VLN 论文精读(七)GC-VLN: Instruction as Graph Constraints for Training-free Vision-and-Language Navigation
这篇论文是清华提出的一篇 VLN 领域的论文,核心思想是将自然语言指令转换为图约束,然后通过优化求解这些约束,来指导机器人在连续环境中而不是离散的节点间的导航 。
这篇论文是清华提出的一篇 VLN 领域的论文,核心思想是将自然语言指令转换为图约束,然后通过优化求解这些约束,来指导机器人在连续环境中而不是离散的节点间的导航 。
工作流程大致如下:
- 指令分解 (Instruction Decomposition):使用 LLM 将用户输入的自然语言指令分解为一个有向无环图,这个图中包含了 waypoint nodes 和 object nodes;
- 图约束构建 (Graph Constraint Construction):构建一个空间约束库,这个库定义了指令中可能出现的所有空间关系,系统使用上一步生成的 DAG 来查询这个库,从而构建出一个包含所有节点和它们之间空间关系的图约束;
- 约束求解与导航 (Constraint Solving & Navigation):导航过程变成了一个逐步求解约束的过程,使用一个约束求解器,结合机器人实时的观测 RGB-D 数据,来确定物体节点和下一个路径点的位置;
- 导航树与回溯 (Navigation Tree & Backtracking):当在求解约束没有解或有多个解时,使用导航树让机器人退回到上一个决策点,并尝试导航树中的其他分支;
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 VLN 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:GC-VLN: Instruction as Graph Constraints for Training-free Vision-and-Language Navigation
- 原文链接: https://arxiv.org/abs/2509.10454
- 发表时间:2025年09月12日
- 发表平台:arxiv
- 预印版本号:[v1] Fri, 12 Sep 2025 17:59:58 UTC (3,183 KB)
- 作者团队:Hang Yin, Haoyu Wei, Xiuwei Xu, Wenxuan Guo, Jie Zhou, Jiwen Lu
- 院校机构:
- Department of Automation, Tsinghua University;
- Beijing Key Laboratory of Embodied Intelligence Systems;
- Beijing National Research Center for Information Science and Technology;
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/bagh2178/GC-VLN
Abstract
本文提出了一种无需训练的视觉和语言导航 (VLN) 框架。现有的零样本 VLN 方法主要针对离散环境,或涉及连续仿真环境中的无监督训练,这使得它们难以在实际场景中推广和部署。为了在连续环境中实现无需训练的框架,作者将 导航引导转化为图约束优化,将指令分解为显式的空间约束。约束驱动范式通过约束求解来解码空间语义,从而实现对未知环境的零样本自适应。具体而言,构建了一个空间约束库,涵盖 VLN 指令中提到的所有类型的空间关系。人类指令被分解为一个有向无环图,其中包含航点节点、对象节点和边,这些节点用作查询来检索库以构建图约束。约束求解器求解图约束优化,以确定航点的位置,从而获得机器人的导航路径和最终目标。为了处理无解或多解的情况,作者 构建了导航树和回溯机制。在标准基准上进行的大量实验表明,与最先进的零样本 VLN 方法相比,框架在成功率和导航效率方面均有显著提升。进一步进行了真机实验,以证明框架能够有效地推广到新的环境和指令集,从而为构建更稳健、更自主的导航框架奠定了基础。
