进阶 LangGraph:记忆管理、人类监督与多智能体协作实战
本文深入探讨LangGraph智能体的四大进阶能力:1)短期记忆实现会话上下文连贯;2)长期记忆支持用户数据持久化;3)人类监督机制确保敏感操作安全;4)多智能体协作系统处理复杂任务。通过酒店预订审核、用户信息查询等实战案例,展示了如何应用InMemorySaver存储会话状态、interrupt()实现人工干预、协调者模式分配多智能体任务。这些能力是构建生产级AI系统的关键要素,可应用于智能客服
在上一篇博客中,我们掌握了 LangGraph 单智能体的基础开发与工具集成能力。但在实际场景中,智能体还需具备 “记住上下文”“接受人工干预”“与其他智能体协作” 等高级能力。本文将通过四个实战案例,带你深入 LangGraph 的核心进阶特性,从单智能体的记忆优化,到多智能体的协同工作,完整覆盖复杂 AI 系统的开发要点。
一、智能体的 “记忆力”:短期与长期记忆的实现
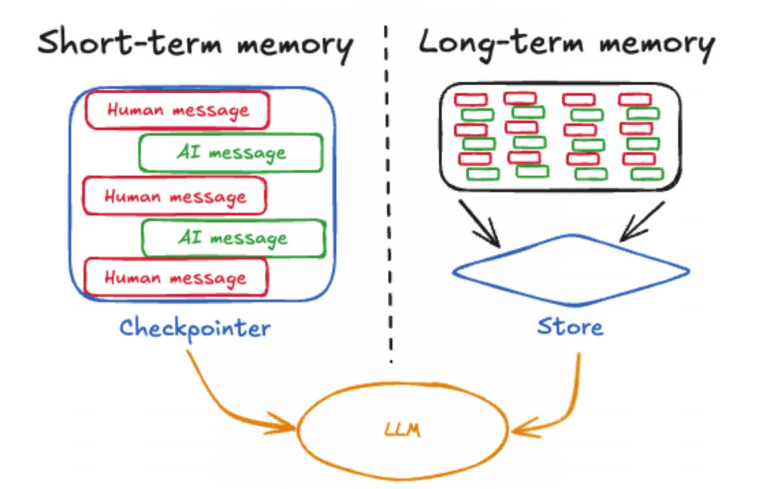
多轮对话中,智能体若无法记住历史交互,会导致回答断裂(比如用户问 “那北京呢?”,智能体却不知道 “那” 指的是天气查询)。LangGraph 将记忆分为短期记忆(会话内上下文)和长期记忆(用户 / 应用级持久化数据),两者分工明确,共同保障对话连贯性。
1. 案例 1:短期记忆(会话内上下文)
短期记忆适用于 “当前对话中的历史信息保存”,比如多轮对话的上下文衔接。LangGraph 通过InMemorySaver实现短期记忆,配合thread_id区分不同会话,避免记忆混淆。
实现代码:
from langchain_deepseek import ChatDeepSeek
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent
# 1. 定义工具(查询天气,模拟实际功能)
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
return f"城市:{city},天气一直都是晴天!"
