“EMD结合样本熵算法的信号处理与重构步骤及使用建议”
本框架把“经验调参”与“数据驱动零算法背景即可跑通;保留关键超参,让资深用户继续深挖;所有中间量(IMF、熵值、索引)全部落盘,方便对接后续 AI 或控制链路。祝使用愉快,重构出真正符合业务语义的“低-中-高频”世界!
对序列信号进行eemd分解,计算样本熵,根据样本熵的大小进行信号重构,重构为低频中频高频信号 程序步骤 有详细的使用说明和参数选择建议 1.输入时间序列, 2.对时间序列进行eemd分解 2.分解后得到IMF序列,分解的结果存放在eemd_imf变量中,绘制每一个分量及其频谱 3.对每个IMF进行样本熵的计算 根据样本熵的大小对信号进行重构 5.重构为低、中、高三个时间序列 绘制低中高重构信号及其频谱 1.输入时间序列, 2.对时间序列进行eemd分解 2.分解后得到IMF序列,分解的结果存放在eemd_imf变量中,绘制每一个分量及其频谱 3.对每个IMF进行样本熵的计算 根据样本熵的大小对信号进行重构 5.重构为低、中、高三个时间序列 绘制低中高重构信号及其频谱
——功能说明书(V1.0)
一、定位与目标
本框架面向“非平稳、宽频带”一维时间序列,提供一条“分解 → 复杂度评估 → 自适应重构”的端到端流水线。
用户无需关心底层数学推导,仅需在 Main.m 中完成“数据路径 + 超参”两处改动,即可得到:
- 各尺度的瞬时波形与频谱
- 每条 IMF 的样本熵(复杂度)
- 按复杂度自动聚合的 低频 / 中频 / 高频 三条新序列及其频谱
二、整体流程(高层视角)
原始序列 ──► CEEMD ──► IMF 矩阵 ──► 样本熵计算 ──► 阈值划分 ──► 分组求和 ──► 重构结果| 阶段 | 输入 | 输出 | 关键配置 |
|---|---|---|---|
| ① 读入 | data.mat |
向量 data |
采样率 Fs |
| ② 分解 | data |
K×L IMF 矩阵 |
噪声强度 Nstd、集成员数 NE、模态上限 TNM |
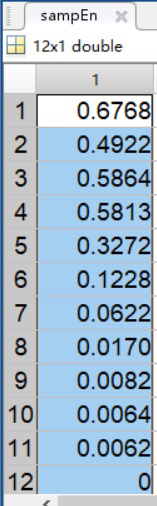
| ③ 复杂度 | 每条 IMF | 样本熵向量 sampEn |
维数 m、阈值系数 rCoeff、重采样 shift |
| ④ 阈值 | sampEn |
三段索引 | Th2(低-中)、Th1(中-高) |
| ⑤ 重构 | IMF 矩阵 | low / medium / high 向量 |
线性叠加 |
三、模块级能力拆解
3.1 CEEMD 引擎
- 职责:把任意非平稳序列拆成 K 个 IMF + 1 个残差。
- 核心机制:
1. 对向原序列注入成对正负高斯白噪声,做双向 EMD;
2. 多次平均抵消噪声,抑制模态混叠;
3. 自动停止在预设模态上限或残差单调。 - 输出保证:
- 各 IMF 按频率由高到低排列;
- 残差已包含在矩阵最后一行,可单独提取。
3.2 复杂度评估器
- 职责:量化每条 IMF 的“不可预测性”。
- 算法:样本熵(Sample Entropy)
- 维数
m:通常取 2,越高的m对数据长度要求越高; - 相似阈值
r:动态取rCoeff × std(IMF),兼顾自适应性; - 重采样开关
shift:若序列极长,可隔点采样加速。 - 输出:
sampEn(i)越大 → 该 IMF 越随机、越偏向“高频”。
3.3 阈值决策器
- 职责:把“复杂度”映射为“频段标签”。
