具身智能及其4个方向的应用案例
本文介绍了具身智能的四个应用方向:实时检测、智能管家、视觉追踪和智能搬运。通过阿里云大模型API和ROS2系统实现多模态信息融合,包括早期/晚期/混合融合等方法。具体应用包括:1)实时场景分析;2)语音控制导航与任务执行;3)目标物体追踪;4)物体夹取搬运。每个应用都包含详细的操作步骤、程序分析和效果演示,展示了具身智能在环境交互中的实际应用能力。(149字)
具身智能及其4个方向的应用案例
手续
1. 大模型API-Key获取及配置
- 1.1 阿里云大模型账号注册和API密钥获取及配置
- 1.1.1 注册账号
- 注册网址:阿里云通义大模型
- 需填写手机号、校验码,同意用户协议、隐私政策、产品服务协议。
- 完成注册后需进行实名认证,可选择个人认证或企业认证。
- 个人认证可选择支付宝认证,需授权阿里云获取支付宝认证信息。
- 1.1.2 部署并测试在线大模型
- 新用户开通即享每个模型100万免费tokens。
- 选择通义千问-Plus模型进行测试。
- 1.1.3 API密钥获取
- 在阿里云控制台的密钥管理页面创建API-KEY。
- 将API-KEY复制并保存到本地电脑。
- 1.1.4 部署密钥
- 修改程序配置文件
/home/ubuntu/ros2_ws/src/large_models/large_models/config.py,将阿里云key放置进去。
- 修改程序配置文件
- 1.1.1 注册账号
- 1.2 部署阶跃星辰API
- 登录阶跃星辰开放平台,获取接口密钥。
- 修改程序配置文件,将阶跃星辰key放置进去。
2. 具身智能概述
2.1. 具身智能概述
具身智能(Embodied Intelligence)是人工智能领域的重要分支,强调智能体通过物理实体与环境的交互实现自主学习和决策。其核心理念在于“智能源于身体与环境的动态互动”,突破了传统 AI 依赖静态数据的局限,广泛应用于工业、医疗、服务、教育、军事等领域。
2.2. 多模态信息融合
具身智能的一个比较重要的知识点分支是多模态信息融合,多模态信息融合是指将来自不同模态(如文本、图像、语音等)的数据进行有效整合,以获得更全面和准确的信息表示。这一过程在人工智能领域尤为重要,因为现实世界中的信息往往是多模态的,单一模态的信息往往无法提供足够的上下文或细节。因此,多模态信息融合旨在通过结合多种模态的数据,提升模型的性能和鲁棒性。
多模态信息融合的方法可以大致分为以下几种:
- 早期融合:
在数据处理的早期阶段就将不同模态的数据合并在一起。这种方法通常在输入层进行,通过数据对齐和转换技术,将原始数据映射到同一空间,生成更丰富和表达力更强的数据形式。例如,在图像和语音融合中,可以将两种模态的数据直接连接作为神经网络的输入。
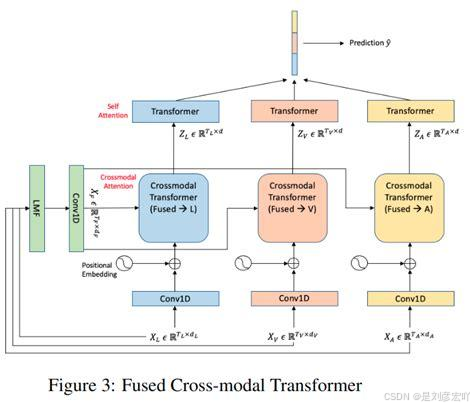
- 晚期融合:
在模型的中间层或输出层将不同模态的数据进行融合。这种方法允许为每个模态使用特定算法进行训练,便于未来添加或交换不同模态。例如,可以将图像识别和文本分析的结果结合在一起,以得出最终的决策。