# 2. 创建短期记忆实例(保存会话内上下文)
checkpointer = InMemorySaver()
# 3. 初始化大模型
llm = ChatDeepSeek(
model="deepseek-chat",
api_key="your-api-key", # 替换为你的API密钥
temperature=0.7,
timeout=60,
max_retries=2
)
# 4. 创建带短期记忆的智能体
agent = create_agent(
model=llm,
tools=[get_weather],
checkpointer=checkpointer, # 启用短期记忆
system_prompt="你是乐于助人的助手,能根据上下文理解用户后续提问。"
)
# 5. 配置会话参数:用固定thread_id绑定会话(同一thread_id共享记忆)
config = {
"configurable": {
"thread_id": "session_001" # 不同会话用不同ID,避免记忆串用
}
}
# 6. 多轮对话测试
# 第一轮:查询冒泡排序(工具未触发,直接回答)
first_response = agent.invoke(
{"messages": [{"role": "user", "content": "使用python帮我实现一个冒泡排序算法"}]},
config
)
print("第一轮回答:", first_response["messages"][-1].content)
# 第二轮:追问Java实现(智能体通过短期记忆理解“Java怎么实现”指的是冒泡排序)
second_response = agent.invoke(
{"messages": [{"role": "user", "content": "java怎么实现?"}]},
config
)
print("第二轮回答:", second_response["messages"][-1].content)
关键要点:
InMemorySaver:默认将记忆保存在内存中,程序结束后会清除,适合测试或短期会话;生产环境可替换为 Redis、SQLite 等外部存储(需自定义BaseCheckpointSaver子类)。thread_id:核心参数,用于区分不同用户 / 不同会话的记忆,比如 “session_001” 对应用户 A 的会话,“session_002” 对应用户 B 的会话,避免记忆混淆。
2. 案例 2:长期记忆(用户 / 应用级持久化)
短期记忆仅能保存会话内数据,若需长期存储用户信息(如姓名、偏好)或应用数据(如订单记录),需用到长期记忆。LangGraph 通过InMemoryStore(测试用)或外部数据库实现,配合namespace区分数据类型,支持跨会话数据共享。
实现代码:
from langchain.agents import create_agent
from langchain_core.runnables import RunnableConfig
from langchain_deepseek import ChatDeepSeek
from langgraph.config import get_store
from langgraph.store.memory import InMemoryStore
from langchain_core.tools import tool
# 1. 初始化长期存储(保存用户级数据,测试用InMemoryStore,生产用数据库)
long_term_store = InMemoryStore()
# 2. 预存测试数据:namespace=("users",) 表示“用户数据”类型,key=user_id
long_term_store.put(
namespace=("users",), # 命名空间:区分“用户数据”“订单数据”等
key="user_123", # 数据唯一标识(如用户ID)
value={"name": "张三", "age": "40"} # 存储的用户信息
)
