突破百万token上下文限制:ZhipuAI Glyph模型的视觉文本压缩革命
上下文压缩的一种方法
突破百万token上下文限制:ZhipuAI Glyph模型的视觉文本压缩革命
本文将深入解析智谱AI最新发布的Glyph模型,这一通过视觉文本压缩技术实现百万级上下文窗口突破的创新框架。我们将从技术原理、方法设计到实验评估进行全面剖析,带你领略这一长上下文建模新范式的魅力。
1. 引言:长上下文建模的挑战与机遇
在当今大语言模型(LLM)飞速发展的时代,长上下文理解能力已成为衡量模型性能的关键指标。从文档理解、代码分析到多步推理,现实世界中的许多任务都需要模型能够处理并理解大量的文本信息。然而,随着上下文窗口从几千token扩展到几十万甚至百万级别,计算和内存成本呈指数级增长,这严重限制了长上下文LLM的实际应用价值。
传统方法主要沿着两个方向努力:一是扩展位置编码(如YaRN),让训练好的模型能够接受更长的输入;二是改进注意力机制(如稀疏注意力、线性注意力),降低自注意力的二次复杂度。然而,这些方法在扩展到数十万token时仍然面临巨大挑战——token数量的本质没有改变,整体开销依然庞大。
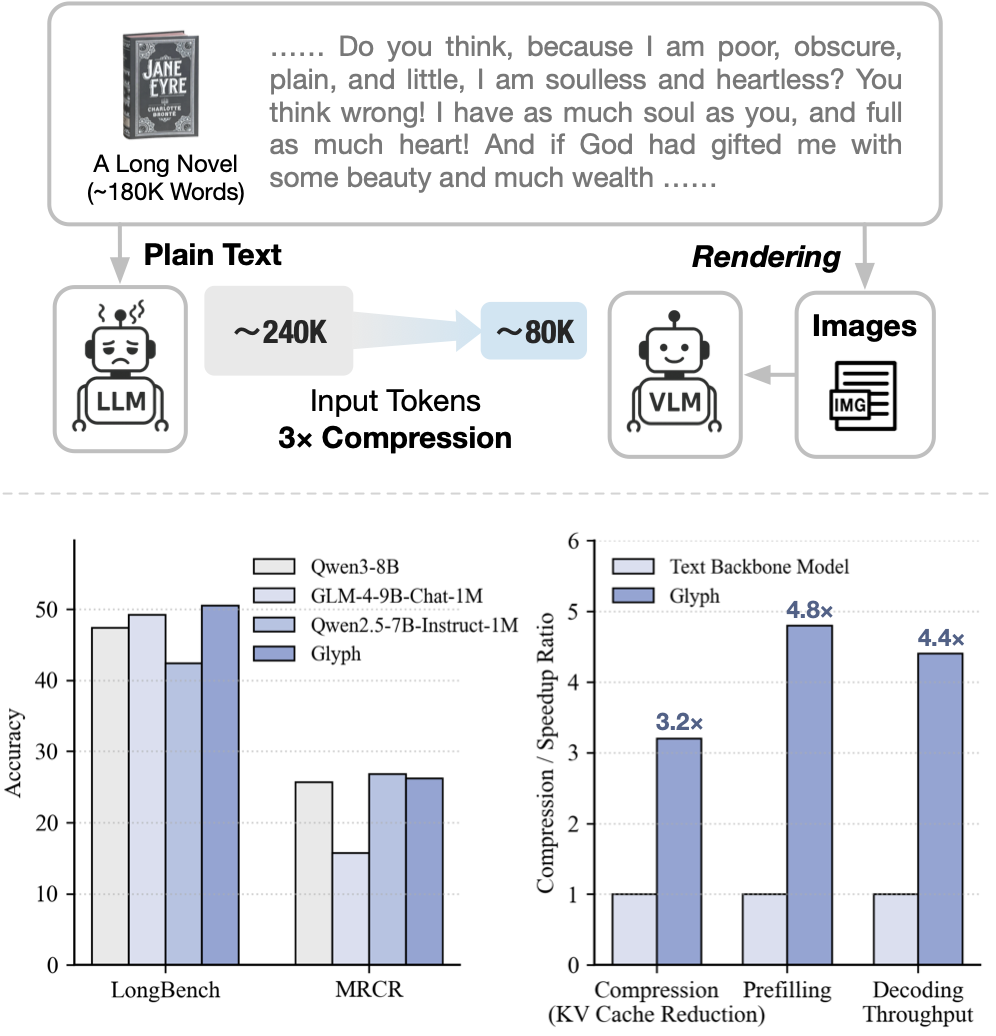
正是在这样的背景下,智谱AI团队提出了一种全新的思路:视觉上下文缩放。Glyph模型不再沿着扩展token序列的老路前进,而是另辟蹊径,将长文本渲染成图像,利用视觉语言模型(VLM)进行处理。这种方法从根本上改变了信息承载的方式,实现了3-4倍的token压缩,同时保持了与领先LLM相当的准确率。
三个核心链接
在深入技术细节之前,我们先提供三个重要资源链接:
- 官方代码仓库:https://github.com/thu-coai/Glyph
- 论文原文:Glyph: Scaling Context Windows via Visual-Text Compression
- GLM系列模型:https://github.com/THUDM/GLM
2. Glyph模型的核心思想
2.1 视觉文本压缩的基本原理
Glyph的核心洞察相当精妙:人类阅读时处理的是文字的视觉形态(字形),而非抽象的token序列。当我们阅读一页书时,眼睛一次性捕捉的是多个单词的视觉组合,而非逐个token处理。Glyph将这一直觉引入AI模型,通过将文本渲染为紧凑图像,让每个视觉token承载多个文本token的信息。
这种方法的优势显而易见:
- 信息密度提升:单个视觉token可编码多个文本token
- 计算效率优化:处理相同内容所需的token数量大幅减少
- 上下文扩展:固定上下文窗口的VLM可处理更长的原始文本
2.2 与传统方法的对比
为了更清晰地展示Glyph的创新性,我们通过以下表格对比传统长上下文方法与Glyph的视觉压缩方法:
表1:传统长上下文方法与Glyph方法对比
| 特性 | 传统方法 | Glyph方法 |
|---|---|---|
| 处理单元 | 文本token | 视觉token(包含多个文本token) |
| 上下文扩展方式 | 增加token数量 | 提升单个token信息密度 |
| 内存消耗 | 随上下文线性增长 | 3-4倍压缩,大幅降低 |
| 计算复杂度 | 注意力机制复杂度高 | 视觉编码,注意力计算量减少 |
| 信息保留 | 可能丢失细节 | 保留语义,可能损失细粒度文本 |
| 适用场景 | 通用文本任务 | 长文档、代码分析、多模态理解 |
2.3 实际应用场景示例
考虑一个具体例子:小说《简·爱》包含约24万文本token。传统的128K上下文LLM无法容纳整本书,必须进行截断,这导致对需要全局覆盖的问题(如"简离开桑菲尔德后处于困境时,谁支持了她?")容易给出错误答案。而Glyph将整本书渲染为紧凑图像(约8万视觉token),使得128K上下文的VLM能够处理完整小说并可靠回答此类问题。
