DA论文笔记(1)Diffusion Domain Teacher: Diffusion Guided Domain Adaptive Object Detector
最近在缓慢地看DA(领域自适应)的论文,打算边看边做一点笔记,主要按论文的顺序进行阅读,可能包括原文的部分翻译、理解和自己的搜索。
00 文献信息
- 作者: Boyong He, Yuxiang Ji, Zhuoyue Tan, Liaoni Wu
- 发表年份: 2024
- 论文标题: Diffusion Domain Teacher: Diffusion Guided Domain Adaptive Object Detector (扩散域教师:扩散引导的域自适应目标检测器)
- 期刊/会议名称: Proceedings of the 32nd ACM International Conference on Multimedia (MM '24)
- 卷号/期号: N/A (会议论文集)
- 10 pages
- DOI号: https://doi.org/10.1145/3664647.3680962
01 abstract 摘要
Object detectors often suffer a decrease in performance due to the large domain gap between the training data (source domain) and real-world data (target domain). Diffusion-based generative models have shown remarkable abilities in generating high-quality and diverse images, suggesting their potential for extracting valuable features from various domains.
由于训练数据(源域)和真实世界数据(目标域)之间的域差距很大,对象检测器的性能经常下降。基于扩散的生成模型在生成高质量和多样化图像方面表现出卓越的能力,表明它们具有从各个领域提取有价值特征的潜力。
这里是简单提到DA研究价值+扩散模型对DA是有用的。
To effectively leverage the crossdomain feature representation of diffusion models, in this paper, we train a detector with frozen-weight diffusion model on the source domain, then employ it as a teacher model to generate pseudo labels on the unlabeled target domain, which are used to guide the supervised learning of the student model on the target domain. We refer to this approach as Diffusion Domain Teacher (DDT).
为了有效利用扩散模型的跨域特征表示,本文在源域上训练了一个具有冻结权重扩散模型的检测器,然后将其作为教师模型,在未标记的目标域上生成伪标签,用于指导学生模型在目标域上的监督学习。我们将这种方法称为扩散域教师 (DDT)。
这里是说明本篇论文的具体方法/思想,摘要后面部分就是在多个数据集上进行实验。并通过广泛实验,说明这个方法的有效性。
这里可以思考:教师模型提出来的特征维度表示和学生模式的特征维度是一样的吗,不一样的话,怎么处理;如何衡量伪标签的有效性;教师模型是如何进行扩散等等。
注意缩写:Diffusion Domain Teacher (DDT)
发现该在论文keywords部分,这篇论文有两个部分:
发现,这是CCS Concepts是ACM出版物特有的要求,不是一个所有学术领域通用的标准。
02 introduction 引言
Object detection is a fundamental task in computer vision, with its applications permeating an array of real-world scenarios. There have been impressive strides and significant achievements in object detection, leveraging both Convolutional Neural Networks (CNNs) [18, 42, 53, 65] and transformer-based models [4, 85].
这里提到,利用卷积神经网络(CNN)和基于Transformer的模型,在目标检测方面取得了令人瞩目的进步和重大成就。
Nonetheless, these data-driven detection algorithms wrestle with the challenging issue of domain shift: the large gap between the training data (source domain) and the testing environments (target domain) frequently results in a substantial decline in detection accuracy.
尽管如此,这些数据驱动的检测算法仍在努力解决具有挑战性的领域偏移问题:训练数据(源域)和测试环境(目标域)之间的巨大差距经常导致检测准确性大幅下降。
这里相当于将CNN和基于transformer的模型定义为“数据驱动的检测算法”,思考一下扩散师生模型是“数据驱动”吗?(应该也算是吧)
Unsupervised Domain Adaptation (UDA) methodologies have surged to the forefront of research, taking advantage of the sparse labeled data from the source domain in conjunction with copious unlabeled data from the target domain to significantly enhance cross-domain detection performance.
无监督域自适应(UDA)方法已经跃居研究前沿,利用源域的稀疏标记数据与目标域的大量未标记数据相结合,显着增强了跨域检测性能。
注意缩写:Unsupervised Domain Adaptation (UDA)
Current UDA tactics have explored a variety of strategies including domain classifiers [10, 25, 59, 81, 84], graph matching [36, 38, 39], domain randomization [32], image-to-image translation [26], and self-training frameworks [6, 14, 41, 56]. These techniques have been crucial in achieving notable advancements in cross-domain object detection.
当前的UDA策略已经探索了多种策略,包括领域分类器、图匹配、领域随机化、图像到图像转换和自训练框架。
这里是提到了很多种策略
后面文中提到了扩散模型,但是其分布推理过程比较慢,无法满足目标检测的即使处理的需求。但是还缺乏将扩散模型应用于跨域检测的研究。
Specifically, we draw inspiration from previous state-of-theart (SOTA) approaches [3, 14, 41] and adopt the Mean Teacher [64] self-training framework, where the teacher model generates pseudo labels for the supervised learning of student model on the target domain.
采用Mean Teacher自我训练框架,其中教师模型为目标域上的学生模型的监督学习生成伪标签。
特别需要注意,这里提到的平均教师模型,并不是教师模型!
一点搜索:
为什么要设置平均教师,而不是学生模型的结果就是预期呢?理由是这样的:
This consistency-based self-training approach allows the student model to progressively learn from the target domain, thereby improving the performance of the detector in cross-domain detection.
这种基于一致性的自训练方法允许学生模型从目标域中逐步学习,从而提高检测器在跨域检测中的性能。
In our approach, we freeze all parameters of the diffusion model and extract intermediate feature from the upsampling structure of the U-Net [55] architecture during the inversion process. These features are then passed through a bottle-neck structure to generate hierarchical features similar to a general backbone for downstream detection tasks.
在我们的方法中,我们冻结了扩散模型的所有参数,并在反演过程中从U-Net 架构的上采样结构中提取中间特征。然后,这些特征通过瓶颈结构传递,以生成类似于下游检测任务的通用主干网的分层特征。
这里又开始讲解论文的方法,冻结了教师模型的参数,如何通过上采样结构中提取中间特征呢?
后文又提到扩散模型是一个高度通用的特征提取器–跨域领域好、推理速度慢。
The contributions of this paper can be summarized as follows:
• We introduce a frozen-weight diffusion model as backbone, which efficiently extracts highly generalized and discriminative feature for cross-domain object detection. Notably, the diffusion-based detector, trained exclusively on the source domain, demonstrates exceptional performance when applied to the target domain.
• We incorporate the diffusion detector as a teacher model within the self-training framework, providing valuable guidance supervised learning of the student model on the target domain. This integration effectively enhances cross-domain detection performance without any increasing of inference time.
• We achieve substantial improvements in cross-domain detection. Our method achieves an average mAP improvement of 21.2% compared with the baseline, and surpassing the current SOTA methods by 5.7% mAP. Further experiments demonstrate that the diffusion domain teacher consistently enhances cross-domain performance for detectors with stronger backbones, leading to superior results in the target domain.
总结本文的贡献:
- 我们引入了冻结权重扩散模型作为骨干,该模型有效地提取了高度广义和判别性的特征,用于跨域目标检测。值得注意的是,基于扩散的检测器专门在源域上训练,在应用于目标域时表现出卓越的性能。
- 我们将扩散检测器作为教师模型纳入自训练框架中,为目标领域上的学生模型提供有价值的指导监督学习。这种集成有效地增强了跨域检测性能,而不会增加任何推理时间。
- (实验提升的效果)
03 related work
3.1 object detection
目标检测相关方法介绍;
3.2 Domain adaptation Detection
DA的相关方法介绍;
3.3 Diffusion Models
扩散模型的基本的基本介绍。
04 approach 方法
First, in Sec. 3.1, we review the formulation of Unsupervised Domain Adaptation Detection (UDAD). Then, in Sec. 3.2, we provide a detailed description of how the frozen-weight diffusion model serves as a feature extractor, producing hierarchical features, to adapt to the detection task. Furthermore, in Sec. 3.3, we explain the application of the diffusion teacher detector in thr self-training framework, where pseudo labels generated on the unlabeled target domain guide the supervised learning of the student model. Finally, we summarize the total training objective.
首先,在第 3.1 节中,我们回顾了无监督域适应检测 (UDAD) 的公式。然后,在第 3.2 节中,我们详细描述了冻结权重扩散模型如何充当特征提取器,生成分层特征,以适应检测任务。此外,在第 3.3 节中,我们解释了扩散教师检测器在THR自训练框架中的应用,其中在未标记的目标域上生成的伪标签指导学生模型的监督学习。最后,我们总结了总体培训目标。
这里,先介绍了本部分的主要内容。
4.1 Formulation of Unsupervised Domain adaptation Detection