1. Introduction
VLN 是各种具身任务的必要基础能力,它要求机器人在陌生的环境中遵循复杂的语言指令移动。VLN 指令通常描述路径序列,包括 沿路径移动的方向和距离 以及路径附近的场景信息。这需要机器人具备语言理解、环境感知和空间推理的能力。然而,受限于标注数据的可用性,早期数据驱动的 VLN 方法在未见过的场景中表现出较差的泛化能力。此外,大多数现有的数据驱动的 VLN 方法都是在仿真环境中训练的,这导致模拟与现实之间存在较大的差距。因此,构建独立于数据的零样本导航框架至关重要。
为了克服标注数据的局限性并缩小模拟与现实之间的差距,Zero-shot VLN 方法被学界提出。DiscussNav 利用多专家讨论来整合指令理解、环境感知和决策验证;MapGPT 构建了一个基于地图引导的 GPT 智能体,该智能体利用在线语言形成的地图进行自适应路径规划。然而,受制于不成熟的仿真器,这些零样本 VLN 方法只能在离散环境中运行,这只允许机器人在环境中的一组离散节点之间移动。离散仿真环境中的方法不适用于实际场景,从而导致了显著的模拟与现实之间的差距。为了更好地模拟真实环境,引入了连续环境中的视觉和语言导航 (Vision-and-language navigation in continuous environments, VLN-CE),机器人可以在环境中自由移动并站立在任何位置。在 VLN-CE 中,机器人预测低级动作,包括转弯和前进,这更接近真实环境。VLN-CE 方法可以轻松部署到新的真实场景中,无需进行自适应。然而,大多数现有的零样本 VLN-CE 方法仍然依赖于仿真器内的无监督训练。A2Nav 为 VLN-CE 构建了五个子任务,并在仿真器中以自监督的方式训练这五个子任务模块。由于在仿真器数据上进行自监督训练,这些方法仍然存在模拟与现实之间的差距。因此,迫切需要一种无需训练的 VLN-CE 框架。
本文提出了用于视觉和语言导航的图约束(Graph-Constraints for Vision-and-Language Navigation, GC-VLN),这是一个无需训练的VLN-CE框架。与以往部署在离散环境中或在仿真器数据上进行自监督训练的研究不同,GC-VLN 采用完全无需训练的方法来感知场景并预测路径。具体来说,构建了一个约束库涵盖指令中发现的所有类型的空间关系约束,然后将语言指令分解为有向无环图,并使用该有向无环图查询该库以构建图约束。导航被表述为一个图约束优化问题,其中航点节点的坐标由约束求解器逐步求解;此外,还构建了一个导航树来解决图约束求解过程中解的数量不确定性问题。在仿真基准测试 R2R-CE 和 RxR-CE 上进行了大量的实验,并取得了全面的 SOTA 性能。真实世界的实验进一步证明了方法强大的泛化能力。
2. Related Work
2.1 Vision-and-Language Navigation
在现实世界的导航场景中,人类通常对到达目标的路径有先验知识。因此,机器人无需自主探索目标。利用人类的先验知识,机器人遵循人类指令到达目标,这项任务称为视觉和语言导航 (VLN) 。早期的 VLN 方法使用离散仿真环境来评估 VLN 方法,其中环境被划分为多个离散的可驾驶路径点。机器人只能站在路径点上,并在每一步中选择一个相邻的路径点作为短期目标。离散环境使该方法能够专注于路径选择。然而,由于模拟与现实之间的巨大差距,离散 VLN 方法难以在现实世界场景中部署。