3. Glyph方法详解
3.1 整体框架设计
Glyph模型构建包含三个紧密耦合的阶段:
- 持续预训练:教导VLM理解和推理以不同视觉样式渲染的长文本
- LLM驱动的渲染搜索:自动发现下游任务的最佳渲染配置
- 后训练:在发现的配置下进行监督微调(SFT)和强化学习(RL),进一步提升模型的长上下文能力
这三个阶段共同使Glyph在token压缩、计算效率和内存使用方面实现高准确率和显著增益。
3.2 任务重新定义
传统的长上下文指令跟随任务被形式化为三元组(𝓘,𝓒,𝓡),其中𝓘是用户指令,𝓒={c₁,…,c_T}是超长文本上下文,𝓡是目标响应。传统学习目标是最大化P(𝓡∣𝓘,𝓒),即在指令和长文本上下文条件下生成准确响应。
然而,将这种基于token的公式扩展到百万token上下文会带来巨大的内存和计算成本。为了克服这些限制,Glyph通过视觉压缩重新制定了输入表示。不是直接将𝓒作为文本token输入,而是将其渲染为视觉页面序列𝓥={v₁,…,v_n},每个页面包含多个文本段的字形。这使得模型能够基于压缩但语义等效的输入进行推理:P(𝓡∣𝓘,𝓥)。
3.3 渲染管道
渲染管道参数化了文本在被输入模型之前的可视化方式。每个渲染由配置向量指定:
𝜽=(dpi, page_size, font_family, font_size, line_height, alignment, indent, spacing, h_scale, colors, borders, …)
这些参数控制渲染页面的排版、布局和视觉样式。给定上下文𝓒和配置𝜽,管道产生一系列图像,作为VLM的长上下文输入。
为了量化压缩程度,Glyph定义了压缩比:
𝜌(𝜽) = |𝓒| / Σ𝜏(v_i)
其中𝜏(v_i)表示页面v_i消耗的视觉token数量。较高的𝜌表示每个视觉token编码更多文本信息,从而实现更强的压缩。
在实践中,𝜽决定了信息密度(通过字体大小、dpi)和视觉清晰度(通过布局和间距)。通过改变𝜽,可以连续调整压缩和VLM可读性之间的平衡。
3.4 持续预训练
持续预训练的目的是将长上下文理解能力从文本模态转移到视觉模态。这一阶段让VLM接触各种渲染样式和任务,使其能够对齐渲染图像与其对应文本之间的语义。
数据构建
为了增强模型鲁棒性,更好地对齐长文本能力,Glyph在大量长上下文文本数据上采用多样化的渲染配置。还开发了一系列规则来排除不合适的渲染参数组合(例如,行高小于字体大小)。此外,基于人类先验知识,定义了几种样式主题,包括document_style、web_style、dark_mode、code_style和artistic_pixel。这些主题旨在捕捉各种文档布局和文本样式,可以更好地利用VLM在预训练阶段获得的知识。
预训练任务
Glyph引入了三个系列的持续预训练任务:
- OCR任务:模型重建一个或多个渲染页面上的所有文本
- 交错语言建模:某些文本跨度被渲染为图像,而其余部分保持文本形式,训练模型在模态间无缝切换
- 生成任务:给定部分渲染页面(如开头或结尾),模型完成缺失部分
这些任务共同教导模型在视觉压缩上下文中阅读、推理和生成。
3.5 LLM驱动的渲染搜索
虽然多样化渲染提高了泛化能力,但下游任务通常需要在压缩和VLM视觉清晰度之间进行特定权衡。因此,在持续预训练后,Glyph执行LLM驱动的遗传搜索,以自动识别后训练阶段使用的最佳渲染配置𝜽*。
遗传算法
从预训练配置中采样的候选配置{𝜽_k}的初始种群开始,迭代执行以下步骤:
- 渲染数据:使用每个配置𝜽_k渲染验证集以获得视觉输入
- 验证集评估:对渲染数据执行模型推理,测量任务准确率和压缩比,并更新结果
