Rerank重排序:提升RAG系统检索准确率的关键技术
摘要 重排序(Reranking)是检索增强生成(RAG)系统中的关键环节,用于优化检索结果。它采用两阶段策略:第一阶段使用高效但精度较低的双编码器(Bi-Encoder)快速召回候选文档;第二阶段通过计算密集但更精准的交叉编码器(Cross-Encoder)对候选文档进行深度重排序。双编码器独立编码查询和文档,通过向量相似度快速匹配,适合海量数据;交叉编码器则联合处理查询和文档,利用注意力机制捕
一、引言:检索系统的最后一道关卡
在构建检索增强生成(Retrieval-Augmented Generation, RAG)系统时,我们常常遇到这样的困境:向量检索虽然速度快,但返回的文档并非全部高度相关;而大语言模型对上下文的理解能力有限,当我们向其输入大量噪声文档时,生成结果的质量就会大打折扣。这正是重排序(Reranking)技术要解决的核心问题。
重排序是一个二阶段检索系统中的精准筛选环节:第一阶段使用快速但相对粗糙的检索方法(如向量检索或BM25)从海量文档中筛选出候选集;第二阶段使用计算密集但更精确的重排序模型对这些候选文档进行深度分析和重新排序,确保最相关的信息被优先呈现给下游的生成模型。
重排序技术的应用场景广泛,包括但不限于:
- RAG系统优化:提高检索准确率,减少大语言模型的幻觉(hallucination)
- 企业级搜索引擎:提升内部知识库的检索质量
- 问答系统:精确匹配问题与最相关答案
- 推荐系统:在候选物品中筛选最匹配用户意图的内容
本文将深入探讨重排序的技术原理、实现方式、应用场景以及性能权衡,帮助读者全面理解这一关键技术。
二、技术基础:理解编码器架构
在深入重排序技术之前,我们需要理解两种核心的编码器架构:双编码器(Bi-Encoder)和交叉编码器(Cross-Encoder)。这两种架构代表了信息检索领域中速度与准确性的不同权衡策略。
2.1 双编码器(Bi-Encoder):速度的王者
2.1.1 架构原理
双编码器,顾名思义,使用两个独立的编码器分别处理查询(query)和文档(document)。其核心思想是:
- 独立编码:查询和文档被分别输入到同一个(或两个结构相同的)Transformer模型中
- 向量表示:每个输入文本被转换为一个固定维度的向量(通常是768或1536维)
- 相似度计算:通过简单的向量运算(如余弦相似度)快速计算查询与文档的相关性
数学表达上,如果查询编码为向量 u,文档编码为向量 v,则相似度计算为:
$ \text{similarity}(q, d) = \frac{\mathbf{u} \cdot \mathbf{v}}{||\mathbf{u}|| \cdot ||\mathbf{v}||} = \cos(\theta) $
2.1.2 训练机制
双编码器通常使用对比学习(Contrastive Learning)进行训练。训练目标是:
- 最大化相关查询-文档对之间的向量相似度
- 最小化不相关查询-文档对之间的向量相似度
常用的损失函数包括:
对比损失(Contrastive Loss):
L = − log exp ( sim ( q , d + ) / τ ) ∑ i exp ( sim ( q , d i ) / τ ) \mathcal{L} = -\log \frac{\exp(\text{sim}(q, d^+) / \tau)}{\sum_{i} \exp(\text{sim}(q, d_i) / \tau)} L=−log∑iexp(sim(q,di)/τ)exp(sim(q,d+)/τ)
其中:
- $q $ 是查询
- d + d^+ d+ 是相关文档(正样本)
- d i d_i di 是批次中的所有文档(包括负样本)
- τ \tau τ 是温度参数,通常设为0.01-0.1
2.1.3 优势与局限
优势:
- 极高的检索效率:文档向量可以预先计算并索引,查询时只需编码查询并进行向量检索
- 可扩展性强:能够处理数十亿级别的文档库
- 低延迟:单次查询通常只需几毫秒
局限:
- 信息压缩损失:将整个文档的语义压缩到固定维度向量中,必然导致信息丢失
- 缺乏交互理解:查询和文档独立编码,无法捕捉它们之间的细微交互关系
- 上下文盲性:在编码文档时无法获知查询内容,导致相关性判断不够精确
2.2 交叉编码器(Cross-Encoder):精度的代表
2.2.1 架构原理
交叉编码器采用完全不同的策略,它将查询和文档作为一个整体同时输入到模型中:
- 联合编码:查询和文档被拼接后(通常使用[SEP]标记分隔)一起输入Transformer
- 深度交互:模型的注意力机制能够在查询和文档的每个token之间建立关联
- 分类输出:模型最终输出一个相关性分数(通常是0到1之间的值)
输入格式通常为:
[CLS] query tokens [SEP] document tokens [SEP]
2.2.2 训练机制
交叉编码器使用二元交叉熵损失(Binary Cross-Entropy, BCE)进行训练:
L = − ( y ⋅ log ( y ^ ) + ( 1 − y ) ⋅ log ( 1 − y ^ ) ) \mathcal{L} = - (y \cdot \log(\hat{y}) + (1 - y) \cdot \log(1 - \hat{y})) L=−(y⋅log(y^)+(1−y)⋅log(1−y^))
其中:
- y ∈ { 0 , 1 } y \in \{0, 1\} y∈{0,1} 是真实标签(1表示相关,0表示不相关)
- y ^ \hat{y} y^ 是模型预测的相关性分数
训练数据通常包括:
- 正样本对:相关的查询-文档对
- 负样本对:不相关的查询-文档对(包括随机负样本和困难负样本)
困难负样本挖掘是提升交叉编码器性能的关键技术。困难负样本指的是那些与查询语义相近但实际不相关的文档,例如:
- 查询:“如何在Elasticsearch中配置API密钥”
- 困难负样本:“如何在S3中配置API密钥”(主题相近但平台不同)
2.2.3 深度交互的优势
交叉编码器的核心优势在于其注意力机制能够捕捉查询和文档之间的细微交互:
示例分析:
- 查询:“机器学习中的正则化技术”
- 文档A:“正则化是防止过拟合的重要技术,包括L1和L2正则化”
- 文档B:“正则是一个数学概念,在集合论中有重要应用”
双编码器可能无法很好地区分这两个文档,因为它们都包含"正则"相关的词汇。但交叉编码器通过联合处理可以理解:
- 查询中的"机器学习"与文档A中的"过拟合"有强关联
- 文档B中的"集合论"与机器学习无关
2.2.4 优势与局限
优势:
- 高准确性:相比双编码器,在大多数基准测试中准确率提升5-15%
- 深度语义理解:能够捕捉查询和文档之间的复杂交互关系
- 上下文感知:在评估文档相关性时考虑具体查询内容
局限:
- 计算成本高:每个查询-文档对都需要完整的Transformer前向传播
- 无法预计算:必须在查询时实时计算,无法像双编码器那样提前索引
- 扩展性差:对于包含1000个候选文档的查询,需要进行1000次模型推理
2.3 性能对比分析
下表总结了双编码器和交叉编码器在多个维度上的对比:
| 维度 | 双编码器 (Bi-Encoder) | 交叉编码器 (Cross-Encoder) |
|---|---|---|
| 计算复杂度 | O(D + Q) - 线性 | O(D × Q) - 二次方 |
| 推理速度 | 极快 (毫秒级) | 较慢 (秒级) |
| 准确性 | 中等 | 高 |
| 可预计算 | ✓ 支持 | ✗ 不支持 |
| 适用文档数 | 数十亿级 | 数百级 |
| 训练数据需求 | 较高 | 较高 |
| 应用场景 | 第一阶段快速检索 | 第二阶段精准重排序 |
其中,计算复杂度的含义:
- D: 文档数量
- Q: 查询数量
- 双编码器只需计算D个文档向量和Q个查询向量,然后进行向量检索
- 交叉编码器需要为每个查询-文档对进行完整计算
实际性能数据(基于MS MARCO数据集):
- 双编码器(如BGE-large): NDCG@10 ≈ 0.55-0.60
- 交叉编码器(如bge-reranker-large): NDCG@10 ≈ 0.70-0.75
- 提升幅度: 约20-25%
三、两阶段检索系统:完美的结合
理解了双编码器和交叉编码器的特性后,我们可以看到它们天然互补:双编码器快但不够准确,交叉编码器准确但太慢。两阶段检索系统正是结合两者优势的最佳实践。
3.1 系统架构
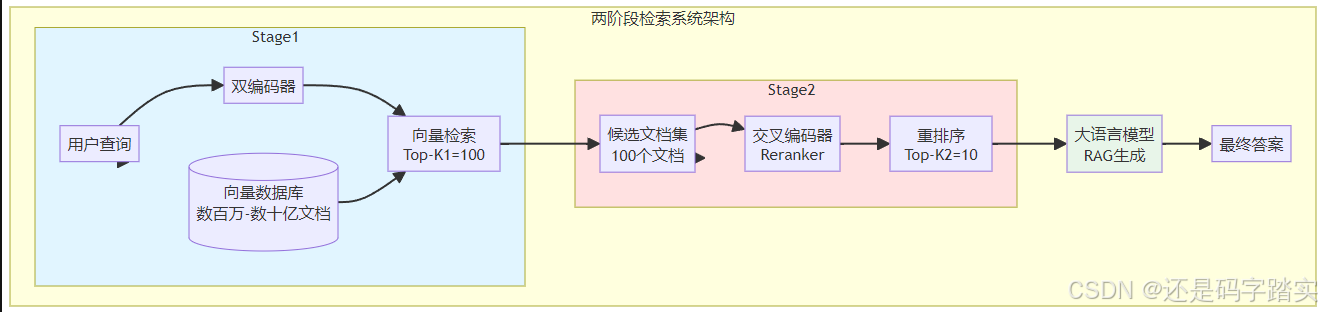
3.2 工作流程详解
3.2.1 第一阶段:快速召回
目标: 从海量文档中快速筛选出可能相关的候选集
步骤:
- 离线处理: 预先使用双编码器对所有文档进行编码,生成向量表示
- 向量索引: 使用专业的向量数据库(如Pinecone、Weaviate、Milvus)建立索引
- 查询编码: 用户查询到来时,使用同一双编码器将查询编码为向量
- 快速检索: 使用近似最近邻(ANN)算法找到Top-K1个最相似的文档向量
关键参数:
- K1值选择: 通常设置为50-100,需要在召回率和计算成本间权衡
- 过小: 可能遗漏相关文档
- 过大: 增加重排序阶段的计算负担
常用ANN算法:
- HNSW (Hierarchical Navigable Small World)
- IVF (Inverted File Index)
- Product Quantization
3.2.2 第二阶段:精准重排序
目标: 对候选文档进行深度相关性分析和重新排序
步骤:
- 输入准备: 将查询与每个候选文档配对
- 批量推理: 使用交叉编码器批量计算相关性分数
- 排序筛选: 根据分数降序排列,选取Top-K2个文档
- 输出: 将最相关的K2个文档传递给LLM
关键参数:
- K2值选择: 通常设置为3-10,取决于LLM的上下文窗口和任务需求
- RAG系统: 3-5个文档通常最优
- 问答系统: 可能需要5-10个文档
- 批量大小(Batch Size): 影响推理效率
- 过小: GPU利用率低
- 过大: 可能超出显存限制
- 典型值: 8-32
3.3 性能提升案例
让我们通过一个实际案例来理解重排序的威力:
场景: 技术文档问答系统
查询: “如何在Elasticsearch中配置API密钥以实现安全访问?”
