【论文阅读11】-基于大型语言模型的轴承故障诊断框架
😊文章背景
题目:LLM-based framework for bearing fault diagnosis
期刊:Mechanical Systems and Signal Processing
检索情况:IF 9.9sciUpTop 工程技术TOPSCI升级版 工程技术1区SC1Q1EI检素
作者:Laifa Tao a,b,c,d, Haifei Liu b,c,d, Guoao Ning b,c,d, Wenyan Cao b,c,d, Bohao Huang b,c,d, Chen Lu
单位:北航
发表年份:2025
DOI:
网址:https://www.sciencedirect.com/science/article/pii/S1474034625001016
❓ 研究问题
尽管深度学习已广泛应用,但当前模型在工业落地中面临三大严峻挑战:
-
跨工况适应性差:在A工况(如高负载)下训练的模型,在B工况(如低负载)下性能急剧下降,适应性弱。
-
小样本学习困难:工业场景下故障数据稀少,难以支撑数据饥渴型模型的有效训练。
-
跨数据集泛化能力弱:为特定设备开发的模型,难以直接迁移到新设备上,重复开发成本高昂。
📌 研究目标
探索并构建一个基于LLM的故障诊断新范式,旨在显著提升模型在跨工况、小样本和跨数据集场景下的泛化能力。
🧠 所用方法
整体框架
输入:轴承振动信号
并行路径处理:
路径一:基于特征的方法
- Feature Extraction(特征提取):从振动信号中人工提取出24个有明确物理意义的特征,包括12个时域特征(如均值、峰值、峭度等)和12个频域特征(如重心频率等)。这些特征是专家经验的总结,能更直接地反映故障状态。
- 将物理信号“文本化”:将提取出的特征数值与它们的自然语言描述相结合,构建成LLM能够理解的“指令-输入-输出”格式,将故障诊断问题转化为一个LLM擅长的文本理解与分类任务。