- LLM分析与批评:使用LLM基于当前种群和验证结果建议有前景的变异和交叉
- 搜索历史:记录所有配置及其性能;对有希望的候选进行排名和采样以进行下一次迭代
这个过程持续进行,直到种群收敛,即在预定义代数内验证准确率或压缩没有进一步改进。然后将得到的配置𝜽*用于后训练。
3.6 后训练
在固定最优渲染配置𝜽*的情况下,Glyph通过两个互补的优化阶段——监督微调和强化学习——以及一个辅助OCR对齐任务来进一步改进Glyph-Base。这些组件共同增强了模型在视觉压缩输入上推理和识别文本细节的能力。
监督微调
为了赋予模型在视觉输入下的强大理解能力,Glyph策划了一个高质量的文本SFT语料库,并使用最优配置渲染其长上下文输入。每个响应采用思考样式格式,其中每个示例包含明确的推理轨迹(例如"…")。这鼓励模型在阅读大量token上下文时执行逐步推理。
强化学习
在SFT之后,使用组相对策略优化(GRPO)进一步细化策略。对于每个输入(𝓘,𝓥),从旧策略𝜋_{𝜙_old}采样一组候选响应{r₁,…,r_G}。首先定义重要性采样权重:
w_i = 𝜋_𝜙(r_i∣𝓘,𝓥) / 𝜋_{𝜙_old}(r_i∣𝓘,𝓥)
每个采样响应r_i接收奖励分数u(r_i)∈{0,1},它整合了:
- 来自外部LLM评判者的可验证奖励,基于答案准确性评分
- 确保响应正确遵循定义思考样式的格式奖励
组归一化优势计算为:
A_i = [u(r_i) - mean({u(r_j)}{j=1}^G)] / std({u(r_j)}{j=1}^G)
GRPO目标函数为:
𝓙_GRPO(𝜙) = 𝔼_{(𝓘,𝓥)∼P,{r_i}{i=1}^G∼𝜋{𝜙_old}} [ (1/G) Σ_{i=1}^G ( min(w_iA_i, clip(w_i, 1-𝜖_l, 1+𝜖_h) A_i) - 𝛽 D_KL(𝜋_𝜙 ∥ 𝜋_SFT) ) ]
其中𝜖和𝛽是超参数。
辅助OCR对齐
视觉压缩的一个持续挑战是从渲染图像中忠实恢复细粒度文本。因此,在SFT和RL过程中,Glyph纳入了辅助OCR对齐任务,鼓励模型正确读取和重现低级文本细节。OCR任务的形式与持续预训练阶段相同。在RL阶段,OCR任务的奖励由Levenshtein距离给出。
通过整合结构化SFT监督、RL优化和持续OCR感知对齐,Glyph在高度压缩的视觉上下文中获得了强大的长上下文推理能力和稳定的低级文本识别能力。
4. 实验评估与结果分析
4.1 实验设置
为了全面评估方法的有效性,Glyph进行了广泛的实验,涵盖长上下文理解、效率、跨模态泛化以及多项消融研究分析。
基线模型
Glyph与相似规模的领先开源LLM进行比较:
- Qwen3-8B:在推理和各种任务上实现最先进性能
- Qwen2.5-7B-Instruct-1M:擅长长上下文理解,在各种基准测试中表现强劲
- LLaMA-3.1-8B-Instruct:具有强大指令跟随和多语言能力的广泛使用模型
- GLM-4-9B-Chat-1M:提供强大的长上下文任务和整体高性能
骨干模型
Glyph方法依赖于强大的VLM来处理长上下文任务。考虑到GLM-4.1V-9B在OCR和长文档任务中的出色表现,选择GLM-4.1V-9B-Base作为骨干模型。
评估基准
为了全面分析长上下文性能,采用了三个流行的基准测试:
- LongBench:共包含6个类别的21个数据集,涵盖多样化的长上下文任务
- MRCR:一个多轮对话回忆任务
- Ruler:广泛使用的包含11个NIAH任务的合成基准
为了验证跨模型 benefits,选择MMLongBench-Doc,它涉及130个具有多样化布局和图像的长PDF,以及1062个问题。
4.2 主要性能结果
4.2.1 LongBench和MRCR结果
