【工业树莓派CM0 Dev Board】AI视觉应用部署方案:物体识别
本文介绍了树莓派 CM0 Dev Board 的实现 AI 视觉应用方案:物体识别的项目设计,包括准备工作、环境搭建、YOLO 模型、流程图、关键代码以及效果演示等,为相关产品在 AI 视觉领域的开发设计和快速应用提供了参考。
【工业树莓派CM0 Dev Board】AI视觉应用部署方案:物体识别
本文介绍了树莓派 CM0 Dev Board 的实现 AI 视觉应用方案:物体识别的项目设计,包括准备工作、环境搭建、YOLO 模型、流程图、关键代码以及效果演示等。
项目介绍
- 准备工作:包括所需 Python 环境以及软件包的安装部署等;
- ONNX 模型:使用 YOLOv5n 等轻量化 ONNX 模型实现物体识别的板端推理。
ONNX
Open Neural Network Exchange (ONNX) 是一个开放的生态系统,为 AI 开发人员提供支持 随着项目的发展选择正确的工具。

ONNX 为 AI 模型(包括深度学习和传统 ML)提供开源格式。它定义了一个可扩展的计算图模型,以及内置运算符和标准的定义 数据类型。
详见:onnx/onnx: Open standard for machine learning interoperability .
YOLO
YOLO(You Only Look Once)是一种流行的目标检测算法,它以其快速和准确性而闻名。YOLO算法的核心思想是将目标检测问题转化为一个回归问题,通过一个单一的卷积神经网络(CNN)直接从输入图像预测边界框和类别概率。
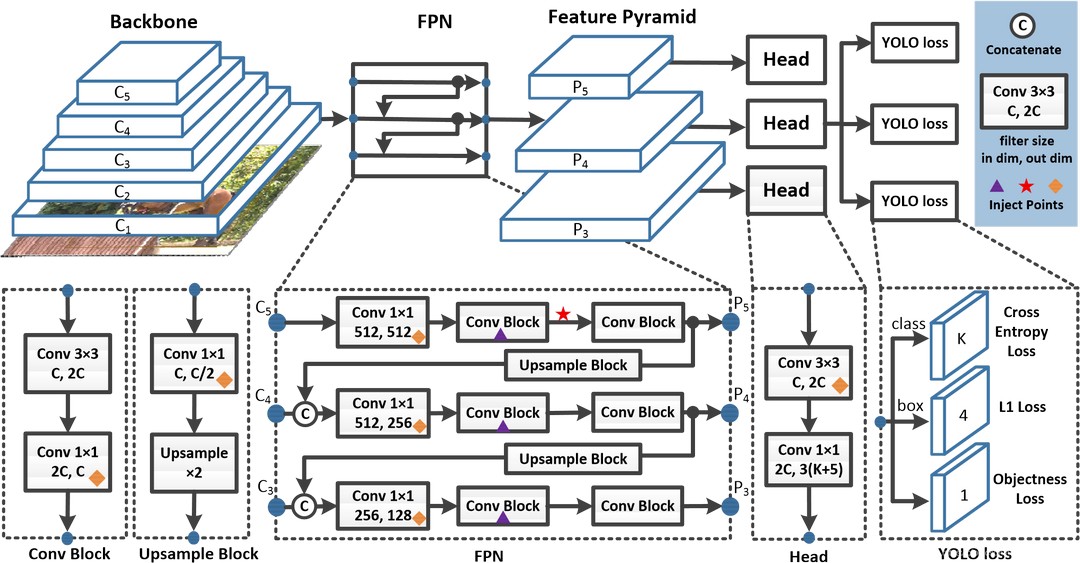
YOLO 的主要优点是速度快,能够实时处理视频流。它还具有较强的通用性,能够迁移到新的领域。
YOLOv5n
YOLOv5n 代表了目标检测方法的进步,源于 Ultralytics 开发的 YOLOv5 模型的基础架构,调整优化了模型架构,从而在目标检测任务中实现了更高的精度-速度权衡。YOLOv5 为那些在研究和实际应用中寻求稳健解决方案的人们提供了高效的解决方案。
准备工作
系统安装及环境搭建详见:【工业树莓派CM0 Dev Board】介绍、镜像烧录、系统测试 .
硬件连接
- 若采用 SSH 远程登录操作,则仅需连接电源供电即可;
- 若采用本地登录,则需连接 HDMI 视频流传输线、USB 键盘连接线等;