上面是原文,但是这部分看内容,更像是背景、基本概念的解释。
4.2 Fozen-Diffusion Feature Extractor
During training, gaussian noise of varying magnitudes is added to the clean training data, commonly referred to as diffusion process.
在训练过程中,不同幅度的高斯噪声被添加到干净的训练数据中,通常称为扩散过程。
X0是原图像,Xt是加了噪声的图像: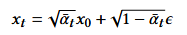
符号的解释说明:
这部分结束后,提到fig2: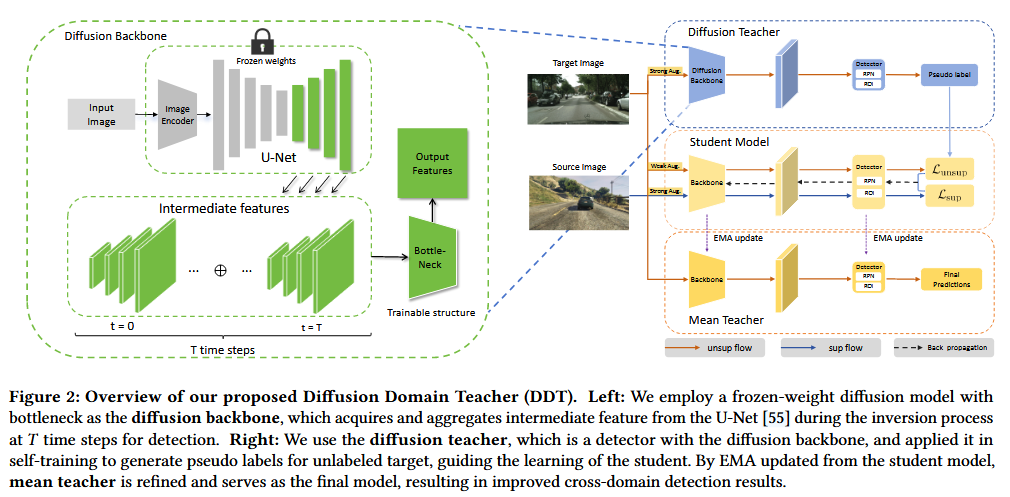
对图片的理解:


学生模型的两条线路需要注意。
4.3 Diffusion Teacher Guided Self-training Framework
We introduce a hyperparameter σ as a threshold for the confidence scores of the output for the teacher model, enabling us to select more reliable pseudo labels.
我们引入了一个超参数σ作为教师模型输出置信度分数的阈值,使我们能够选择更可靠的伪标签。

这是关于学生模型的公式。基本思路是先先划分区域(RPN),再进行回归或分类任务(ROI);学生模型有分为在源域上的监督,和在伪标签上的非监督。

接着对学生模型进行平滑处理,得到平均教师模型(感觉交平均学生模型会更为恰当)。

这是完整的损失函数(后续的改进可能从损失函数入手?)
In our DDT framework, following [41], we employ Weak Augmentation to provide target domain images to the diffusion teacher model for generating reliable and accurate pseudo labels. Simultaneously, we apply Strong Augmentation to the images as inputs to the student model, as illustrated in Fig. 2. Specifically, Weak Augmentation includes random crop and random horizontal flip, while Strong Augmentation involves color transformations such as color space conversion, contrast adjustment, equalization, sharpness enhancement, and posterization, as well as spatial transformations such as rotation, shear, and translation of the position.
在我们的DDT框架中,继[41]之后,我们采用弱增强为扩散教师模型提供目标域图像,以生成可靠和准确的伪标签。同时,我们将强增强应用于图像,作为学生模型的输入,如图2所示。具体来说,弱增强包括随机裁剪和随机水平翻转,而强增强则涉及色彩空间转换、对比度调整、均衡、锐度增强和平估等颜色变换,以及位置的旋转、剪切和平移等空间变换。
这里可以思考为什么这样进行操作:教师模型是弱增强,学生模型是用的强增强呢?
这部分我也也进行了询问,这是回答:


