RAG:大模型的“知识导航”,从此问答不迷路
RAG(检索增强生成)技术通过将大模型与外部知识库结合,有效解决了传统大模型知识局限、幻觉问题等痛点。其核心流程分为准备阶段(文档分片、向量索引)和回答阶段(检索-重排-生成),实现了精准回答、答案可溯源、低成本知识更新等优势。代码示例展示了基于DeepSeek API的RAG系统实现过程,包括文档加载、向量检索、答案生成等关键环节。该技术将大模型的通用推理能力与企业专属知识解耦,使企业能以文档维
目录
0 前言
众所周知,现在所有的大模型都是基于已有的公开数据进行训练的。它们知识渊博,但却“不知道自己不知道什么”。当我想为公司搭建一个客服助手时,发现了一个尴尬的局面:我引入的DeepSeek大模型,就像一个毫无感情的问答机器人,它对我们的商家信息、商品详情一无所知。一个很自然的想法是:“那我直接把公司文档喂给它不就行了?”于是,我们尝试在提问时,附带上厚厚的产品手册。但很快,新的问题又出现了:
- 效率低下: 如果这篇文档过长,而与当前问题真正相关的可能只有几页。但模型需要“通读”全文,才能找到那关键几行。
- 能力瓶颈: 由于大模型的上下文窗口(记忆长度)有限,当文档超出限制时,模型根本无法处理,最终只能“断章取义”。
成本与效果双输: 将长篇文档全部塞给模型,不仅消耗巨大的计算资源(Token都是钱!),还会让模型被大量无关信息干扰,导致回答效果差强人意,甚至“一本正经地胡说八道”。那么,有没有一种方法,能像我们人类查资料一样,先快速“检索”到相关的知识点,再让模型基于这些精准的信息来“生成”答案呢?
答案是:有!这就是今天我们要深入探讨的主角——RAG。
1 什么是RAG
RAG(Retrieval-Augmented Generation:检索增强生成)。简单的讲,就像一个学识渊博的机器人,你没有给它配备任何资料,它只能根据已有知识回答,或者不回答。当配备了RAG,好比给这个机器人一个资料库,每当你向它提问资料库里面的内容时,它会快速翻阅资料库,定位到相关位置进行总结回复,生成一个可靠的答案。总体工作流程是:先从资料库里检索相关内容——>再基于这些内容生成答案。
2 RAG是如何工作的
RAG工作流程:
- 准备阶段(回答问题之前):分片——>索引
- 回答阶段(回答问题之后):召回——>重排——>生成
2.1 准备阶段
准备阶段发生在用户提问之前,提前将文档处理好用来后期使用。
分片:将资料库划分成多个片段文本的过程。可以按照字数划分、按照段落划分、按照章节划分、按照页码划分。
索引:使用Embedding模型将片段文本转换为向量,再把Embedding后的向量以及对应片段文本放到向量数据库中方便后期查询。
| 片段文本 | 向量 |
| 我们公司500人 | [15,9,3,10,7,14,10] |
| 主要业务是Agent | [10,8,8,11,0,12,13] |
| 注册公司2.5个两年半了 |
[11,20,14,6,9,1,12] |
2.2 回答阶段
回答阶段发生在用户提问之后,用于选出与用户问题关联程度最大的片段。
召回:搜索与用户问题有相关片段的过程,选出相关性最大的几个片段。
相关性计算依据 :向量相似度S。
similarity():计算函数 QV:用户问题向量 FV:片段向量
目前比较流行的三种计算方案:
- 余弦相似度:夹角越小,向量相似度越大。
- 欧氏距离:两个向量终点的距离,距离越小,向量相似度越大。
- 点积:综合1和2的计算方式,点积值越大,向量相似度越大。
计算完毕后选出10个向量相似度最高的片段向量。数量可以自行设置,不一定是10个,总之不会很多。
重排:重新排序,对召回的10个结果重新排序并选取3个向量相似度最高的。
这里大家不免会有一个疑问,不是已经召回一次了吗,完全可以在召回阶段选出三个向量相似度最高的片段结果,为什么还要继续重排这一步骤?是的没错,我们确实可以在召回或者重排任一阶段选出3个高相关性的片段向量。
原因在于,我们追求的是效率与精度的平衡。虽然重排的计算精度比召回的高,但是相应成本也高,计算时间也较长,所以我们综合二者共同筛选,结合了召回的“高效率” 和重排的“高精度”。好比公司招聘,收到了10000份简历,但是招聘岗位只有10人。如果直接从10000份简历中选出这10人,难度较大,所以采取先粗筛再精选的方案。通过学历、专业和实习经历大致选出50份简历,再结合岗位需求和候选人的技能掌握精选出最后10人。召回重排也是这个原理。
重排计算依据:cross_encoder。
| 召回 | 重排 | |
