Dify私有化部署之Xinference部署及接入AI大模型
Dify随着大家的深入使用,发现ollama部署大模型虽然方便,但是Dify知识库混合检索,需要有rerank模型,这一点上,ollama是不直接支持rerank模型的。因此,本篇文章我们讲解下如何部署Xinference,并基于该产品安装大模型,接入Dify。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
Dify随着大家的深入使用,发现ollama部署大模型虽然方便,但是Dify知识库混合检索,需要有rerank模型,这一点上,ollama是不直接支持rerank模型的。因此,本篇文章我们讲解下如何部署Xinference,并基于该产品安装大模型,接入Dify。
一、什么是Xinference?
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,我们可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。
它支持的模型种类有:
- 语言模型:比如 qwen2、baichuan、deepseek、gemma 等场景的语言模型
- Embedding 模型:有 Jina 的 Embedding 模型(结合 Rerank,知识库检索不就起来了嘛 );
- Rerank 模型:有 Jina 的 Rerank 模型;
- 图像模型:除了 Stable Diffusion 之外,还有 Flux 模型
- 语音模型:有 ChatTTS以及 whisper 等等;
- 视频模型:这类模型还没了解过,Xinference 里是 CogVideoX 模型;
- 自定义模型:需要先注册,然后才可以在这里看到;
相较于 Ollama 来说,Xinference 在部署之后会为我们提供一个可视化界面,我们可以通过图形化界面安装部署大模型。
【xinference的官网链接】https://inference.readthedocs.io/zh-cn/latest/index.html
【github链接】https://github.com/xorbitsai/inference
二、安装Xinference
Xinference 在 Dockerhub 和 阿里云容器镜像服务 中上传了官方镜像。本地安装Dify已经有部署了docker,因此这里直接基于docker来安装Xinference。
1、 准备工作
- Xinference 使用 GPU 加速推理,该镜像需要在有 GPU 显卡并且安装 CUDA 的机器上运行。
- 保证 CUDA 在机器上正确安装。可以使用 nvidia-smi 检查是否正确运行。
- 镜像中的 CUDA 版本为 12.4 。为了不出现预期之外的问题,请将宿主机的 CUDA 版本和 NVIDIA Driver 版本分别升级到 12.4 和 550 以上。
2、拉取并使用镜像
默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
打开docker容器终端,直接参考官方文档,输入如下命令拉取镜像并启动Xinference。
docker run -d --name xinference -v d:\xinference:/root/xinference -v d:\xinference\.xinference:/root/.xinference -v d:\xinference\.cache/huggingface:/root/.cache/huggingface -v d:\xinference\.cache/modelscope:/root/.cache/modelscope -e XINFERENCE_HOME=/root/xinference -p 9998:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0参数解释:
• --name : 设置容器名称
•-v d:\xinference:/root/xinference -e XINFERENCE_HOME=/root/xinference :将主机上指定的目录挂载到容器中,并设置 XINFERENCE_HOME 环境变量指向容器内的该目录。这样,所有下载的模型文件将存储在您在主机上指定的目录中。您无需担心在 Docker 容器停止时丢失这些文件,下次运行容器时,您可以直接使用现有的模型,无需重复下载。
•-v d:\xinference\.xinference:/root/.xinference -v d:\xinference\.cache/huggingface:/root/.cache/huggingface -v d:\xinference\.cache/modelscope:/root/.cache/modelscope:由于 xinference cache 目录是用的软链的方式存储模型,需要将原文件所在的目录也挂载到容器内。例如你使用 huggingface 和 modelscope 作为模型仓库,那么需要将这两个对应的目录挂载到容器内,一般对应的 cache 目录分别在 <home_path>/.cache/huggingface 和 <home_path>/.cache/modelscope
• -p 9998:9997:将容器内的9997端口映射到宿主机的 9998 端口
• --gpus :必须指定,正如前文描述,镜像必须运行在有 GPU 的机器上,否则会出现错误。
• -H 0.0.0.0 :也是必须指定的,否则在容器外无法连接到 Xinference 服务。
• 可以指定多个 -e 选项赋值多个环境变量。
运行结束后,可以看到已经启动的容器,接下来可以访问它的UI界面了。

如果你是linux系统,并且有docker服务,那么同样可以通过上述docker命令完成 Xinference镜像拉取和启动!