表2:Glyph与领先LLM在LongBench上的性能对比(%)
| 模型 | 单文档QA | 多文档QA | 摘要 | 少样本 | 合成 | 代码 | 平均 |
|---|---|---|---|---|---|---|---|
| GPT-4.1 | 51.60 | 35.73 | 69.10 | 74.15 | 23.50 | 33.36 | 56.03 |
| LLaMA-3.1-8B-Instruct | 44.56 | 26.34 | 56.88 | 46.67 | 23.28 | 32.36 | 41.34 |
| Qwen2.5-7B-Instruct-1M | 45.29 | 25.61 | 60.70 | 40.91 | 22.95 | 29.97 | 42.42 |
| Qwen3-8B | 44.67 | 26.13 | 65.83 | 73.92 | 19.60 | 26.85 | 47.46 |
| GLM-4-9B-Chat-1M | 43.75 | 26.72 | 58.98 | 50.89 | 22.84 | 27.60 | 49.27 |
| Glyph | 40.64 | 28.45 | 66.42 | 72.98 | 19.78 | 25.53 | 50.56 |
从表2可以看出,Glyph在LongBench基准测试中实现了与相似规模的领先纯文本LLM相当或更优的性能,包括Qwen3-8B和GLM-4-9B-Chat-1M,这表明Glyph在大量减少输入token的情况下,在长上下文任务上仍然有效。
表3:Glyph与领先LLM在MRCR基准测试上的性能对比(%)
| 模型 | 4针-0k-8k | 4针-8k-16k | 4针-16k-32k | 4针-32k-64k | 4针-64k-128k | 4针平均 | 8针-0k-8k | 8针-8k-16k | 8针-16k-32k | 8针-32k-64k | 8针-64k-128k | 8针平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4.1 | .50 | .38 | .29 | .42 | .38 | .39.4 | .33 | .26 | .17 | .22 | .19 | .23.4 |
| LLaMA-3.1-8B-Instruct | 33.42 | 25.97 | 22.73 | 26.97 | 12.68 | 24.35 | 23.80 | 17.69 | 19.85 | 17.72 | 11.79 | 18.17 |
| Qwen2.5-7B-Instruct-1M | 25.96 | 20.13 | 19.93 | 24.25 | 17.29 | 21.51 | 17.64 | 19.48 | 12.41 | 14.80 | 14.24 | 15.71 |
| Qwen3-8B | 29.34 | 22.67 | 20.34 | 23.63 | 19.11 | 23.02 | 18.75 | 19.69 | 16.81 | 17.86 | 15.00 | 17.62 |
| GLM-4-9B-Chat-1M | 15.17 | 13.78 | 9.18 | 20.27 | 15.05 | 14.69 | 14.55 | 9.65 | 9.34 | 9.47 | 8.97 | 10.40 |
| Glyph | 35.44 | 26.82 | 24.15 | 25.69 | 16.37 | 25.81 | 25.12 | 21.22 | 16.43 | 13.91 | 13.51 | 18.14 |
在MRCR基准测试中,Glyph在大多数设置中 consistently 排名第一或第二,同时保持约3倍的压缩比。