第一阶段结果(双编码器, Top-10):
| 排名 | 文档标题 | 余弦相似度 |
|---|---|---|
| 1 | Elasticsearch安全配置指南 | 0.74 |
| 2 | API密钥管理最佳实践 | 0.73 |
| 3 | S3存储桶的API密钥配置 | 0.72 |
| 4 | Elasticsearch基础教程 | 0.71 |
| 5 | 数据库访问控制概述 | 0.71 |
| 6 | Couchbase认证机制 | 0.70 |
| 7 | API安全性通用指南 | 0.70 |
| 8 | Elasticsearch索引优化 | 0.69 |
| 9 | 密钥轮换策略 | 0.69 |
| 10 | RESTful API设计规范 | 0.68 |
问题分析:
- 文档3(S3)、文档6(Couchbase): 虽然包含"API密钥"关键词,但与Elasticsearch无关
- 文档4、8、10: 与Elasticsearch相关,但不涉及API密钥配置
- 仅文档1和2真正相关
第二阶段结果(交叉编码器重排序, Top-5):
| 排名 | 文档标题 | 重排序分数 | 原始排名 | 相关性 |
|---|---|---|---|---|
| 1 | Elasticsearch安全配置指南 | 0.92 | 1 | ✓ 高度相关 |
| 2 | API密钥管理最佳实践 | 0.78 | 2 | ✓ 相关 |
| 3 | API安全性通用指南 | 0.65 | 7 | ~ 部分相关 |
| 4 | Elasticsearch基础教程 | 0.52 | 4 | ~ 弱相关 |
| 5 | 数据库访问控制概述 | 0.48 | 5 | ~ 弱相关 |
| – | S3存储桶的API密钥配置 | 0.23 | 3 | ✗ 不相关 |
| – | Couchbase认证机制 | 0.19 | 6 | ✗ 不相关 |
提升效果:
- 精确度提升: 不相关文档(S3、Couchbase)被成功过滤
- 排序优化: 高度相关的文档保持在前列
- 信噪比改善: Top-5中相关文档占比从40%提升到60%
3.4 计算成本分析
假设场景:
- 文档库规模: 1,000,000个文档
- 查询频率: 1,000 QPS (每秒查询数)
- 双编码器参数量: 330M
- 交叉编码器参数量: 330M
第一阶段成本 (双编码器):
- 离线索引: 一次性成本,1M文档 × 单文档编码时间
- 在线查询: 每次查询只需编码查询 + 向量检索
- 延迟: ~10ms
第二阶段成本 (交叉编码器):
- 在线重排序: 每次查询需要对K1个文档进行交叉编码
- 若K1=100: 需要100次模型推理
- 延迟: ~100-500ms (取决于批量大小和硬件)
总体优势:
- 避免了对1M个文档使用交叉编码器(将耗时数小时)
- 仅对100个候选文档重排序(仅需几百毫秒)
- 在速度和准确性间取得最佳平衡
四、重排序的实现方式
重排序技术经历了从传统机器学习模型到深度学习模型,再到大语言模型的演进过程。每种方法都有其独特的优势和适用场景。
4.1 传统交叉编码器重排序
4.1.1 主流模型
目前业界最常用的交叉编码器重排序模型包括:
开源模型:
| 模型名称 | 参数量 | 支持语言 | 最大长度 | NDCG@10 |
|---|---|---|---|---|
| bge-reranker-base | 278M | 多语言 | 512 | 0.67 |
| bge-reranker-large | 560M | 多语言 | 512 | 0.71 |
| bge-reranker-v2-m3 | 568M | 100+语言 | 8192 | 0.74 |
| jina-reranker-v1-base | 137M | 英文 | 8192 | 0.69 |
| jina-reranker-v2-base | 278M | 多语言 | 8192 | 0.72 |
商业API服务:
| 服务商 | 模型名称 | 特点 | 性能 |
|---|---|---|---|
| Cohere | rerank-english-v3.0 | 业界领先准确率 | NDCG@10: ~0.76 |
| Voyage AI | rerank-lite-1 | 平衡性能和成本 | NDCG@10: ~0.70 |
4.1.2 代码实现分析
class CrossReranker(BaseReranker):
def __init__(self, config):
super().__init__(config)
# 加载预训练的tokenizer和模型
self.tokenizer = AutoTokenizer.from_pretrained(self.reranker_model_path)
self.ranker = AutoModelForSequenceClassification.from_pretrained(
self.reranker_model_path,
num_labels=1 # 单标签分类,输出相关性分数
)
self.ranker.eval() # 设置为评估模式
self.ranker.to(self.device) # 转移到指定设备(CPU/GPU)
@torch.no_grad() # 禁用梯度计算,节省内存
def get_rerank_scores(self, query_list, doc_list, batch_size):
# 展平所有查询-文档对
all_pairs = []
for query, docs in zip(query_list, doc_list):
all_pairs.extend([[query, doc] for doc in docs])
all_scores = []
# 批量处理以提高效率
for start_idx in tqdm(range(0, len(all_pairs), batch_size),
desc='Reranking process: '):
pair_batch = all_pairs[start_idx:start_idx + batch_size]
# Tokenization: 将文本对转换为模型输入
inputs = self.tokenizer(
pair_batch,
padding=True, # 填充到批次最大长度
truncation=True, # 截断超长文本
return_tensors='pt', # 返回PyTorch张量
max_length=self.max_length # 最大序列长度
).to(self.device)
# 模型推理
batch_scores = self.ranker(**inputs, return_dict=True)\
