AI代理的“大脑”与“双手”:Skill Creator框架能否完全取代领域知识图谱?
知识图谱(Knowledge Graph, KG)的核心思想,是将信息从非结构化的文本或孤立的数据表中,转化为一个由实体(Entities)和关系(Relations)构成的、语义丰富的网络。它关注的不是零散的数据点,而是这些数据点之间“是什么”以及“如何关联”。这是一种声明式知识(Declarative Knowledge)的表达方式,即陈述关于世界的事实。知识图谱的核心组成要素实体 (Enti
引言:AI代理的“大脑”与“双手”之辩
随着大型语言模型(LLM)驱动的AI代理从技术演示走向企业核心流程,一个关键的架构问题摆在了所有开发者和架构师面前:我们应如何为这些强大的通用模型,赋予完成特定、复杂任务所需的专业领域知识?长久以来,我们依赖两种主流范式来增强AI的能力:以知识图谱为代表的结构化知识(Structured Knowledge)和以工具调用(Tool Use)为核心的程序化技能(Procedural Skills)。
前者,领域知识图谱,如同为AI构建一个精密、严谨的“大脑”,使其能够理解实体、关系和领域内的复杂规则,从而进行深刻的推理和查询。后者,以Anthropic的Skill Creator框架为代表,则像是为AI装配一双灵巧的“双手”,使其能够遵循指令、使用工具、与外部世界交互,从而执行具体的工作流。
这自然引出了一个核心问题:当Skill Creator框架变得足够强大,能够通过references文件存储信息、通过scripts执行复杂逻辑时,它是否能够完全取代领域知识图谱的核心功能?
本文将深入探讨这一问题。我们将通过详尽的对比分析、清晰的实训案例,以及一个前所未有的融合架构演示,最终揭示——真正的答案并非“二选一”的替代,而在于构建一个“大脑”与“双手”协同工作的、更高维度的智能范体。我们的核心论点是:Skill Creator框架和领域知识图谱并非竞争者,而是强大的协同伙伴。知识图谱提供AI深刻的、结构化的理解力,而技能则赋予AI行动和执行程序的能力。下一代高级AI代理的未来,在于它们的无缝集成。
第一部分:深度剖析领域知识图谱——构建AI的认知基石
要理解两种技术的界限与协同,我们必须首先从第一性原理出发,深入剖析各自的本质。
什么是知识图谱?(“是什么”)
知识图谱(Knowledge Graph, KG)的核心思想,是将信息从非结构化的文本或孤立的数据表中,转化为一个由实体(Entities)和关系(Relations)构成的、语义丰富的网络。它关注的不是零散的数据点,而是这些数据点之间 “是什么” 以及 “如何关联”。这是一种 声明式知识(Declarative Knowledge) 的表达方式,即陈述关于世界的事实。