为了更贴近真实场景,提出了连续环境中的视觉和语言导航(VLN-CE),通过预测低级动作,使机器人能够在场景内自由移动。为 VLN-CE 设计的方法无需修改即可直接部署到真实场景中。为了在离散 VLN 方法的简化和 VLN-CE 对真实环境的逼近之间取得平衡,提出了航点预测器,用于在连续环境中在线预测离散航点,并成为 VLN-CE 任务的主流技术方法。
2.2 Training-free Navigation
传统的导航方法是任务训练型的,涉及诸如 LSTM 和 Transformer 等模块。标注数据的局限性导致这些方法对于更多样化的目标或人类指令的泛化能力有限。此外,任务训练方法也存在模拟与现实之间的差距,这限制了它们在实际场景中的表现。
为了解决泛化问题,人们提出了零样本导航方法。在面向目标的导航领域,用于 object-goal 导航、image-goal 导航和 text-goal 导航的零样本方法已经相对成熟。对于离散环境中的VLN,零样本方法也取得了显著进展。然而,对于VLN-CE任务,零样本方法仍然不能令人满意,而这正是作者想要达成的目标。
3. Approach
首先介绍任务定义和该方法的整体流程,然后解释图约束 K \mathcal{K} K 的构造方法。最后,详细说明如何依次求解 K \mathcal{K} K 中节点的坐标,并利用 K \mathcal{K} K 来指导导航方向。
3.1 Overview
在 VLN 中,机器人在未知环境中初始化。机器人需要遵循人类提供的语言指令 I \mathcal{I} I,以便在环境中移动并到达最终目的地。如 Fig.1 所示,指令通常是一段文本,描述如何从起点导航到目的地,包括导航方向、导航路径上遇到的物体以及导航路径与物体之间的空间关系。如果代理在不超过 t t t 步的时间内到达导航终点 r r r 米范围内,则导航成功。

Figure 1: GC-VLN 将指令建模为图约束优化问题,并根据机器人的观测结果求解图约束以获得机器人的路径,从而实现无需训练的 VLN。将演示图约束如何引导导航路径,以及在探索失败时如何重新规划路径。
Pipeline
如 Fig.2 所示,GC-VLN的流水线包含两个主要模块:图约束构建模块 和 约束优化模块。首先,将原始指令分解为一个多阶段有向无环图 G \mathcal{G} G,其中包含导航所需的所有信息。构建一个约束库,该约束库涵盖 VLN 指令中所有类型的空间关系。利用图 G \mathcal{G} G 查询该库,获取节点之间的约束类型,从而构建图约束 K \mathcal{K} K。 K \mathcal{K} K 中节点坐标的确定被转化为基于约束条件的约束优化问题,导航树处理来自约束求解器的坐标解个数不确定的问题,当没有解满足约束条件时进行回溯。
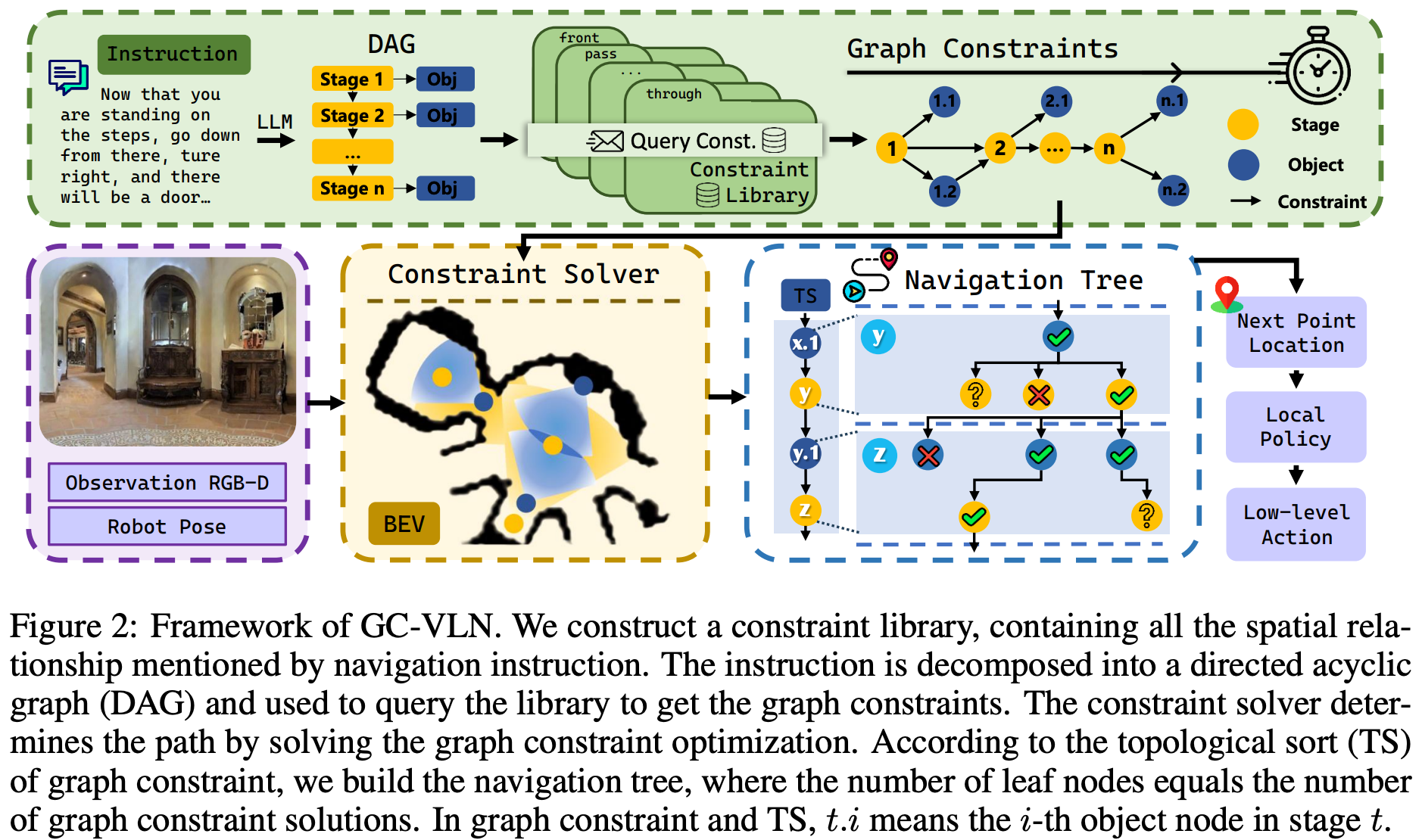
Figure 2: GC-VLN 框架。构建了一个约束库,其中包含导航指令中提到的所有空间关系。该指令被分解为有向无环图 (directed acyclic graph, DAG),并用于查询该库以获取图约束。约束求解器通过求解图约束优化来确定路径。根据图约束的拓扑排序 (topological sort, TS),构建导航树,其中叶节点的数量等于图约束解的数量。在图约束和 TS 中, t . i t.i t.i 表示阶段 t t t 中的第 i i i 个对象节点。
3.2 Graph Constraint Construction
为了处理指令 I \mathcal{I} I 中的长序列特征和复杂的空间关系,将 I \mathcal{I} I 转换为结构化表示,即图约束,它需要满足三个标准:
- 不能丢失 I \mathcal{I} I 中的任何信息;
- 必须明确包含 I \mathcal{I} I 中提到的所有对象;