# 3. 定义工具:从长期存储中查询用户信息
@tool(return_direct=True)
def get_user_info(config: RunnableConfig) -> str:
"""根据用户ID从长期存储中查询用户信息"""
# 获取长期存储实例
store = get_store()
# 从配置中提取用户ID(跨节点传递参数)
user_id = config["configurable"].get("user_id")
# 查询数据:指定namespace和key
user_data = store.get(namespace=("users",), key=user_id)
# 返回结果(处理数据不存在的情况)
return str(user_data.value) if user_data else "未找到该用户信息"
# 4. 初始化大模型与智能体
llm = ChatDeepSeek(
model="deepseek-chat",
api_key="your-api-key",
temperature=0.7,
timeout=60,
max_retries=2
)
agent = create_agent(
model=llm,
tools=[get_user_info],
store=long_term_store, # 配置长期存储
system_prompt="你是用户信息查询助手,调用get_user_info工具获取用户数据。"
)
# 5. 调用智能体:传入用户ID(通过config传递)
result = agent.invoke(
input={"messages": [{"role": "user", "content": "查找用户信息"}]},
config={"configurable": {"user_id": "user_123"}} # 指定要查询的用户ID
)
# 打印结果
print("用户信息查询结果:", result["messages"][-1].content)

关键要点:
namespace:类似数据库的 “表”,用于分类存储不同类型的数据(如 “users” 存用户信息,“orders” 存订单信息),避免数据混乱。get_store():在工具内部获取全局存储实例,支持读写操作,实现 “智能体 - 存储 - 工具” 的数据流通。- 持久化扩展:生产环境中,
InMemoryStore可替换为基于 Redis 的RedisStore或基于 SQL 的存储(需自定义实现BaseStore接口),确保数据跨服务、跨会话共享。
二、人类监督(Human-in-the-loop):敏感操作的人工干预
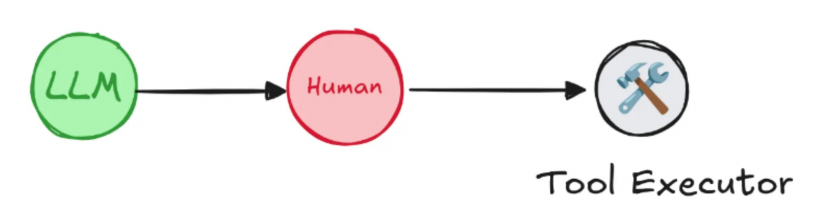
智能体自主调用工具时,可能出现误操作(如误订高价酒店、错误调用支付接口)。LangGraph 的人类监督功能允许在关键步骤中断智能体,等待人工确认或修改参数后再继续执行,大幅提升系统安全性。
案例 3:酒店预订的人工审核
以 “酒店预订” 为例,智能体在执行预订前需暂停,等待用户确认酒店名称是否正确,支持 “同意(OK)” 或 “修改(edit)” 操作,避免错误预订。
实现代码:
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
from langchain_core.tools import tool
# 1. 定义带人工审核的敏感工具(酒店预订)
@tool(return_direct=True)
def book_hotel(hotel_name: str):
"""预订酒店,需人工审核后执行"""
# 中断智能体,等待人工输入(OK=同意,edit=修改酒店名称)
human_response = interrupt(
f"正准备预订酒店:{hotel_name},请确认:\n"
"选择'OK'同意预订,或选择'edit'修改酒店名称(需传入新的hotel_name)。"
)
# 根据人工反馈处理
if human_response["type"] == "OK":