.logits.view(-1,).float().cpu()
all_scores.extend(batch_scores)
return all_scores
关键技术点:
- 批量处理:
- 将多个查询-文档对组合成批次
- 充分利用GPU并行计算能力
- 典型批量大小: 16-64 (取决于显存和文档长度)
- 文本处理:
- Padding: 确保批次内所有样本长度一致
- Truncation: 处理超长文档
- 最大长度通常设为512 tokens (BERT标准)或更长(如8192 for modern models)
- 输出处理:
num_labels=1: 输出单个相关性分数(回归任务).logits.view(-1,): 将输出展平为一维分数向量.cpu(): 将结果移回CPU以释放GPU内存
4.1.3 重排序流程
@torch.no_grad()
def rerank(self, query_list, doc_list, batch_size=None, topk=None):
# 参数初始化
if batch_size is None:
batch_size = self.batch_size
if topk is None:
topk = self.topk
# 标准化输入格式
if isinstance(query_list, str):
query_list = [query_list]
if not isinstance(doc_list[0], list):
doc_list = [doc_list]
# 验证输入有效性
assert len(query_list) == len(doc_list)
assert topk < min([len(docs) for docs in doc_list])
# 提取文档内容
doc_contents = []
for docs in doc_list:
doc_contents.append([doc['contents'] for doc in docs])
# 获取所有相关性分数
all_scores = self.get_rerank_scores(query_list, doc_contents, batch_size)
# 对每个查询的文档进行排序
start_idx = 0
final_scores = []
final_docs = []
for docs in doc_list:
# 提取当前查询的分数
doc_scores = all_scores[start_idx:start_idx+len(docs)]
doc_scores = [float(score) for score in doc_scores]
# 降序排序并选取top-k
sort_idxs = np.argsort(doc_scores)[::-1][:topk]
start_idx += len(docs)
# 保存重排序结果
final_docs.append([docs[idx] for idx in sort_idxs])
final_scores.append([doc_scores[idx] for idx in sort_idxs])
return final_docs, final_scores
流程图:
4.2 双编码器重排序(BiReranker)
除了交叉编码器,双编码器也可以用于重排序,尽管准确性稍低,但速度更快:
class BiReranker(BaseReranker):
def __init__(self, config):
super().__init__(config)
self.encoder = Encoder(
model_name = self.reranker_model_name,
model_path = self.reranker_model_path,
pooling_method = config['rerank_pooling_method'],
max_length = self.max_length,
use_fp16 = config['rerank_use_fp16']
)
def get_rerank_scores(self, query_list, doc_list, batch_size):
# 编码查询
query_emb = []
for start_idx in range(0, len(query_list), batch_size):
query_batch = query_list[start_idx:start_idx + batch_size]
batch_emb = self.encoder.encode(query_batch, is_query=True)
query_emb.append(batch_emb)
query_emb = np.concatenate(query_emb, axis=0)
# 编码文档
flat_doc_list = sum(doc_list, [])
doc_emb = []
for start_idx in range(0, len(flat_doc_list), batch_size):
doc_batch = flat_doc_list[start_idx:start_idx + batch_size]
batch_emb = self.encoder.encode(doc_batch, is_query=False)
doc_emb.append(batch_emb)
doc_emb = np.concatenate(doc_emb, axis=0)
# 计算相似度矩阵
scores = query_emb @ doc_emb.T # 矩阵乘法
# 提取每个查询对应的文档分数
all_scores = []
score_idx = 0
for idx, doc in enumerate(doc_list):
all_scores.extend(scores[idx, score_idx:score_idx+len(doc)])
score_idx += len(doc)
return all_scores
BiReranker的特点:
- 优势: 速度快,可以对更多候选文档重排序
- 劣势: 准确性低于CrossReranker
- 适用场景: 需要在极短延迟内处理大量候选文档
4.3 基于大语言模型的重排序
随着大语言模型(LLM)的兴起,研究者们开始探索使用LLM进行重排序的新方法。这些方法分为三类:
4.3.1 Pointwise (逐点法)
原理: 让LLM为每个查询-文档对单独打分
Prompt示例:
Given a query and a document, rate their relevance on a scale from 1-10.
