Stable Diffusion 短视频制作算力需求与优化策略研究
随着生成式 AI 技术的快速发展,Stable Diffusion 已成为 AIGC 视频制作领域的核心技术平台。然而,视频生成相比静态图像对算力提出了更高要求,算力消耗与硬件成本成为制约技术普及的关键瓶颈。本研究旨在深入分析 Stable Diffusion 在短视频制作场景下的算力需求规律,系统评估不同硬件配置的性能表现,并提供针对性的优化策略,为企业和个人创作者的硬件投资决策提供科学依据。
随着生成式 AI 技术的快速发展,Stable Diffusion 已成为 AIGC 视频制作领域的核心技术平台。然而,视频生成相比静态图像对算力提出了更高要求,算力消耗与硬件成本成为制约技术普及的关键瓶颈。本研究旨在深入分析 Stable Diffusion 在短视频制作场景下的算力需求规律,系统评估不同硬件配置的性能表现,并提供针对性的优化策略,为企业和个人创作者的硬件投资决策提供科学依据。
当前,短视频制作正经历从传统人工创作向 AI 辅助生成的技术变革。2025 年中国娱乐类 AIGC 市场规模预计达到 689 亿元,其中娱乐垂直领域贡献约 275.6 亿元,同比增长超过 80%。在这一背景下,理解 Stable Diffusion 的算力需求特征,掌握有效的优化方法,对于提升创作效率、降低成本具有重要意义。
本研究将从技术架构分析、硬件性能基准测试、优化策略评估、成本效益分析以及行业案例研究五个维度,全面剖析 Stable Diffusion 短视频制作的算力需求问题。

一、技术架构与实现路径分析
1.1 视频生成的核心技术原理
Stable Diffusion 视频生成的核心技术基础是潜空间压缩技术,这一技术实现了计算效率的革命性提升。传统视频渲染需要处理每帧图像的完整 RGB 数据,以 512×512 像素图像为例,数据量达到 786,432 维,而潜空间技术将数据压缩至 16,384 维,压缩比高达 1:64。这种降维处理使得模型能够在消费级 GPU 上实时运算,例如 NVIDIA RTX 40 系列显卡可同时处理 1280×2048 分辨率视频的 4.7 秒片段。
在技术实现层面,模型通过 U-Net 架构在潜空间进行噪声预测与逆向扩散,主要包括三个关键步骤:
1、前向扩散过程:将原始视频帧逐步添加高斯噪声,转化为纯噪声潜空间表示。这一过程为后续的逆向生成奠定了数学基础。
2、逆向扩散过程:根据文本提示词,通过预训练的 CLIP 文本编码器引导噪声去除过程。这是视频生成的核心环节,决定了最终输出的视觉质量和语义准确性。
3、时序一致性维护:采用 3D 卷积核处理帧间运动信息,确保动作连贯性。这一技术创新是区别于静态图像生成的关键特征,通过 3D 卷积和时序注意力层实现时空联合建模。
1.2 主流技术架构对比分析
当前 Stable Diffusion 视频生成领域存在多种技术架构,各有特点和适用场景:
Stable Video Diffusion (SVD) 架构是最具代表性的技术路线之一。SVD 在 Stable Diffusion 2.1 基础上添加了 Video LDM 相同的视频模块,包括 3D 卷积层和时序注意力层。该架构的优势在于能够生成高分辨率视频,支持 576×1024 分辨率,通过微调基础模型可实现高分辨率文生视频、图生视频、视频插帧和多视角生成等多种应用。