05 Experiments
5.1 Datasets
Cityscapes. Cityscapes [12] dataset provides a diverse of urban scenes from 50 cities. It includes 2,975 training images and 500 validation images with detailed annotations. The dataset covers 8 detection categories, using bounding boxes sourced from instance segmentation.
BDD100K. BDD100K [73] dataset is a comprehensive collection of 100,000 images specifically designed for autonomous driving applications. The dataset offers detailed detection annotations with 10 categories.
Sim10K. Sim10k [30] is a synthetic dataset comprising 10,000 rendered images simulated within the Grand Theft Auto gaming engine, specifically designed to facilitate the training and evaluation of object detection algorithms in autonomous driving systems.
VOC. VOC [16] is a general-purpose object detection dataset that includes bounding box and class annotations for common objects across 20 categories from the real world. Following [41], we combined the PASCAL VOC 2007 and 2012 editions, resulting in a total of 16,551 images.
Clipart. Clipart [28] dataset comprises 1,000 clipart images across the same 20 categories as the VOC dataset, exhibiting significant differences from real-world images. Following [41], we utilize 500 images each for training and testing purposes.
Comic. Comic [28] dataset consists of 2,000 comic-style images, featuring 6 categories shared with the VOC dataset. Following [29], we allocate 1,000 images each for training and testing.
Watercolor. Watercolor [28] dataset contains 2,000 images in a watercolor painting style, with 6 categories shared with the VOC dataset. Following [41], we use 1,000 images for both training and testing.
这里是说明了所使用的数据集。
5.2 Cross-domian Detection Settings
Cross-Camera. We train on Cityscapes [12] (source domain) and validate on BDD100K [73] (target domain) to evaluate the cross-camera detection performance in diverse weather and scene conditions. We focus on the 7 same categories as SWDA [59].
跨摄像机。我们在Cityscapes[12](源域)上进行训练,并在BDD100K[73](目标域)上进行验证,以评估跨摄像机在不同天气和场景条件下的检测性能。我们关注与SWDA相同的7个类别[59]。
Synthetic to Real (Syn2Real). We train on Sim10K (source domain) and validate on Cityscapes [12] and BDD100K [73] (target domian)to validate the performance of synthetic-to-real detection. Following SWDA [59], we focus on the shared category car.
合成到实数 (Syn2Real)。我们在Sim10K(源域)上进行训练,并在Cityscapes [12]和BDD100K[73](目标domian)上进行验证,以验证合成到真实检测的性能。继SWDA [59]之后,我们重点关注共享类别汽车。
Real to Artistic. We train on the VOC [16] (source domain) and perform validation on the Clipart [28], Comic [28], and Watercolor [28] (target domains) to assess cross-domain detection performance from real-world images to artistic styles. Referring to AT [41] and D-ADAPT [29], we respectively apply the 20, 6, and 6 shared categories between VOC and each of the Clipart, Comic, and Watercolor.
从真实到艺术。我们在VOC [16](源域)上进行训练,并在剪贴画[28]、漫画[28]和水彩[28](目标域)上进行验证,以评估从真实世界图像到艺术风格的跨域检测性能。参考AT [41]和D-ADAPT [29],我们分别应用了VOC与剪贴画、漫画和水彩画之间的20、6和6个共享类别。
这三种跨域场景,是Domain Adaptation(DA)领域公认的、用来衡量模型泛化能力的“标准考题”。
这样设计的目的是为了全面且有针对性地评测一个DA模型的能力。它模拟了现实世界中三种最典型、难度各不相同的“域偏移”(Domain Shift)问题。(这点还蛮有趣的,相当于说明设计也是多维度、全面的)
搜索后进行了详细的回答:

5.3 Implementation Details

说明的是其他细节和超参数的设置。
5.4 Results and Comparisons
The baseline refers to the results that only train on the source domain and test on the target domain.
然后进行了一些实验结果对比
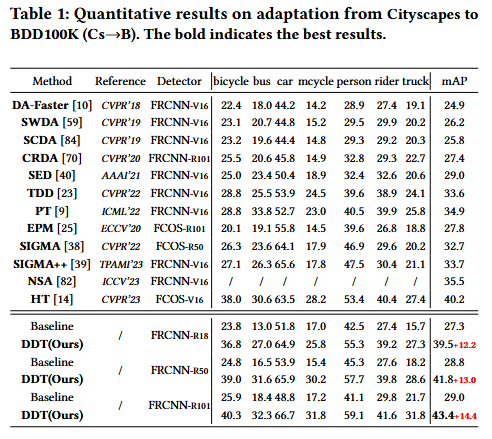
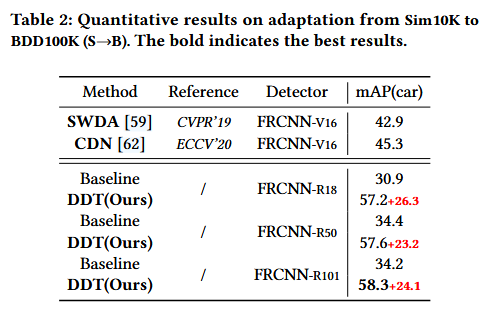
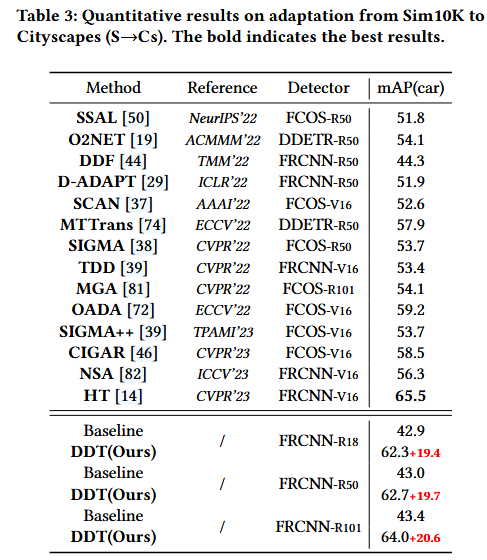
接下来的table 4-6 也展示了在不同数据库之前的对比。
5.5 Ablation Studies
We conduct additional experiments to analyze the feature representation capabilities of different models. Specifically, we compared our diffusion model with powerful backbones, including ConvNext [48], Swin Transformer [47], VIT [15], as well as the self-supervised method MAE [21], pretrained on ImageNet [57].
我们进行了额外的实验来分析不同模型的特征表示能力。具体来说,我们将我们的扩散模型与强大的主干网进行了比较,包括ConvNext [48]、Swin Transformer [47]、VIT [15],以及在ImageNet上预训练的自监督方法MAE [21][57]。
Additionally, GLIP [33], which is pretrained on a larger dataset and has shown promising performance on object detection benchmarks. Our objective is to investigate two questions: (1) Will the diffusion model offer better intra-domain and crossdomain feature representation?
(2) Will the diffusion model serve as a better teacher?
此外,GLIP [33]在更大的数据集上进行了预训练,在目标检测基准测试中显示出良好的性能。我们的目标是研究两个问题:(1)扩散模型是否会提供更好的域内和跨域特征表示?
(2)扩散模型会成为更好的老师吗?
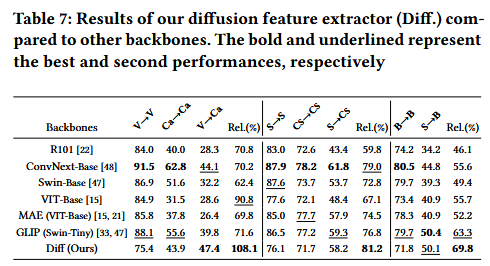
不同backbone,比较其在域内和不同域的效果情况。
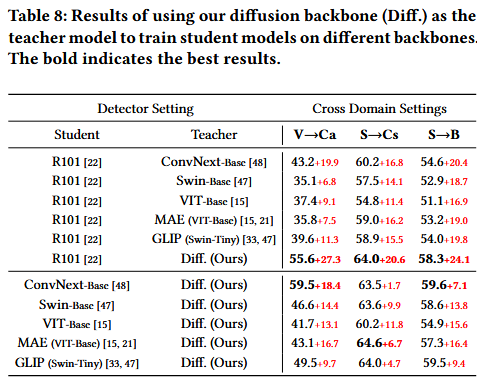
依旧,控制变量,进行比较
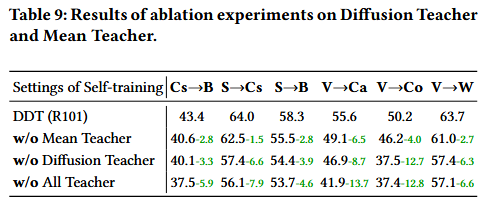
这个表格,表示的是逐渐去掉某个部分后的效果。
5.6 Analysis
略
06 Conclusion
略

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)