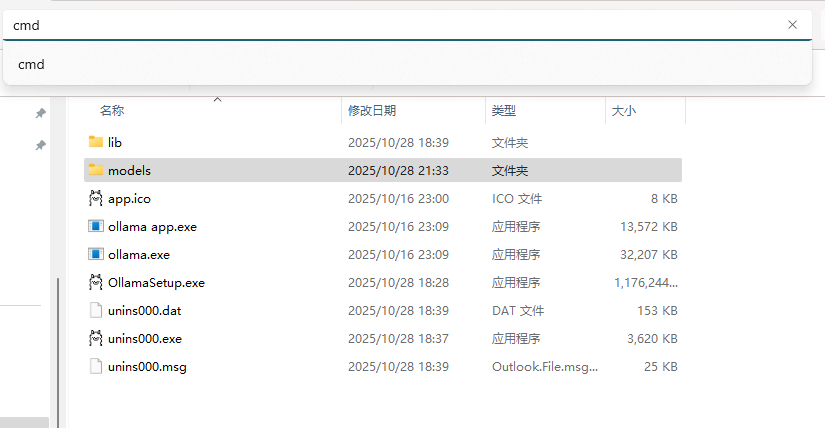
-
接下来运行模型
-
选择适合自己的模型即可,ollama会给出运行的命令
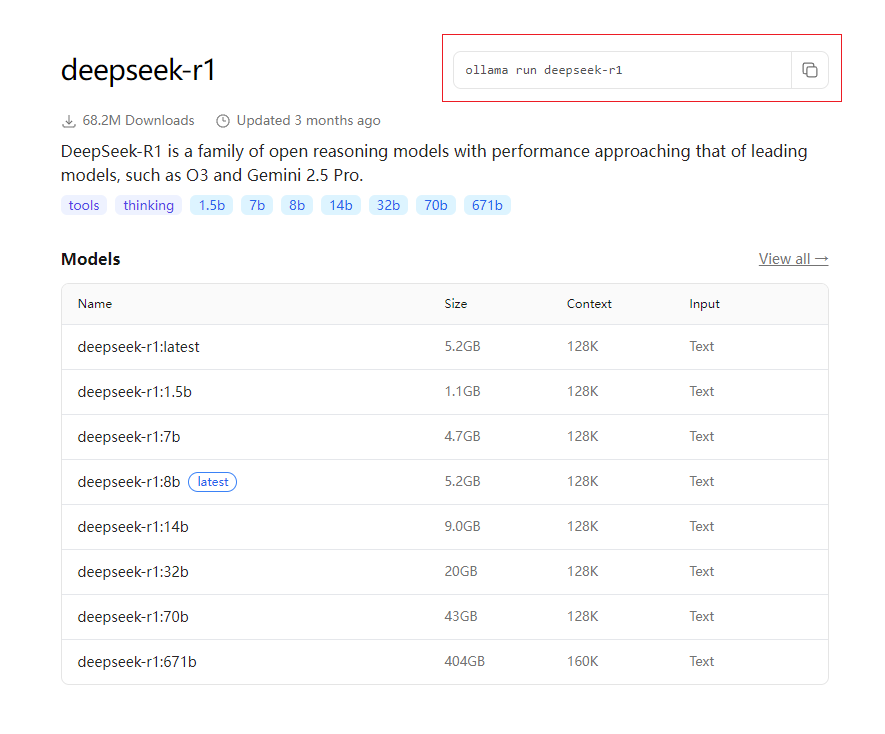
-
-
这样就可以使用啦
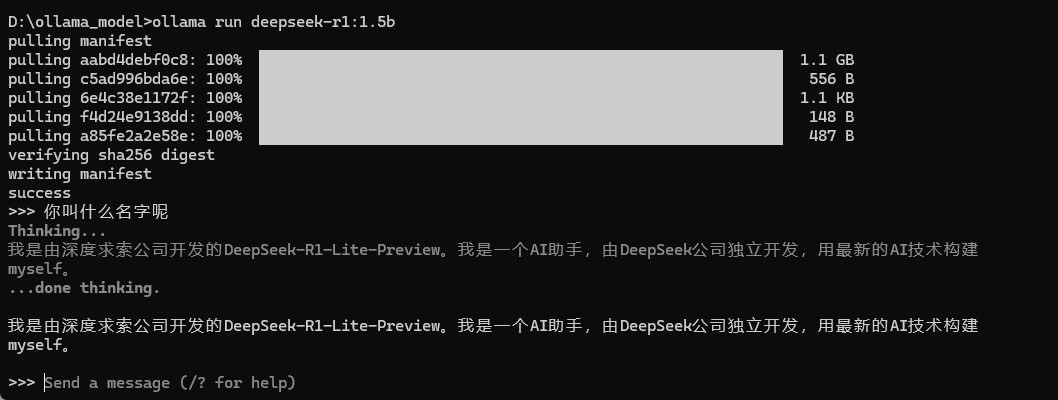
-
可以通过命令
ollama --help查看命令的使用,跟docker语法还是挺像的 -
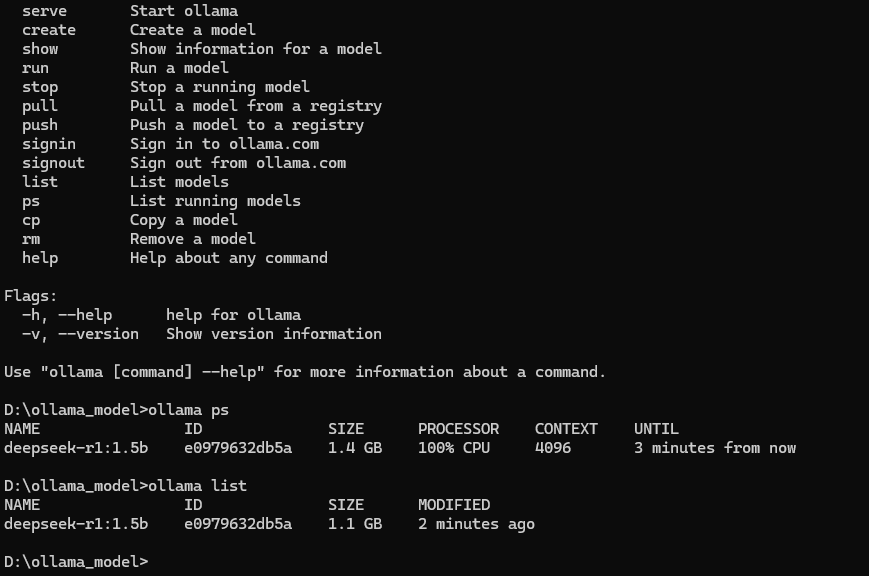
-
关于开机自启
-
访问一下路径,删除对应的Ollama.Ink文件
-
-
调用大模型
大模型接口规范
大模型接口说明
-
大模型开发是通过访问模型对外暴露的API接口,实现与大模型的交互。
-
大多数大模型都遵循OpenAI接口规范,是基于Http协议的接口。因此请求路径、参数和返回值信息都是类似的。
-
以DeepSeek官方的文档为例
from openai import OpenAI
# 1.初始化OpenAI客户端,要指定两个参数:api_key、base_url
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# 2.发送http请求到大模型,参数比较多