知识图谱的核心组成要素:
- 实体 (Entities/Nodes):代表现实世界中的独立事物,如一个人、一个项目、一家公司或一种技术。
- 关系 (Relations/Edges):连接两个实体的边,描述它们之间的特定联系,如“管理”、“属于”、“依赖于”。
- 属性 (Properties):附着在实体或关系上的键值对,用于提供更详细的信息,如一个员工的“职位”或一个项目的“预算”。
通过这种方式,知识图谱将领域知识编码成一个机器可读、可推理的结构。它不再是一个简单的数据库,而是一个能够让AI“理解”领域上下文的认知基础。
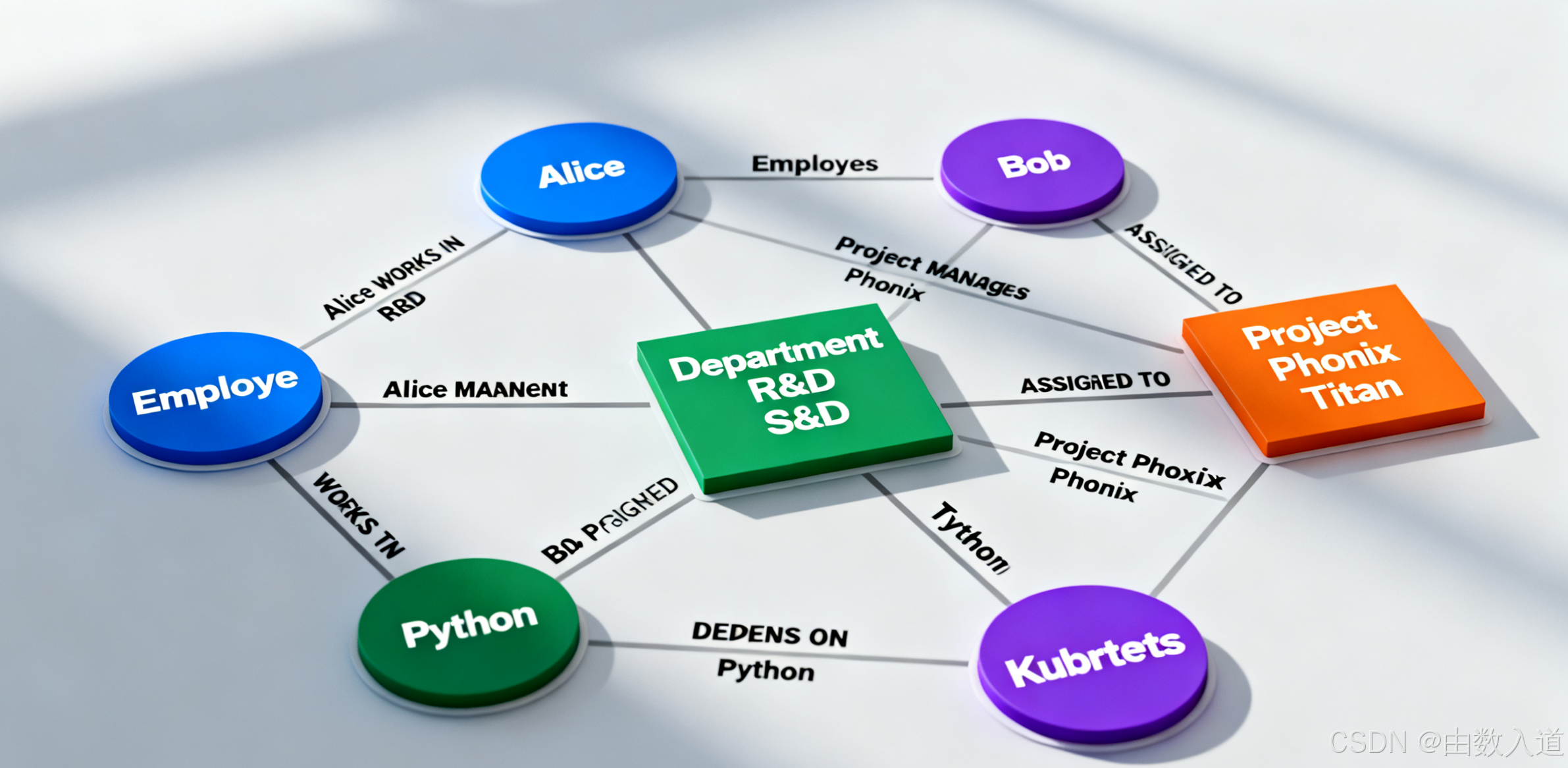
实训案例1A: 构建一个“企业组织与项目”知识图谱
为了让概念更具体,我们来构想一个简化的企业内部知识图谱,用于管理人员、部门和项目之间的关系。
1. 定义实体类型 (Nodes):
Employee: 员工 (e.g., Alice, Bob)Department: 部门 (e.g., R&D, Sales)Project: 项目 (e.g., Project Phoenix, Project Titan)Technology: 技术栈 (e.g., Python, Kubernetes)
2. 定义关系类型 (Edges):
WORKS_IN: 员工 -> 部门 (e.g., AliceWORKS_INR&D)MANAGES: 员工 -> 项目 (e.g., AliceMANAGESProject Phoenix)ASSIGNED_TO: 员工 -> 项目 (e.g., BobASSIGNED_TOProject Phoenix)DEPENDS_ON: 项目 -> 技术 (e.g., Project PhoenixDEPENDS_ONPython)
3. 知识图谱的核心能力:复杂查询与推理
这个知识图谱的真正威力在于回答那些传统数据库难以处理的复杂、多跳(multi-hop)问题:
- 简单查询:“Project Phoenix的负责人是谁?” (Alice)
- 多跳查询:“找出所有由研发部(R&D)员工管理的项目。” (需要从
Department: R&D出发,找到所有WORKS_IN的Employee,再找到这些Employee所MANAGES的Project。) - 推理查询:“Alice的同事(同在R&D部门的员工)参与了哪些项目?”
