大模型技术应用系列一:RAG 技术与应用
本文系统介绍了检索增强生成(RAG)技术的核心原理、应用场景及优化方法。RAG通过结合语言模型与外部知识检索,有效解决了大模型知识时效性、专业性和幻觉问题。文章详细解析了RAG三大核心阶段:数据准备(文档处理、向量化)、知识检索(混合检索、查询转换)和答案生成(提示词优化、动态防护栏),并提供了基于LangChain构建本地知识库的实践案例。通过阿里云、哈啰出行等企业实践,展示了RAG在提升检索精
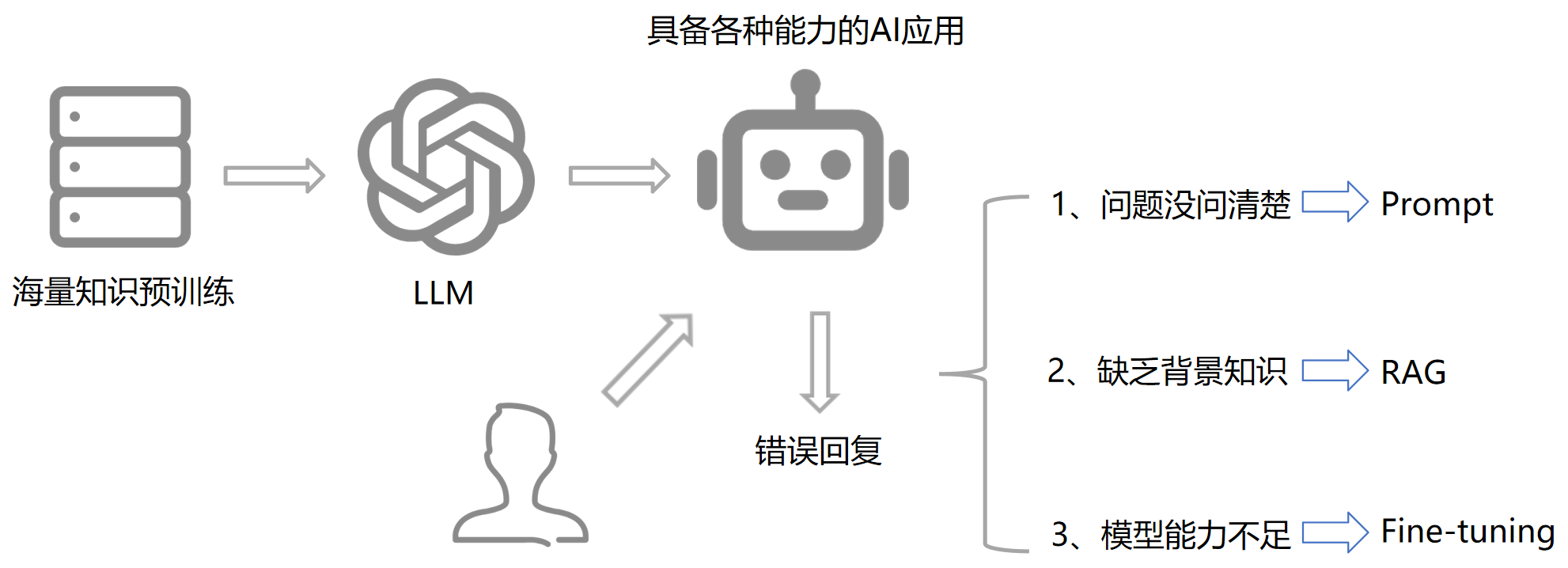
1. 大模型开发的三种模式
提示词:Prompt
检索增强:RAG
微调:Fine-tuning
三种手段的具体应用场景如下图所示。图中 LLM 指的是大模型。
2. RAG介绍
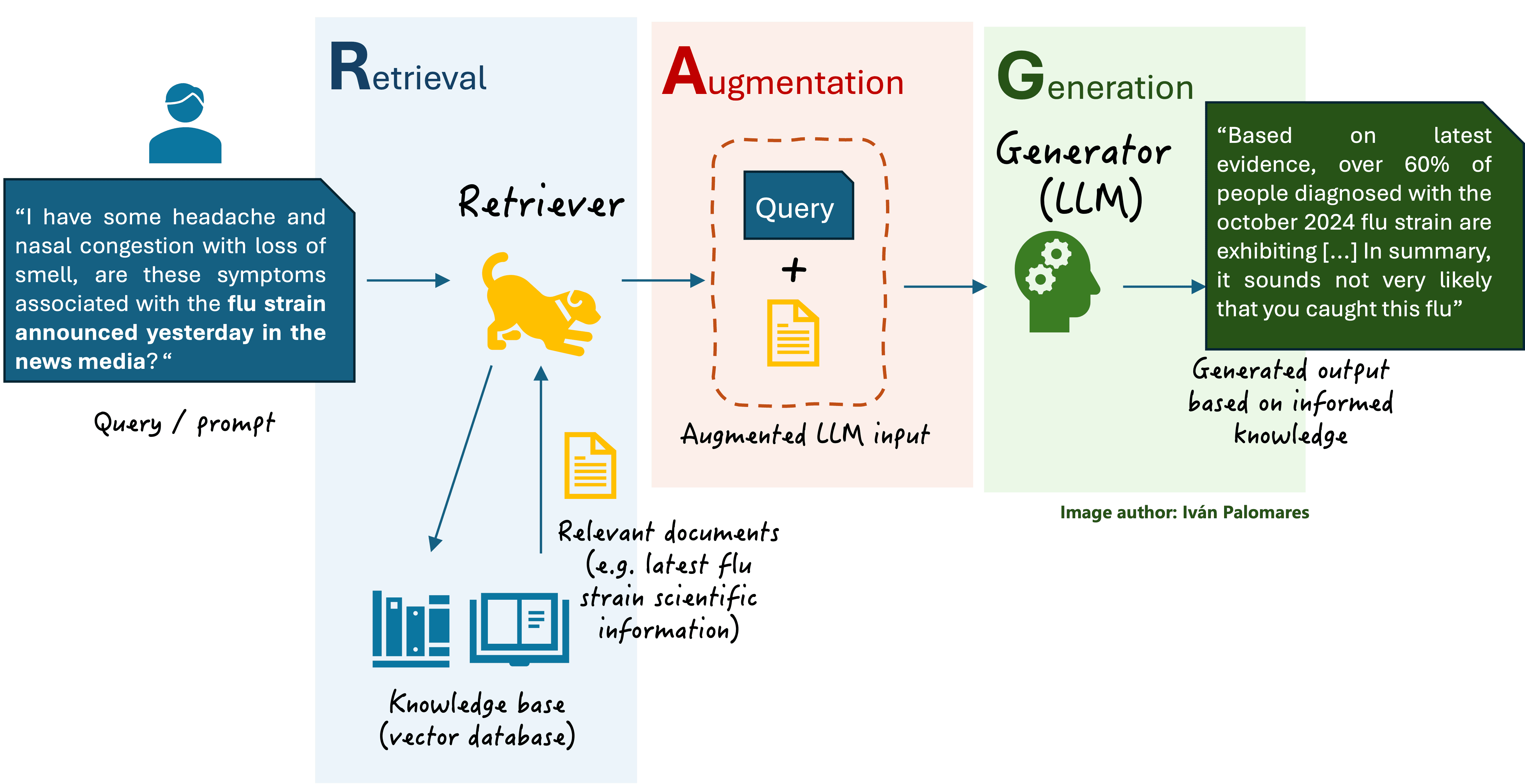
RAG的全称是Retrieval-Augmented Generation,即检索增强生成,是一种结合语言模型与语言信息检索技术的AI应用架构。其核心是通过检索外部知识库(如文档、数据库)来增强生成模型的回答准确性和相关性,常用于问答系统、智能客服等场景。
总体流程:提问、检索、增强、生成。
2.1 RAG的优势
解决知识时效性问题:大模型的训练数据通常是静态的,无法涵盖最新信息,而RAG可以检索外部知识库实时更新信息。
减少模型幻觉:通过引入外部知识,RAG能够减少模型生成虚假信息或不准确内容的可能性。
提升专业领域回答质量:RAG能够结合垂直领域的专业知识库,生成更具专业深度的回答。
生成内容的溯源:增强生成内容的可解释性。
2.2 RAG核心原理与流程
- 数据预处理,构建索引库
- 知识库构建:收集并整理文档、网页、数据等多源数据,构建外部知识库。
- 文档分块:将文档切分为大小合适的片段(chunks),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡
- 向量化处理:使用嵌入模型(如BGE、M3E、Chinese-Alpaca-2)将文本转换为向量,并存储在向量数据库中
- 检索阶段
- 查询处理:将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段。
- 重排序:对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入。
- 内容生成阶段
- 上下文组装:将检索到的文本片段与用户问题结合,形成增强的上下文输入。
- 生成回答:大语言模型基于增强的上下文生成最终答案。
RAG的本质就是重构一个新的Prompt。
BGE(北京智源人工智能研究院开发),它的特点是多语言支持:支持超过100种语言,包括中英等多语言模型,跨语言检索能力突出。模型结构:基于 Transformer(如BERT或RoBERT)微调,通过对比学习优化嵌入空间。应用场景:适用于语义检索、跨语言信息检索及多粒度文本处理(句子、段落、文档等)。源码地址:https://github.com/FlagOpen/FlagEmbedding