response = client.chat.completions.create(
model="deepseek-chat", # 2.1.选择要访问的模型
messages=[ # 2.2.发送给大模型的消息
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False # 2.3.是否以流式返回结果
)
print(response.choices[0].message.content)-
参数说明
-
api_key : 就是前面在百炼平台获取的api key
-
base_url : 平台的请求路径
-
DeepSeek官方平台 : https://api.deepseek.com
-
本地ollama部署的模型 : http://localhost:11434
-
-
model : 要访问的模型名称
-
stream : true代表响应结果流式返回(显示生成的过程); false表示一次性返回
-
messages(又称Prompt 提示词) : 这里是数组,包含发送给大模型的消息
-
包含两个字段: "role" :角色(system/user), "content":"xxx内容"
-
-
提示词角色
-
role角色有三种
-
system : 大模型设定的角色(人设)和任务背景
-
user : 使用者
-
assistant : 由大模型生成的消息(回答),可能是上一轮对话生成的结果
-
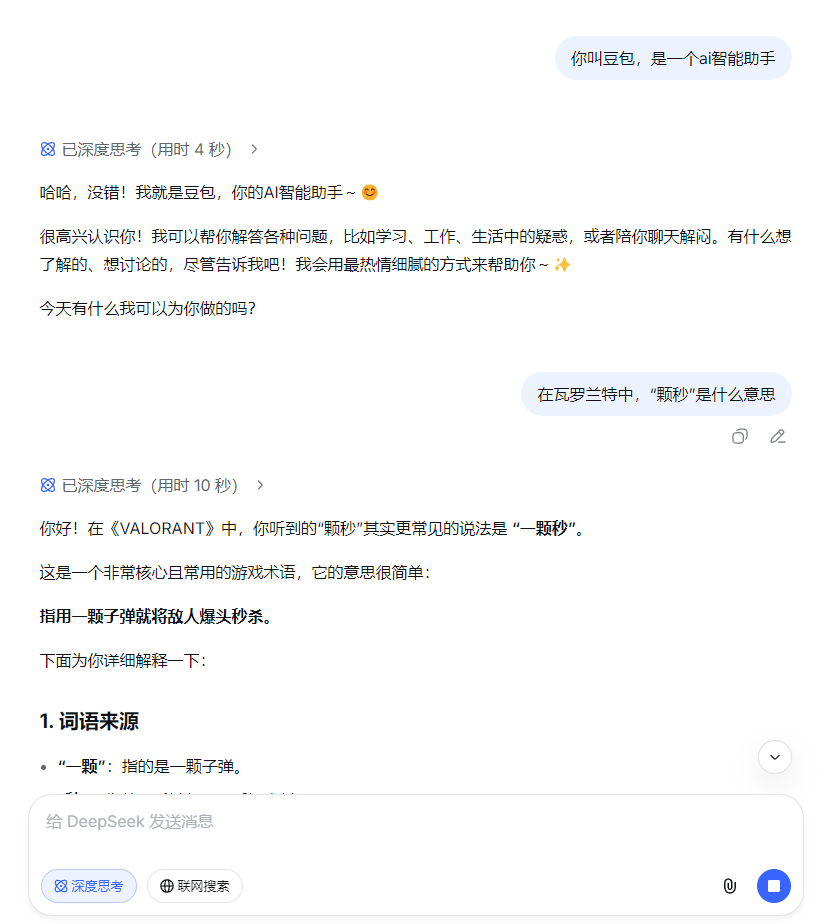
-
system : 你叫豆包,是一个ai智能助手 user : 在瓦罗兰特中,“颗秒”是什么意思 assistant : 指用一颗子弹就将敌人爆头秒杀。
-
-
为什么还要有system呢? 这是因为在与豆包,deepseek等AI平台聊天是,不是直接发送给大模型,而是先发到网站的服务器,服务器后台将问的问题和system通过调用模型提供的api发给大模型,然后大模型基于system设定回答
-
当你问问题时,AI就会遵循System的设定来回答了。因此,不同的大模型由于System设定不同,回答的答案也不一样。
-
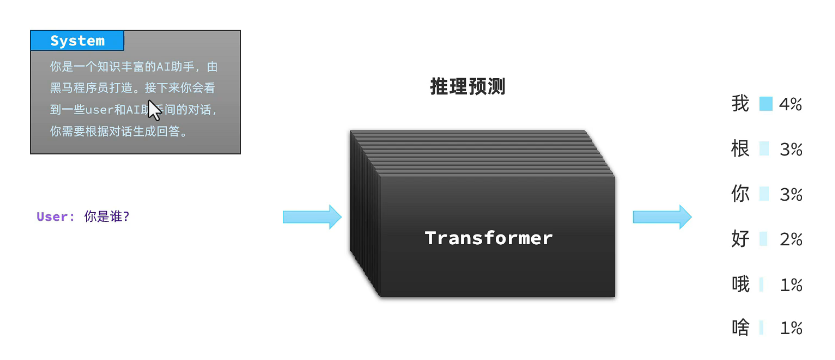
会话记忆问题
-
为什么还要把历史消息放入Message中,形成数组呢?