知识图谱的本质,是为AI提供一个可以进行深度探索和逻辑推理的、关于领域事实的“世界模型”。
第二部分:深度剖析Skill Creator框架——赋予AI行动的力量
与知识图谱的“是什么”哲学相对,Skill Creator框架体现的是一种“怎么做”的哲学。
什么是技能?(“怎么做”)
技能(Skill)的核心,是为AI提供程序化知识(Procedural Knowledge)——即完成一项任务所需的步骤、流程和工具使用方法。它不关心存储世界上所有的事实,而关心如何利用已有信息和外部工具去实现一个特定的目标。
技能的核心组成要素:
SKILL.md(总指挥):这是技能的“大脑”,用Markdown编写,包含了触发条件、核心工作流指令,以及如何协调使用其他资源。scripts/(双手):可执行的脚本(如Python),用于完成确定性的、重复性的任务,如API调用、数据计算、文件操作。references/(参考手册):静态文档(如Markdown文件),为AI提供执行任务时需要参考的背景知识、规范或数据模式。assets/(物料库):用于最终输出的模板或资源文件,如报告模板、图片、代码样板。
技能的本质,是将一个复杂的人类工作流,解构成一个AI可以理解并自主执行的、包含工具和指南的软件包。
实训案例1B: 构建一个“项目管理助手”技能
我们重温之前创建的“项目管理助手”技能,以突出其程序化特性。
技能的目录结构:
project-manager-assistant/
├── SKILL.md
├── scripts/
│ ├── create_task.py
│ └── generate_report.py
├── references/
│ ├── project_schema.md
│ └── policies.md
└── assets/
└── report_template.md
技能的核心能力:执行工作流
当用户说:“帮我为‘Project Phoenix’项目创建一个高优先级的任务,内容是‘修复登录模块Bug’”,AI的行为模式与知识图谱完全不同:
- 触发技能:AI的
description匹配机制激活了project-manager-assistant技能。 - 遵循指令:AI加载
SKILL.md,阅读到“创建新任务”部分,得知需要调用scripts/create_task.py脚本。 - 参数提取:AI从用户请求中提取参数:
project_name='Project Phoenix',priority='High',task_name='修复登录模块Bug'。 - 调用工具:AI执行
create_task.py脚本,并传入参数。该脚本可能内部会调用Jira或Asana的API。 - 反馈结果:AI将脚本的成功或失败结果反馈给用户。
请注意,该技能本身并不存储所有项目的历史数据。它只知道如何去操作项目管理系统。这就是“是什么”与“怎么做”的根本区别。
第三部分:正面交锋——Skill Creator与知识图谱的全面对比
现在,我们可以将两种技术范式并列,进行一次深入的、多维度的比较。
| 特性维度 | 领域知识图谱 (Domain Knowledge Graph) | 扩展技能 (Extended Skill) |
|---|---|---|
| 知识类型 | 声明式 (Declarative):关于事实、实体和关系的知识。核心是“是什么”。 | 程序化 (Procedural):关于流程、步骤和如何使用工具的知识。核心是“怎么做”。 |
| 核心目的 | 理解与查询 (Understanding & Querying):让AI理解领域概念,回答复杂问题,建立世界模型。 | 行动与执行 (Action & Execution):让AI能够完成特定领域的任务,与外部世界交互。 |
| 数据结构 | 图结构 (Graph-based):由节点、边和属性构成,为复杂关系推理和高效查询而优化。 | 文件结构 (File-based):由SKILL.md、脚本、参考文档和资产构成,为模块化和工作流编排而设计。 |
| 交互方式 | AI通过查询语言(如SPARQL, Cypher)或自然语言转查询来检索和推理信息。 | AI遵循SKILL.md中的指令来调用工具和使用资源,是一种指令驱动的执行模式。 |
| 动态性 | 结构相对静态,但数据可更新。主要反映世界的当前状态,是被动的信息源。 | 高度动态,通过调用脚本和API与外部世界进行实时交互,能够改变世界的状态。 |
| 典型应用场景 | 智能问答、推荐系统、风险控制网络、数据血缘分析、语义搜索。 | 自动化工作流、代码生成与调试、报告撰写、与第三方软件(如CRM, ERP)集成。 |
第四部分:功能重叠区——技能在何处“模拟”知识图谱?