Query: How to configure API keys in Elasticsearch?
Document: Elasticsearch security features include role-based access control...
Relevance score:
优劣分析:
- ✓ 简单易实现
- ✓ 可并行处理
- ✗ 忽略文档间的相对关系
- ✗ 效率较低(需要N次LLM调用)
4.3.2 Pairwise (成对法)
原理: 让LLM比较两个文档,判断哪个更相关
Prompt示例:
Given a query and two documents, which document is more relevant?
Query: How to configure API keys in Elasticsearch?
Document A: [Content A]
Document B: [Content B]
Which is more relevant? Answer 'A' or 'B'.
排序算法: 使用比较结果构建排序,常用算法包括:
- Bubble Sort
- Heap Sort
- Tournament Sort
优劣分析:
- ✓ 考虑文档间相对关系
- ✗ 复杂度O(N²),需要N(N-1)/2次比较
- ✗ 比较结果可能不一致(A>B, B>C, C>A)
4.3.3 Listwise (列表法) - RankGPT
原理: 让LLM直接对整个文档列表进行排序
RankGPT的创新:
- 滑动窗口策略: 解决LLM上下文长度限制
- 排列生成方法: 让LLM输出文档ID的排列
工作流程:
Prompt示例 (RankGPT):
You are RankLLM, an intelligent assistant that ranks passages based on relevance.
Query: How to configure API keys in Elasticsearch?
Passages:
[1] Elasticsearch security features include...
[2] API keys provide secure access to...
[3] S3 bucket configuration requires...
[4] To configure Elasticsearch API keys, first...
Rank the passages by relevance to the query. Output the ranking as: [4] > [2] > [1] > [3]
优劣分析:
- ✓ 整体考虑所有文档
- ✓ 利用LLM的推理能力
- ✓ 零样本或少样本即可工作
- ✗ 成本高(需要调用GPT-4等大模型)
- ✗ 延迟高(生成排列需要时间)
- ✗ 上下文长度限制(需要滑动窗口)
4.3.4 蒸馏方法:RankZephyr和RankVicuna
为了降低LLM重排序的成本,研究者提出了知识蒸馏方法:
训练流程:
- 使用RankGPT (GPT-3.5或GPT-4)对大量查询生成排序结果
- 将这些排序结果作为训练数据
- 训练小型开源模型(如Zephyr 7B, Vicuna 7B)
- 得到的模型可以在本地部署,成本大幅降低
性能对比:
| 模型 | 参数量 | NDCG@10 | 延迟 | 成本 |
|---|---|---|---|---|
| RankGPT-4 | 未知 | 0.74 | 高 | 高 |
| RankGPT-3.5 | 未知 | 0.71 | 中 | 中 |
| RankZephyr | 7B | 0.70 | 低 | 低 |
| RankVicuna | 7B | 0.68 | 低 | 低 |
| BGE-reranker-large | 560M | 0.71 | 很低 | 很低 |
结论: 蒸馏后的7B模型能够接近GPT-3.5的性能,但成本和延迟大幅降低。
4.4 混合和增强方法
4.4.1 Reciprocal Rank Fusion (RRF)
当有多个检索器时,可以使用RRF融合结果:
RRF ( d ) = ∑ r ∈ R 1 k + r ( d ) \text{RRF}(d) = \sum_{r \in R} \frac{1}{k + r(d)} RRF(d)=r∈R∑k+r(d)1
其中:
- R R R 是所有检索器的集合
- r ( d ) r(d) r(d) 是文档 d d d在检索器 r r r中的排名
- k k k 是平滑参数(通常为60)
4.4.2 最大边际相关性(MMR)
MMR在保证相关性的同时增加结果多样性:
MMR = arg max d i ∈ R \ S [ λ ⋅ sim ( q , d i ) − ( 1 − λ ) ⋅ max d j ∈ S sim ( d i , d j ) ] \text{MMR} = \arg\max_{d_i \in R \backslash S} [\lambda \cdot \text{sim}(q, d_i) - (1-\lambda) \cdot \max_{d_j \in S} \text{sim}(d_i, d_j)] MMR=argdi∈R\Smax[λ⋅sim(q,di)−(1−λ)⋅dj∈Smaxsim(di,dj)]
其中:
- λ \lambda λ 控制相关性和多样性的权衡
- S S S 是已选择的文档集合
- R R R 是候选文档集合
五、何时使用Rerank及其效果分析
5.1 何时应该使用Rerank
重排序并非万能药,以下场景下使用重排序能够带来显著提升:
5.1.1 强烈推荐使用的场景
1. 高准确性要求的应用
- 示例: 医疗问答、法律咨询、金融分析
- 原因: 这些领域容不得半点错误,重排序能够大幅提升相关性
- 提升幅度: NDCG@10 通常提升10-20%
2. 语义复杂的查询
- 示例: “比较Python和JavaScript在异步编程方面的优劣”
- 原因: 这类查询需要深度理解上下文,交叉编码器更擅长处理
- 对比:
- 双编码器可能混淆"异步编程"和"编程语言比较"
- 交叉编码器能准确理解"比较"+"异步"的组合意图
3. 长查询或长文档
- 示例: 用户提供了详细的问题描述或需要处理长篇文档
- 原因: 双编码器难以将长文本的所有信息压缩到固定维度向量中
- 建议: 使用支持长上下文的reranker(如8192 tokens)