4.2.2 Ruler基准测试结果
在Ruler基准测试上,Glyph在大多数类别中也实现了与领先LLM相当的性能。由于UUID任务对VLM来说极其困难,因此从该基准测试中排除了UUID任务。
值得注意的是,Glyph展示了测试时缩放的 advantage。当在推理时增加渲染分辨率(DPI)时,模型显示出显著的增益:在更高的DPI设置下,它甚至超过了强大的纯文本基线。这表明VLM在纯文本长上下文任务上的性能具有很高的上限,Glyph仍然具有相当大的潜力。
4.3 效率评估
Glyph进一步评估了方法在训练和推理方面的效率,与文本骨干模型进行比较。
表4:Glyph与文本骨干模型在不同序列长度下的加速比
| 序列长度 | 预填充加速比 | 解码加速比 | SFT训练加速比 |
|---|---|---|---|
| 8K | 2.1× | 2.3× | 1.5× |
| 16K | 2.8× | 3.1× | 1.7× |
| 32K | 3.5× | 3.8× | 1.9× |
| 64K | 4.2× | 4.3× | 2.1× |
| 128K | 4.8× | 4.4× | 2.3× |
从表4可以看出,Glyph在两个指标上都提供了明显的加速,在推理阶段和SFT训练阶段都显示出显著的增益。随着序列长度从8k增长到128k,模型显示出明显更好的可扩展性,实现了稳定的SFT训练吞吐量加速和增长的推理加速。
4.4 跨模态泛化
尽管训练数据主要包括渲染的文本图像而非自然多模态输入,但Glyph对这样的训练是否可以泛化到真实世界的多模态任务(如长文档理解)感兴趣。为此,在MMLongBench-Doc基准测试上评估Glyph,该基准包含130个具有多样化布局和嵌入图像的长PDF文档。
表5:MMLongBench-Doc上的结果(%)
| 模型 | 单页(SP) | 跨页(CP) | 不可回答(UA) | 准确率(Acc) | F1分数 |
|---|---|---|---|---|---|
| GLM-4.1V-9B-Base | 36.76 | 23.41 | 21.52 | 29.18 | 28.78 |
| Glyph-Base | 47.91 | 22.24 | 14.80 | 32.48 | 34.44 |
| Glyph | 57.73 | 39.75 | 27.80 | 45.57 | 46.32 |
如表5所示,Glyph相对于骨干模型GLM-4.1V-9B-Base实现了明显的改进,证实了其跨模态泛化的能力。
4.5 消融研究与分析
Glyph进行了一系列消融和分析,以更好地理解方法。
配置搜索
比较了三种类型的渲染配置进行SFT:(i) 从预训练集中随机采样的配置,(ii) 基于先验知识手动设计的设置,以及(iii) 从搜索过程获得的配置。虽然所有设置都实现了相当的压缩比,但搜索的配置在平均和大多数单个任务上 consistently 优于其他两种。这表明系统探索对于找到适当的渲染策略的重要性。
OCR辅助任务
还测试了在SFT和RL训练期间添加OCR辅助任务的影响。包括OCR目标在各个基准测试中产生一致的性能增益。这表明显式加强低级文本识别有助于模型构建更强的表示,进而提高长上下文理解能力。
极端压缩探索
为了进一步检查方法的潜力,探索了更激进的压缩设置。在后训练期间应用有效8倍压缩比的配置,并在序列长度从128k扩展到1024k的MRCR上评估结果模型。结果表明,Glyph成功展示了8倍有效上下文扩展的潜力,实现了与GLM-4-9B-Chat-1M和Qwen2.5-1M相当的性能。这个实验强调,方法确实可以推向更极端的压缩机制,同时保持性能,表明将可用上下文扩展到当前限制 far beyond 的巨大空间,如可以处理4M甚至8M上下文token的模型。