| 成本 | 低 | 高 |
| 准确率 | 低 | 高 |
| 计算方式 | 向量相似度 | cross_encoder |
| 筛选特点 | 粗筛 | 精选 |
生成:将用户问题和与用户问题相关的3个片段一起发给大模型,让大模型来回答用户问题。
这是RAG流程的最后一步,大模型会返回用户问题的答案。
总体流程: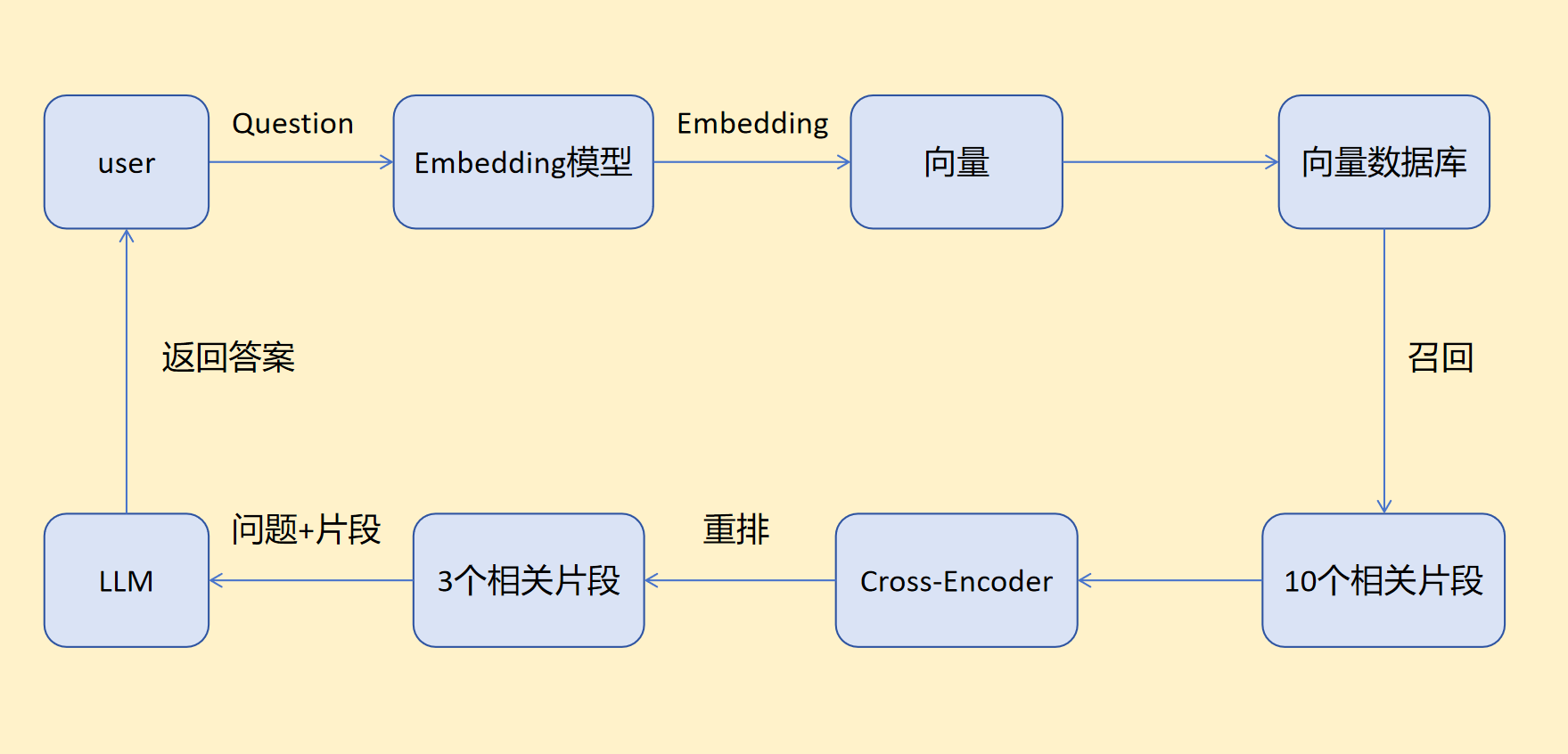
在回答用户问题之前,RAG系统会预先对文档进行分片处理,并为每个片段建立索引。这一过程将文本转化为向量形式,并与原始内容一并存储于向量数据库中。当用户提出问题时,系统首先使用Embedding模型将查询内容向量化,随后通过召回与重排机制,从海量片段中筛选出关联度最高的若干条文本。最终,系统将原始问题与这些精选出的文本片段一同发送给大语言模型。经由大模型整合、推理与生成后,用户将获得一个准确、有据可依的答案。
3 RAG带来的核心优势
1. 答案可溯源,从根本上提升可信度
传统大模型的回答如同一个匿名的观点,我们无从考证其依据。而RAG的每一次回答,都像是附上了一份清晰的“参考文献列表”。系统可以明确告知用户,其结论是基于哪份文档的哪个章节。这种可追溯的特性,不仅让用户能够交叉验证,更在决策支持、合规审查等高风险场景中,为AI的产出建立了至关重要的审计链条,使其从“仅供参考”的意见,升级为值得信赖的参考依据。
2. 知识库易于维护,实现低成本即时更新
RAG创造性地将大模型的“通用推理能力”与企业的“专属知识”进行了解耦。这意味着,更新AI的知识不再等同于耗时费钱的“模型再训练”。对企业而言,管理RAG系统就像维护一个普通的文档库——当产品信息、公司政策或市场资料发生变化时,IT人员只需在知识库中替换或上传新的文件即可。这种模式极大地降低了AI系统的运维门槛与成本,使得企业能够拥有一个永远与最新信息同步的智能助手。
4 RAG代码实战
安装依赖:
pip install sentence-transformers openai numpy python-dotenv同级目录下创建.env文件
DEEPSEEK_API_KEY=你的DeepSeek_API密钥main.py
import numpy as np
from sentence_transformers import SentenceTransformer
from openai import OpenAI
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
class RealRAG:
def __init__(self):
# 初始化Embedding模型
self.embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# 初始化OpenAI客户端(使用DeepSeek API)
self.client = OpenAI(
api_key=os.getenv('DEEPSEEK_API_KEY'), # 在.env文件中设置
base_url="https://api.deepseek.com/v1"
)
self.vectors = []
self.chunks = []
def load_document(self, file_path="doc.md"):
"""加载并处理文档"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 按段落分片
self.chunks = [chunk.strip() for chunk in content.split('\n\n') if chunk.strip()]
# 生成向量
if self.chunks:
self.vectors = self.embedding_model.encode(self.chunks)
print(f"✅ 成功加载 {len(self.chunks)} 个文档片段")
else:
print("❌ 文档内容为空")
except FileNotFoundError:
print(f"❌ 文件 {file_path} 未找到,请创建doc.md文件")
except Exception as e:
print(f"❌ 加载文档时出错: {e}")
def search(self, query, top_k=3):
"""搜索最相关的文档片段"""
if not self.vectors:
print("❌ 请先加载文档")