- 必须提供明确的导航方向,以及对象与导航路径之间的空间关系;
Instruction Decomposition
要求 LLM 将指令 I \mathcal{I} I 分解为多个导航阶段,每个阶段仅涉及一次位移(旋转次数不做要求)。每个阶段包含两个属性:导航方向 和 该阶段出现的对象。导航方向分为以下几类:["front", "right", "left", "back", "unknown"]。指令 I \mathcal{I} I 中提到的每个对象都属于且仅属于一个导航阶段。每个对象都有一个属性:它与导航路径的空间关系。这些节点和边构成一个有向无环图 G \mathcal{G} G。
图 G = \mathcal{G}= G=LLM( I \mathcal{I} I),其中 G = ( V , E ) \mathcal{G=(V,E)} G=(V,E) 式中 V , E \mathcal{V,E} V,E 分别代表节点和有向边; V \mathcal{V} V 可以被分为 waypoints 导航点 V w \mathcal{V}^{w} Vw 和 object nodes 对象点 V o \mathcal{V}^{o} Vo,其中 V w = { v 1 w , v 2 w , … , v n w } , V o = ⋃ i = 1 n { v i 1 o , v i 2 o , … , v i k i o } \mathcal{V}^{w}=\{v_{1}^{w},v_{2}^{w},\dots,v_{n}^{w}\}, \mathcal{V}^{o}=\bigcup^{n}_{i=1}\{v_{i1}^{o},v_{i2}^{o},\dots,v_{ik_{i}}^{o}\} Vw={v1w,v2w,…,vnw},Vo=⋃i=1n{vi1o,vi2o,…,vikio};边个可以根据是否连接到对象节点被分为 E w \mathcal{E}^{w} Ew 和 E o \mathcal{E}^{o} Eo,其中 E w = { ( v i w , v i + 1 w ) ∣ 1 ≤ i ≤ n − 1 } , E o = ⋃ i = 1 n = ( { ( v i w , v i j o ) ∣ 1 ≤ j ≤ j k } ∪ { ( v i j o , v i w ) ∣ 1 ≤ j ≤ m i } ) \mathcal{E}^{w}=\{(v_{i}^{w},v_{i+1}^{w})|1\leq i\leq n-1\},\mathcal{E}^{o}=\bigcup^{n}_{i=1}=(\{(v_{i}^{w},v_{ij}^{o})|1\leq j\leq j_{k}\}\cup\{(v_{ij}^{o},v_{i}^{w})|1\leq j\leq m_{i}\}) Ew={(viw,vi+1w)∣1≤i≤n−1},Eo=⋃i=1n=({(viw,vijo)∣1≤j≤jk}∪{(vijo,viw)∣1≤j≤mi}),式中 v i w v_{i}^{w} viw 和 v i j o v_{ij}^{o} vijo 表示第 i i i 阶段中的航点节点和第 j j j 个对象节点, e = ( u , v ) e=(u,v) e=(u,v) 代表从节点 u u u 到节点 v v v 的路径。有关指令分解的详细信息,请参阅补充材料。
Constraint Library
指令 I \mathcal{I} I 中提到的节点之间的空间关系被认为是它们坐标 u u u, v v v 的空间约束 c ( v ∣ u ) c(v|u) c(v∣u)。约束的类型根据 I \mathcal{I} I 中对空间关系拓扑的描述进行区分。如 Fig.3 所示,构建了一个包含六种约束类型的约束库 L \mathcal{L} L,涵盖了VLN指令中涉及的所有空间关系拓扑类型。
