以yolov12为例的数据集标注及训练
5.点击左侧change save dir选择保存标注(label)的目录如"F:\yolov12-main\yolov12-main\yolotest\labels"4.点击左侧open dir选择需要标注的图片目录 如"F:\yolov12-main\yolov12-main\yolotest\images"8.通过下面的 split.py,设定图片和标注的目录,以及输出的训练集和val集的目
自定义数据集
标注:
1.在当前yolov12终端下 pip install labelimg ,下载标注工具
2.终端输入 labelimg ,启动标注工具
3.在 view 里面勾选 "auto save model"
4.点击左侧open dir 选择需要标注的图片目录 如"F:\yolov12-main\yolov12-main\yolotest\images"
5.点击左侧change save dir 选择保存标注(label)的目录 如"F:\yolov12-main\yolov12-main\yolotest\labels"
6.点击左侧 create RectBox开始标注
划分:
7.将labels目录下的 classes.txt移动到yolotest目录下,与images和labels平级。
8.通过下面的 split.py,设定图片和标注的目录,以及输出的训练集和val集的目录
import os, shutil
from sklearn.model_selection import train_test_split
val_size = 0.2
postfix = 'jpg'
imgpath = r'F:\yolov12-main\yolov12-main\yolotest\images'
txtpath = r'F:\yolov12-main\yolov12-main\yolotest\labels'
#dataset与images和labels平级目录,会自动创建
output_train_img_folder =r'F:\yolov12-main\yolov12-main\yolotest\dataset1/images/train'
output_val_img_folder = r'F:\yolov12-main\yolov12-main\yolotest\dataset1/images/val'
output_train_txt_folder = r'F:\yolov12-main\yolov12-main\yolotest\dataset1\labels/train'
output_val_txt_folder = r'F:\yolov12-main\yolov12-main\yolotest\dataset1\labels/val'
os.makedirs(output_train_img_folder, exist_ok=True)
os.makedirs(output_val_img_folder, exist_ok=True)
os.makedirs(output_train_txt_folder, exist_ok=True)
os.makedirs(output_val_txt_folder, exist_ok=True)
listdir = [i for i in os.listdir(txtpath) if 'txt' in i]
train, val = train_test_split(listdir, test_size=val_size, shuffle=True, random_state=0)
for i in train:
img_source_path = os.path.join(imgpath, '{}.{}'.format(i[:-4], postfix))
txt_source_path = os.path.join(txtpath, i)
img_destination_path = os.path.join(output_train_img_folder, '{}.{}'.format(i[:-4], postfix))
txt_destination_path = os.path.join(output_train_txt_folder, i)
shutil.copy(img_source_path, img_destination_path)
shutil.copy(txt_source_path, txt_destination_path)
for i in val:
img_source_path = os.path.join(imgpath, '{}.{}'.format(i[:-4], postfix))
txt_source_path = os.path.join(txtpath, i)
img_destination_path = os.path.join(output_val_img_folder, '{}.{}'.format(i[:-4], postfix))
txt_destination_path = os.path.join(output_val_txt_folder, i)
shutil.copy(img_source_path, img_destination_path)
shutil.copy(txt_source_path, txt_destination_path)
配置文件设置:
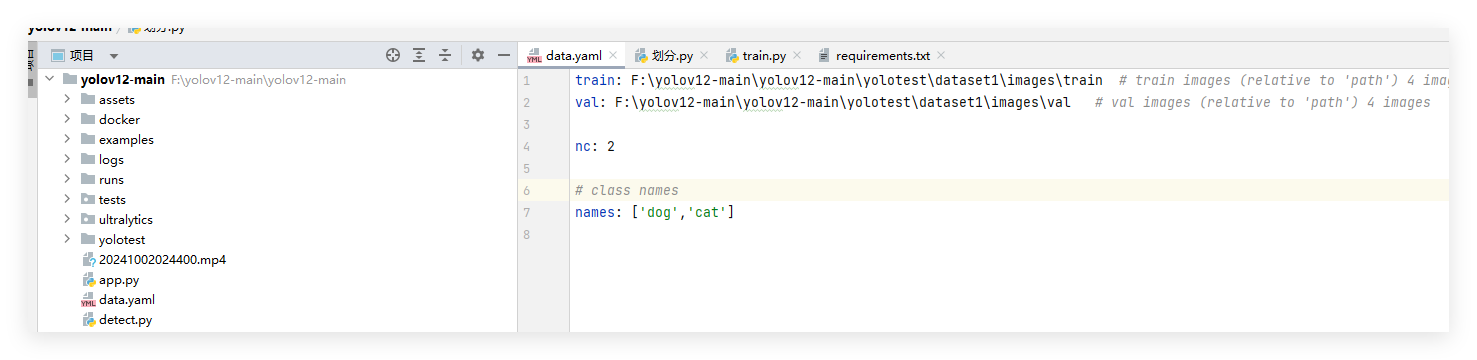
9.在data.yaml 数据配置文件中,配置数据的路径,names的顺序与classes.txt保持一致。
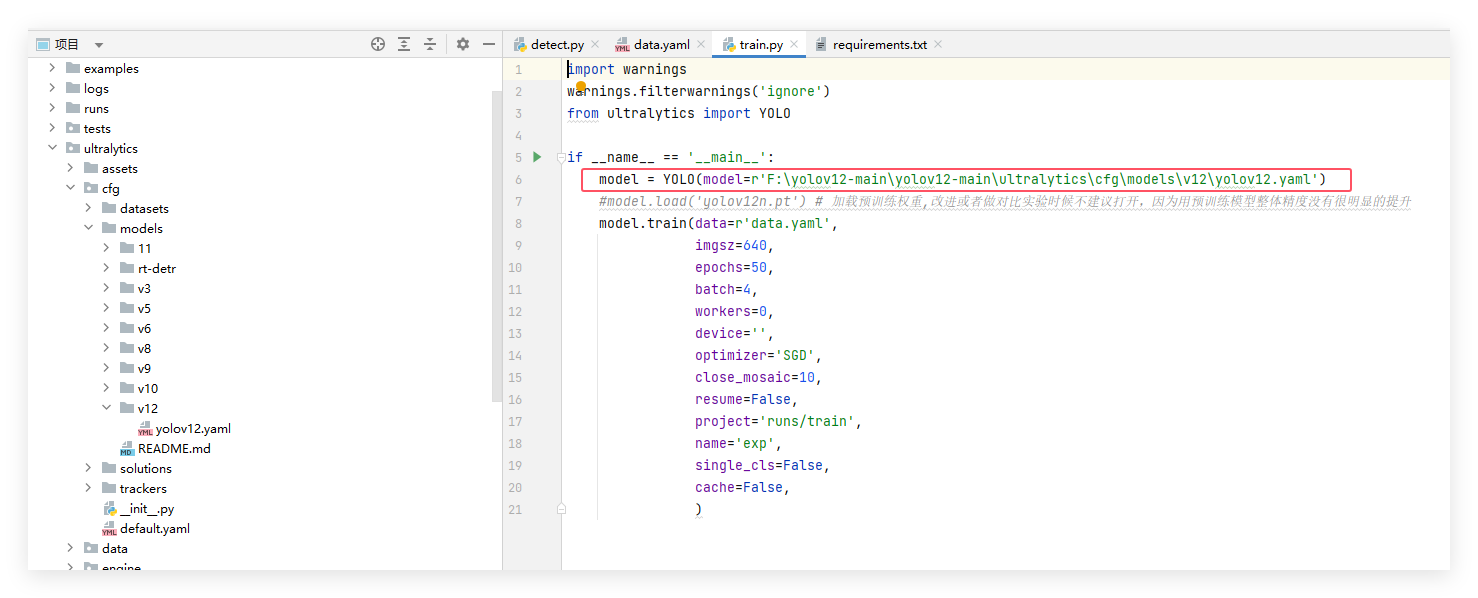
10.在train.py中,设置模型配置文件的路径
运行:
11.运行train.py,训练模型。