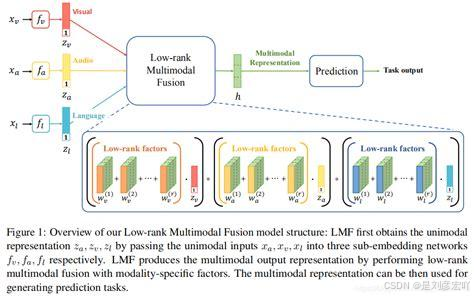
- 混合融合:
结合早期融合和晚期融合的优点,在不同的处理阶段进行多次融合。这种方法能够充分利用不同模态之间的互补性,提高模型的性能和鲁棒性。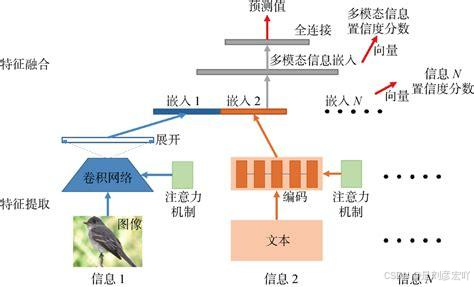
- 特征级融合:
将从多个模态中抽取的特征通过某种变换映射为一个特征向量,然后送入分类模型中,获得最终决策。这种方法在特征提取阶段就将不同类型的数据进行融合。
- 决策级融合:
将不同模态信息获得的决策合并来获得最终决策。这种方法具有较好的抗干扰性能,对于传感器性能和种类要求相对不高,但可能面临较大的信息损耗。
- 深度融合:
发生在特征提取阶段,它在特征空间中混合多模态数据以获得融合特征,补偿其他模态缺失的特征,然后在预测阶段应用这些融合特征进行分类或回归任务。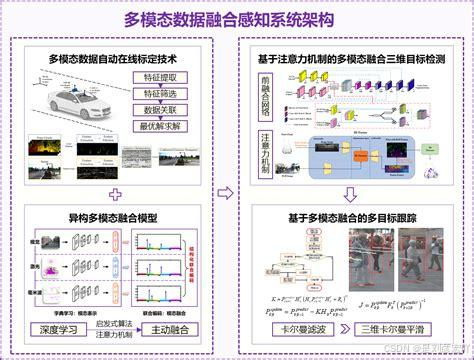
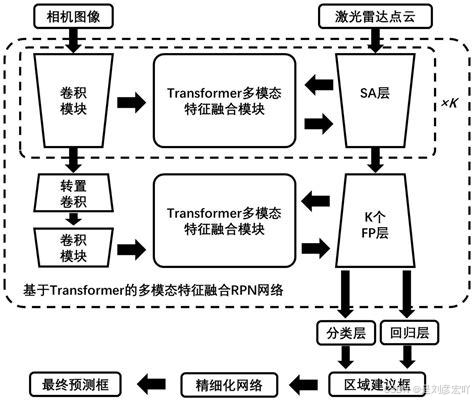
多模态信息融合不仅在理论上有重要意义,而且在实际应用中也展现了巨大的潜力。例如,在自动驾驶、医学图像分析、人机交互等领域,多模态信息融合技术都得到了广泛的应用,并显著提升了系统的性能和可靠性。
3.具身智能应用之实时检测
3.1.玩法简介
本节课学习使用大模型对时实场景进行分析实现实时检测玩法。本节课的大模型属于线上大模型,需要准备一根网线用于连接网络,或者将机器人连接到局域网。
说出唤醒词(唤醒词需确认烧录的固件,我们出厂默认烧录的固件唤醒词是“Hello,HiWonder”)激活WonderEchoPro,WonderEchoPro回应“我在”。
执行该玩法,我们可以自由组织语言,通过机器人进行识别当前场景,进行分析并播报出它的分析结果。
3.2.准备工作
3.2.1.确认WonderEchoPro固件
WonderEchoPro出厂默认的唤醒词是“Hello,HiWonder”的英文固件。如果想要更换唤醒词为“小幻小幻”,可以参考教程目录下“AI大模型课程\语音模块介绍与安装”及同目录下的“固件烧录视频”烧录附录中的中文固件。
假设之前已经根据以上方法,烧录过其他固件(例如“小幻小幻”唤醒词固件),则需要使用对应的唤醒词进行唤醒。
下面的课程示例默认以出厂唤醒词“Hello,HiWonder”为例进行说明。
3.2.2.配置大模型相关key
程序默认不配置大模型相关密钥,在开启玩法前需要可以参考本章节“多模态大模型应用\大模型API-Key获取及配置”完成对相关密钥的配置,此步骤不可跳过,不然影响大模型相关玩法的体验。
3.2.3.配置网络
注意:本节课的大模型是属于线上大模型,在开始前需要准备一根网线用于连接网络或者将机器人切换成局域网模式。
在此玩法模式下,机器人必须联网,配置为STA(局域网)模式或AP(直连)模式下连接网线。
网络的具体配置方法有以下两种方式:
通过手机APP进行网络配置,具体的路径如下。
“教程资料/机器人快速使用指南”文档内的“基础使用/手机APP安装与连接/局域网模式连接(选看)”.