M3E(MokaAI开发):主要针对中文,支持双语处理,但多语言能力弱于BGE。模型架构采用混合嵌入技术,通过千万级中文句对数据训练,提升向量表达能力。应用场景专注于中文语义相似度计算和异质文本检索。HuggingFace地址:https://huggingface.co/moka-ai
Chinese-Alpaca-2:由哈尔滨工业大学讯飞联合实验室推出。
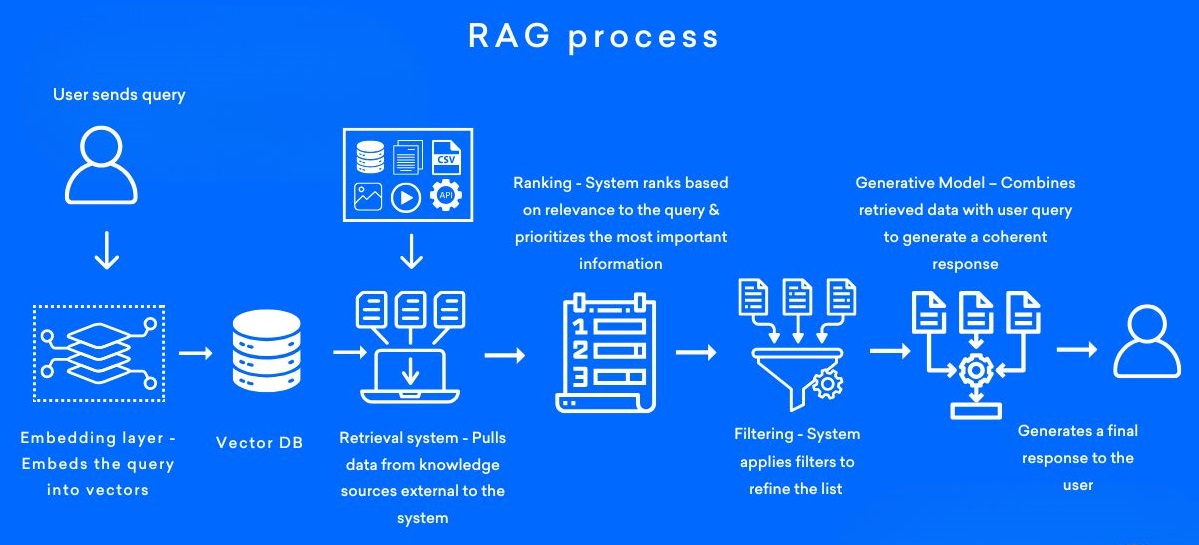
3. NativeRAG
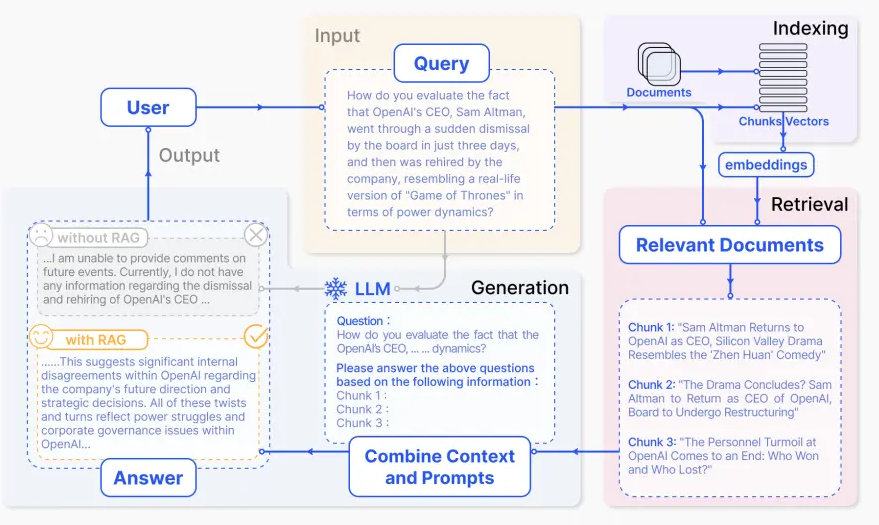
NativeRAG的步骤:
- Indexing => 如何更好的把知识存储起来。
- Retrieval => 如何在大量的知识中,找到一部分有用的,给到模型参考。
- Generation => 如何结合用户的提问和检索到的知识,让模型生成有用的答案。
上面三个步骤看似简单,但是在 RAG 应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容。
4. LangChain 快速搭建本地知识库检索
4.1 环境准备
1. 本地安装好 Conda 环境
2. 推荐使用阿里大模型百炼平台:https://bailian.console.aliyun.com/
4.2. 搭建流程
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
# !pip install pypdf2
# !pip install dashscope
# !pip install langchain
# !pip install langchain-openai
# !pip install langchain-community
# !pip install faiss-cpu
import os
import logging
import pickle
from PyPDF2 import PdfReader
from langchain_classic.chains.question_answering import load_qa_chain
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.callbacks.manager import get_openai_callback
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from typing import Tuple,List
def extract_text_with_page_number(pdf) -> Tuple[str, List[int]]:
"""
从 PDF 中提取文本并记录每行文本对应的页码。
:param pdf: PDF文件对象
:return:
text: 提取的文本内容