这里通过docker查看实时的日志文件,
# 进入容器
docker exec -it xinference /bin/bash
# 进入到 /root/xinference/logs 目录下找到xinference.log
cd /root/xinference/logs
# 查看实时日志
tail -f xinference.log3、访问Xinference界面
浏览器输入:http://localhost:9997, 回车。即可访问界面。
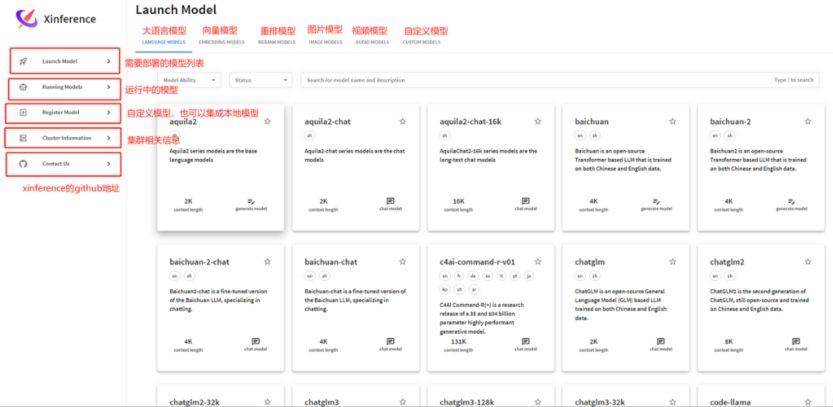
三、基于Xinference下载模型
下载模型,因为要去模型仓库拉取模型,默认两个:huggingface和modelscope。所以这里下载模型需要科学上网。
1、 下载大语言模型
下载一个简单的模型,以qwen3为例