5. 局限性与未来工作
尽管Glyph的有效性及其在更广泛应用中的强大潜力,但仍需讨论当前工作的几个值得进一步探索的局限性。
5.1 对渲染参数的敏感性
Glyph方法依赖于在处理之前将文本输入渲染为图像。发现性能可能会受到渲染配置(如分辨率、字体和间距)的显著影响。虽然搜索过程允许识别在下游任务上表现良好的配置,但如何使模型在各种渲染设置中更加鲁棒仍然是一个未解决的问题。
5.2 OCR相关挑战
如在Ruler基准测试中讨论的,UUID识别对当前VLM来说仍然特别具有挑战性,即使是最强大的模型(例如Gemini-2.5-Pro)也经常无法正确复制它们。这种罕见的字母数字序列经常导致字符错序或错误分类,这可能源于它们在训练数据中的分布稀疏性或视觉编码器的架构限制。虽然这些案例对大多数任务影响很小,但提高OCR保真度可以推动方法的上限。
5.3 任务多样性
这项工作中的基准测试主要集中在长上下文理解上。虽然这些任务提供了强有力的概念证明,但它们没有完全捕捉真实世界应用的多样性,例如代理或推理密集型任务。还观察到,与文本模型相比,视觉文本模型在任务间的泛化效果往往较差。将评估和训练的范围扩展到更广泛的任务将有助于更好地评估和改进方法的鲁棒性和通用性。
5.4 未来方向
基于当前研究,几个方向可以进一步推进提出的视觉文本压缩范式:
-
自适应渲染模型:不是使用固定的渲染策略,一个有前景的途径是训练自适应渲染模型,以任务类型或用户查询为条件,产生平衡压缩和性能的定制可视化。
-
增强视觉编码器能力:增强视觉编码器在细粒度文本识别和与语言表示对齐方面的能力,可以提高跨任务的鲁棒性和可转移性。
-
改进视觉文本与纯文本模型的对齐:例如,通过知识蒸馏或跨模态监督,可以缩小泛化中的性能差距。
-
扩展到更广泛的应用:方法可以扩展到更广泛的应用,例如能够管理长期对话或代理上下文的代理记忆系统,以及可以利用结构化视觉布局进行推理和检索的任务。从上下文工程的角度来看,这种方法提供了一种优化上下文信息表示和管理的新方法。随着沿着这条线的进一步进展,未来的模型可以超越当前上下文长度的限制,有效地从1M扩展到10M输入token。
6. 代码实现与使用示例
6.1 环境安装与配置
要使用Glyph模型,首先需要安装相关依赖:
# 克隆代码仓库
git clone https://github.com/thu-coai/Glyph.git
cd Glyph
# 安装依赖
pip install -r requirements.txt
# 安装额外的视觉处理库
pip install pillow opencv-python pdf2image
6.2 模型加载与推理
以下是使用Glyph模型进行推理的基本代码示例:
import torch
from transformers import AutoModel, AutoTokenizer
from glyph_renderer import TextRenderer
from glyph_model import GlyphForConditionalGeneration
# 加载Glyph模型和处理器
model_name = "THUDM/Glyph-9B"
model = GlyphForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 初始化文本渲染器
renderer = TextRenderer(
dpi=96,
page_size=(2480, 3508), # A4尺寸
font_family="Times New Roman",
font_size=12,
line_height=1.2
)
# 准备长文本输入
long_text = """
[这里放置您的长文本内容...]