AnimateDiff 架构由腾讯 ARC 团队提出,采用插件式设计理念,无需对原始 Stable Diffusion 模型进行完整微调。其核心创新在于引入轻量级 "动态适配器" 模块,嵌入到预训练文本到图像扩散模型的 U-Net 结构中,专门负责建模帧间的时间动态信息。这种设计保持了原有图像生成能力不变的前提下,赋予模型时序建模能力,极大降低了训练成本和资源消耗。
ModelScope 架构由阿里云推出,采用两阶段流水线架构:第一阶段生成关键帧草图与结构布局,第二阶段填充细节并插值中间帧。这种 "分而治之" 的生成哲学模仿人类创作思维,先勾勒轮廓,再细化内容,有效缓解了单一模型同时兼顾语义准确性和运动平滑性的压力。
1.3 逐帧生成与关键帧插值模式对比
在实际应用中,Stable Diffusion 视频生成主要采用两种技术路径:逐帧生成模式和关键帧插值模式,两者在算力消耗和生成质量上存在显著差异。
逐帧生成模式是最直接的实现方式,每帧图像独立生成,具有最高的画质控制精度,但算力消耗极大。以 10 秒 30fps 视频为例,需要生成 300 帧图像,按照单帧生成时间 5-10 秒计算,总耗时可达 25-50 分钟。这种模式适合对画质要求极高的专业场景,但对硬件配置要求苛刻。
关键帧插值模式则采用 "先生成关键帧,再通过插值算法生成中间帧" 的策略。关键帧的密度设置直接影响生成效果和算力消耗:关键帧越密,动作衔接越流畅,但重绘变化越多,容易导致画面闪烁。这种模式通过智能补帧算法,如 RIFE 等,可以实现接近实时的帧插值处理,速度比传统 DAIN 算法快 10-25 倍,显存占用仅为后者的 1/5。
1.4 不同分辨率和帧率的技术要求
视频分辨率和帧率是决定算力需求的两个核心参数,对硬件配置提出了差异化要求:
720P 视频生成:基础配置为 RTX 2060 显卡(6GB 显存),单帧生成耗时约 12 秒,支持 24-30fps 的影视级标准帧率146。这一配置适合入门级用户和小规模项目,能够满足日常短视频制作需求。
1080P 视频生成:推荐配置为 RTX 4070 显卡(12GB 显存),配合 32GB 内存可实现实时预览
英伟达实验室测试显示,采用先进的优化技术处理 1080p 视频时,内存占用较传统方法降低 82%,生成速度提升 30 倍。
4K 视频生成:专业配置需要双 RTX 4090 显卡(48GB 显存)阵列,可处理 4K 视频并支持复杂光影效果
值得注意的是,在生成 4K 分辨率图像时,最新版本的渲染速度较前代提升 60%,GPU 显存占用反而降低 30%,这得益于多级渲染技术的应用。
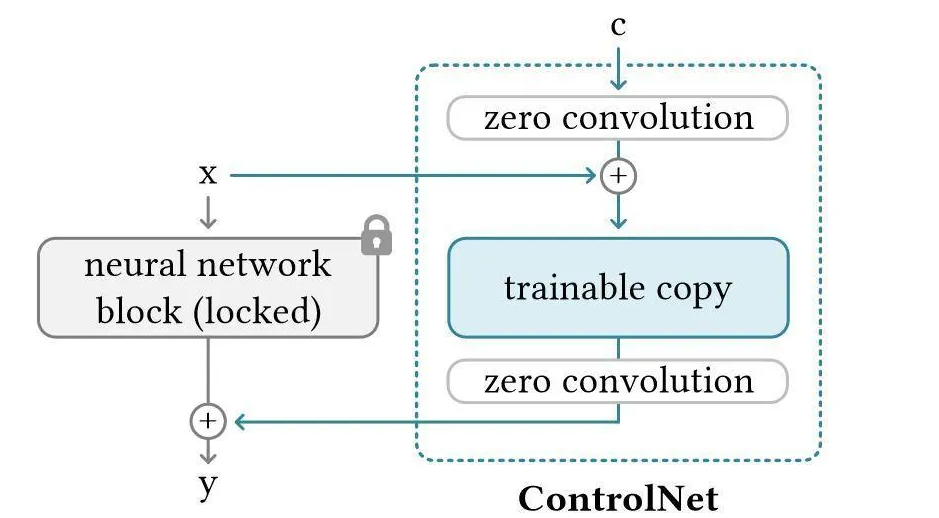
1.5 ControlNet 在视频制作中的应用
ControlNet 作为强大的空间控制工具,在短视频制作中发挥着重要作用。通过 OpenPose 人体姿态估计框架与 Stable Diffusion 深度融合,可以实现精确的姿态控制。ControlNet Pose 模型将骨架特征图与文本嵌入向量在 UNet 的中间层进行交叉归一化(CrossNorm)处理,实现姿态信息对生成过程的精准约束,支持同时输入多个人体姿态参考图像,通过权重分配实现混合姿态控制。
