MongoDB多模态数据库与AI技术栈联动
本文分享了作者在MongoDB开发者大会上的技术演讲内容,重点探讨了MongoDB在多模态数据处理和AI智能化辅助方面的应用。文章指出,数据治理应以业务需求为导向,MongoDB凭借其灵活的文档模型、强大的聚合框架和多种索引方案,能有效处理文本、图像、时序等多模态数据。同时介绍了MongoDB与AI技术的结合,如向量搜索、实时流处理等创新应用。通过具体案例展示了MongoDB在混合架构中的实践价值
在举办的MongoDB开发者大会,并围绕《MongoDB高效应用》主题进行了技术分享。现将演讲核心内容整理成文,望能给诸位提供实践参考和启示。
本次分享的主旨:
基于多年数据库及周边领域的工作经验,笔者总结出核心结论:“数据治理工作应当围绕业务需求展开,并以业务流程架构作为核心设计依据”,形成可落地的实施框架。
本次分享技术栈主角:
MongoDB作为NoSQL数据库的杰出代表,在处理多模态非结构化数据方面具备显著技术优势,能够帮助业务带来以下效能提升:
1.多模态数据统一存储与高效查询
-
文档模型灵活性:支持直接存储JSON格式的异构数据,无需预定义模式即可容纳文本、图像元数据、时序数据等多模态信息;
-
聚合管道强化处理:通过$match、$lookup、$group等聚合阶段实现跨模态数据关联分析,例如将订单数据与库存信息实时关联;
-
索引优化机制:支持复合索引、文本索引、地理空间索引等多维索引方案,保障混合工作负载下的毫秒级响应;
2.AI增强型技术栈赋能智能业务
-
矢量搜索集成:原生支持向量嵌入检索,可直接对接生成式AI模型,实现语义相似度匹配、推荐系统等场景;
-
实时流处理能力:通过Change Streams监控数据变更,结合Atlas Stream Processing构建事件驱动架构;
-
客户端字段级加密:在数据离开应用前完成加密,为敏感业务数据提供端到端安全防护;
3.云端一体化部署与弹性扩展
-
Atlas云平台集成:提供完全托管的多云数据库服务,支持自动分片和弹性扩缩容;
-
数据联邦查询:支持跨多个数据源联合查询,打破业务数据孤岛;
-
DevOps友好工具链:Compass图形化界面、Relational Migrator迁移工具等大幅降低运维复杂度;
本次分享的内容总结:
一、业务模型为导向的应用平台
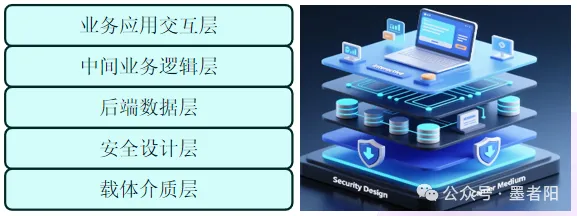
笔者基于商业某业务类型平台的架构设计实践,总结出其典型五层架构模型,自上而下依次为:业务应用交互层(用户界面与功能入口)、中间业务逻辑层(核心业务规则与流程引擎)、后端数据层(数据存储与处理中枢)、安全设计层(全链路安全防护体系)、载体介质层(物理与虚拟资源基础设施)。该架构模型通过分层解耦实现业务与技术的有机融合。
|
业务层次 |
业务特点 |
技术需求 |
|
业务应用交互层 |
直接面向用户,提供交互界面,注重用户体验、易用性和响应速度。 | 前端技术(HTML/CSS/JavaScript、React/Vue等)、响应式设计、UI/UX优化、移动端适配。 |
|
中间业务逻辑层 |
实现核心业务逻辑,处理业务流程、规则引擎、事务控制,强调灵活性和可扩展性。 | 后端开发框架、微服务架构、API设计、业务流程管理(BPM)、事务管理。 |
|
后端数据层 |
负责数据存储、管理、查询和分析,关注数据一致性、完整性和性能。 |
数据库技术、数据建模、缓存、数据仓库、数据备份与恢复。 |
|
安全设计层 |
贯穿各层的安全策略实施,确保数据、系统和用户的安全,强调防护和合规。 |
身份认证与授权(OAuth2、RBAC)、加密技术(SSL/TLS、数据加密)、安全审计、防火墙、入侵检测。 |
|
载体介质层 |
提供系统运行的物理或虚拟基础设施,保障系统稳定性、可用性和可扩展性。 |
云计算平台、容器化、服务器、网络、存储、监控与运维。 |
在业务开展过程中,可能涉及多种模态的非结构化数据,具体包括:
|
类别 |
子类型 |
典型格式/示例 |
说明 |
|
文本类数据 |
办公文档 |
Word/Excel/PPT、OFD版式文档、PDF |
OFD为国产版式标准,PDF支持混合内容 |
|
标记语言数据 |
XML、HTML |
XML为半结构化,HTML为嵌套式半结构化 |
|
|
多媒体类数据 |
图像数据 |
JPG/PNG/GIF、扫描件(如OFD) |
可嵌入PDF或OFD中 |
|
音视频数据 |
MP3/WAV音频、MP4/AVI视频 |
常见于业务培训材料 |
|
|
复合型数据 |
混合格式文档 |
含XML数据流的PDF、OFD公文(整合文本、签章、元数据) |
如可检索的电子合同 |
|
业务系统生成数据 |
社交媒体评论(文本+图片)、工业检测报告(XML描述+缺陷图片+视频记录) |
多模态组合场景 |
|
|
特殊格式数据 |
XML衍生格式 |
XSLT转换模板、RSS订阅数据 |