# 人工同意,执行预订
return f"成功在 {hotel_name} 预订了一个房间。"
elif human_response["type"] == "edit":
# 人工修改,使用新的酒店名称
new_hotel = human_response["args"]["hotel_name"]
return f"已修改酒店为 {new_hotel},并成功预订。"
else:
raise ValueError(f"无效的反馈类型:{human_response['type']}")
# 2. 初始化短期记忆(保存会话状态,支持中断后恢复)
checkpointer = InMemorySaver()
# 3. 初始化大模型与智能体
llm = ChatDeepSeek(
model="deepseek-chat",
api_key="your-api-key",
temperature=0.7,
timeout=60,
max_retries=2
)
agent = create_agent(
model=llm,
tools=[book_hotel],
checkpointer=checkpointer, # 支持中断后恢复会话
system_prompt="你是酒店预订助手,执行预订前必须通过人工审核。"
)
# 4. 配置会话参数
config = {"configurable": {"thread_id": "booking_001"}}
# 5. 流式调用智能体(支持中断与人工反馈)
print("=== 第一步:触发预订请求 ===")
# 第一次调用:智能体中断,等待人工反馈
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "帮我在图灵宾馆预定一个房间"}]},
config
):
print(chunk)
# 6. 人工反馈:修改酒店名称为“三号宾馆”(通过Command恢复会话)
print("\n=== 第二步:人工反馈(修改酒店) ===")
for chunk in agent.stream(
Command(resume={"type": "edit", "args": {"hotel_name": "三号宾馆"}}), # 人工修改指令
config
):
print(chunk)
# 打印最终预订结果
if "messages" in chunk:
print("最终结果:", chunk["messages"][-1].content)
关键要点:
interrupt():工具内部调用,中断智能体执行,生成包含 “确认选项” 的反馈,等待人工输入。Command(resume=...):人工反馈的载体,支持 “OK”(同意)和 “edit”(修改参数),实现 “中断 - 反馈 - 恢复” 的完整流程。- 适用场景:敏感操作(支付、预订、数据修改)、高风险工具调用(如 API 删除操作),确保智能体行为可控。
三、多智能体协作:分工明确的 “AI 团队”
单个智能体难以处理复杂多任务(如 “预订航班 + 预订酒店”),LangGraph 支持构建多智能体系统:通过 “协调者(Coordinator)” 拆分任务,分配给不同专业智能体(如航班助理、酒店助理),实现 “分工协作”。
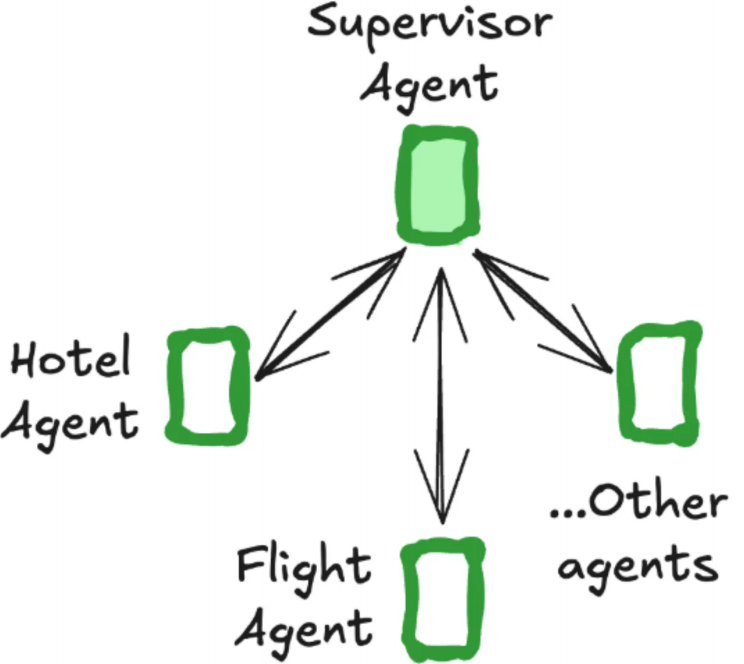
案例 4:航班 + 酒店预订的多智能体系统
构建一个包含 “协调者”“航班预订助理”“酒店预订助理” 的多智能体系统,协调者负责分析用户请求、分配任务,专业助理负责具体执行,最终汇总结果。
实现代码:
from langchain.agents import create_agent
from langchain_deepseek import ChatDeepSeek
from langchain_core.messages import HumanMessage
import json
# 1. 定义工具:航班预订与酒店预订
def book_flight(from_airport: str, to_airport: str) -> str:
"""预订航班(从出发机场到目的机场)"""