在实际应用中,使用 ControlNet 需要注意算力消耗的增加。基础 ControlNet 叠加(1-2 个)需要 GPU 显存≥12GB(如 RTX 4070 12GB),显存占用比纯生成增加 30%-50%,单张时间延长至 40-80 秒。多 ControlNet 叠加(3-4 个)则需要 GPU 显存≥16GB(如 RTX 4080 16GB),需优化工作流(如分阶段加载模型)以避免显存溢出。
二、硬件性能基准测试与算力量化
2.1 入门级硬件配置性能分析
入门级硬件配置以4-8GB 显存为主要特征,包括 RTX 3050 8GB、RTX 4060 8GB、RTX 3060 等显卡。这类配置的生成速度为 15-30 秒 / 张,支持轻度参数调整。
具体性能表现方面,RTX 3060 在生成 512×512 图像时,50 步采样需要 8.7 秒。在 17 款显卡的横向对比测试中,RTX 3060 每分钟可生成 5.45 张图,约 11 秒 / 张。然而,需要注意的是,RTX 3060 的性能表现相对较弱,在测试中成绩最差,基本只能与 2060 Super 相当。
对于4GB 显存的极限配置,虽然理论上可以运行 Stable Diffusion,但只能生成 512×512 分辨率的基础图像,且生成时间较长。这种配置仅适合学习和实验用途,不适合实际的短视频制作任务。
入门级配置的主要优势在于成本控制,RTX 3060 价格约 3000 元,按 3 年折旧计算月均成本约 83 元,配合每小时 0.15 元的电费,每天生成 200 张图(约 2 小时)月电费仅 9 元。但在实际视频生成任务中,这类配置面临显存不足的严重制约,难以满足连续多帧生成的需求。
2.2 中端级硬件配置性能评估
中端级硬件配置以8-12GB 显存为核心特征,包括 RTX 4070 12GB、RTX 3090 24GB 等显卡。这类配置支持 1024×1024 直接生成,叠加 LoRA 后速度仍能保持在 20-40 秒 / 张。
在实际测试中,中端显卡表现出明显的性能优势。RTX 4070 介于 RTX 3080Ti 和 RTX 3080 之间,RTX 4070Ti 勉强跑赢了 RTX 3090。更重要的是,RTX 4080 Super 配合 TensorRT 加速可提升 50% 性能,这为中端配置提供了进一步优化的可能性。
显存容量对中端配置的影响尤为显著。8GB 显存可生成 1024×1024 图片,而 12GB 显存可支持 1536×1536 分辨率。在 4K 图像生成任务中,12GB 显存可支持 5120×5120 分辨率配合 200 步采样,而 8GB 显存需压缩至 3840×3840 才能避免溢出。实测显示,12GB 显存在 Blender 3.6 的 Cycles 渲染中,显存占用比 8GB 低 22%。
中端配置在短视频制作中的表现可圈可点。RTX 4070 Mobile(8GB)配合 i7-13700H 处理器和 32GB DDR5 内存的移动工作站配置,能够满足移动场景下的视频生成需求。这类配置的性价比优势明显,既能够提供足够的算力支撑,又不会造成过度的成本负担。
2.3 高端级硬件配置性能测试
高端级硬件配置以16-24GB 显存为显著特征,包括 RTX 4090(24GB GDDR6X)、RTX 4080 Super(16GB)等旗舰显卡。这类配置在性能表现上具有压倒性优势。