page_numbers: 每行文本对应的页码列表
"""
text = ""
page_numbers = []
for page_number, page in enumerate(pdf.pages, start=1):
extracted_text = page.extract_text()
if extracted_text:
text += extracted_text
page_numbers.extend([page_number] * len(extracted_text.split("\n")))
else:
logging.warning(f"Page {page_number} has no text")
return text, page_numbers
def process_text_with_splitter(text: str, page_numbers: List[int], save_path: str = None) -> FAISS:
"""
处理文本并创建向量存储
参数:
text: 提取的文本内容
page_numbers: 每行文本对应的页码列表
save_path: 可选,保存向量数据库的路径
返回:
knowledgeBase: 基于 FAISS 的向量存储对象
"""
# 创建文本分割器,用于将长文本分割成小块
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=512,
chunk_overlap=128,
length_function=len,
);
# 分割文本
chunks = text_splitter.split_text(text)
print(f"文本被分割成 {len(chunks)} 个块。")
# 创建嵌入模型,OpenAI嵌入模型,配置环境变量 OPEN_API_KEY
# embeddings = OpenAIEmbeddings()
# 调用阿里百炼平台文本嵌入模型,配置环境变量 DASHSCOPE_API_KEY
embeddings = DashScopeEmbeddings(model="text-embedding-v2")
# 从文本块创建知识库
knowledgeBase = FAISS.from_texts(chunks, embeddings)
print("已从文本块创建知识库...")
# 存储每个文本框对应的页码信息
page_info = {chunk: page_numbers[i] for i, chunk in enumerate(chunks)}
knowledgeBase.page_info = page_info
#如果提供了保存路径,则保存向量数据库和页码信息
if save_path:
# 确保目录存在
os.makedirs(save_path, exist_ok=True)
# 保存 FAISS 向量数据库
knowledgeBase.save_local(save_path)