return f"成功预订了从 {from_airport} 到 {to_airport} 的航班。"
def book_hotel(hotel_name: str) -> str:
"""预订酒店"""
return f"成功预订入住 {hotel_name}。"
# 2. 初始化大模型
llm = ChatDeepSeek(
model="deepseek-chat",
api_key="your-api-key",
temperature=0.7,
timeout=60,
max_retries=2
)
# 3. 创建专业智能体(分工明确)
# 航班预订助理:仅处理航班相关任务
flight_agent = create_agent(
model=llm,
tools=[book_flight],
system_prompt="你是航班预订助理,仅处理航班预订,用户提到'航班''机场'等关键词时调用book_flight工具。",
name="flight_assistant"
)
# 酒店预订助理:仅处理酒店相关任务
hotel_agent = create_agent(
model=llm,
tools=[book_hotel],
system_prompt="你是酒店预订助理,仅处理酒店预订,用户提到'酒店''住宿'等关键词时调用book_hotel工具。",
name="hotel_assistant"
)
# 4. 创建协调者(任务分析与分配)
class BookingCoordinator:
def __init__(self, flight_agent, hotel_agent, llm):
self.flight_agent = flight_agent # 航班助理
self.hotel_agent = hotel_agent # 酒店助理
self.llm = llm # 用于分析用户请求
def analyze_request(self, user_input):
"""分析用户请求:判断需要预订航班、酒店,或两者都需要"""
analysis_prompt = f"""
分析用户请求:"{user_input}",按以下格式返回JSON:
{{
"need_flight": true/false, # 是否需要航班预订
"need_hotel": true/false, # 是否需要酒店预订
"flight_info": {{"from": "", "to": ""}}, # 航班出发地/目的地
"hotel_info": {{"name": ""}} # 酒店名称
}}
"""
try:
# 调用大模型分析请求
response = self.llm.invoke(analysis_prompt)
return json.loads(response.content)
except:
# 备用方案:关键词匹配(防止大模型解析失败)
need_flight = any(word in user_input for word in ["航班", "机场", "飞往"])
need_hotel = any(word in user_input for word in ["酒店", "住宿", "入住"])
return {
"need_flight": need_flight,
"need_hotel": need_hotel,
"flight_info": {},
"hotel_info": {}
}
def process_request(self, user_input):
"""处理用户请求:分配任务给对应智能体,汇总结果"""
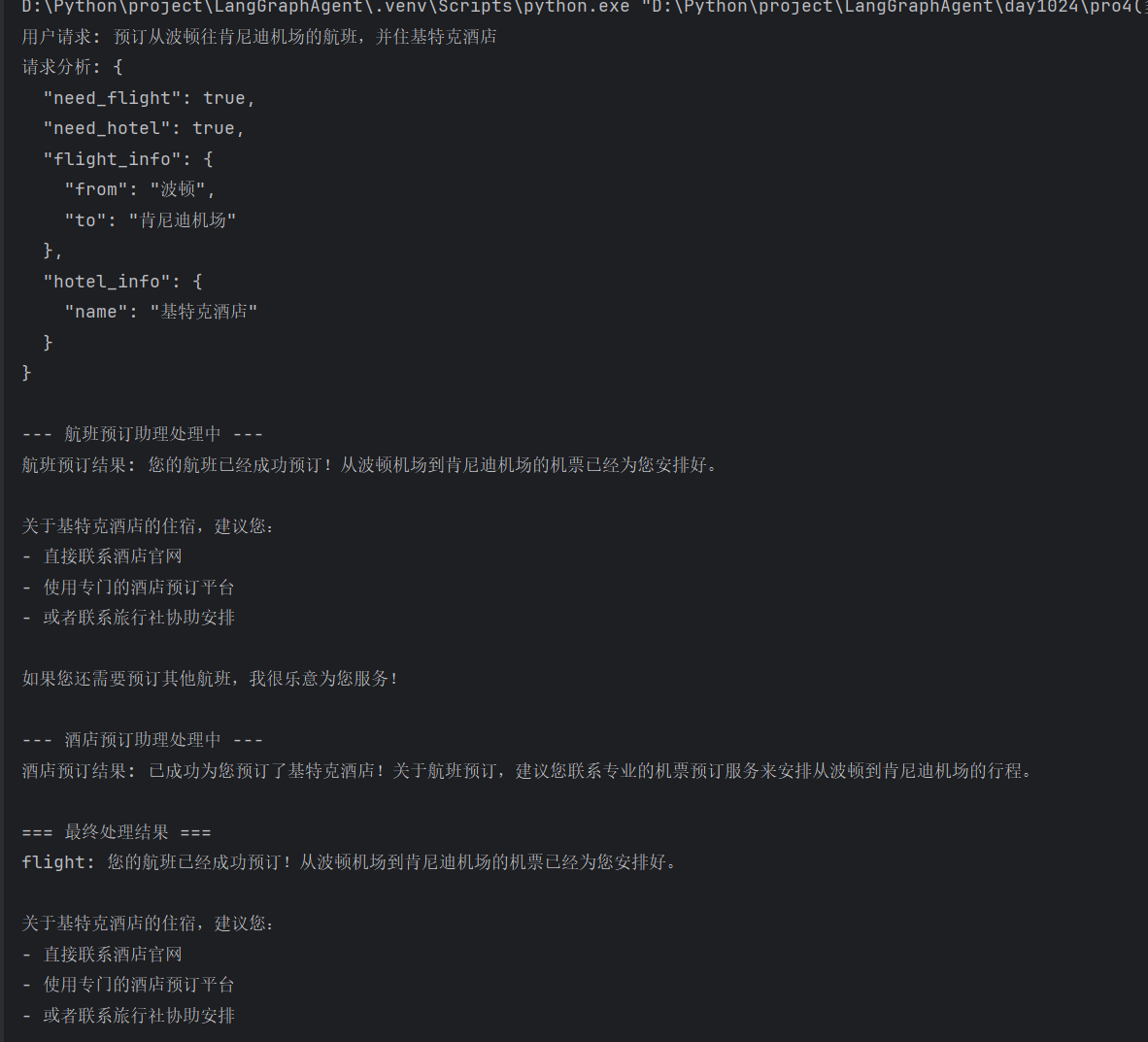
print(f"用户请求:{user_input}\n")
# 1. 分析请求
request_analysis = self.analyze_request(user_input)
print(f"请求分析结果:\n{json.dumps(request_analysis, ensure_ascii=False, indent=2)}\n")