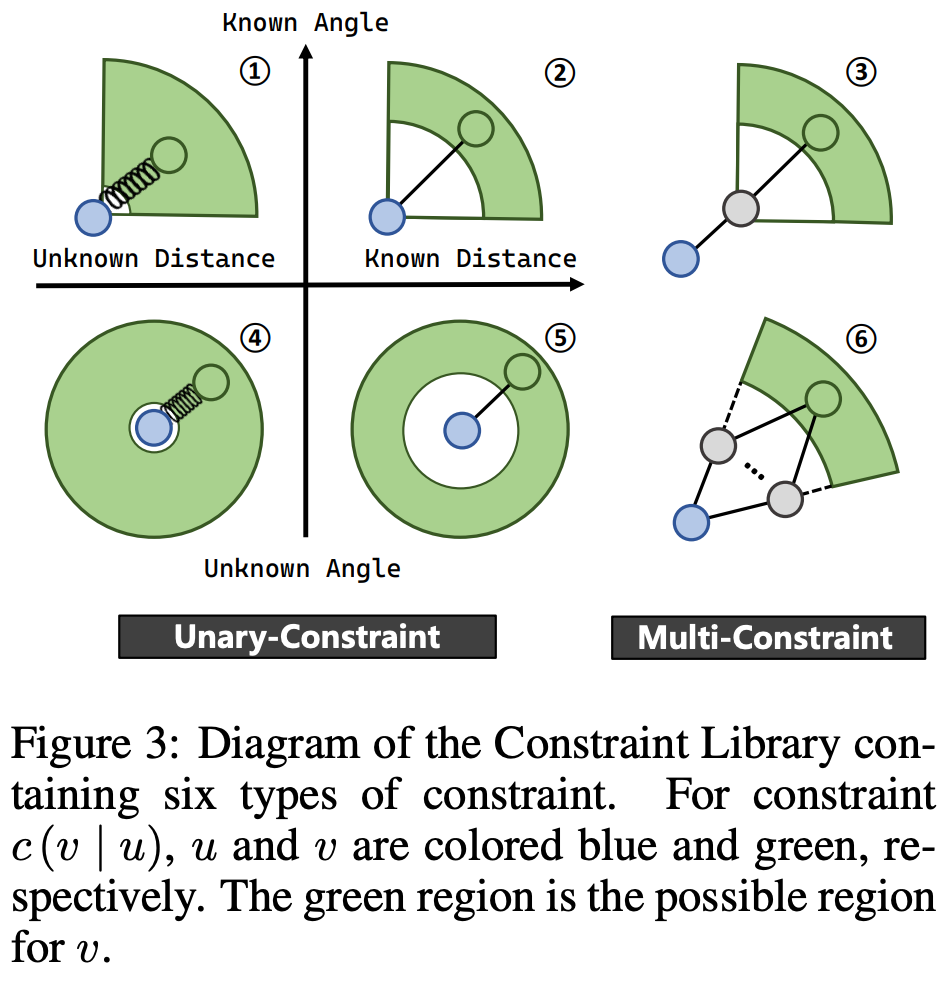
Figure 3: 约束库示意图,包含六种约束类型。对于约束 c ( v ∣ u ) c (v | u) c(v∣u), u u u 和 v v v 分别标记为蓝色和绿色。绿色区域是 v v v 的可能区域。
假设 u u u 已知,以第二类约束为例,约束 c ( v ∣ u ) c(v|u) c(v∣u) 可以表示为:
c ( v ∣ u ) = ( c a ( v ∣ u ) , c d ( v ∣ u ) ) , sum ( c ) = c a + c d , min ( c ) = min ( c a , c d ) c a ( v ∣ u ) = cos ( Δ ϕ ) ∣ ∣ v − u ∣ ∣ − [ ∣ ∣ v − u ∣ ∣ − ( v − u ) ⋅ ( cos ϕ , sin ϕ ) ] c d ( v ∣ u ) = Δ d 2 − ( ∣ ∣ v − u ∣ ∣ − d ) 2 \begin{align} c(v|u)&=(c^{a}(v|u),c^{d}(v|u)), \text{sum}(c)=c^{a}+c^{d}, \min(c)=\min(c^{a},c^{d}) \\ c^{a}(v|u)&=\cos(\Delta\phi) ||v-u|| - [||v-u||-(v-u)\cdot(\cos\phi,\sin\phi)] \\ c^{d}(v|u)&=\Delta d^{2}-(||v-u||-d)^{2} \end{align} c(v∣u)ca(v∣u)cd(v∣u)=(ca(v∣u),cd(v∣u)),sum(c)=ca+cd,min(c)=min(ca,cd)=cos(Δϕ)∣∣v−u∣∣−[∣∣v−u∣∣−(v−u)⋅(cosϕ,sinϕ)]=Δd2−(∣∣v−u∣∣−d)2
其中 ϕ \phi ϕ、 Δ ϕ \Delta\phi Δϕ 和 d d d、 Δ d \Delta d Δd 分别为 e e e 的基准线和角度与距离的容差, c a c^{a} ca、 c d c^d cd 分别为角度和距离的子约束。其余五类约束的子约束的完整表达式见补充材料。
Graph Constraint
使用 e ∈ E e\in\mathcal{E} e∈E 查询约束库 L \mathcal{L} L,得到与 e e e 对应的约束类型 c = L ( e ) c = \mathcal{L}(e) c=L(e)。所有节点和约束共同构成图约束 K \mathcal{K} K:
K = ( V , C ) , C = { L ( e ) ∣ e ∈ E } \begin{equation} \mathcal{K}=(\mathcal{V,C}), \mathcal{C}=\{\mathcal{L}(e)|e\in\mathcal{E}\} \end{equation} K=(V,C),C={L(e)∣e∈E}
c c c 的方向代表因果关系和推断的方向,这意味着只有知道其父节点 u u u 的坐标,才能推断出 v v v 的坐标。在导航开始时坐标 v 1 w v_{1}^{w} v1w 值为 ( 0 , 0 ) (0,0) (0,0), V \mathcal{V} V 中其他节点坐标都是未知的;在导航结束时,所有 v i w ∈ V w v_{i}^{w}\in\mathcal{V}^{w} viw∈Vw 中的坐标都被探明, v n w v_{n}^{w} vnw 是本次 episode 的终点。
3.3 Constrained Optimization for Node Coordinates
图约束 K \mathcal{K} K 用于引导机器人的运动方向。节点 v ∈ V v\in\mathcal{V} v∈V 的坐标根据导航顺序确定。作者提出了一个 图约束优化框架来确定坐标,并提出了一个导航树来处理解数量的不确定性。