print(f"向量数据库已保存到:{save_path}")
# 保存页码信息到同一目录
with open(os.path.join(save_path, "page_info.pkl"), "wb") as f:
pickle.dump(page_info, f)
print(f"页码信息已保存到:{os.path.join(save_path, 'page_info.pkl')}")
return knowledgeBase
def load_knowledge_base(load_path: str, embeddings = None) -> FAISS:
"""
从磁盘加载向量数据库和页码信息
:param load_path: 向量数据库保存路径
:param embeddings: 可选,嵌入模型。如果为 None,将创建一个新的 DashScopeEmbeddings 实例
:return:
knowledgeBase: 加载的 FAISS 向量数据库对象
"""
# 如果没有提供嵌入模型,则创建一个新的
if embeddings is None:
embeddings = DashScopeEmbeddings(model="text-embedding-v2")
# 加载 FAISS 向量数据库,添加 allow_dangerous_deserialization=True参数以允许反序列化
knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True)
print(f"向量数据库已经从 {load_path} 加载。")
# 加载页码信息
page_info_path = os.path.join(load_path, "page_info.pkl")
if os.path.exists(page_info_path):
with open(page_info_path, "rb") as f:
page_info = pickle.load(f)
knowledgeBase.page_info = page_info
print("页码信息已经加载。")
else:
print("警告:未找到页码提示文件。")
return knowledgeBase
# 读取pdf文件
pdf_reader = PdfReader("./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf")
# 提取文本和页码信息
text, page_numbers = extract_text_with_page_number(pdf_reader)
print(f"提取的文本长度:{len(text)} 个字符")
# 处理文本并创建知识库,同时保存到磁盘
save_dir = "./vector_db"
knowledgeBase = process_text_with_splitter(text, page_numbers, save_path=save_dir)