路径二:基于数据的方法
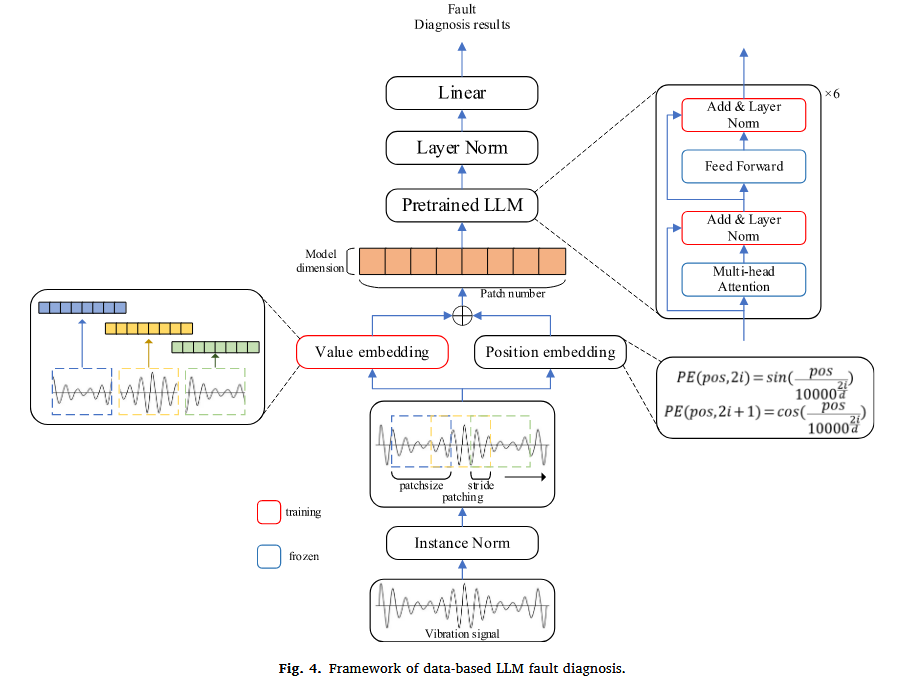
- Token Embedding(词元嵌入):将分块后的信号片段(数值序列)转换成计算机能够处理的数字向量(一串有意义的数字)。
- Position Embedding(位置嵌入):在转换过程中,加入每个信号块在原始序列中的位置信息,因为振动信号的顺序对诊断至关重要。
- 这条路线的目标是尽量保留原始数据的完整信息,直接让LLM去学习。
对LLM进行微调:使用 LoRA 和 QLoRA 这两种高效的微调技术。
输出:经过微调的LLM最终能够完成故障诊断任务,同时适用于基于特征和基于数据的两种方法。
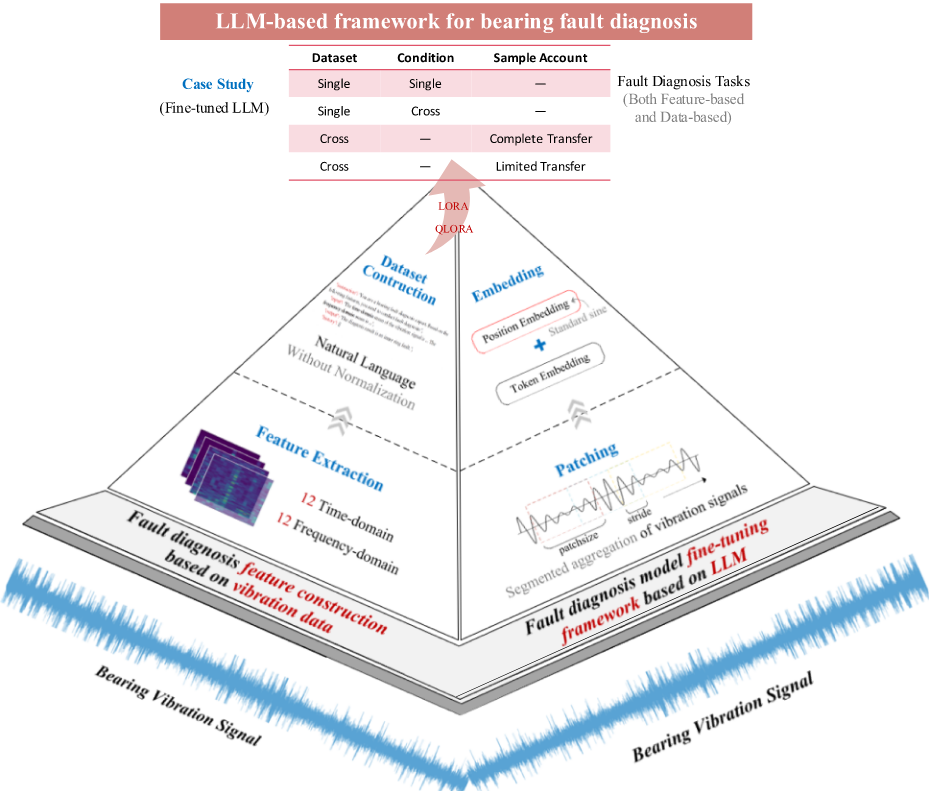
一、基于特征提取的LLM诊断框架——为LLM编写“诊断手册”
-
第一步:特征提取。我们从振动信号中系统性地提取了12个时域特征(如均值、峭度)和12个频域特征(如重心频率),共24个具有明确物理意义的指标。
-
第二步:特征文本化(关键创新)。这不是简单的数值输入,而是将特征构建成LLM能理解的“指令-回答”对。如下图所示,通过自然语言描述将数值“包装”起来,形成一段富含语义的文本输入,相当于为LLM准备了一份结构清晰的“故障诊断手册”。
-

-
第三步:高效微调。采用LoRA/QLoRA等参数高效微调技术,只训练一个极小的“外挂”参数矩阵,即可让通用LLM(如ChatGLM2)快速掌握诊断技能,极大节省计算资源。
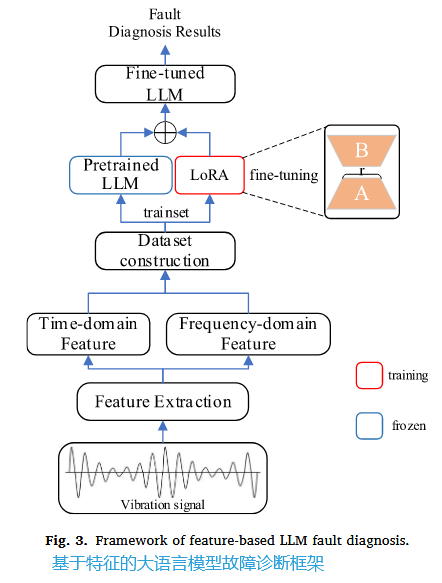
二、基于原始数据的LLM诊断框架——让LLM直接学习“振动语言”
-
第一步:信号分块 (Patching)。将长长的振动信号切割成短序列,减少冗余,形成数据“短语”。
-