基于XML的扩展应用 |
|
OFD特有元素 |
电子签章数据、版式控制指令 |
OFD格式的独有功能 |

二、后端数据层技术挑战与MongoDB应对方案
在业务场景中,面对高频交易、实时性要求高且数据一致性强的挑战,可采取以下应对方案:
-
事务支持:
MongoDB 4.0+ 支持多文档ACID事务,确保数据读写操作等环节的数据一致性。
// MongoDB 事务示例
const session = db.getMongo().startSession();
session.startTransaction();
try {
const icsCollection = session.getDatabase("ic_db").getCollection("ics");
const auditCollection = session.getDatabase("ic_db").getCollection("audit_logs");
icsCollection.insertOne({
icCode: "00001",
aot: 15.00,
isDate: new Date(),
status: "isd"
});
auditCollection.insertOne({
action: "ic_isd",
icCode: "00001",
timestamp: new Date(),
userId: "xxxxxx"
});
session.commitTransaction();
} catch (error) {
console.error("Transaction aborted:", error);
session.abortTransaction();
} finally {
session.endSession();
}-
复杂查询能力:
MongoDB 强大的聚合框架支持多维度检索和联表查询:
db.ics.aggregate([
{
$match: {
"icCode": { $regex: /^INV2024/ },
"aot": { $gte: 10, $lte: 50 },
"issueDate": {
$gte: ISODate("2024-01-01T00:00:00Z"),
$lte: ISODate("2024-12-31T23:59:59Z")
}
}
},
{
$group: {
_id: {
month: { $month: "$issueDate" },
status: "$status"
},
totalaot: { $sum: "$aot" },
count: { $sum: 1 }
}
},
{
$sort: {
"_id.month": 1,
"totalaot": -1
}
},
{
$project: {
month: "$_id.month",
status: "$_id.status",
totalaot: 1,
count: 1,
_id: 0
}
}
])-
数据安全与合规:
MongoDB 提供字段级加密、审计日志、角色权限控制,满足税务监管要求。三、海量业务下的技术挑战与数据库架构选择
面对高频、多模态、非结构化的业务场景,采用混合架构模式,充分发挥各数据库优势。
混合模式架构落地:
MongoDB:处理非结构化、多模态业务数据(文档、XML/OFD/PDF元数据)
MySQL:存储强一致性要求的基础信息数据
Redis:缓存高频访问数据和会话状态
OSS:存储数据原件文件(PDF/OFD/XML)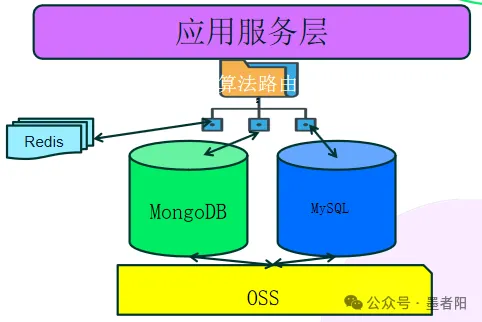
四、MongoDB多模态能力在业务的实践
MongoDB支持多模态数据存储,无需预定义结构,适应业务变化。
-
JSON/BSON 原生支持:
将XML、OFD、PDF等格式的元数据提取后存储为JSON文档,保留原始结构
// 某文档示例
{
_id: ObjectId("..."),
iCode: "123456789",
isDate: ISODate("2024-01-01"),
format: "OFD",
metadata: {
sName: "xxx",
bName: "yyy",
aot: 1000.00,
taot: 100.00,
sId: "00000001",
bId: "00000002",
items: [
{ name: "xxxxx", quantity: 1, pe: 111.00 }
]
},
fileRef: "oss://bucket/abc123.ofd",
status: "verified",
createdAt: ISODate("2024-01-01T10:00:00Z"),
updatedAt: ISODate("2024-01-01T10:00:00Z")
}-
GridFS 大文件存储:
对于需要直接存储的PDF/OFD文件,可使用GridFS分块存储。
// GridFS 文件存储示例