RTX 4090作为当前消费级显卡的巅峰,配备 24GB GDDR6X 显存,显存位宽 384 位,带宽高达 1TB/s。在实际测试中,RTX 4090 每分钟可生成 19.35 张图,约 3 秒 / 张,出图速度是上代旗舰 3090Ti 的 1.76 倍。RTX 4090 的 CUDA 核心数达到 16,384 个,FP32 算力高达 82.6 TFLOPS,FP16 算力更是达到 165.2 TFLOPS,相比 RTX 3090 的 35.7 TFLOPS 提升了 131%。
RTX 4090 在视频生成任务中展现出卓越的性能。实测显示,在处理 1080P/30fps、60 秒的复杂场景视频时,相比 RTX 3060,渲染时间可缩短 60% 以上。更令人印象深刻的是,RTX 4090 的 24GB GDDR6X 显存可同时处理 4 路 8K 视频流,为超高清视频制作提供了硬件基础。
RTX 4080 Super同样表现出色,在 Stable Diffusion 图像生成任务中,完成 512×512 分辨率图片的速度比 RTX 3080 Ti 快 37%。配合 TensorRT 加速,性能可提升 50%,进一步巩固了其在高端市场的竞争力。
高端配置在专业视频制作中具有不可替代的优势。某团队使用 32-GPU 集群(4 台 HGX H100 服务器,每台 8 个 H100 GPU)进行模型微调,展现了顶级硬件在大规模训练任务中的价值。对于个人创作者而言,RTX 4090 虽然价格较高,但在 24 小时连续出图的场景下,相比入门级显卡每天可多生成 4000 张左右,绝对数量的差距十分显著。
2.4 显存容量对性能的决定性影响
显存容量是影响 Stable Diffusion 视频生成性能的决定性因素,不同容量的显存对应着截然不同的处理能力:
4GB 显存的极限情况只能生成 512×512 分辨率的基础图像,且生成时间较长,基本无法满足视频生成需求。这种配置仅适合简单的图像生成实验,不具备视频制作能力。
8GB 显存是入门级视频生成的标准配置,可生成 1024×1024 图片,支持基础的视频生成任务。但在实际应用中,8GB 显存面临诸多限制,例如在 4K 图像生成时需要压缩至 3840×3840 分辨率以避免溢出。
12GB 显存提供了显著的性能提升,可支持 1536×1536 分辨率,在 4K 图像生成时可支持 5120×5120 分辨率配合 200 步采样。更重要的是,12GB 显存能够流畅完成 20 步迭代,而 8GB 显存会在第 12 步触发 "显存溢出",被迫启用系统内存缓冲,导致生成速度暴跌 60%。
24GB 显存代表了当前的最高水准,如 RTX 4090 配备的 24GB GDDR6X 显存,不仅能够处理 4K 分辨率生成和多模态模型,还支持同时处理 4 路 8K 视频流。在 TensorRT FP8 量化后,显存占用可减少 40% 至 11GB,进一步提升了硬件利用率。
2.5 不同硬件级别的实际应用表现
通过对不同硬件级别的综合测试和分析,可以得出以下关键性能数据:
在Tag 抽卡测试(768×768 分辨率,无 LoRA)中,性能排名为:RTX 4090 > RTX 4080 > RTX 4070Ti ≈ RTX 3090 > RTX 4070 > RTX 3080Ti > RTX 3080。RTX 4090 以每分钟 19.35 张图的速度遥遥领先,而 RTX 3060 表现最差,基本只能与 2060 Super 相当。