尽管两者哲学迥异,但在实践中,一个设计精良的技能确实可以在一定程度上“模拟”知识图谱的部分功能,这正是“技能能否替代知识图谱”这一问题的根源。
references/作为“微型知识库”
在“项目管理助手”技能中,references/project_schema.md文件定义了任务(Task)对象的结构、字段和允许值。references/policies.md文件则定义了公司的项目管理规则。
当AI需要决策时,例如用户想将一个任务的状态设置为“等待中”,AI可以查阅project_schema.md,发现“等待中”并非一个允许的status值,从而向用户指出错误。在这个场景下,references/目录中的Markdown文件,就扮演了一个小型的、基于文本的、声明式的知识库角色。它回答了“一个任务应该是什么样的?”以及“我们的规则是什么?”这类问题。
scripts/作为“硬编码推理引擎”
一个脚本可以内嵌复杂的业务逻辑。假设我们有一个assign_task.py脚本,它内部的逻辑可能是:
- 检查任务的优先级。
- 如果优先级为“高”,则从“高级工程师”池中分配。
- 检查候选工程师的当前负载。
- 分配给负载最低的高级工程师。
当AI调用这个脚本时,它实际上是在执行一个预先编写好的推理链。这个推理过程在知识图谱中可能通过一系列规则(Rules)或复杂的图查询来实现。因此,脚本在功能上可以替代部分硬编码的、确定性的推理任务。
局限性分析
这种“模拟”方式虽然轻量且易于实现,但其局限性也十分明显:
- 可扩展性差:当实体和规则数量急剧增加时,维护大量的Markdown文件和硬编码的脚本将成为一场噩梦。
- 查询效率低:在大型
references/文件中查找信息依赖于文本搜索,效率远低于图数据库的索引查询。 - 缺乏灵活性:无法处理非预定义的、探索性的查询。所有“推理”路径都必须预先在脚本中写死。
第五部分:不可逾越的鸿沟——知识图谱的核心价值
现在,我们来探讨那些技能框架在设计上就无法替代的知识图谱核心功能。
1. 复杂的语义关系推理
这是知识图谱最核心的护城河。让我们回到案例1A的“企业组织与项目”知识图谱。现在,CEO提出了一个极其复杂的战略问题:
“找出所有由销售部(Sales)员工管理、但技术上依赖于至少一种目前只有研发部(R&D)员工掌握的技术(Technology)的关键项目(Project)。”
要回答这个问题,需要执行一个包含多层关系、过滤和聚合的复杂图遍历:
- 从
Department: Sales出发,找到所有WORKS_IN的Employee。 - 找到这些
Employee所MANAGES的Project集合(集合A)。 - 从
Department: R&D出发,找到所有WORKS_IN的Employee。 - 找到这些
Employee所HAS_SKILL的Technology集合(集合B)。 - 找出
Project集合A中,每个项目DEPENDS_ON的Technology。 - 检查这些
Technology是否存在于Technology集合B中,且不被其他部门员工掌握。 - 返回符合条件的
Project。
这种查询对于图数据库来说是原生操作,但对于一个技能来说,几乎是不可能完成的任务。它需要读取和交叉引用大量references/文件,执行多次、低效的文本匹配,逻辑复杂到无法在SKILL.md中有效编排。
2. 大规模结构化数据的高效查询
知识图谱通常构建在专业的图数据库(如Neo4j, NebulaGraph)之上,这些数据库为处理数十亿级别的节点和边进行了深度优化。对大规模图数据进行毫秒级的关联查询是其核心能力。
而技能的references/目录本质上是文件系统。当知识库达到数百万条记录时(例如,一个包含所有产品、零件、供应商和客户的知识库),通过文本搜索来回答“哪些供应商提供了用于我们最畅销产品的、且评分低于4星的零件?”这类问题,在性能上是完全不可接受的。
3. 知识发现与探索
知识图谱不仅能回答已知问题,还能帮助发现未知的模式。数据科学家可以在知识图谱上运行社区发现、中心性分析等算法,来找出“组织中非正式的关键影响人物”或“项目中隐藏的技术依赖风险”。
而技能是目标驱动的。它的设计初衷是高效地完成一个已知的工作流,而不是在一个庞大的知识网络中进行开放式的探索和发现。
第六部分:终极融合——构建“大脑”与“双手”协同的AI代理
我们已经论证了“替代”是不可行的。那么,正确的道路是什么?答案是融合。让我们通过一个详尽的实训案例,来展示一个集成了“大脑”(知识图谱)和“双手”(技能)的AI代理是如何工作的。
实训案例2: 构建“战略风险分析”混合技能
1. 场景定义
一位金融分析师向AI代理提出请求:“请为我们的VIP客户‘FutureTech Inc.’准备一份战略风险评估报告。我需要了解他们的核心业务、主要竞争对手,并结合最新的市场动态,评估他们面临的主要风险。”