knowledgeBase
from langchain_community.llms import Tongyi
# 设置查询问题
# query = "客户经理被投诉了,投诉一次扣多少分?"
query = "腹部下午吃点东西就胀的厉害怎么治疗?"
if query:
# 示例:如何加载已保存的向量数据库
# 注释掉以下代码以避免在当前运行中重复加载
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2"
)
# 从磁盘加载向量数据库
loaded_knowledgeBase = load_knowledge_base("./vector_db", embeddings)
# 使用加载的知识库进行查询
docs = loaded_knowledgeBase.similarity_search(query)
# 初始化对话大模型
DASHSCOPE_API_KEY = os.getenv("DASHSCOPE_API_KEY"),
llm = Tongyi(model_name="deepseek-v3", dashscope_api_key=DASHSCOPE_API_KEY)
# 加载问答链
chain = load_qa_chain(llm, chain_type="stuff")
# 准备输入数据
input_data = {"input_documents": docs, "question": query}
# 使用回调函数跟踪API调用成本
with get_openai_callback() as cost:
# 执行问答链
response = chain.invoke(input=input_data)
print(f"查询已处理。成本: {cost}")
print(response["output_text"])
print("来源:")
# 记录唯一的页码
unique_pages = set()
# 显示每个文档块的来源页码
for doc in docs:
text_content = getattr(doc, "page_content", "")
source_page = knowledgeBase.page_info.get(
text_content.strip(), "未知"
)
if source_page not in unique_pages:
unique_pages.add(source_page)
print(f"文本块页码: {source_page}")
小结:
1. PDF文本提取与处理
-
使用PyPDF2库的PdfReader从PDF文件中提取文本在提取过程中记录每行文本对应的页码,便于后续溯源
-
使用RecursiveCharacterTextSplitter将长文本分割成小块,便于向量化处理
2. 向量数据库构建
-
使用OpenAIEmbeddings / DashScopeEmbeddings将文本块转换为向量表示
-
使用FAISS向量数据库存储文本向量,支持高效的相似度搜索为每个文本块保存对应的页码信息,实现查询结果溯源
3. 语义搜索与问答链
-