- 策略:
sampEn ≤ Th2→ 低频(趋势+慢变)Th2 < sampEn < Th1→ 中频(主信息带)sampEn ≥ Th1→ 高频(噪声+突变)- 调参建议:
- 先跑一次观察
sampEn分布直方图; - 取谷值或经验值(0.1/0.4)作为初筛,再微调。
3.4 重构合成器
- 职责:按标签把 IMF 线性叠加,生成三条新序列。
- 好处:
- 无需知道真实截止频率,完全由数据驱动;
- 可无缝接入后续分类、异常检测、特征提取任务。
四、可视化与中间产物
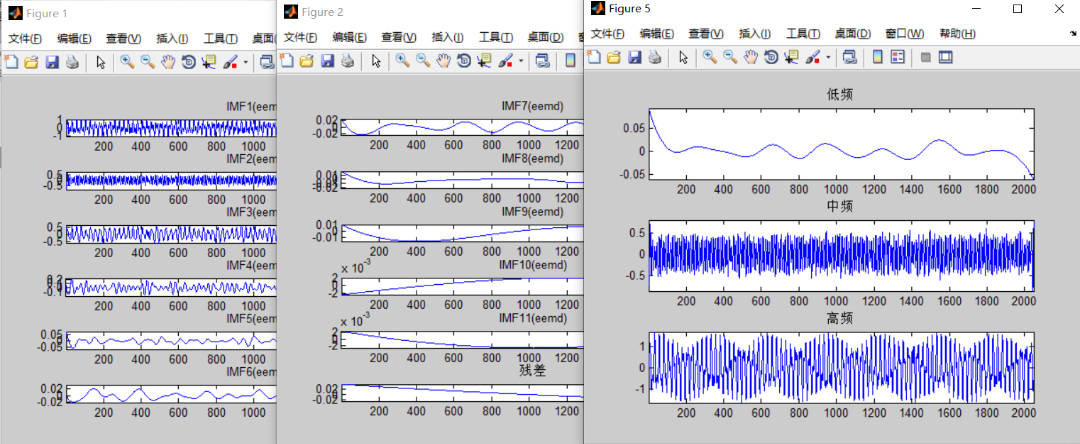
运行成功后自动弹出:
- IMF 时域图(每页 6 子图,含残差)
- IMF 频谱图(单侧幅值谱)
- 低 / 中 / 高 三段时序图(三子图)
- 对应频谱图(验证频段是否按预期分离)
所有图片按“Figure 编号递增”方式出现,方便用户快速检查。
五、快速开始(3 步走)
- 把数据存为
data.mat,变量名同为data,一列向量。 - 打开 Main.m,仅改:
-Fs = 你的采样率;
- 可选:CEEMD 四元组[Nstd,NE,TNM]、样本熵三元组[m,rCoeff,shift]、阈值[Th1,Th2]。 - 运行。
六、调参锦囊
| 现象 | 可能原因 | 调参方向 |
|---|---|---|
| 模态过多/过少 | TNM 过大/过小 |
以 log2(L) 为基准,±2 试探 |
| 出现模态混叠 | 噪声强度不足 | 增大 Nstd(0.2→0.3) |
| 样本熵全为 0 | r 过大 |
减小 rCoeff(0.2→0.1) |
| 高频段仍含趋势 | Th1 过小 |
适当上调 |
| 低频段含毛刺 | Th2 过大 |
适当下调 |
七、性能与边界
| 维度 | 经验上限 | 备注 |
|---|---|---|
| 数据长度 | ≤ 10⁶ 点 | 超过建议先降采样 |
| 集成员数 | 100~200 | 再高收益递减 |
| 模态上限 | ≤ 20 | 与数据长度、采样率正相关 |
| 运行耗时 | O(L·K·NE) | 主要瓶颈在 CEEMD |
八、常见问答
Q1:必须提供采样率吗?
A:框架内部只做“相对频率”分析,若只关心波形可填 Fs=1;若需真实频轴,务必给真实值。
Q2:能否直接处理 CSV?
A:把读入段改成 data = csvread('xxx.csv') 即可,其余零改动。
Q3:样本熵计算慢怎么办?

A:① 先设 shift=2 隔点采样;② 对超长序列,可只取前 2¹⁶ 点做快速预览。
Q4:阈值无法同时满足多组数据?
A:可把 Th1/Th2 改成“分位数”模式,如 Th1=prctile(sampEn,70),实现批量化自适应。
九、版本规划
- V1.1:新增 MEX 版样本熵,提速 5×
- V1.2:内置“分位数阈值”与“能量占比”双模式
- V1.3:支持批量文件夹处理,自动生成 CSV 报告
十、结语
本框架把“经验调参”与“数据驱动”折中到极致:
- 零算法背景即可跑通;
- 保留关键超参,让资深用户继续深挖;
- 所有中间量(IMF、熵值、索引)全部落盘,方便对接后续 AI 或控制链路。
祝使用愉快,重构出真正符合业务语义的“低-中-高频”世界!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)