const bucket = new GridFSBucket(db, {
bucketName: 'isc'
});
// 上传文件
const uploadStream = bucket.openUploadStream('abcd123.ofd');
fs.createReadStream('./abcd123.ofd').pipe(uploadStream);
// 下载文件
const downloadStream = bucket.openDownloadStream(fileId);
downloadStream.pipe(fs.createWriteStream('./downloaded.abcd123.ofd'));-
多模态数据索引优化策略
针对不同数据类型的索引策略实践:
1. XML格式数据索引优化
// 创建XML关键字段复合索引
db.ics.createIndex({
"xmlMetadata.sTId": 1,
"xmlMetadata.bTId": 1,
"xmlMetadata.isDate": -1
}, {
name: "xml_tx_date_idx",
background: true
});
// XML数据查询示例
db.ics.find({
"xmlMetadata.sTId": "00000001",
"xmlMetadata.iseDate": {
$gte: ISODate("2024-01-01"),
$lte: ISODate("2024-03-31")
}
}).sort({"xmlMetadata.isDate": -1});2. OFD格式数据索引优化
// 创建OFD文本索引
db.ics.createIndex({
"ofdMetadata.sName": "text",
"ofdMetadata.bName": "text",
"ofdMetadata.notes": "text"
}, {
name: "ofd_tx_search_idx",
weights: {
"ofdMetadata.sName": 10,
"ofdMetadata.bName": 8,
"ofdMetadata.notes": 5
},
default_language: "chinese"
});
// 文本搜索示例
db.ics.find({
$text: {
$search: "xxxxxx",
$language: "chinese"
}
}, {
score: { $meta: "textScore" }
}).sort({ score: { $meta: "textScore" } });3. PDF格式数据索引优化
// 创建多键索引处理数组字段
db.ics.createIndex({
"pdfMetadata.items.name": 1,
"pdfMetadata.totalAot": -1
}, {
name: "pdf_items_amount_idx"
});
// 创建部分索引优化高频查询
db.ics.createIndex({
"pdfMetadata.icType": 1,
"pdfMetadata.isDate": -1
}, {
name: "pdf_type_date_idx",
partialFilterExpression: {
"pdfMetadata.icType": { $in: ["xxxxx", "xxxx"] }
}
});
// 多键索引查询示例
db.ics.find({
"pdfMetadata.items.name": "xxxx",
"pdfMetadata.totalAot": { $gt: 10 }
});4. 时序数据索引优化
// 创建TTL索引自动清理过期数据
db.audit_logs.createIndex(
{ "createdAt": 1 },
{
name: "audit_ttl_idx",
expireAfterSeconds: 365 * 24 * 60 * 60 // 1年过期
}
);
// 时序集合优化(MongoDB 5.0+)
db.createCollection("ice_metrics", {
timeseries: {
timeField: "timestamp",
metaField: "metadata",
granularity: "hours"
}
});5. 模糊匹配与多关键字查询
// 多条件模糊匹配查询
db.ics.aggregate([
{
$match: {
$or: [
{ "sName": { $regex: "abcd", $options: "i" } },
{ "bName": { $regex: "abcd", $options: "i" } },
{ "notes": { $regex: "bcd.*ccd", $options: "i" } }
],
"status": { $in: ["verified", "pid"] },