第二步:Token化与位置嵌入。通过一维卷积和位置编码,将信号数据转换为LLM能够处理的“词向量”,同时保留其关键的顺序信息。
-
第三步:针对性微调策略。冻结LLM(如GPT-2)的核心注意力层和前馈网络以保留其通用知识,仅训练层归一化层和线性分类层。这种策略能高效引导LLM适配新任务
🧪 实验设计与结果
一、实验设计
为验证框架有效性,选择四个在轴承类型、故障模式、工况和采样频率上具有显著差异的公开数据集:
-
CWRU: 美国凯斯西储大学数据集,行业基准。
-
MFPT: 机械故障预防技术学会数据集,包含多种负载条件。
-
JNU: 江南大学数据集,包含多种转速。
-
PU: 德国帕德博恩大学数据集,以高精度著称
设计了严格实验,重点考察:
-
跨数据集泛化:在A、B、C数据集上训练,在D数据集上测试。
-
小样本学习:先多数据集预训练,再用目标数据集极少量(如10%)样本微调。
-
跨工况:在不同的工况上进行测试
实验分为三个层次,由易到难,系统地验证框架的性能。
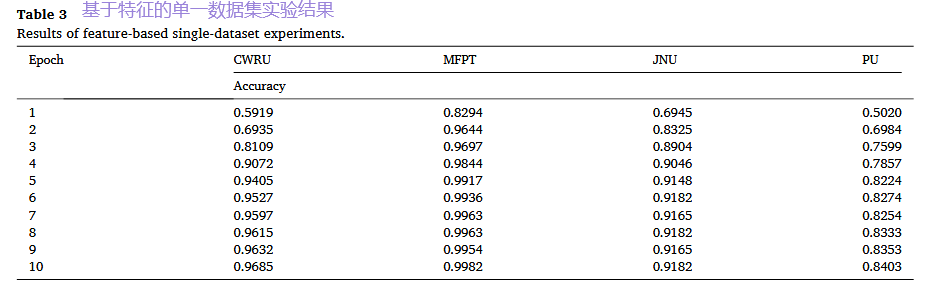
1. 单数据集实验:验证基础有效性
-
设计: 首先在每个数据集内部,按8:2的比例划分训练集和测试集,验证方法在标准设定下的基础诊断能力。
2. 单数据集跨工况实验:挑战工况变化
-
设计: 以CWRU数据集为例,它包含4种不同负载/转速的工况(0HP/1797RPM, 1HP/1772RPM等)。采用“留一法”,即使用三种工况的数据进行训练,在剩下的一种未见过的工况上进行测试,模拟实际应用中工况突变的情况。
3. 跨数据集实验:核心泛化能力验证(重点)
-
场景A:完整数据迁移
-
设计: 在三个数据集上联合训练模型,然后在第四个完全未见过的数据集上进行测试。例如,用CWRU、MFPT、JNU训练,在PU上测试。
-
-
场景B:小样本数据迁移(模拟工业现实)
-