基于用户查询,使用similarity_search在向量数据库中检索相关文本块
-
使用文本语言模型和load_qa_chain构建问答链将检索到的文档和用户问题作为输入,生成回答
4. 成本跟踪与成果展示
-
使用get_openai_callback跟踪API调用成本
-
展示问答结果和来源页码,方便用户验证信息
5. 三大阶段有效提升RAG质量方法
5.1 数据准备阶段
5.1.1. 常见问题
-
数据质量差: 企业大部分数据(尤其是非结构化数据)缺乏良好的数据治理,未经标记/评估的非结构化数据可能包含敏感、过时、矛盾或不正确的信息。
-
多模态信息: 提取、定义和理解文档中的不同内容元素,如标题、配色方案、图像和标签等存在挑战。
-
复杂的PDF提取: PDF是为人类阅读而设计的,机器解析起来非常复杂。
5.1.2. 如何提升数据准备阶段的质量
-
构建完整的数据准备流程
-
采用智能文档技术
(1)构建完整的数据准备流程
1. 数据评估与分类
- 数据审计:全面审查现有数据,识别敏感、过时、矛盾或不准确的信息。
- 数据分类:按类型、来源、敏感性和重要性对数据进行分类,便于后续处理。
2. 数据清洗
- 去重:删除重复数据
- 纠错:修正格式错误、拼写错误等
- 更新:替换过时信息,确保数据时效性
- 一致性检查:解决数据矛盾,确保逻辑一致
3. 敏感信息处理
- 识别敏感数据:使用工具或正则表达式识别敏感信息,如个人身份信息
- 脱敏或加密:对敏感数据进行脱敏处理,确保合规。
4. 数据标记与标注
- 元数据标记:为数据添加元数据,如来源、创建时间等
- 内容标注:对非结构化数据进行标注,便于后续检索和分析
5. 数据治理框架
- 制定政策:明确数据管理、访问控制和更新流程
- 责任分配:指定数据治理负责人,确保政策执行
- 监控与审计:定期监控数据质量,进行审计
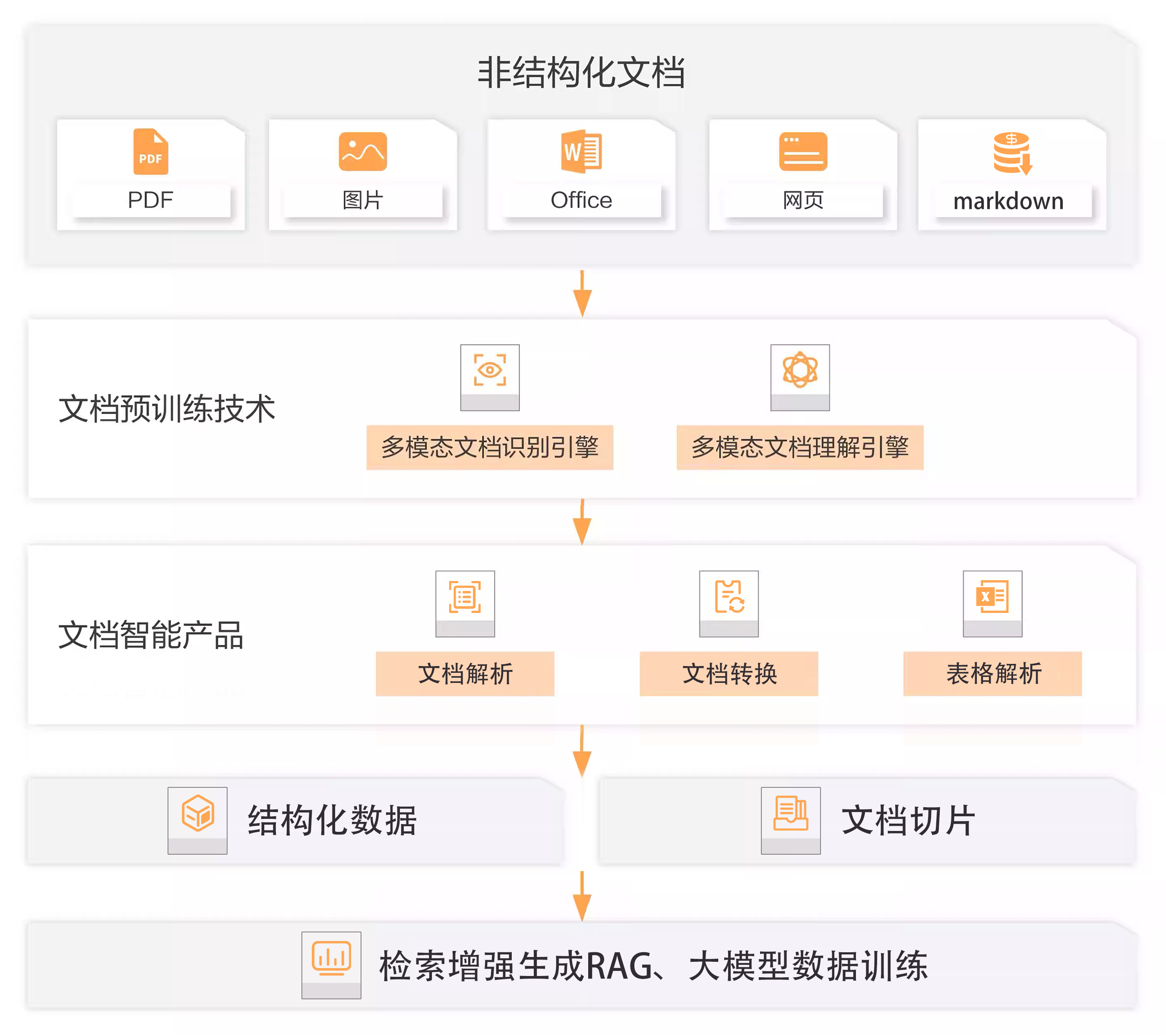
(2)智能文档技术
阿里文档智能:https://www.aliyun.com/product/ai/docmind?spm=a2c4g.11174283.0.0.bfe667a8tIVMdG
微软 LayoutLMv3:https://www.microsoft.com/en-us/research/articles/layoutlmv3/
上海人工智能实验室MinerU:https://mineru.net/
一般做知识库构建时,需要将 pdf 文件转换为 markdown 格式文档。
5.2 知识检索阶段
5.2.1. 常见问题
-
内容缺失: 当检索过程缺少关键内容时,系统会提供不完整、碎片化的答案 => 降低RAG的质量
-
错过排名靠前的文档: 用户查询相关的文档时被检索到,但相关性极低,导致答案不能满足用户需求,这是因为在检索过程中,用户通过主观判断决定检索“文档数量”。理论上所有文档都要被排序并考虑进一步处理,但在实践中,通常只有排名top k的文档才会被召回,而k值需要根据经验确定。
-
不在上下文中: 从数据库中检索出包含答案的文档,但未能包含在生成答案的上下文中。这种情况通常发生在返 回大量文件时,需要进行整合以选择最相关的信息。
5.2.2. 如何提升知识检索阶段的质量?