2. “大脑”组件:客户端与市场知识图谱
我们预先构建了一个知识图谱,包含以下实体和关系:
- 实体:
Client,Industry,Competitor,MarketTrend,RiskFactor - 关系:
OPERATES_IN(Client -> Industry),COMPETES_WITH(Client -> Competitor),AFFECTED_BY(Industry -> MarketTrend),ASSOCIATED_WITH(MarketTrend -> RiskFactor)

3. “双手”组件:“战略风险分析”技能
我们为此任务创建一个专门的技能,其目录结构如下:
strategic-risk-analyzer/
├── SKILL.md
├── scripts/
│ ├── query_client_kg.py
│ └── fetch_market_news.py
├── references/
│ └── risk_assessment_framework.md
└── assets/
└── risk_report_template.docx
query_client_kg.py: 一个Python脚本,接收一个类Cypher的查询语句,并从我们的知识图谱中返回JSON结果。fetch_market_news.py: 一个模拟脚本,接收行业名称,调用外部新闻API,返回最新的市场新闻标题和摘要。risk_assessment_framework.md: 一份参考文档,定义了如何根据新闻内容和风险因子对风险进行分类和评级(例如,技术风险、市场风险、供应链风险;高、中、低)。risk_report_template.docx: 一个预设格式的Word文档模板。
4. SKILL.md作为总指挥
这是整个协同工作的核心蓝图。AI将严格遵循此文件中的指令。
---
name: strategic-risk-analyzer
description: This skill assesses strategic risks for a given client by querying an internal knowledge graph, fetching external market news, and generating a structured report based on a defined framework. Use when a user requests a risk assessment for a specific company.
---
# 战略风险分析工作流
要为客户生成一份战略风险报告,请严格按以下步骤顺序执行。
## 步骤 1: 从知识图谱中获取基础信息 (理解“是什么”)
**目标**: 识别客户的核心业务、行业和已知竞争对手。
1. 从用户请求中提取客户名称 (e.g., "FutureTech Inc.")。
2. 构造一个知识图谱查询,以获取该客户所在的行业和其所有竞争对手。
* **查询示例**: `MATCH (c:Client {name: "$client_name"})-[:OPERATES_IN]->(i:Industry) MATCH (c)-[:COMPETES_WITH]->(comp:Competitor) RETURN i.name, collect(comp.name)`
3. 调用 `scripts/query_client_kg.py` 脚本并传入构造的查询。
4. 存储返回的行业名称和竞争对手列表以备后用。
## 步骤 2: 获取外部实时动态 (与世界交互)
**目标**: 收集与客户行业相关的最新市场新闻。
1. 使用上一步获取的行业名称。
2. 调用 `scripts/fetch_market_news.py` 脚本,并传入行业名称。
3. 存储返回的新闻摘要列表。
## 步骤 3: 根据框架进行风险评估 (应用领域知识)
**目标**: 结合新闻和评估框架,识别并评级风险。
1. 加载并仔细阅读 `references/risk_assessment_framework.md` 文件,理解风险的分类标准和评级方法。
2. 遍历步骤2中获取的每一条新闻摘要。
3. **对于每条新闻**,判断其内容与`risk_assessment_framework.md`中定义的哪个风险类别相关(如:供应链、技术变革、法规政策)。
4. 根据新闻的影响程度和框架的指导,为识别出的风险定级(高、中、低)。
## 步骤 4: 生成并格式化报告 (完成任务)
**目标**: 将所有分析结果整合到一份专业的报告中。
1. 将步骤1(客户基础信息)、步骤3(识别出的风险及其评级)的所有信息进行汇总。