设计: 为了模拟新设备故障数据极少的“冷启动”场景,我们在上述“三练一测”的基础上,增加一个步骤:使用目标数据集仅10%的少量数据对已预训练的模型进行快速微调,然后在其完整的测试集上进行评估。
-
二、实验结果
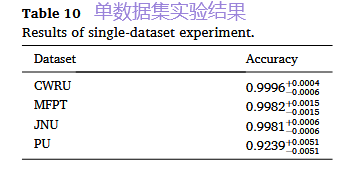
1. 单数据集实验:验证基础有效性
结果: 无论是基于特征还是基于数据的方法,在四个数据集上都取得了高精度(均在90%以上)。这证明,两种路径都能有效完成基本的故障分类任务,为后续更复杂的实验奠定了基础。
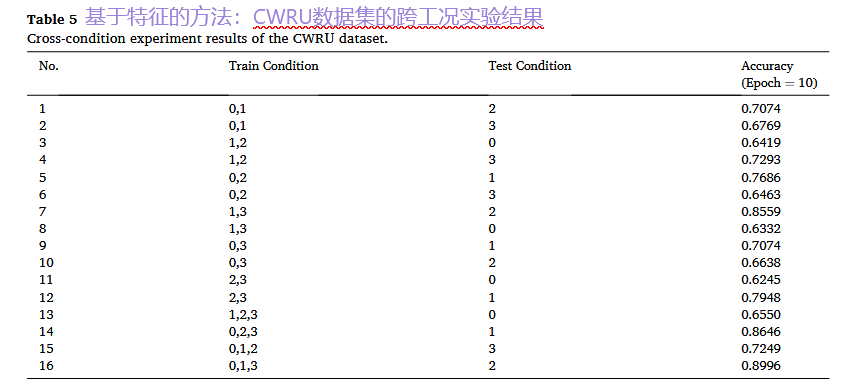
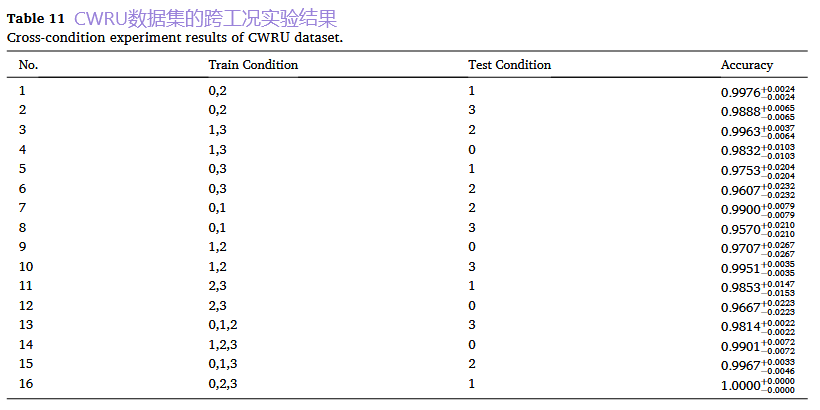
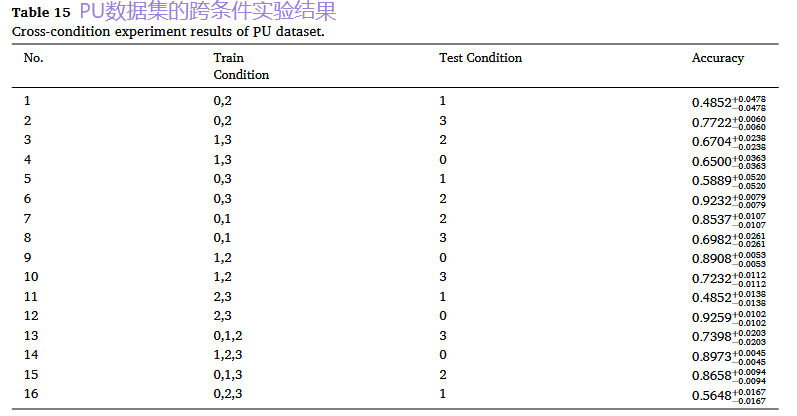
2. 单数据集跨工况实验:挑战工况变化
结果:用于训练的工况数据越多、越多样,模型对未知工况的泛化能力就越强。这表明LLM能够学习并推理不同工况与故障模式之间的关系。
基于数据的方法:
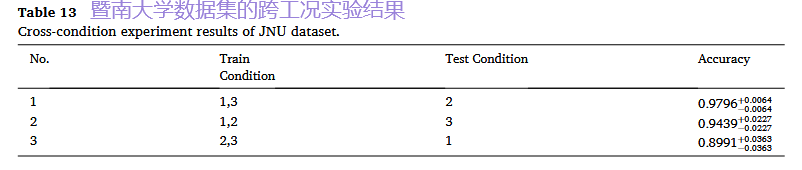
3. 跨数据集实验:核心泛化能力验证(重点)
- 场景A:完整数据迁移:
- 关键结果: 这种“三练一测”的方式带来了显著的性能提升。例如,基于特征的方法在PU数据集上的准确率,相比仅用PU数据训练,提升了约7.7%(10个训练周期下)。这强有力地证明了LLM能够进行有效的知识迁移,将在多个数据集上学到的通用故障模式应用到一个全新的设备上。
基于特征的方法:
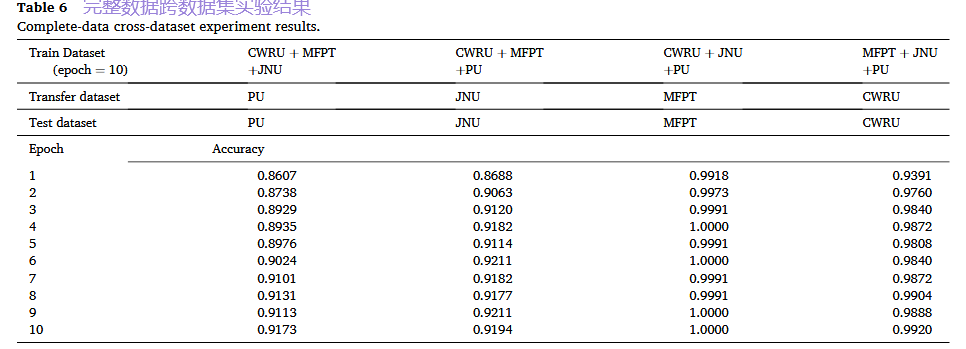
基于数据的方法:

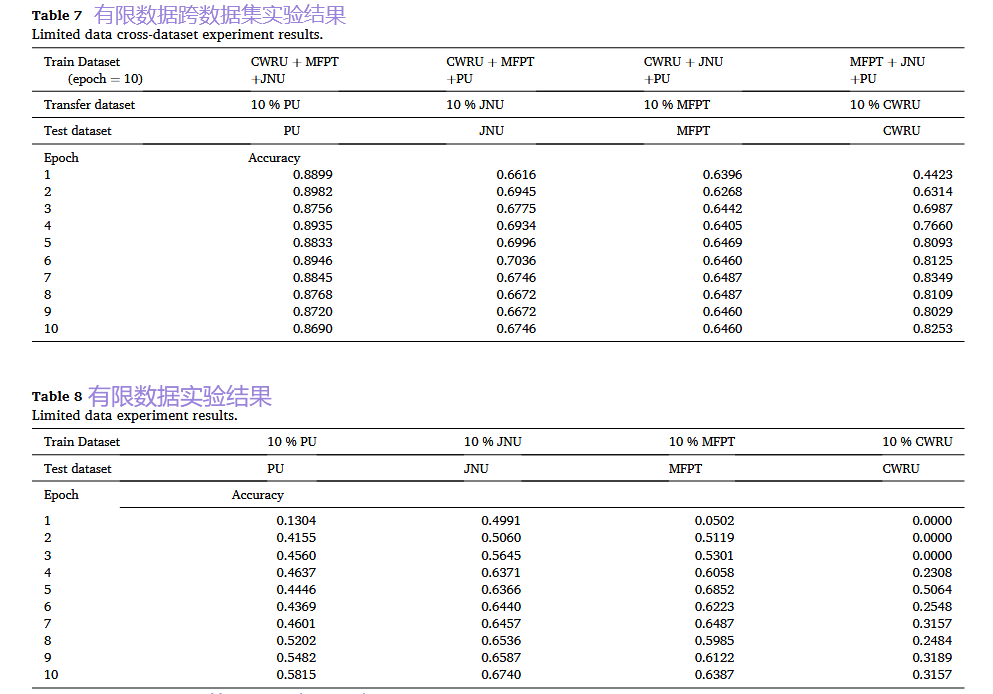
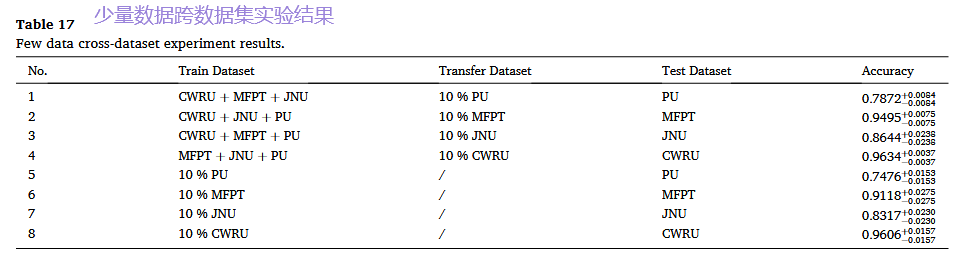
- 场景B:小样本数据迁移(模拟工业现实)
