【模型推理篇】vLLM核心思想 - ① 分页注意力 paged attention
开始前的碎碎念…近期在公司内部尝试了几个大模型相关岗位,不是太顺利,问题还是集中在,“鸡生蛋,蛋生鸡”,虽然自认为有着还算不错的知识储备和热情,但还是会被“过往项目经验匹配度问题”婉拒,有的很礼貌,有的则相当不客气,甚至直接不看好。不过我的目标很明确,也清楚过程注定不会轻松,所以在不影响主业的情况下,会继续用个人时间学习和沉淀;一次不行就等下一次,不信没有机会!些许风霜罢了~早上看到 3I/ATL
开始前的碎碎念…
近期在公司内部尝试了几个大模型相关岗位,不是太顺利,问题还是集中在,“鸡生蛋,蛋生鸡”,虽然自认为有着还算不错的知识储备和热情,但还是会被“过往项目经验匹配度问题”婉拒,有的很礼貌,有的则相当不客气,甚至直接不看好。
不过我的目标很明确,也清楚过程注定不会轻松,所以在不影响主业的情况下,会继续用个人时间学习和沉淀;一次不行就等下一次,不信没有机会!些许风霜罢了~
早上看到 3I/ATLAS 快到 木卫二了,降临派认为它是朝着地球来的;那它的路线倒是非常清晰,无非路上干扰多了一些,继续保持节奏,做该做的事儿,走好每一步,等待合适机会!
前几篇的【模型训练篇】文章,分别复习了:Megatron、TRL、VeRL,接下来则是【模型推理篇】系列,会主要集中在 vLLM、SGLang、Triton上;
本期先从应用最多的 vLLM 开始,还是按以往的套路,先理论、再源码、后实践,只不过因为DeepSeek的大佬开源过 nano-vLLM,想着是不是可以跟着它也 "手搓"一个 vLLM。
vLLM 的核心思想主要有两个:① 分页注意力 paged attention ② 动态批处理 continuous batching
今天先从 分页注意力 paged attn 开始,下面所有内容均来自其论文 【Efficient Memory Management for Large Language
Model Serving with PagedAttention】
背景
提高serving能力其中一个方向是 高效的batching ,最大化batch并行处理的请求数量,但batch size会受GPU显存限制,所以突破显存瓶颈,是突破推理吞吐量的关键。
这其中KV Cache占用了大量显存,如下图,先不看占最大头的模型参数,剩下的主要就是kv cache 和 others(激活值还可以recompute等手段减少)