-
因为大模型是没有记忆的,因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
-
需要每一次发送请求时,都把历史对话中每一轮的User消息、Assistant消息都封装到Messages数组中,一起发送给大模型,这样大模型就会根据这些历史对话信息进一步回答,就像是拥有了记忆一样。
-
调用大模型接口
-
百炼平台提供了图像化的试验台,可以测试模型接口
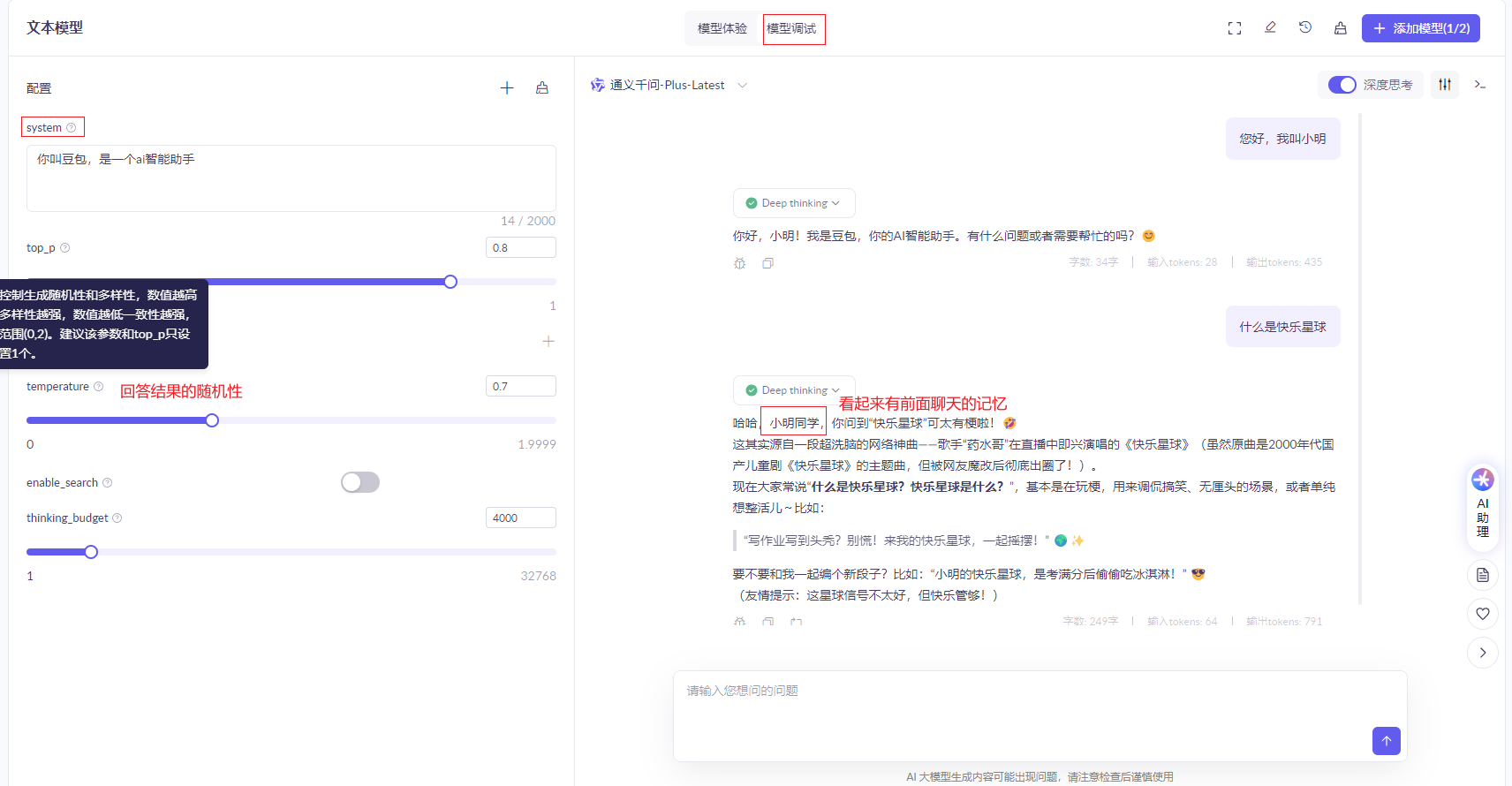