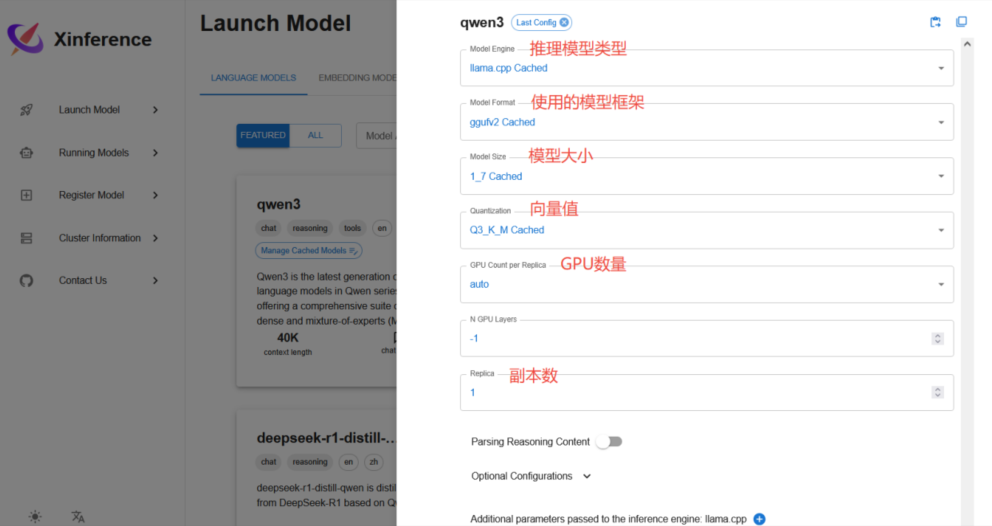
1-模型引擎
Transformers:依赖Hugging Face Transformers库,适用于标准PyTorch或TensorFlow部署,通常兼容性比较好,支持多种硬件加速(如GPU)。
vLLM:适用于高吞吐量推理,利用PagedAttention进行优化,推荐用于大规模推理场景,减少显存占用。
SGLang : 可能是专门优化的推理引擎,具体表现需要查看官方文档或测试。
llama.cpp: 适用于CPU运行,优化了低资源设备上的LLM推理,适合本地运行或嵌入式环境。
—》选择建议:
- 高性能CPU推理:vLLM
- 通用部署(PyTorch或TensorFlow支持):Transformers
- 低资源或本地运行(CPU推理):llama.cpp
- 特定优化需求:SGLang
2-模型格式