Constraint Solver
图约束 K \mathcal{K} K 用于求解路径点 v i w ∈ V w v_{i}^{w}\in\mathcal{V}^{w} viw∈Vw。通过使用预先训练的视觉模型感知 RGB-D 观测来确定对象节点 v i j o ∈ V o v_{ij}^{o}\in\mathcal{V}^{o} vijo∈Vo 的坐标。求解节点 v v v 的坐标需要了解 K \mathcal{K} K 中其所有父节点的坐标。在导航的初始状态下,只有 Stage 1 的起点(作为 K \mathcal{K} K 的根节点 v 1 w v_{1}^{w} v1w)具有已知坐标; v 1 w v_{1}^{w} v1w作为求解所有后续节点坐标的原始参考。对 K \mathcal{K} K 执行拓扑排序 (topological sort, TS) 以确定导航过程中解决节点坐标的顺序。拓扑排序的顺序确保对于任何约束 c ( v ∣ u ) c(v|u) c(v∣u) 中 v v v 总是跟在 u u u 后面。因此,在按此顺序确定节点坐标时,保证当前节点的父节点坐标已解出。拓扑排序的详细信息可参见补充材料。
对于航点 v i w v_{i}^{w} viw,多种约束 C = { c ( v i w ∣ v i − 1 w ) } ∪ { c ( v i w ∣ v i j o ) ∣ 1 ≤ j ≤ m i } \mathcal{C}=\{c(v_{i}^{w}|v_{i-1}^{w})\}\cup\{c(v_{i}^{w}|v_{ij}^{o})|1\leq j\leq m_{i}\} C={c(viw∣vi−1w)}∪{c(viw∣vijo)∣1≤j≤mi} 联合限制,对应于指向的所有边 v i w v_{i}^{w} viw。将坐标确定表述为非线性约束优化问题(nonlinear constrained optimization problem, P1):
(P1): Maximize v i w ∑ c ∈ C v i w sum ( c ) subject to min ( c ) ≥ 0 , ∀ c ∈ C v i w ∣ ∣ v i w − x j ∣ ∣ ≥ L , ∀ j ∈ { 1 , … , k − 1 } \begin{align} \text{(P1):} &\substack{\text{Maximize} \\ v_{i}^{w}}\sum_{c\in\mathcal{C}_{v_{i}^{w}}}\text{sum}(c) \\ &\text{subject to}\min(c)\geq0,\forall_{c}\in\mathcal{C}_{v_{i}^{w}} \\ & ||v_{i}^{w}-x_{j}||\geq\text{L},\forall j\in\{1,\dots,k-1\} \end{align} (P1):Maximizeviwc∈Cviw∑sum(c)subject tomin(c)≥0,∀c∈Cviw∣∣viw−xj∣∣≥L,∀j∈{1,…,k−1}
其中 x j x_{j} xj 表示 v i w v^{w}_{i} viw 的第 j j j 个解。函数 sum ( c ) \text{sum}(c) sum(c) 和 min ( c ) \text{min}(c) min(c) 分别表示 c c c 中子约束的和与最小值。该约束被求解多次,在第 k k k 次迭代中,将前 k − 1 k-1 k−1 个解并入约束条件中。对于对象节点 v j i o v_{ji}^{o} vjio ,仅保留约束条件(不包含优化目标)。预训练的视觉模型感知观测中的对象,并将这些对象投影到 BEV 图上。满足约束条件的对象坐标被选为 v j i o v_{ji}^{o} vjio 的解。