在底模 LoRA 高分辨率修复测试(512×768 放大至 1024×1536,叠加多个 LoRA)中,即使强如 RTX 4090,每分钟也只能生成 3.75 张图,约 16 秒 / 张。这表明复杂任务对算力的需求呈指数级增长,对硬件配置提出了更高要求。
在ControlNet Tile 高清细节测试(512×512 修复至 1280×1280)中,RTX 4060 每分钟生成 5.45 张图(11 秒 / 张),而其他显卡表现出细微变化。值得注意的是,RTX 40 系列在这一测试中表现优于前代产品,可能得益于新版 CUDA 深度神经网络库的优化。
这些测试数据表明,硬件性能与实际应用效果之间存在明显的正相关关系。对于短视频制作而言,选择合适的硬件配置需要综合考虑项目需求、预算限制和性能要求等多个因素。
3.5 综合优化策略的成本效益分析
综合运用多种优化策略,可以实现显著的成本效益提升。通过模型量化、xFormers 优化和 LoRA 技术的组合应用,可以在保持生成质量的前提下大幅降低硬件需求和运行成本。
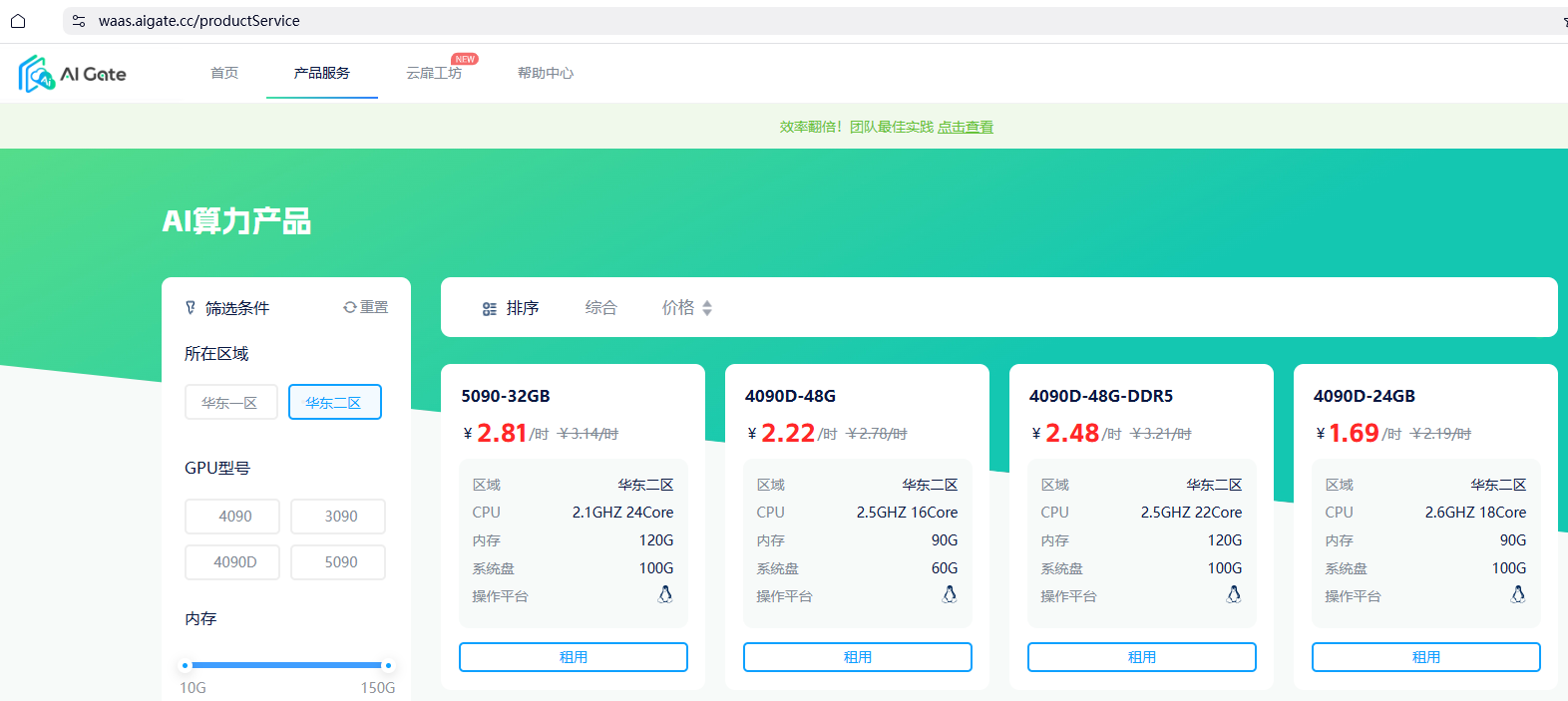
硬件投资成本对比显示,本地部署 Stable Diffusion 的硬件成本为 5000-20000 元(RTX 3060 至 RTX 4090),而云服务租用 8 卡 A100 集群月租金约 1.2 万元。以 RTX 3060 为例,价格约 3000 元,按 3 年折旧计算月均成本约 83 元,这种一次性投资模式相比持续的云服务费用具有明显的成本优势。
运行成本分析表明,电费是主要的持续性支出。GPU 功耗约 350W,月均电费增加 15-30 美元。以每小时 0.15 元电费计算,每天生成 200 张图(约 2 小时)月电费仅 9 元。这种极低的运行成本使得本地部署成为经济实惠的选择。
云服务成本对比显示,不同配置的云服务器价格差异显著:3080 显卡配置 0.48 元 / 小时,4060 配置 0.9 元 / 小时,4090 配置 2.6 元 / 小时。存储成本相对较低,0.01 元 / 10GB / 小时,40GB 存储 24 小时费用 0.98 元。按实际使用计算,512×512 图像生成成本约 0.0002 美元 / 次。
初步实施可使用线上云服务器:如“智算云扉https://waas.aigate.cc/user/charge?channel=W6P9Y2F8H&coupon=3ROAWRGJRH等租赁平台,已经按照应用需求优化好使用环境,支持各类镜像服务,按量计费。
投资回报率分析方面,专业配置如 RTX 4090 在 24 小时连续出图时,相比入门级显卡每天可多生成 4000 张左右。在商业应用中,剪辑效率可提升 300%,单条视频成本降至 2.5 元。某电商团队运用 AI 工作流,将产品图制作成本降低 87%。
这些数据表明,通过合理的优化策略,不仅可以显著降低硬件需求和运行成本,还能获得可观的投资回报。对于不同规模的用户,可以根据实际需求选择合适的优化组合,在成本和性能之间找到最佳平衡点。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)