-
通过查询转换澄清用户意图:明确用户意图,提高检索准确性。
-
采用混合检索和重排策略:确保最相关的文档被优先处理,生成更准确的答案。
(1)通过查询转换澄清用户意图
-
场景:用户询问 “如何申请信用卡?”
-
问题:用户意图可能模糊,例如不清楚是申请流程、所需材料还是资格条件。
-
解决方法:通过查询转换明确用户意图。
-
实现步骤:
-
意图识别:使用自然语言处理技术识别用户意图。例如,识别用户是想了解流程、材料还是资格。
-
查询扩展:根据识别结果扩展查询。例如:
- 如果用户想了解流程,查询扩展为“信用卡申请的具体步骤”
- 如果用户想了解材料,查询扩展为“申请信用卡需要哪些材料”
- 如果用户想了解资格,查询扩展为“申请信用卡的资格条件”
-
检索:使用扩展后的查询检索相关文档
-
-
示例:
-
用户输入:“如何申请信用卡?”
-
系统识别意图为
流程,扩展查询为信用卡申请的具体步骤 -
检索结果包含详细的申请步骤文档,系统生成准确答案
-
(2)混合检索和重排策略
-
场景:用户询问“信用卡年费是多少?”
-
问题:直接检索可能返回大量文档,部分相关但排名低,导致答案不准确。
-
解决方法:采用混合检索和重排策略。
步骤:
- 混合检索:结合关键词检索和语义检索。比如:关键词检索:“信用卡年费”。
- 语义检索:使用嵌入模型检索与“信用卡年费”语义相近的文档。
- 重排:对检索结果进行重排。
- 生成答案:从重排后的文档中生成答案。
示例:
-
用户输入:“信用卡年费是多少?”
-
系统进行混合检索,结合关键词和语义检索。
-
重排后,最相关的文档(如“信用卡年费政策”)排名靠前。
-
系统生成准确答案:“信用卡年费根据卡类型不同,普通卡年费为100元,金卡为300元,白金卡为1000元。”
5.3 答案生成阶段
5.3.1 常见问题
- 未提取:答案与提供的上下文相符,但大语言模型却无法准确提取。这种情况通常发生在上下文中存在过多噪声或者相互冲突的信息时。
-
不完整: 尽管能够利用上下文生成答案,但信息缺失会导致对用户查询的答复不完整。格式错误:当prompt中的附加指令格式不正确时,大语言模型可能误解或曲解这些指令,从而导致错误的答案。
-
幻觉: 大模型可能会产生误导性或虚假性信息。
5.3.2. 如何提升答案生成阶段的质量
-
改进提示词模板
-
实施动态防护栏
(1)改进提示词模板
| 场景 | 原始提示词 | 改进后的提示词 |
|---|---|---|
| 用户询问“如何申请信用卡?” | “根据以下上下文回答问题:如何申请信用卡?” | “根据以下上下文,提取与申请信用卡相关的具体步骤和所需材料:如何申请信用卡?” |
| 用户询问“信用卡的年费是多少?” | “根据以下上下文回答问题:信用卡的年费是多少?” | “根据以下上下文,详细列出不同信用卡的年费信息,并说明是否有减免政策:信用卡的年费是多少?” |
| 用户询问“什么是零存整取?” | “根据以下上下文回答问题:什么是零存整取?” | “根据以下上下文,准确解释零存整取的定义、特点和适用人群,确保信息真实可靠:什么是零存整取?” |
如何对原有的提示词进行优化?