- 关键结果与对比: 我们将其与直接使用10%数据从头训练模型的“基线方法”进行对比。结果非常显著:经过多数据集预训练的模型,即使只使用10%的新数据微调,其性能也远远超过基线方法。下图清晰地展示了这一巨大优势:
-
精度大幅提升: 对于JNU、PU等数据集,准确率提升超过30%。
-
稳定性极高: 多数据集预训练极大地降低了模型在小样本场景下的性能波动(标准差远低于基线)。
-
核心价值体现: 这证明了我们的框架能够将“旧知识”快速适配到新设备,极大地降低了新设备诊断模型对大量标注数据的依赖,具有极高的工程应用价值。
-
- 关键结果与对比: 我们将其与直接使用10%数据从头训练模型的“基线方法”进行对比。结果非常显著:经过多数据集预训练的模型,即使只使用10%的新数据微调,其性能也远远超过基线方法。下图清晰地展示了这一巨大优势:
基于特征的方法:
基于数据的方法:
✅ 研究结论
本研究成功验证了:
-
可行性:将LLM用于轴承故障诊断完全可行且有效。
-
泛化能力:所提框架能同时应对跨工况、小样本和跨数据集三大挑战。
-
高效性:参数高效微调技术是实现这一目标的关键,在性能与成本间取得绝佳平衡。
📈 研究意义
本研究是一个基础性框架,为后续研究开辟了方向。
🔮 未来研究方向
本研究是一个起点,未来工作可从三方面展开:
-
面向真实工业场景:在更复杂、噪声更多的数据上验证与优化。
-
探索专用模型架构:设计更适合机械信号处理的Token化方法或模型结构。
-
扩展应用范围:将框架推广至齿轮、发动机等其他关键部件的诊断。
📕专业名词
一、 核心目标与挑战
-
泛化能力: 指模型在面对全新、未见过的数据时的适应能力和表现。本文目标是提升诊断模型在三种挑战性场景下的泛化能力。
-
跨工况适应性: 要求模型能够适应轴承在不同工作状态(如变化的速度、负载)下的诊断任务。
-