飞浆找的现成数据集
第一步:(json->txt)
把里面json格式的label改成yolo可识别的txt格式
第二步:(改data.xml)
修改data.xml中,images里面的train和val的路径
修改data.xml中,nc的数量
修改data.xml中,类别名称
第三步:运行

注意:
1、data.xml中只用填写images中训练集和测试集的数据的位置,yolo会自动到images同目录下找labels的位置,所以拿到数据集里面的 图片+json数据后,需要划分为下面的格式: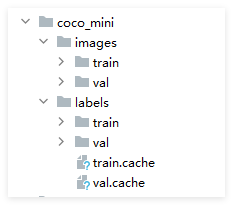
2、
pycharm中的项目支持查看历史版本的项目代码,可以回滚跳转
可执行自定义数据集版本:

比对不同参数下训练结果
epoch=10,batch=8,imgsz=640

epoch=10,batch=32,imgsz=320

epoch=10,batch=32,imgsz=480

epoch=100,batch=32,imgsz=320

训练一个模型后进行视频检测
训练结果:
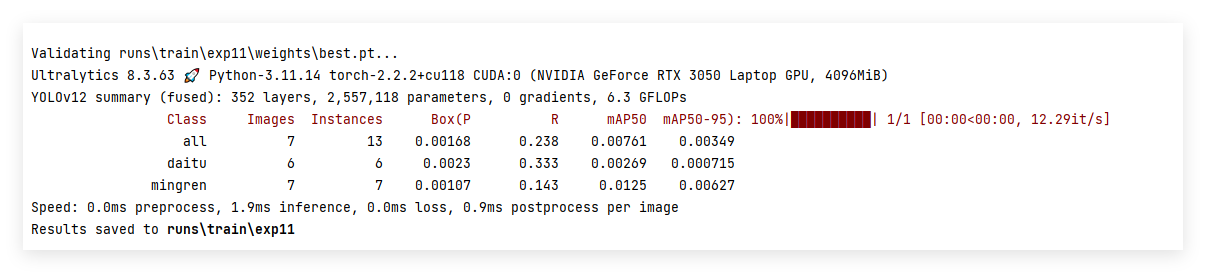
运行命令:
yolo detect predict model=runs/train/exp11/weights/best.pt source="F:\edge download file\yolov5-code-main\datasets\BVN.mp4" show=True
参考文章:
YOLOv12环境配置,手把手教你使用YOLOv12训练自己的数据集和推理(附YOLOv12网络结构图),全文最详细教程_yolo12-CSDN博客

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)