可以通过 DeepSeek-R1 或 QWQ 的推理链,对提示词进行优化:
-
信息提取:从原始提示词中提取关键信息。
-
需求分析:分析用户的需求,明确用户希望获取的具体信息。
-
提示词优化:根据需求分析的结果,优化提示词,使其更具体、更符合用户的需求。
(2)实施动态防护栏
动态防护栏(Dynamic Guardrails)是一种在生成式AI系统中用于实时监控和调整模型输出的机制,旨在确保生成的内容符合预期、准确且安全。它通过设置规则、约束和反馈机制,动态地干预模型的生成过程,避免生成错误、不完整、不符合格式要求或含有虚假信息(幻觉)的内容。
在RAG系统中,动态防护栏的作用尤为重要,因为它可以帮助解决以下问题:
-
未提取:确保模型从上下文中提取了正确的信息。
-
不完整:确保生成的答案覆盖了所有必要的信息。
-
格式错误:确保生成的答案符合指定的格式要求。
-
幻觉:防止模型生成与上下文无关或虚假的信息。
场景1:防止未提取
用户问题:“如何申请信用卡?”
-
上下文:包含申请信用卡的步骤和所需材料。
-
动态防护栏规则:检查生成的答案是否包含“步骤”和“材料”。如果缺失,提示模型重新生成。
-
示例:
-
错误输出:“申请信用卡需要提供一些材料。”
-
防护栏触发:检测到未提取具体步骤,提示模型补充。
-
场景2:防止不完整
用户问题:“信用卡的年费是多少?”
-
上下文:包含不同信用卡的年费信息。
-
动态防护栏规则:检查生成的答案是否列出所有信用卡的年费。如果缺失,提示模型补充。
-
示例:
-
错误输出:“信用卡A的年费是100元。”
-
防护栏触发:检测到未列出所有信用卡的年费,提示模型补充。
-
场景3:防止幻觉
用户问题:“什么是零存整取?”
-
上下文:包含零存整取的定义和特点。
-
动态防护栏规则:检查生成的答案是否与上下文一致。如果不一致,提示模型重新生成。
-
示例:
-
错误输出:“零存整取是一种贷款产品。
-
防护栏触发:检测到与上下文不一致,提示模型重新生成。
-
如何实现动态防护栏技术?
事实性校验规则,在生成阶段,设置规则验证生成内容是否与检索到的知识片段一致。例如,可以使用参考文献验证机制,确保生成内容有可靠来源支持,避免输出矛盾或不合理的回答。
如何制定事实性校验规则?
当业务逻辑明确且规则较为固定时,可以人为定义一组规则,比如:
- 规则1:生成的答案必须包含检索到的知识片段中的关键实体(如“年费”、“利率”)。
- 规则2:生成的答案必须符合指定的格式(如步骤列表、表格等)。
- 实施方法:
- 使用正则表达式或关键词匹配来检查生成内容是否符合规则。
- 例如,检查生成内容是否包含“年费”这一关键词,或者是否符合步骤格式(如“1. 登录;2. 设置”)。
6. RAG在不同阶段提升质量的实践
-
数据准备环节,阿里云考虑到文档具有多层标题属性且不同标题之间存在关联性,提出多粒度知识提取方案,按照不同标题级别对文档进行拆分,然后基于Qwen14b模型和RefGPT训练了一个面向知识提取任务的专属模型,对各个粒度的chunk进行知识提取和组合,并通过去重和降噪的过程保证知识不丢失、不冗余。最终将文档知识提取成多个事实型对话,提升检索效果;
-
知识检索环节,哈啰出行采用多路召回的方式,主要是向量召回和搜索召回。其中,向量召回使用了两类,一类是大模型的向量、另一类是传统深度模型向量;搜索召回也是多链路的,包括关键词、ngram等。通过多路召回的方式,可以达到较高的召回查全率。
-
答案生成环节,中国移动为了解决事实性不足或逻辑缺失,采用FoRAG两阶段生成策略,首先生成大纲,然后基于大纲扩展生成最终答案。
7. QA
如果LLM可以处理无限上下文了,RAG还有意义吗?
-
效率与成本:LLM处理长上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
-
知识更新:LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
-
可解释性:RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
-
定制化:RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
-
数据隐私:RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
-
结合LLM的生成能力和RAG的检索能力,可以提升整体性能,提供更全面、准确的回答。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)