Pytorch: 原生PyTorch格式,未量化,最高精度但占用更多显存。适用于高精度推理,但对硬件要求较高。
awq: 量化方案,主要优化激活值感知权重量化,可以减少推理时的计算开销,同时保持较高的精度。适用于低显卡GPU或高吞吐量场景,如vLLM和llama.cpp。适合于多种硬件,特别是NVIDIA GPU运行。
gptq: 另一种 后训练量化 方法,目标是 最小化量化误差,尤其对Transformers模型进行优化。gptq通常比AWQ更轻量,适用于 极限压缩场景(如4-bit GPTQ)。适用于低功耗设备 或 超大型的轻量化部署。
—》选择建议:
- 如果显存足够,追求最佳模型精度 :pytorch
- 如果需要在低显存GPU(如24GB以内)高效推理:awq
- 如果显存极其受限(如16GB或更低),或需要极端优化:gptq
填写完后,点击下方小火箭,即可部署。需耐心等待下载部署完成。部署完成后,可以在日志看到,并且如下界面看到运行的模型:
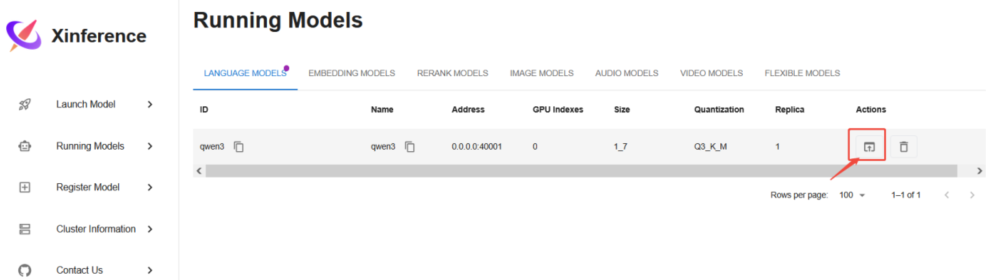
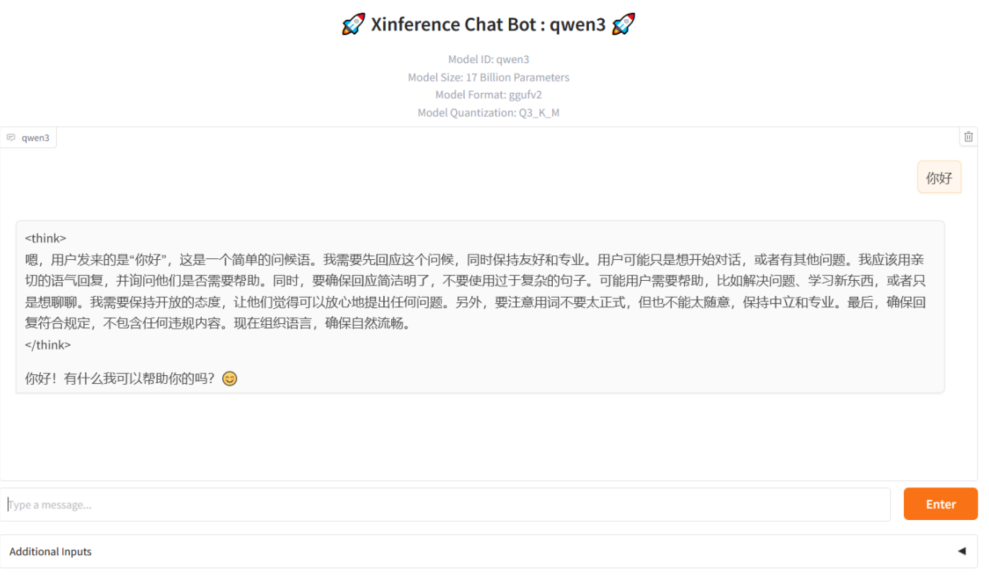
点击如上,可通过问答测试模型
2、 下载Embedding模型
点击 Embedding模型,这里我们选择排名较靠前的 bge-large-zh-v1.5
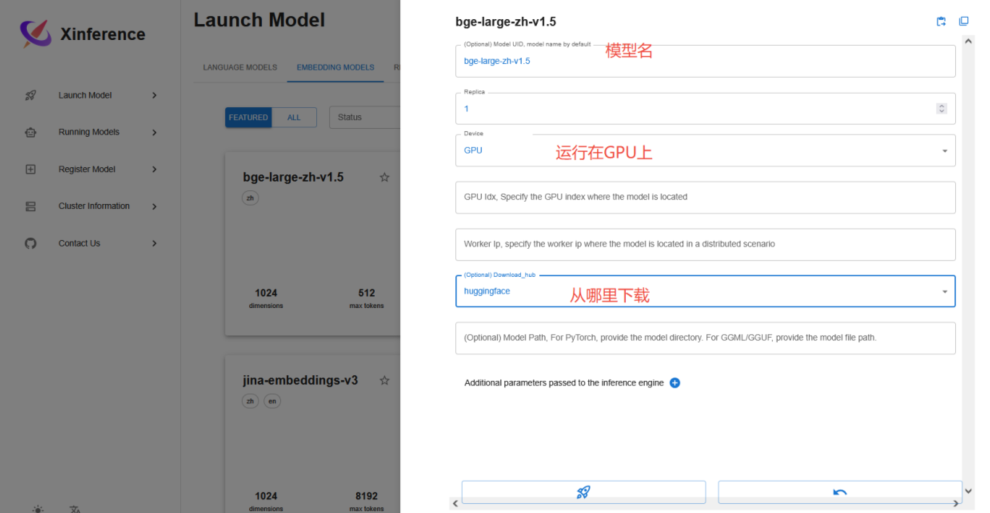
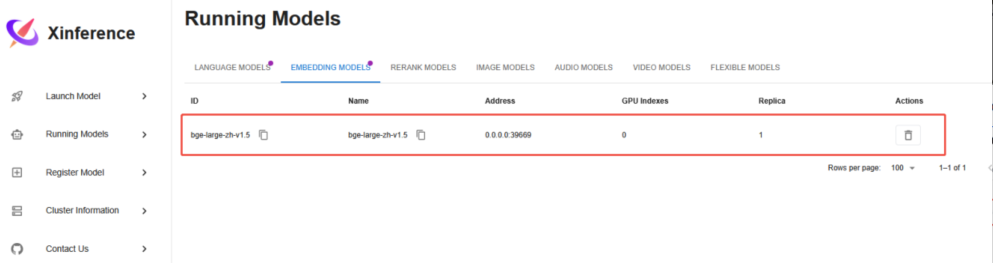
下载完成后,Running Models,可以看到正在运行的 embedding模型。
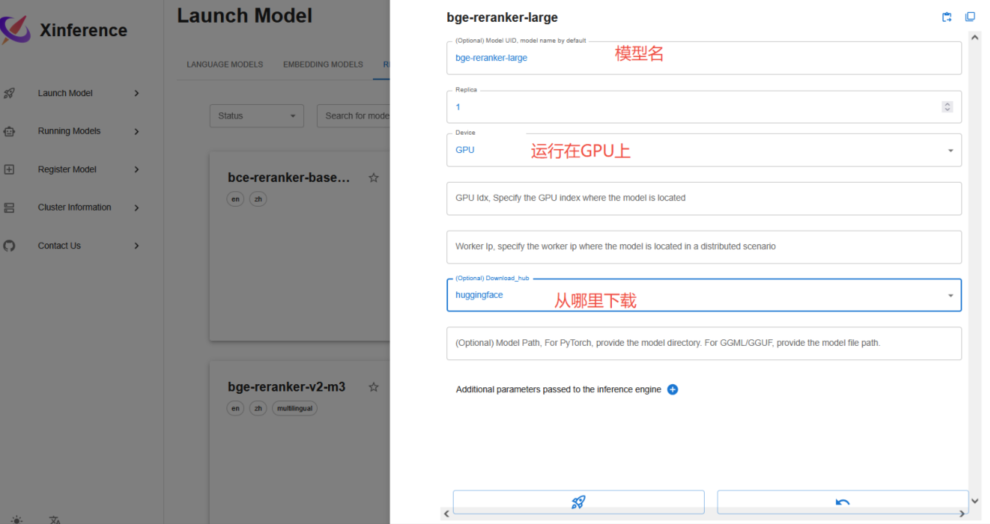
3、 下载Rerank模型