2. 使用 `assets/risk_report_template.docx` 作为模板,将汇总的信息填充到对应的章节中。
3. 向用户交付最终生成的Word文档报告。
5. 模拟AI代理的执行流程
- 用户: “请为我们的VIP客户‘FutureTech Inc.’准备一份战略风险评估报告…”
- AI (思考): “请求是风险评估。这完全匹配
strategic-risk-analyzer技能的description。我将激活此技能并遵循SKILL.md的指令。” - AI (执行步骤1): “我需要先了解FutureTech Inc.的基础信息。我将构造查询并调用
query_client_kg.py。”- 调用
scripts/query_client_kg.py… - 返回结果:
{"industry": "AI Chip Manufacturing", "competitors": ["Nvidia", "AMD", "Intel"]}
- 调用
- AI (执行步骤2): “好的,他们在AI芯片制造业。现在我需要获取该行业的最新新闻。我将调用
fetch_market_news.py。”- 调用
scripts/fetch_market_news.py… - 返回结果:
[{"title": "Global Silicon Shortage Worsens...", "summary": "..."}, {"title": "US imposes new export controls on advanced semiconductors...", "summary": "..."}]
- 调用
- AI (执行步骤3): “我获取了新闻。现在我需要评估风险。我将加载
risk_assessment_framework.md来指导我的分析。”- AI阅读参考文件,然后分析新闻…
- AI (思考): “‘硅片短缺’新闻对应框架中的‘供应链风险’,影响巨大,评级为‘高’。‘出口管制’新闻对应‘法规政策风险’,同样评级为‘高’。”
- AI (执行步骤4): “分析完成。现在我将所有信息填入
risk_report_template.docx模板,生成最终报告。” - AI (响应用户): “我已经为您生成了关于FutureTech Inc.的战略风险评估报告。请查收附件。”
这个案例完美地展示了“大脑”与“双手”的协同:知识图谱提供了深刻的、结构化的理解,而技能则提供了执行具体步骤和与外部世界交互的能力。两者缺一不可。
第七部分:架构启示与未来展望
这种融合模型为我们设计未来的AI系统提供了深刻的启示。
- 超越RAG的范式: 简单的检索增强生成(RAG)是从文档库中检索文本片段。而“KG+Skill”的模式是一种更高级的范式,AI检索的不仅是文本,而是结构化的、可推理的知识,并且其后续行动不仅仅是“总结”,而是执行一系列复杂的、与外部工具的交互。
- 企业AI的黄金架构: 对于企业级应用,一个健壮的AI系统应该包含:
- 一个核心知识图谱,作为企业所有关键实体和关系的“单一事实来源”。
- 一个技能库,包含一系列模块化的技能,用于操作内部系统(ERP, CRM)、调用外部API、执行标准业务流程。
- 一个智能代理核心,能够根据用户意图,动态地查询知识图谱并编排技能库中的技能来完成任务。
- 未来展望: 我们可以预见,未来的AI代理将能够动态地将知识图谱的推理结果作为参数传递给技能,甚至能够根据任务的失败反馈,反过来向知识图谱提出问题以寻求更深层次的理解,形成一个完整的“感知-认知-行动-学习”的智能闭环。
结论:超越“替代”思维,拥抱协同智能
让我们回到最初的问题:Skill Creator框架能否完全取代领域知识图谱?
答案是明确的不能。
将两者视为竞争对手,是一种认知上的误区。这如同争论一辆汽车的引擎和轮子哪个更重要。引擎(知识图谱)提供动力和方向(理解与推理),而轮子(技能)则负责将动力转化为在真实世界中的行动(执行与交互)。
- 知识图谱是AI代理的“大脑”,它提供了深厚的领域背景知识、复杂的逻辑推理能力和对世界结构化的理解。
- 技能是AI代理的“双手”,它提供了执行具体任务、遵循流程、与数字和物理世界互动的能力。
真正的挑战和机遇,不在于用一种技术替代另一种,而在于如何设计出能够让“大脑”和“双手”无缝协同的智能系统。本文所展示的“战略风险分析”混合技能案例,仅仅是这种协同智能的冰山一角。
作为AI架构师和开发者,我们的任务是停止“替代”思维,开始拥抱“协同”设计。我们需要成为知识的建模者,也需要成为流程的编排者。只有这样,我们才能构建出真正能够理解复杂世界、并能在其中高效行动的下一代AI代理,最终释放人工智能的全部潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)