Navigation Tree
约束求解器为节点 v ∈ V v\in\mathcal{V} v∈V 生成不确定数量的解。构建导航树 T \mathcal{T} T 来处理这种不确定性,其中 T \mathcal{T} T 中的每个节点在环境中都有特定的坐标。假设 K \mathcal{K} K 的拓扑排序 (TS) 为 [ v 1 , v 2 , … , v ∣ V ∣ ] [v_{1},v_{2},\dots,v_{|\mathcal{V}|}] [v1,v2,…,v∣V∣],约束求解器逐步求解节点坐标。根据约束求解器的解的数量,TS 扩展为导航树,其中 T 中第 i i i 层的节点是 K \mathcal{K} K 中第 i i i 个节点 v i v_{i} vi 的坐标解。站在 T \mathcal{T} T 的第 i i i 层,导航树第 ( i + 1 ) (i + 1) (i+1) 层的分支数对应于 v i + 1 v_{i+1} vi+1 的解的数量。从 T \mathcal{T} T 中的根节点到 T \mathcal{T} T 中的叶节点的路径对应于环境中的特定路径。
如果约束求解器未能找到可行解,则 v i v_{i} vi 在该层级上将没有分支,这表明该特定导航分支失败。在这种情况下,机器人将在 T \mathcal{T} T 中回溯,直到找到一个具有未探索兄弟节点的分支点。在此分支点,机器人选择下一个未探索的兄弟节点作为未来路径。回溯机制增强了 GC-VLN 的容错能力,使机器人能够探索可能错过的正确路径。如果机器人到达 T \mathcal{T} T 的最后一层级(对应于端点 v ∣ V ∣ v_{|\mathcal{V}|} v∣V∣),则导航终止。
4. Experiments
使用仿真器和真实场景进行了大量的实验,以验证方法的有效性。本节将分别介绍实验设置、与 SOTA 方法的比较、消融研究、定性分析。
4.1 Benchmarks and Implementation Details
Datasets
对 VLN-CE 任务的主流 R2R-CE 和 RxR-CE 数据集进行了模拟器实验。R2R-CE 和 RxR-CE 是通过将 R2R 和 RxR VLN 数据集中的离散轨迹转换为 Habitat 模拟器内的连续轨迹而得出的。R2R-CE 和 RxR-CE 数据集中的场景来源于 MP3D 数据集。使用 R2R-CE 和 RxR-CE 的验证集-未见集划分,包括 1,839 和 11,006 个 episode。R2R-CE 中的指令全是英文,而 RxR-CE 中的指令则使用三种语言。RxR-CE 中的平均路径长度和指令长度均大于 R2R-CE。
Evaluation Metrics
使用成功率 (success rate, SR) 和路径长度加权的成功率 (success rate weighted by path length, SPL) 作为主要评估指标。SR 表示智能体成功到达端点 m 米范围内的事件比例,其中 m = 3 m = 3 m=3;SPL 在成功率的基础上,结合了路径长度,反映了实际路径与地面真实路径之间的相似性。此外,还测试了导航误差 (navigation error, NE) 和 Oracle 成功率 (Oracle Success Rate, OSR)。
Compared Methods
与无需训练的 VLN-CE 的最新方法进行了比较。NavGPT-CE 是针对连续环境的 NavGPT 适配版本;CA-Nav 是一种约束感知的零样本 VLN-CE 方法;InstructNav 是一种通用的指令导航方法,适用于 VLN-CE、目标-目标导航和需求驱动导航。
Implementation Details