切换到rerank模型,这里我们选择bge系列的 bge-reranker-large
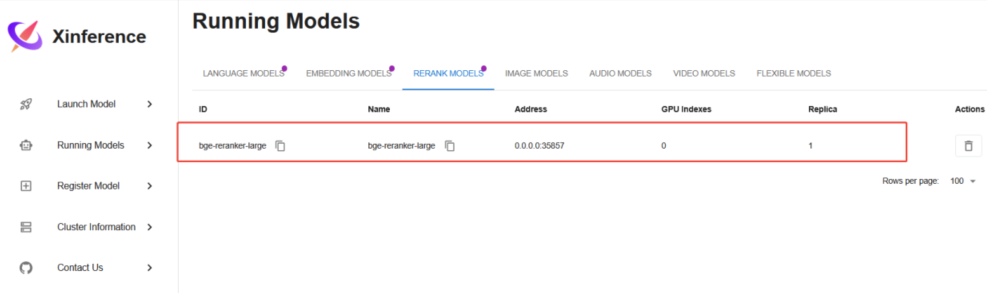
下载完成后,Running Models,可以看到正在运行的 rerank 模型。
这里目前先给大家演示这三种模型下载,其他模型,图像模型、视频模型等这个自己看智能体开发需求,再去对应下载即可。
四、在Dify接入在xinference中安装的模型
1、安装xinference插件
访问dify,点击右上角个人头像 - 设置 - 模型供应商,安装xinference插件
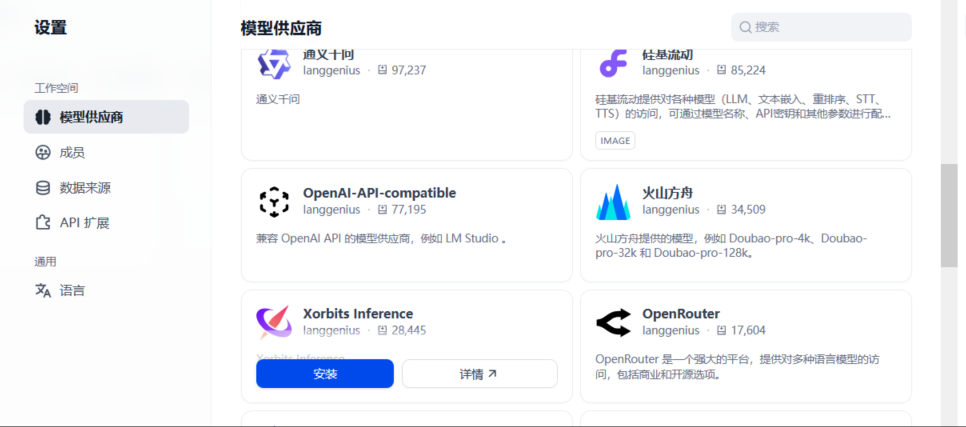
下载完成后,待配置 可看到
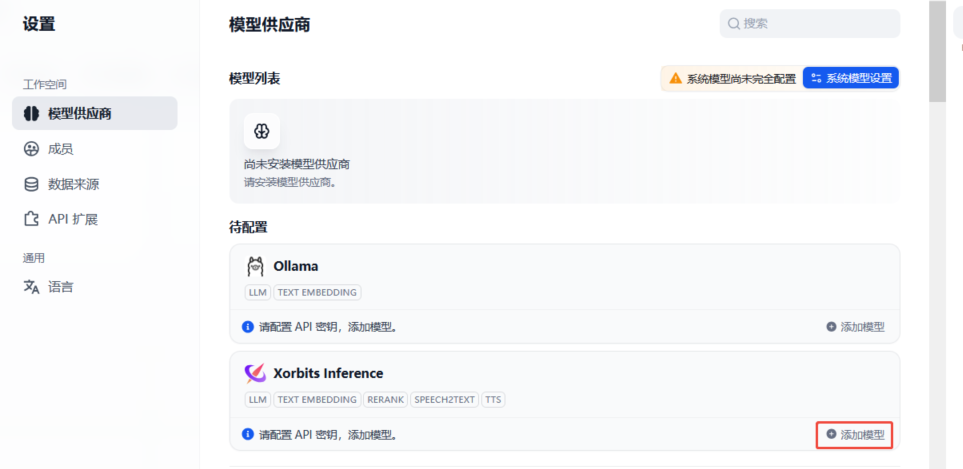
2、配置模型
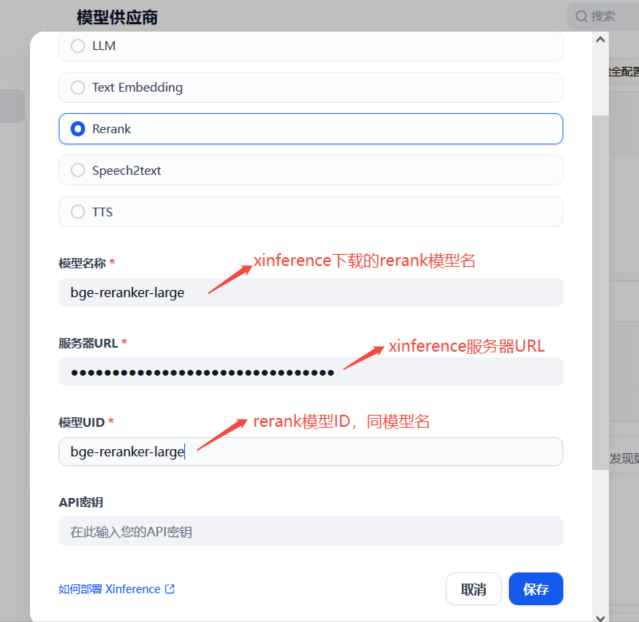