小样本学习: 在故障数据极其稀少的情况下训练出有效的诊断模型,模拟工业现实中故障少发的场景。
-
跨数据集泛化: 训练好的模型能够直接应用于不同来源、不同设备的轴承数据,而无需重新训练,实现“一次学习,多处应用”。
二、 关键技术方法
-
LLM: 大语言模型。一种强大的人工智能模型,本文创新性地利用其处理序列数据和存储知识的能力来进行故障诊断。
-
特征提取: 从复杂的原始振动信号中,提炼出能反映故障本质的、具有物理意义的关键指标(如均值、峰值、峭度等)。
-
文本化: 将提取出的特征数值与它们的文字描述相结合,转换成LLM能够理解的“语言”或“指令”格式。
-
微调: 对已经预训练好的通用LLM进行“专业培训”,用特定的故障诊断数据使其专注于新任务,而不必从头开始训练。
-
LoRA: 低秩自适应。一种高效的微调技术,通过只训练一个很小的“外挂”参数矩阵来调整模型,节省计算资源。
-
QLoRA: 量化低秩自适应。LoRA的升级版,通过降低数值精度来进一步减少内存消耗,使得在普通硬件上微调大模型成为可能。
三、 模型与架构
-
Transformer架构: 当今大多数LLM的底层技术基础,其核心是注意力机制,能让模型专注于输入信息中最重要的部分。
-
GPT-2: 本文在“基于数据的诊断”实验中使用的一个著名大语言模型。
-
ChatGLM2-6B: 本文在“基于特征的诊断”实验中使用的一个开源双语对话大模型。
四、 实验与评估
-
CWRU, MFPT, JNU, PU: 四个公开的、常用的标准轴承故障数据集的名称缩写,用于公平地验证和比较不同方法的性能。
-
t-SNE: 一种可视化技术,用于将高维数据投影到二维平面,直观展示模型是否能将不同故障状态清晰区分。
-
混淆矩阵: 一种用于评估分类模型性能的表格,能清晰显示模型在哪些类别上容易预测错误。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)