在 habitat 仿真环境和真实世界机器人 Hex move 中评估了 GC-VLN。部署 DeepSeek-R1 作为 LLM 进行指令分解,并使用 Grounded-SAM 2 进行物体感知。局部策略采用 Fast Marching Method 快速行进法。
4.2 Comparison with State-of-the-art
Table.1 中比较了 GC-VLN 与最先进的 VLN-CE 方法,分别在监督学习、零样本和免训练三种 VLN-CE 环境下的表现。GC-VLN 超越了之前的零样本方法,并且在 R2R-CE 基准测试中,比目前最佳的免训练方法 InstructNav 的成功率高出 2%。在 RxR-CE 上的表现优于所有已报告性能的零样本方法;在监督学习环境下也优于一些方法,例如 RxR-CE 上的 NaVid。
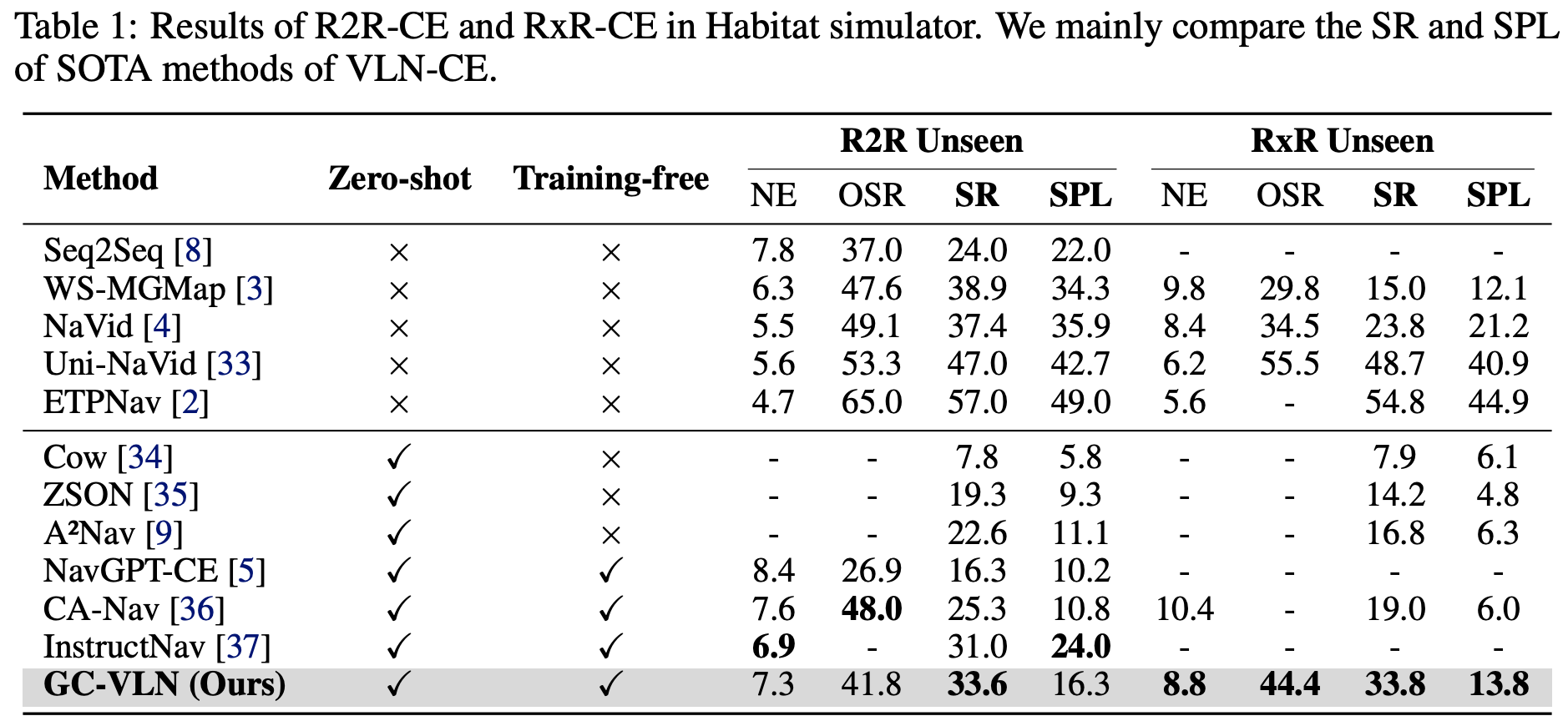
尤其RxR比R2R更具挑战性,但我们的方法在RxR上保持了较高的性能,体现了其更强的处理复杂指令的能力。
4.3 Ablation Study
对 R2R-CE 进行消融研究,以验证 GC-VLN 中每个模块的有效性。
Effect of graph constraint
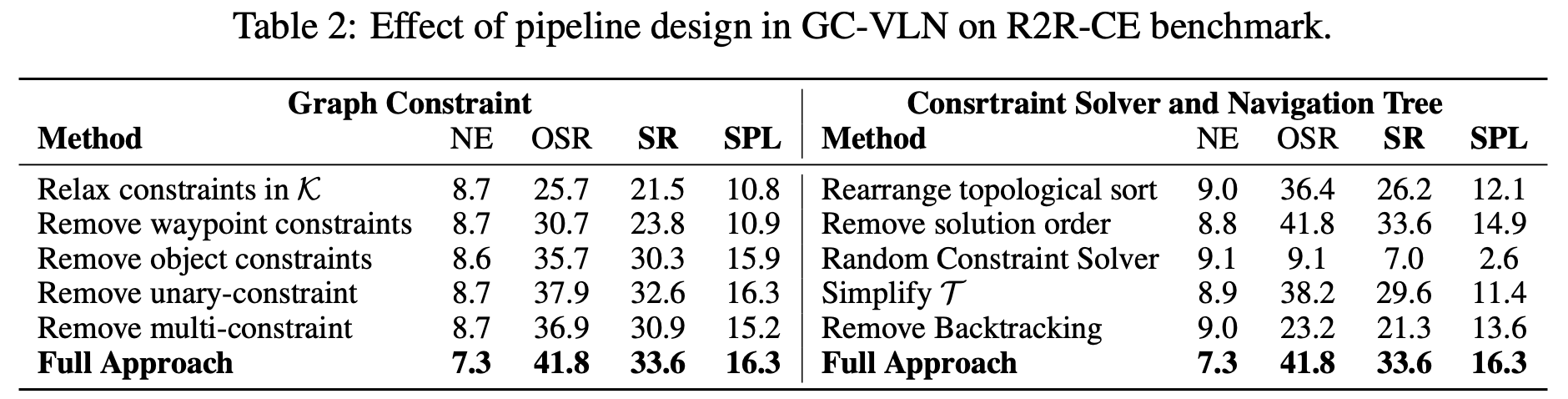
Table.2 中首先放宽了图约束,即移除角度约束,仅保留最大距离作为距离约束。结果显示,SR和SPL显著下降。然后我们删除航点约束 c ( v t + 1 w ∣ v t w ) c(v^{w}_{t+1}|v_{t}^{w}) c(vt+1w∣vtw)、对象约束 c ( v t + 1 w ∣ v t j o ) c(v^{w}_{t+1}|v^{o}_{tj}) c(vt+1w∣vtjo)、一元约束 (type 1, 2, 4, 5)、多约束 (type 3,6),用最弱的约束(type 4)代替它们,GC-VLN的性能出现了不同程度的下降,证明了图约束的有效性。
Effect of constraint solver and navigation tree
通过使对象节点不再属于特定阶段来重新排列拓扑排;对于解的顺序,不再使用节点坐标解的顺序来构建导航树分支,而是采用随机顺序;对于约束求解器,不再使用最大化目标函数来求解坐标,而是在约束条件定义的区域内随机采样点;通过移除早期未探索的分支来简化导航树 T \mathcal{T} T,并通过完全不保存未探索的分支来消除回溯。发现性能全面下降,证明了约束求解器和导航树的有效性。
4.4 Qualitative Results
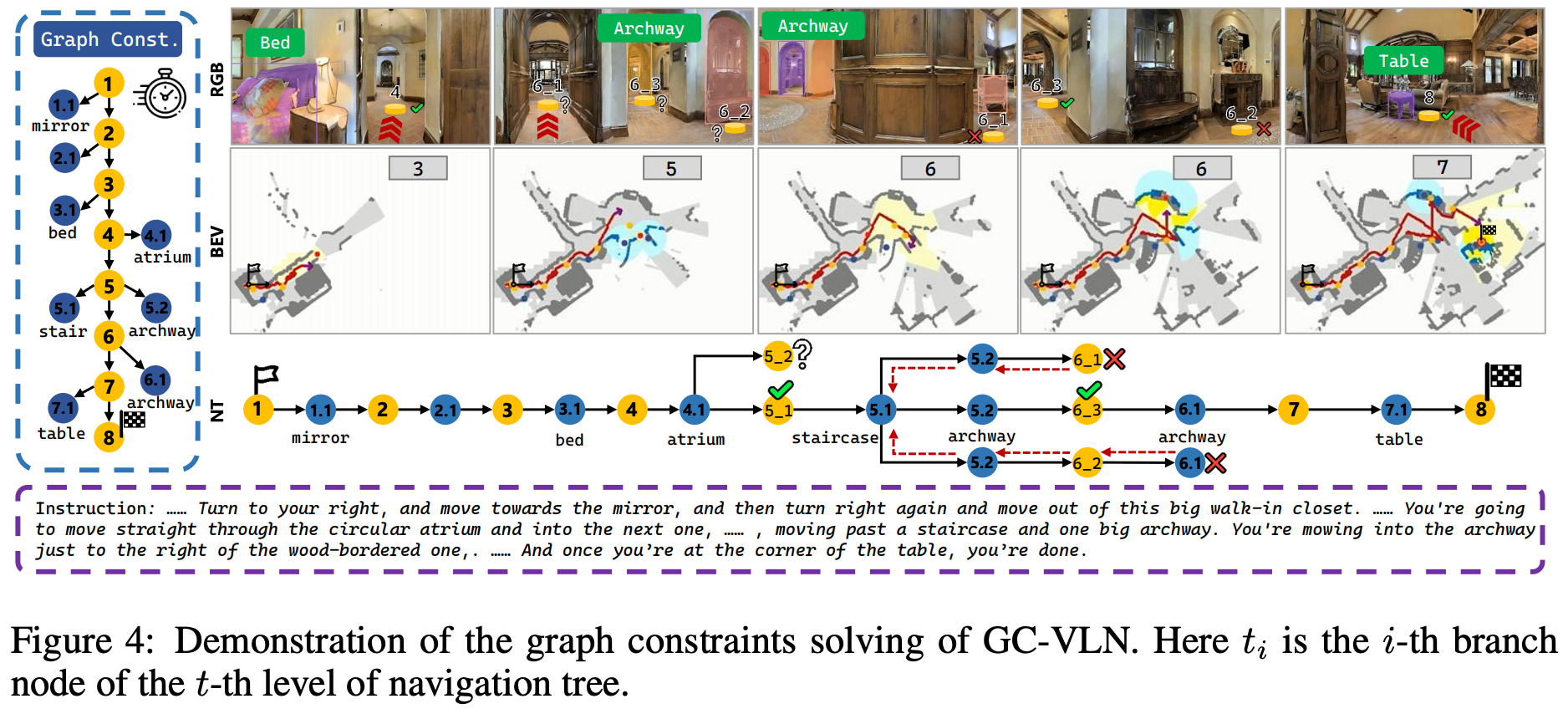
为了更直观地展示效果,作者分别在仿真器和真实环境中展示了导航过程的可视化效果。如 Fig.4 所示,机器人在模拟器中逐步探索场景,并根据空间约束求解每个航点的位置。
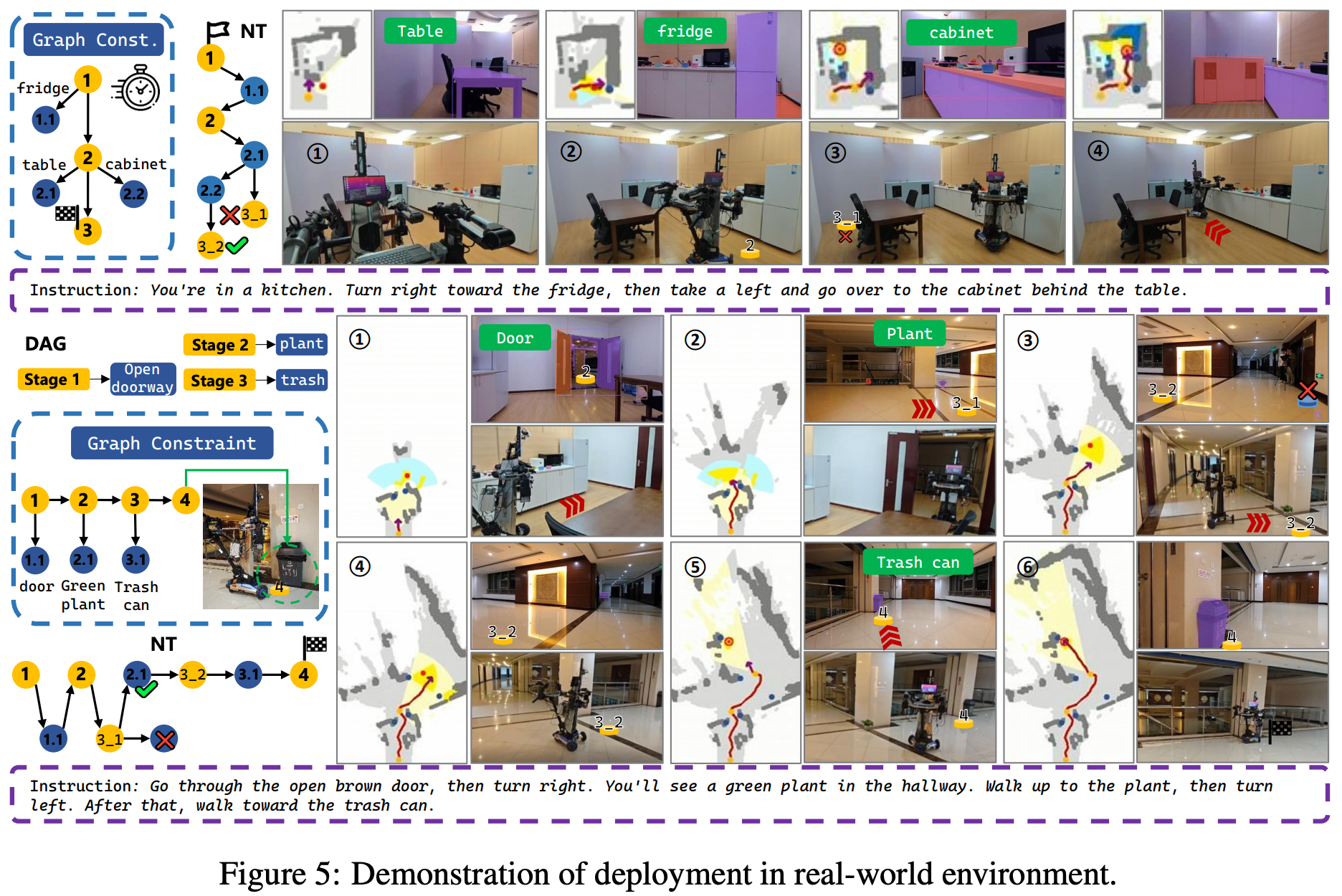
如 Fig.5 所示,在真实世界中部署了 GC-VLN,展示了其在真实世界中强大的泛化能力。
5. Conclusion
本文提出了一种图约束引导的免训练视觉和语言导航框架。由于离散环境下的零样本VLN方法和连续环境下的自监督VLN方法在模拟和实际应用中存在较大的差距,因此在实际场景中部署它们具有挑战性。作者构建了一个包含所有可能空间约束的空间约束库,并利用LLM将指令分解为有向无环图。该图用于查询约束库并获取图约束。有向无环图中节点的位置由约束求解器确定,从而解决了图约束优化问题。导航树用于处理解数量不确定的问题。在模拟和实际场景中进行的大量实验证明了GC-VLN的性能和泛化能力,它可以轻松地部署在实际环境中而不会降低性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)