基于安装好的xinference插件,点击“添加模型”, 在弹出的页面主要填写信息:
模型类型、模型名称、模型ID,xinference服务器URL,其他选项默认。
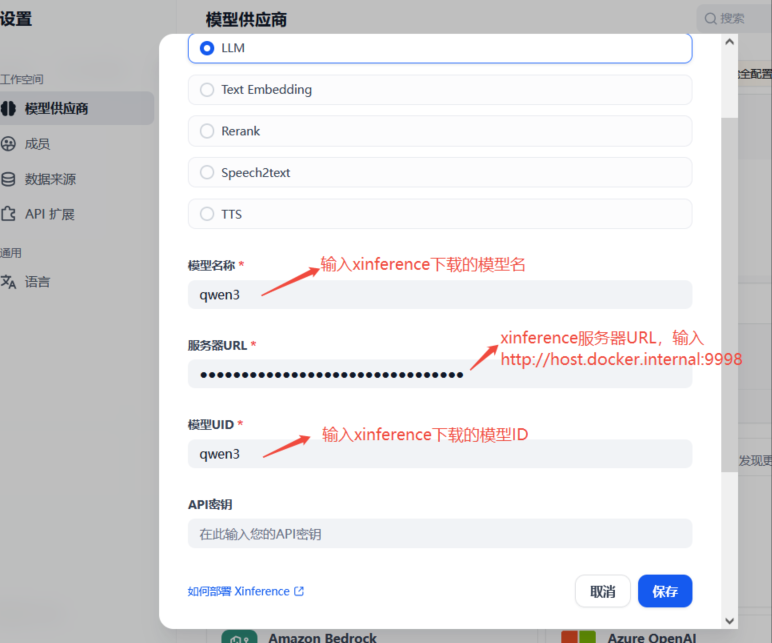
1) 配置LLM模型
服务器URL填入:http://host.docker.internal:9998
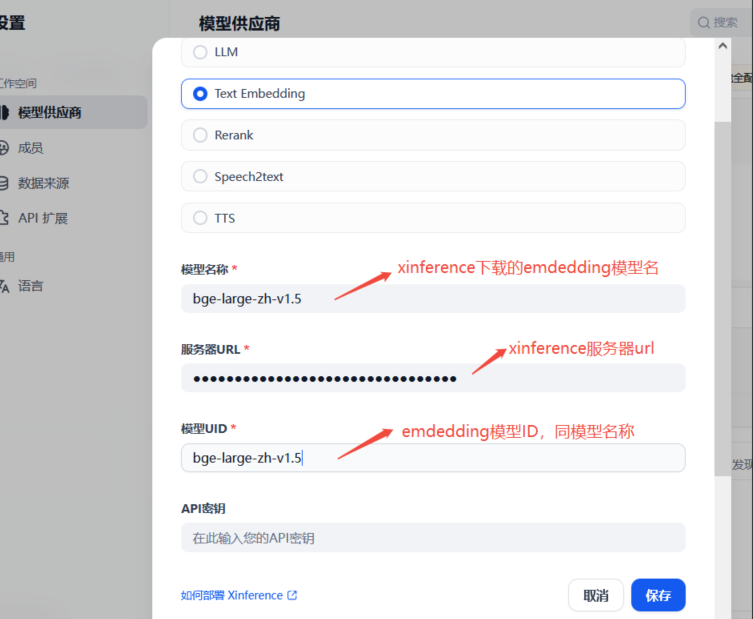
2) 配置Emdedding模型
3) 配置Rerank模型
3、模型使用
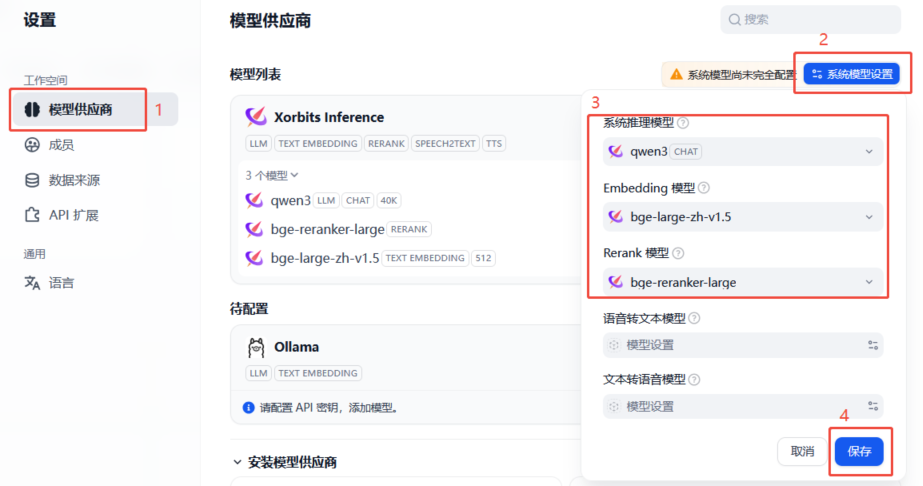
配置成功后,可以在界面看到模型,并可以【系统模型设置】选择要使用的模型。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)