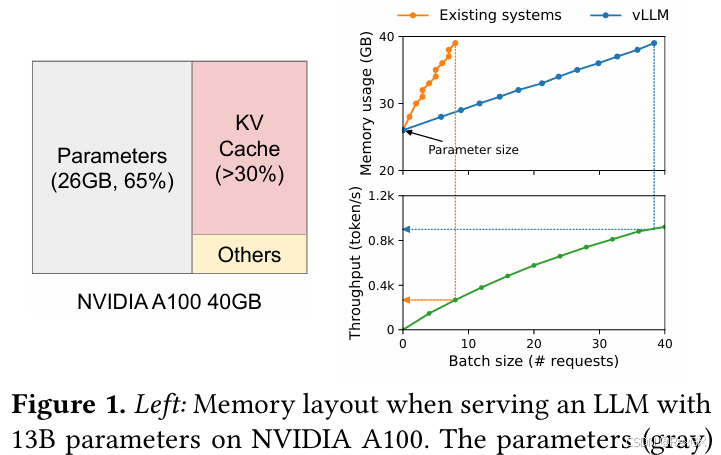
kv cache 的大致估算公式: k v _ c a c h e = 2 ∗ b a t c h _ s i z e ∗ s e q _ l e n ∗ n u m _ l a y e r s ∗ 精度 kv\_cache = 2 * batch\_size * seq\_len * num\_layers * 精度 kv_cache=2∗batch_size∗seq_len∗num_layers∗精度 ,也就是每层attn都要存储,batch_size个、seq_len个token的kv值;
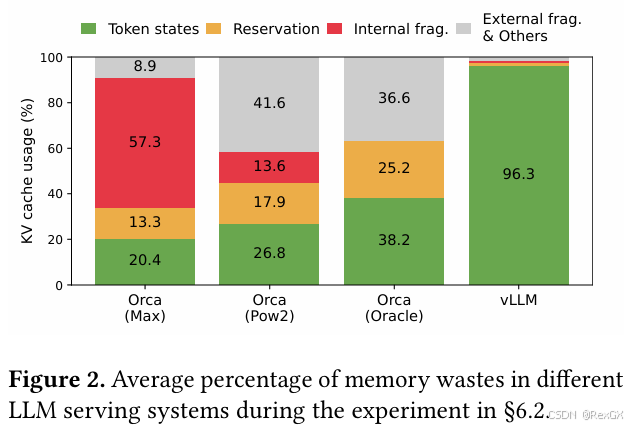
vLLM大佬们经过分析,发现显存中主要存在着以下3种显存浪费;
下面这张图中,黄色和绿色分别代表两个request, 其中浅色代表prompt,深色代表output;
首先第一处显存浪费就是 external fragmentation 也就是 显存碎片,因为系统在分配显存时,都是尽量的分配连续的,但很多时候空闲的不连续的显存,无法满足需求,所以就形成了一些 显存空洞,也就是 显存碎片;
另一方面,由于无法预知最终生成seq的长度,所以一般都是直接按max_seq_len进行显存分配,这就会导致另外两种显存浪费;
在 decode 阶段,递归式的生成下一个token的时候,不确定最终会生成多少个,假设预计生成2048个token,但实际只会生成100个token,那么在从生成第一个token开始,到<eos>为止,这期间的reserved没有被充分利用(虽然最终会写满)
同时,从<eos>到最终2048个token这部分显存,则永远不会被利用,就造成了 internal fragmentation。

所以针对以上问题,vLLM提出了 paged attention,下图是经过优化后的vLLM,大大降低了显存浪费。
思想
逻辑分块
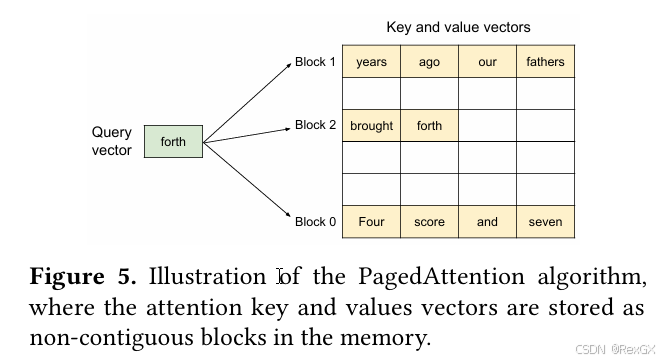
vLLM 借鉴了操作系统对内存的优化,也就是 内存分块后,通过虚拟内存的的逻辑表,映射到真实的物理内存;
下图中,kv cache 是分块(block)存储的,block是不连续的,每个block内部存储固定size个token的kv cache;
如图,正常的一句话是 “Four score and seven / years ago our fathers / brought forth”