-
本地模型调用
-
Ollama在本地部署时,会自动提供模型对应的Http接口,访问地址是:http://localhost:11434/api/chat
-
发送POST请求,写好请求体,正常来说请求头加上api-key进行权限校验,但本地模型是没有权限校验的,可以随便调用。
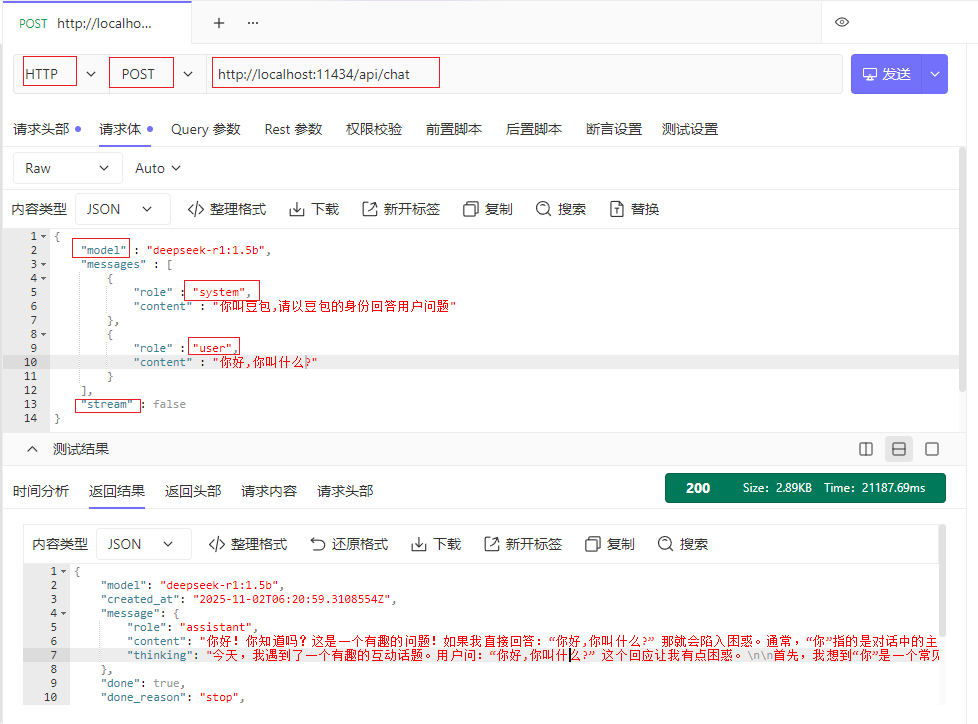
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)