4. 跨领域或专业领域
- 示例: 生物医学、法律、金融等专业领域
- 原因: 通用嵌入模型可能无法准确捕捉领域特定术语
- 解决方案:
- 使用领域微调的reranker
- 或使用LLM-based reranker(更强的zero-shot能力)
5. 多语言或跨语言检索
- 示例: 用中文查询检索英文文档
- 原因: 多语言reranker能更好地理解语言间的语义对应
- 推荐模型: bge-reranker-v2-m3 (支持100+语言)
5.1.2 效果可能有限的场景
1. 事实查询(Factoid Queries)
- 示例: “埃菲尔铁塔有多高?”
- 原因: 此类查询通常有明确答案,向量检索已经足够准确
- 建议: 可以跳过重排序,节省计算资源
2. 小规模文档库
- 示例: 少于1000个文档的知识库
- 原因:
- 向量检索已经能返回大部分相关文档
- 重排序的边际效益较小
- 建议: 除非准确性要求极高,否则不必使用reranker
3. 实时性要求极高的场景
- 示例: 毫秒级响应要求的在线推荐系统
- 原因: Reranker会增加100-500ms延迟
- 替代方案:
- 使用更强的双编码器模型
- 或使用轻量级reranker(如BiReranker)
4. 初始检索质量已经很好
- 判断标准: 如果向量检索的NDCG@10 > 0.7
- 原因: 重排序的提升空间有限(通常<5%)
- 建议: 进行A/B测试验证是否值得增加reranker
5.1.3 决策树
5.2 效果提升的量化分析
5.2.1 基准测试结果
基于多个公开数据集的测试结果:
MS MARCO Passage Ranking:
| 方法 | NDCG@10 | MRR@10 | Recall@100 |
|---|---|---|---|
| BM25 (稀疏检索) | 0.18 | 0.16 | 0.62 |
| BGE-large (双编码器) | 0.56 | 0.52 | 0.86 |
| + BGE-reranker-base | 0.67 | 0.63 | 0.86 |
| + BGE-reranker-large | 0.71 | 0.67 | 0.86 |
| + Cohere-rerank-v3 | 0.76 | 0.72 | 0.86 |
提升幅度:
- 相对于双编码器: +27% (large) 到 +36% (Cohere)
- 相对于BM25: +295% (large) 到 +322% (Cohere)
BEIR基准测试 (跨域泛化能力):
| 数据集 | 双编码器 | + Reranker | 相对提升 |
|---|---|---|---|
| NFCorpus | 0.32 | 0.38 | +18.8% |
| SciFact | 0.65 | 0.71 | +9.2% |
| FiQA | 0.38 | 0.44 | +15.8% |
| ArguAna | 0.42 | 0.49 | +16.7% |
| 平均 | 0.44 | 0.51 | +15.9% |
LlamaIndex RAG评估 (端到端RAG系统):
| 嵌入模型 | 无Reranker | + BGE-large | + Cohere |
|---|---|---|---|
| OpenAI | Hit Rate: 0.797 MRR: 0.531 | 0.910 0.856 | 0.927 0.866 |
| BGE-large | 0.764 0.548 | 0.876 0.823 | 0.876 0.823 |
| Jina-v2 | 0.809 0.587 | 0.938 0.869 | 0.933 0.874 |
关键发现:
- Hit Rate提升: 平均提升14-19%
- MRR提升: 平均提升33-61%
- 嵌入模型不敏感: 即使使用不同嵌入模型,reranker都能带来显著提升
5.2.2 实际应用案例
案例1: 企业知识库问答系统
背景:
- 文档数量: 50,000篇内部技术文档
- 查询类型: 技术问题、最佳实践、故障排查
实验设置:
- 基线: OpenAI ada-002 + Top-10检索
- 优化: + Cohere rerank-v3 + Top-3输出
结果:
| 指标 | 基线 | +Reranker | 提升 |
|---|---|---|---|
| 答案准确率 | 68% | 87% | +19% |
| 平均响应时间 | 1.2s | 1.6s | +0.4s |
| 用户满意度 | 3.4/5 | 4.3/5 | +26% |
| 幻觉率 | 18% | 7% | -61% |
分析:
- 准确率大幅提升源于更相关的上下文
- 幻觉率降低因为过滤了误导性文档
- 虽然延迟增加400ms,但用户体验整体改善
案例2: 电商产品推荐
背景:
- 产品数量: 1,000,000
- 任务: 根据用户查询推荐最相关产品
实验设置:
- 第一阶段: 向量检索Top-100
- 第二阶段: Cross-encoder重排序Top-10
结果:
| 指标 | 仅向量检索 | +Reranker |
|---|---|---|
| 点击率(CTR) | 2.3% | 3.1% |
| 转化率 | 0.8% | 1.2% |
| 平均客单价 | $45 | $52 |
| 每次查询延迟 | 80ms | 250ms |
ROI分析:
- CTR提升34.8% → 更多用户交互
- 转化率提升50% → 直接增加收入
- 延迟增加170ms,但可接受(仍<500ms)
- 整体ROI: 收入增加远超算力成本
5.3 何时效果不佳
5.3.1 负面案例分析
案例: 新闻标题检索
场景:
- 任务: 根据关键词检索新闻标题
- 文档: 短文本(标题,通常<20词)
结果:
| 方法 | NDCG@10 |
|---|---|
| BM25 | 0.72 |
| 双编码器 | 0.69 |
| + Reranker | 0.70 |
分析:
- 文本过短: 标题信息密度高但长度短,交叉编码器无法充分发挥优势
- 关键词匹配更重要: 在短文本场景,精确的词汇匹配比语义理解更重要
- BM25更优: 传统稀疏检索在此场景下反而最有效
5.3.2 Reranker失效的原因
1. 训练数据偏差
- 如果reranker的训练数据与应用场景差异大,效果会下降
- 例如: 用通用数据训练的模型在医学领域可能表现不佳
2. 初始检索质量太差