- 有3个不连续的block
- 每个block内部存储4个token的kv cache
- 当前token “forth” 在计算attn的时候,会和前面的所有token,进行attn计算
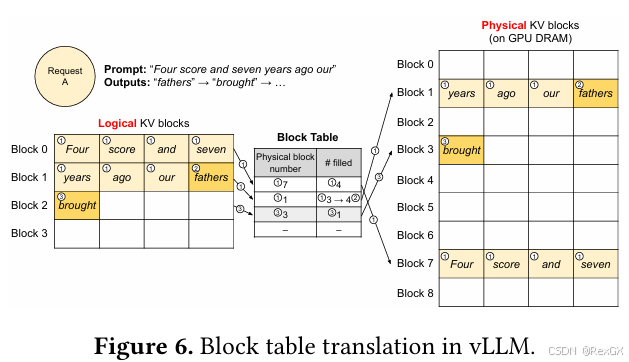
其中实现基础就是 KV Cache Manager,靠的是 Block Table 即逻辑映射表;
下图可以拆分成两个阶段:
prefill:一次性的对 “Four score and seven years ago our” 计算kv cache,然后进行分块存储decode:自递归的生成 “father”,然后是 ”brought“
其中:
- 逻辑block中的
Four score and seven映射到物理不连续的block7上,且已经填满filled了4个token - 逻辑block中的
years ago our fathers映射到物理不连续的block1上,从第3个token生成第4个token “fathers”
下图展示了对两个request的处理:
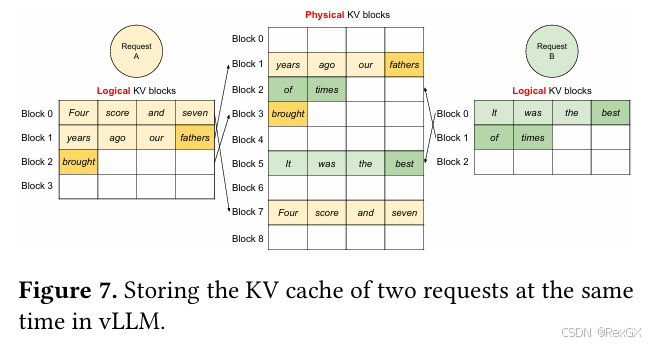
所以通过这种方式,使得vLLM不需要再像之前那样进行 预分配连续显存,提高了显存利用率,从而提升了可并行处理个数,即吞吐量,从而提高了serving能力!
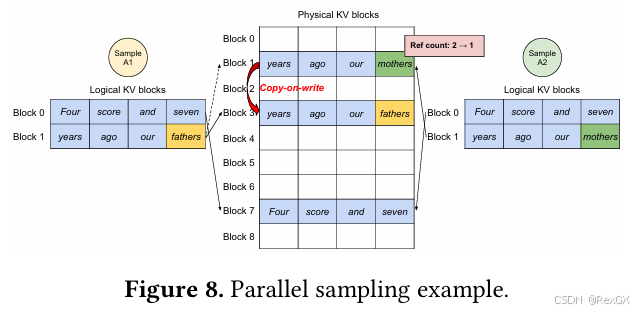
并行采样
vLLM的这种设计带来的另外一个好处是,提升并行采样能力,例如 beam search 或是 rollout 时需要针对同一个prompt生成多个output,如下图,针对 “Four score and seven / years ago our”,采样2个output,1个生成的是 “father”,1个是"mother",那么此时,就可以利用分块后的block,共享大部分信息;
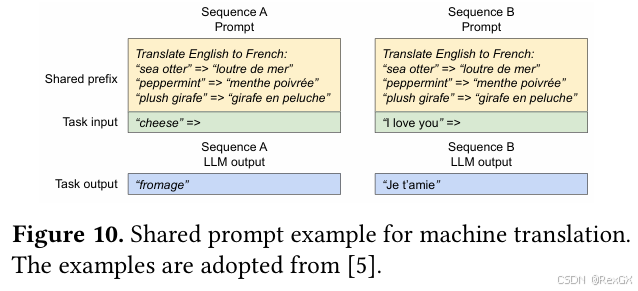
共享前缀
同时,大段的、固定的、系统提示词,甚至是多轮对话场景,也可以共享prefix,进一步降低显存;
以上是 vLLM 核心思想 Paged Attention 的理论介绍,下一篇继续介绍 continuous batching。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)