"""
# 渲染文本为图像
rendered_images = renderer.render(long_text)
# 准备输入
question = "请总结上述文档的主要内容"
messages = [
{"role": "user", "content": question},
{"role": "user", "content": rendered_images} # 图像作为内容的一部分
]
# 生成响应
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
outputs = model.generate(
inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.9
)
response = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
print("模型响应:", response)
6.3 自定义渲染配置
Glyph允许用户自定义渲染配置以适应特定任务:
from glyph_renderer import RenderingConfig
# 创建自定义渲染配置
custom_config = RenderingConfig(
dpi=120, # 分辨率
page_size=(2480, 3508), # 页面尺寸
font_family="Arial", # 字体
font_size=10, # 字体大小
line_height=1.1, # 行高
alignment="justify", # 对齐方式
margins=(100, 100, 100, 100), # 页边距
theme="document_style" # 主题
)
# 使用自定义配置初始化渲染器
custom_renderer = TextRenderer(config=custom_config)
# 渲染文本
images = custom_renderer.render(long_text)
6.4 批量处理与优化
对于需要处理多个长文档的场景,可以使用批量处理:
from glyph_utils import BatchProcessor
# 初始化批量处理器
batch_processor = BatchProcessor(
model=model,
tokenizer=tokenizer,
renderer=renderer,
max_batch_size=4,
max_length=128000
)
# 准备多个文档
documents = [
"第一个长文档内容...",
"第二个长文档内容...",
# ... 更多文档
]
questions = [
"第一个文档的问题...",
"第二个文档的问题...",
# ... 对应问题
]
# 批量处理
results = batch_processor.process_batch(documents, questions)
for i, result in enumerate(results):
print(f"文档 {i+1} 的答案: {result}")
7. 技术细节与实现考量
7.1 渲染参数优化
Glyph的渲染管道包含多个可调参数,这些参数直接影响压缩比和模型性能:
# 详细的渲染参数配置
optimal_params = {
'dpi': 96, # 每英寸点数
'page_size': (2480, 3508), # 像素为单位的页面尺寸
'font_family': 'Times New Roman', # 字体族
'font_size': 11, # 字体大小
'line_height': 1.2, # 行高倍数
'alignment': 'left', # 文本对齐
'margins': (80, 80, 80, 80), # 上、右、下、左页边距
'indent': 0, # 首行缩进
'spacing': 0, # 段落间距
'h_scale': 1.0, # 水平缩放
'colors': { # 颜色配置
'background': (255, 255, 255), # 背景色
'text': (0, 0, 0) # 文字颜色
},
'borders': None, # 边框设置
'auto_crop': True # 自动裁剪
}
7.2 内存优化策略
Glyph实现了多种内存优化策略,以处理极长上下文:
class MemoryOptimizedGlyph(GlyphForConditionalGeneration):
def __init__(self, config):
super().__init__(config)
self.attention_window = 4096 # 注意力窗口大小
self.gradient_checkpointing = True # 梯度检查点
self.quantization_enabled = False # 量化开关
def enable_quantization(self):
"""启用模型量化以减少内存使用"""
self.quantize(torch.qint8)
self.quantization_enabled = True
def optimize_for_long_context(self, max_length):
"""针对长上下文进行优化"""
if max_length > 131072: # 128K
self.attention_window = 8192
self.enable_gradient_checkpointing()
if max_length > 262144: # 256K
self.enable_quantization()
7.3 训练配置细节
Glyph的训练过程涉及多个阶段的精细调优:
# 持续预训练配置
pretrain_config = {
'learning_rate': 2e-6,
'batch_size': 170,
'max_steps': 4000,
'warmup_steps': 500,
'weight_decay': 0.01,
'lr_scheduler_type': 'cosine',
'max_grad_norm': 1.0,
'context_length': 131072 # 128K
}
# SFT训练配置
sft_config = {
'learning_rate': 5e-6,
'batch_size': 32,
'max_steps': 1500,
'warmup_steps': 160,
'lr_scheduler_type': 'cosine',
'use_thinking_format': True # 使用思考格式
}
# RL训练配置
rl_config = {
'learning_rate': 1e-6,
'batch_size': 32,
'max_iterations': 500,
'group_size': 16, # GRPO组大小
'clip_range': (0.8, 1.2),
'kl_penalty': 0.1
}
8. 应用场景与案例分析
8.1 长文档理解与分析
Glyph在长文档处理方面表现出色,特别是在以下场景:
# 法律文档分析案例
legal_document = """
[长法律文档内容...]