results = {}
# 2. 分配任务给航班助理
if request_analysis["need_flight"]:
print("--- 航班预订助理处理中 ---")
try:
flight_result = self.flight_agent.invoke({
"messages": [HumanMessage(content=user_input)]
})
results["航班预订"] = flight_result["messages"][-1].content
print(f"航班预订结果:{results['航班预订']}\n")
except Exception as e:
results["航班预订"] = f"处理失败:{str(e)}"
# 3. 分配任务给酒店助理
if request_analysis["need_hotel"]:
print("--- 酒店预订助理处理中 ---")
try:
hotel_result = self.hotel_agent.invoke({
"messages": [HumanMessage(content=user_input)]
})
results["酒店预订"] = hotel_result["messages"][-1].content
print(f"酒店预订结果:{results['酒店预订']}\n")
except Exception as e:
results["酒店预订"] = f"处理失败:{str(e)}"
# 4. 汇总最终结果
print("=== 最终处理结果 ===")
for task, result in results.items():
print(f"{task}:{result}")
return results
# 5. 测试多智能体系统
if __name__ == "__main__":
# 创建协调者实例
coordinator = BookingCoordinator(flight_agent, hotel_agent, llm)
# 用户请求:同时预订航班和酒店
user_request = "预订从波士顿飞往肯尼迪机场的航班,并入住麦基特里克酒店"
# 处理请求
coordinator.process_request(user_request)
关键要点:
- 分工明确:专业智能体(航班 / 酒店助理)仅处理单一类型任务,避免 “全能但不精” 的问题,提升任务处理准确性。
- 协调者核心作用:
- 任务分析:通过大模型或关键词匹配,判断用户需求类型(航班 / 酒店 / 两者都要)。
- 任务分配:将不同类型的任务分配给对应专业智能体。
- 结果汇总:收集各智能体的处理结果,统一反馈给用户。
- 扩展性:可新增 “高铁预订助理”“景点门票助理” 等,只需在协调者中添加任务分析逻辑和智能体实例,系统扩展性极强。
四、总结与后续方向
本文通过四个实战案例,覆盖了 LangGraph 智能体的进阶核心能力:短期记忆保障会话连贯性,长期记忆实现数据持久化,人类监督提升系统安全性,多智能体协作处理复杂任务。这些能力是构建生产级 AI 系统的关键,比如:
- 智能客服:短期记忆记住用户对话历史,长期记忆存储用户会员信息,人类监督处理高风险投诉。
- 旅行助手:多智能体协作完成 “航班 + 酒店 + 门票” 一站式预订。
后续可进一步探索的方向:
- 记忆优化:短期记忆的消息压缩(避免历史消息过多导致内存溢出)、长期记忆的检索优化(如基于向量数据库的快速查询)。
- 监督增强:支持多人审核、审核超时自动处理、审核日志记录。
- 多智能体通信:通过 LangGraph 的 “状态共享” 实现智能体间直接数据传递,而非依赖协调者中转。
LangGraph 的优势在于将复杂流程抽象为 “节点 + 边” 的图结构,让开发者无需关注底层流转逻辑,只需聚焦 “智能体该做什么”“如何协作”。掌握这些进阶特性后,你已具备构建复杂 AI 系统的能力,接下来可尝试结合实际业务场景,落地更有价值的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)