库安装
-
执行指令
sudo apt install python3-opencv安装 OpenCV -
安装解析 ONNX 模型所需的 onnxruntime 库,终端执行
sudo apt install python3-pip
sudo pip3 install onnxruntime --break-system-packages
模型下载
- 下载 模型文件至本地
./model文件;
mkdir model
cd model
wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.onnx
详见:【工业树莓派CM0 Dev Board】AI视觉应用部署方案:人脸检测 .
物体识别
采用 YOLOv5n 轻量化的 onnx 模型实现物体识别的本地板端推理,并弹窗显示识别结果。
流程图
代码
执行 touch or_onnx.py 指令新建文件,并使用 nano 文本编辑器添加如下代码
#!/usr/bin/env python3
import cv2, numpy as np, onnxruntime as ort
from pathlib import Path
COCO_NAMES = ["person","bicycle","car","motorcycle","airplane","bus","train","truck","boat","traffic light",
"fire hydrant","stop sign","parking meter","bench","bird","cat","dog","horse","sheep","cow",
"elephant","bear","zebra","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee",
"skis","snowboard","sports ball","kite","baseball bat","baseball glove","skateboard","surfboard",
"tennis racket","bottle","wine glass","cup","fork","knife","spoon","bowl","banana","apple",
"sandwich","orange","broccoli","carrot","hot dog","pizza","donut","cake","chair","couch",
"potted plant","bed","dining table","toilet","tv","laptop","mouse","remote","keyboard","cell phone",
"microwave","oven","toaster","sink","refrigerator","book","clock","vase","scissors","teddy bear",
"hair drier","toothbrush"]
MODEL_PATH = "model/yolov5n.onnx"
IMG_PATH = "img/desktop.jpg"
# ---------- 1. 加载 FP16 模型 ----------
sess = ort.InferenceSession(MODEL_PATH, providers=['CPUExecutionProvider'])
in_name = sess.get_inputs()[0].name # 期望 tensor(float16)
out_name = sess.get_outputs()[0].name
# ---------- 2. 读图 ----------
img0 = cv2.imread(IMG_PATH)
if img0 is None: raise FileNotFoundError(IMG_PATH)
# ---------- 3. 预处理(FP16 + 640×640) ----------
blob = cv2.resize(img0, (640, 640))
blob = (blob.astype(np.float16) / 255.0).transpose(2, 0, 1)[None] # <- 关键:float16
# ---------- 4. 推理 ----------
outputs = sess.run([out_name], {in_name: blob})[0]
outputs = np.squeeze(outputs) # [25200,85]
# ---------- 5. 后处理 + 画框 ----------
boxes, scores, class_ids = [], [], []
for pred in outputs:
x, y, w, h, conf = pred[:5]
if conf < 0.25: continue
cls = int(np.argmax(pred[5:]))
scores.append(float(conf))
class_ids.append(cls)
# 映射回原图
x1 = int((x - w / 2) * img0.shape[1] / 640)
y1 = int((y - h / 2) * img0.shape[0] / 640)
x2 = int((x + w / 2) * img0.shape[1] / 640)
y2 = int((y + h / 2) * img0.shape[0] / 640)
boxes.append([x1, y1, x2 - x1, y2 - y1])
indices = cv2.dnn.NMSBoxes(boxes, scores, score_threshold=0.25, nms_threshold=0.45)
if indices is not None:
for i in indices.flatten():
x, y, w, h = boxes[i]
label = f"{COCO_NAMES[class_ids[i]]} {scores[i]:.2f}"
cv2.rectangle(img0, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(img0, label, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# ---------- 6. 弹窗 ----------
cv2.imshow("YOLOv5n-FP16-ORT", img0)
cv2.waitKey(0)
cv2.destroyAllWindows()
保存代码;
效果
终端执行 python or_onnx.py 弹窗显示物体识别结果;

- 更多应用场景的识别效果如下
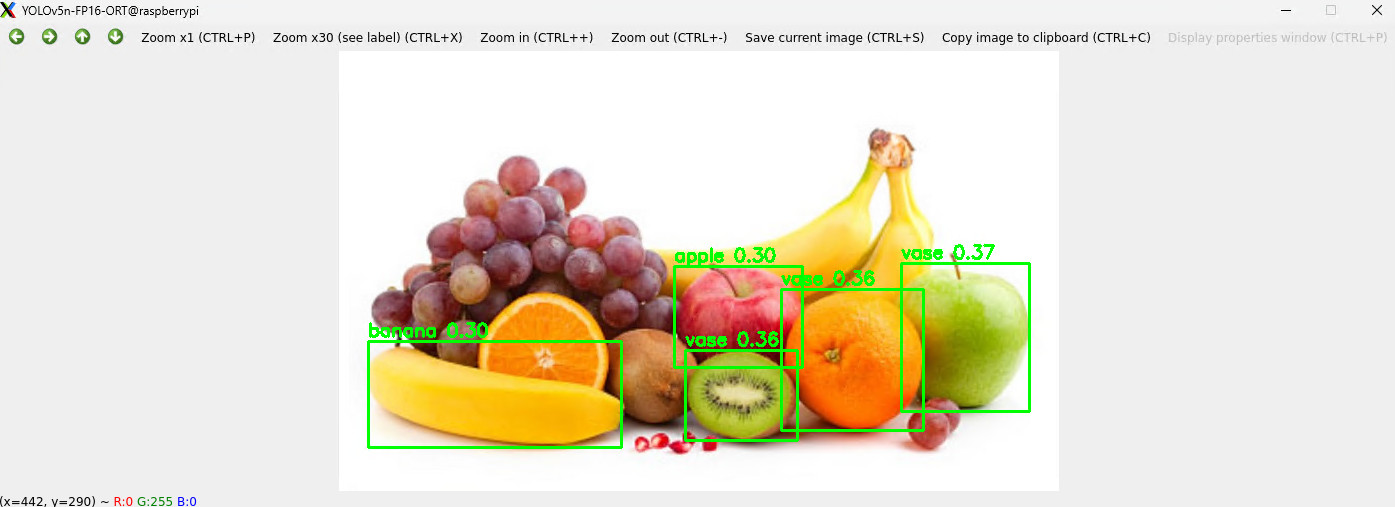
道路

运动

室内

户外

总结
本文介绍了树莓派 CM0 Dev Board 的实现 AI 视觉应用方案:物体识别的项目设计,包括准备工作、环境搭建、YOLO 模型、流程图、关键代码以及效果演示等,为相关产品在 AI 视觉领域的开发设计和快速应用提供了参考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)