return []
query_vector = self.embedding_model.encode([query])
# 计算余弦相似度
similarities = np.dot(self.vectors, query_vector.T).flatten()
norms = np.linalg.norm(self.vectors, axis=1) * np.linalg.norm(query_vector)
similarities = similarities / norms
# 获取最相关的片段
top_indices = similarities.argsort()[-top_k:][::-1]
results = []
for idx in top_indices:
results.append({
'content': self.chunks[idx],
'similarity': float(similarities[idx])
})
return results
def generate_answer(self, question, context_chunks):
"""使用真实大模型生成答案"""
# 构建上下文
context = "\n\n".join([doc['content'] for doc in context_chunks])
# 构建系统提示词
system_prompt = """你是一个专业的助手,需要根据用户提供的参考文档来回答问题。
请严格按照参考文档的内容进行回答,不要编造文档中不存在的信息。
如果参考文档中没有相关信息,请明确说明“根据提供的文档,没有找到相关信息”。"""
user_prompt = f"""参考文档:
{context}
问题:{question}
请根据以上参考文档回答:"""
try:
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.1, # 低温度确保答案更准确
max_tokens=1000
)
return response.choices[0].message.content
except Exception as e:
return f"❌ 调用大模型时出错: {e}"
def ask(self, question):
"""完整的RAG提问流程"""
if not self.chunks:
print("❌ 请先加载文档")
return
print(f"\n🤔 问题: {question}")
# 1. 检索相关文档
relevant_docs = self.search(question)
if not relevant_docs:
print("❌ 未找到相关文档")
return
# 2. 生成答案
answer = self.generate_answer(question, relevant_docs)
# 3. 显示结果
print(f"\n✅ 答案: {answer}")
print(f"\n📚 参考来源 (共{len(relevant_docs)}条):")
for i, doc in enumerate(relevant_docs):
print(f"{i+1}. [相似度: {doc['similarity']:.3f}] {doc['content'][:60]}...")
return answer
# 使用示例
if __name__ == "__main__":
# 创建RAG系统
rag = RealRAG()
# 加载文档
rag.load_document("doc.md")
# 交互式提问
print("🚀 RAG系统已启动,输入'quit'退出")
print("-" * 50)
while True:
question = input("\n请输入问题: ").strip()
if question.lower() in ['quit', 'exit', '退出']:
break
if question:
rag.ask(question)
print("-" * 50)
5 总结
RAG技术成功地将大模型的通用推理能力与企业专属知识完美结合,既保持了前者的强大智能,又具备了后者的准确性和时效性。它不仅是技术架构的创新,更是企业AI落地的重要里程碑——让每个企业都能以最低成本拥有理解自身业务的“专属专家”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)