"amount": { $gte: 111, $lte: 555 }
}
},
{
$lookup: {
from: "es",
localField: "sTId",
foreignField: "TId",
as: "sInfo"
}
},
{
$lookup: {
from: "es",
localField: "bTId",
foreignField: "TId",
as: "bInfo"
}
},
{
$unwind: {
path: "$sInfo",
preserveNullAndEmptyArrays: true
}
},
{
$unwind: {
path: "$bInfo",
preserveNullAndEmptyArrays: true
}
},
{
$project: {
icCode: 1,
amount: 1,
isDate: 1,
sName: "$sInfo.name",
bName: "$bInfo.name",
sRegion: "$sInfo.region",
bRegion: "$bInfo.region"
}
},
{ $sort: { "isDate": -1, "aot": -1 } },
{ $limit: 100 }
]);6. 时序数据分析查询
// 复杂时序关联分析
db.ics.aggregate([
{
$match: {
"isDate": {
$gte: ISODate("2024-01-01T00:00:00Z"),
$lt: ISODate("2024-04-01T00:00:00Z")
},
"status": "completed"
}
},
{
$lookup: {
from: "es",
localField: "sTId",
foreignField: "TId",
as: "s"
}
},
{
$lookup: {
from: "is",
localField: "s.iyCode",
foreignField: "code",
as: "iy"
}
},
{ $unwind: "$s" },
{ $unwind: "$iy" },
{
$group: {
_id: {
year: { $year: "$isDate" },
month: { $month: "$isDate" },
iy: "$iy.name",
ren: "$s.ren"
},
totalics: { $sum: 1 },
totalaot: { $sum: "$aot" },
avgaot: { $avg: "$aot" },
maxaot: { $max: "$aot" }
}
},
{
$match: {
"totalaot": { $gt: 111 }
}
},
{
$project: {
period: {
$concat: [
{ $toString: "$_id.year" },
"-",
{ $toString: "$_id.month" }
]
},
iy: "$_id.iy",
ren: "$_id.ren",
totalics: 1,
totalaot: 1,
avgaot: { $round: ["$avgaot", 2] },
maxaot: 1,
_id: 0
}
},
{ $sort: { "period": 1, "totalaot": -1 } }
]);7.索引优化最佳实践总结:
*针对不同数据格式创建专用索引(XML、OFD、PDF)
*使用复合索引优化多字段查询条件
*利用部分索引减少索引大小,提升性能
*对文本搜索字段创建文本索引
*使用时序集合和TTL索引优化时间序列数据
*监控索引使用情况,定期优化索引策略五、MongoDB数据与AI的辅助联动
// 创建向量索引
db.ics.createIndex({
"contentVector": "vector"
}, {
"name": "ic_vector_idx",
"similarity": "cosine",
"dimensions": 1536 // OpenAI Embedding维度
});
// 向量相似度搜索
db.ics.aggregate([
{
$vectorSearch: {
index: "ic_vector_idx",
path: "contentVector",
queryVector: [0.1, 0.2, ...], // 查询向量
limit: 10,
numCandidates: 100
}
}
])六、总结
MongoDB 凭借 JSON 文档模型、GridFS 大文件分片、8.0 向量搜索及原生 LangChain 集成,为“智存”提供了“多模态存储—高并发处理—语义检索—智能问答”一站式技术栈,落地了“数据治理工作应当围绕业务需求展开,并以业务流程架构作为核心设计依据”的中心思想。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)