"""
legal_questions = [
"本合同中的关键责任条款有哪些?",
"双方的违约责任是如何规定的?",
"争议解决机制是什么?"
]
for question in legal_questions:
result = process_legal_document(legal_document, question)
print(f"问题: {question}")
print(f"答案: {result}\n")
8.2 学术论文处理
Glyph可以处理完整的学术论文,进行摘要、关键点提取等任务:
def process_academic_paper(paper_content):
"""处理学术论文"""
tasks = {
"summary": "请提供这篇论文的详细摘要",
"contributions": "论文的主要贡献是什么?",
"methodology": "使用的研究方法有哪些?",
"results": "主要实验结果和发现是什么?"
}
results = {}
for task, question in tasks.items():
rendered_paper = renderer.render(paper_content)
answer = model.answer_question(rendered_paper, question)
results[task] = answer
return results
8.3 代码库分析
Glyph在分析大型代码库方面也表现出潜力:
# 代码分析示例
def analyze_codebase(code_files):
"""分析代码库"""
analysis_prompt = """
请分析以下代码库:
1. 整体架构设计
2. 主要模块和它们的功能
3. 潜在的性能瓶颈
4. 代码质量建议
"""
combined_code = "\n\n".join([f"文件: {name}\n内容:\n{content}"
for name, content in code_files.items()])
rendered_code = renderer.render(combined_code)
analysis = model.answer_question(rendered_code, analysis_prompt)
return analysis
9. 性能优化与部署建议
9.1 推理优化
对于生产环境部署,推荐以下优化策略:
class OptimizedGlyphInference:
def __init__(self, model_path):
self.model = self.load_optimized_model(model_path)
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.renderer = TextRenderer()
def load_optimized_model(self, model_path):
"""加载优化后的模型"""
model = GlyphForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
load_in_4bit=True, # 4位量化
attn_implementation="flash_attention_2" # 使用FlashAttention
)
return model
@torch.inference_mode()
def generate_optimized(self, prompt, max_tokens=512):
"""优化后的生成方法"""
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
with torch.backends.cuda.sdp_kernel(enable_flash=True):
outputs = self.model.generate(
**inputs,
max_new_tokens=max_tokens,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=self.tokenizer.eos_token_id
)
return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
9.2 分布式处理
对于需要处理大量长文档的场景,可以实现分布式处理:
from multiprocessing import Pool
import json
class DistributedGlyphProcessor:
def __init__(self, num_workers=4):
self.num_workers = num_workers
self.model_path = "THUDM/Glyph-9B"
def process_document_batch(self, document_batch):
"""处理文档批次"""
with Pool(self.num_workers) as pool:
results = pool.map(self.process_single_document, document_batch)
return results
def process_single_document(self, document_task):
"""处理单个文档"""
doc_id, content, questions = document_task
# 这里实现单个文档的处理逻辑
rendered = self.renderer.render(content)
answers = {}
for q_id, question in questions.items():
answer = self.model.answer_question(rendered, question)
answers[q_id] = answer
return {"doc_id": doc_id, "answers": answers}
10. 结论
Glyph模型代表了一种全新的长上下文处理范式,通过视觉文本压缩技术,成功实现了3-4倍的上下文压缩,同时在各种长上下文基准测试中保持了与领先LLM相当

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)