通过VNC远程连接到机器人修改相关配置文件进行网络配置,具体的路径如下。“教程资料/机器人快速使用指南”文档内的“开发环境搭建/远程设备连接/局域网模式连接”。
3.3.玩法步骤
1.指令输入需严格区分大小写及空格。
2.机器人必须联网,配置为 STA(局域网)模式或 AP(直连)模式下连接网线。
- 启动机器人,将其连接至远程控制软件 VNC。关于如何连接远程桌面,可前往“教程资料\机器人快速使用指南\配套手册\LanderPi 使用入门->开发环境搭建”。
- 在树莓派的桌面双击的“Terminator”图标 ,打开命令行终端,进入到 ROS2 开发环境。
- 输入指令关闭自启的玩法。
~/.stop_ros.sh
3.4. 实现效果
玩法开启后,我们可以自由组织语言,例如:“你看到了什么”,机器人自动识
别视线范围内的场景并进行思考,将目前的场景内容都描述出来。
3.5. 程序简要分析
3.5.1.launch 文件分析
程序路径:
/home/ubuntu/ros2_ws/src/large_models_examples/large_models_examples/vllm_with_camera.launch.py
4. 具身智能应用之智能管家
- 4.1 玩法简介
- 通过语音控制机器人完成导航和任务。
- 4.2 准备工作
- 确认固件,配置key,配置网络,建图。
- 4.3 玩法步骤
- 启动机器人,运行launch文件,唤醒机器人,下达指令。
- 4.4 实现效果
- 机器人导航到指定位置,执行任务。
- 4.5 程序简要分析
- 分析launch文件和python文件,涉及导航、语音交互、动作执行等。
- 4.6 导航位置修改
- 修改程序中的导航位置参数。
5. 具身智能应用之视觉追踪
- 5.1 玩法简介
- 通过语音控制机器人追踪指定物体。
- 5.2 准备工作
- 确认固件,配置key,配置网络。
- 5.3 玩法步骤
- 启动机器人,运行launch文件,唤醒机器人,下达指令。
- 5.4 实现效果
- 机器人追踪指定物体并在画面中框选。
- 5.5 程序分析
- 分析launch文件和python文件,涉及目标检测、图像处理、跟踪算法等。
6. 具身智能应用之智能搬运
- 6.1 玩法简介
- 通过语音控制机器人完成物体的夹取和放置。
- 6.2 准备工作
- 确认固件,配置key,配置网络,夹取放置校准,导航地图构建。
- 6.3 玩法步骤
- 启动机器人,运行launch文件,唤醒机器人,下达指令。
- 6.4 实现效果
- 机器人完成物体的夹取和放置任务。
- 6.5 导航位置修改
- 修改程序中的导航位置参数。
- 6.6 程序分析
- 分析launch文件和python文件,涉及导航、夹取、放置、语音交互等。
关键引用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)