- 如果第一阶段检索的Top-100中几乎没有相关文档
- Reranker也无法"无中生有"
- 解决方案: 提升初始检索质量或增加K1值
3. 查询-文档不匹配
- 某些查询类型本身就难以匹配
- 例如: 用非常抽象的查询检索具体技术文档
4. 模型容量不足
- 小型reranker(如base-sized models)可能难以处理复杂场景
- 解决方案: 使用更大的模型或LLM-based reranker
5.4 最佳实践建议
5.4.1 配置参数调优
K1 (第一阶段检索数量):
# 经验法则
if corpus_size < 10000:
K1 = 50
elif corpus_size < 100000:
K1 = 100
else:
K1 = 200
# 考虑计算预算
if latency_requirement < 200ms:
K1 = min(K1, 50)
K2 (最终输出数量):
# 根据LLM上下文窗口
if LLM_context_window < 4096:
K2 = 3
elif LLM_context_window < 8192:
K2 = 5
else:
K2 = 10
# 考虑LLM性能退化
# "Lost in the Middle" 现象: LLM对中间文档关注度低
K2 = min(K2, 5) # 保守选择
Batch Size:
# GPU显存优化
if model_size < 500M:
batch_size = 32
elif model_size < 2B:
batch_size = 16
else:
batch_size = 8
# 根据文档长度调整
if avg_doc_length > 1000:
batch_size //= 2
5.4.2 混合策略
策略1: 分层重排序
# 第一层: 快速过滤 (BiReranker)
candidates = bi_reranker.rerank(query, docs, topk=50)
# 第二层: 精准排序 (CrossReranker)
final_docs = cross_reranker.rerank(query, candidates, topk=10)
策略2: 阈值过滤
# 使用重排序分数阈值
reranked_docs, scores = reranker.rerank(query, docs)
# 只保留分数高于阈值的文档
filtered_docs = [
doc for doc, score in zip(reranked_docs, scores)
if score > 0.5 # 阈值需要根据模型调整
]
# 如果过滤后文档不足,保留Top-K
if len(filtered_docs) < 3:
filtered_docs = reranked_docs[:3]
策略3: 多模型集成
# 使用多个reranker投票
scores_1 = reranker_1.get_scores(query, docs)
scores_2 = reranker_2.get_scores(query, docs)
# 加权融合
final_scores = 0.6 * scores_1 + 0.4 * scores_2
# 或使用RRF
final_ranking = reciprocal_rank_fusion([
rank_by_scores(scores_1),
rank_by_scores(scores_2)
])
六、性能优化与工程实践
6.1 延迟优化
6.1.1 批量推理优化
重排序的主要瓶颈在于需要对大量查询-文档对进行推理。优化批量大小至关重要:
动态批量调整:
def optimize_batch_size(model, device, doc_lengths):
"""根据文档长度动态调整批量大小"""
avg_length = np.mean(doc_lengths)
if device == "cuda":
gpu_memory = torch.cuda.get_device_properties(0).total_memory
available_memory = gpu_memory * 0.7 # 预留30%
# 估算单个样本的内存需求
memory_per_sample = avg_length * model_size * 4 # 4 bytes per float
optimal_batch = int(available_memory / memory_per_sample)
# 限制范围
return max(4, min(optimal_batch, 64))
else:
return 8 # CPU默认较小批量
# 使用示例
batch_size = optimize_batch_size(reranker.model, device, doc_lengths)
6.1.2 模型量化
使用半精度(FP16)或8位量化(INT8)可以显著减少内存占用和推理时间:
FP16推理:
from torch.cuda.amp import autocast
class OptimizedCrossReranker(CrossReranker):
@torch.no_grad()
def get_rerank_scores(self, query_list, doc_list, batch_size):
all_scores = []
with autocast(): # 自动混合精度
for start_idx in range(0, len(all_pairs), batch_size):
pair_batch = all_pairs[start_idx:start_idx + batch_size]
inputs = self.tokenizer(...).to(self.device)
# FP16推理
batch_scores = self.ranker(**inputs).logits
all_scores.extend(batch_scores.float().cpu())
return all_scores
效果:
- 内存占用: 减少约50%
- 推理速度: 提升30-50%
- 准确性损失: 通常<1%
6.1.3 缓存策略
对于重复查询,缓存可以显著减少重复计算:
from functools import lru_cache
import hashlib
class CachedReranker:
def __init__(self, reranker, cache_size=10000):
self.reranker = reranker
self.cache = {}
self.cache_size = cache_size
def _get_cache_key(self, query, doc_ids):
"""生成缓存键"""
content = query + "".join(doc_ids)
return hashlib.md5(content.encode()).hexdigest()
def rerank(self, query, docs):
doc_ids = [doc['id'] for doc in docs]
cache_key = self._get_cache_key(query, doc_ids)
# 检查缓存
if cache_key in self.cache:
return self.cache[cache_key]
# 执行重排序
result = self.reranker.rerank(query, docs)
# 存入缓存(使用LRU策略)
if len(self.cache) >= self.cache_size:
# 删除最旧的条目
oldest_key = next(iter(self.cache))
del self.cache[oldest_key]
self.cache[cache_key] = result
return result
6.2 成本分析
6.2.1 计算成本对比
假设:
- 查询频率: 1000 QPS
- 文档库: 10M文档
- 第一阶段返回: Top-100
- 重排序输出: Top-10
方案对比:
| 方案 | 每次查询推理次数 | GPU利用率 | 单GPU支持QPS | 成本/月(AWS p3.2xlarge) |
|---|---|---|---|---|
| 无重排序 | 0 | N/A | N/A | $0 |
| BGE-reranker-base | 100 | 40% | ~50 | $ 7,300 × 20 ≈ $146,000 |
| BGE-reranker-large | 100 | 60% | ~30 | $ 7,300 × 33 ≈ $241,000 |
| Cohere API | 100 | N/A | ~500 | $ 0.002/次 × 100 × 86M = $17,200 |
结论:
- 对于高QPS应用,商业API可能更经济
- 对于中小规模或隐私敏感应用,自部署更优
6.2.2 成本优化策略
1. 选择性重排序:
def selective_rerank(query, docs, reranker):
"""仅对不确定的结果进行重排序"""
# 计算初始分数的分布
scores = [doc['score'] for doc in docs]
score_std = np.std(scores)
# 如果分数差异明显,跳过重排序
if score_std > 0.15: # 阈值需调优
return docs[:10]
# 否则进行重排序
return reranker.rerank(query, docs, topk=10)
2. 分时段策略:
# 高峰期使用轻量级reranker
if is_peak_hour():
reranker = bi_reranker
else:
reranker = cross_reranker
3. 渐进式重排序:
# 首先用快速方法筛选到Top-30
candidates = bi_reranker.rerank(query, docs, topk=30)
# 再用精确方法筛选到Top-10
final = cross_reranker.rerank(query, candidates, topk=10)
6.3 监控与评估
6.3.1 关键指标
准确性指标:
- NDCG@K: 归一化折损累计增益
- MRR: 平均倒数排名
- Hit Rate@K: 前K个结果中包含相关文档的比例
- Precision@K: 前K个结果中相关文档的比例
系统指标:
- 延迟: P50, P95, P99
- 吞吐量: QPS
- 资源利用率: GPU/CPU, 内存
业务指标:
- 用户满意度: 点击率, 停留时间
- 转化率: 对于商业应用
- 重查询率: 用户是否需要修改查询
6.3.2 A/B测试框架
class RerankerABTest:
def __init__(self, control_reranker, treatment_reranker,
split_ratio=0.5):
self.control = control_reranker
self.treatment = treatment_reranker
self.split_ratio = split_ratio
self.metrics = {'control': [], 'treatment': []}
def process_query(self, query, docs):
# 随机分组
if random.random() < self.split_ratio:
variant = 'control'
results = self.control.rerank(query, docs)
else:
variant = 'treatment'
results = self.treatment.rerank(query, docs)
# 记录实验组
return results, variant
def evaluate_metrics(self, variant, true_relevance, predicted_ranking):
"""计算并记录指标"""
ndcg = calculate_ndcg(true_relevance, predicted_ranking)
mrr = calculate_mrr(true_relevance, predicted_ranking)
self.metrics[variant].append({
'ndcg': ndcg,
'mrr': mrr,
'timestamp': time.time()
})
def statistical_test(self):
"""统计显著性检验"""
control_ndcg = [m['ndcg'] for m in self.metrics['control']]
treatment_ndcg = [m['ndcg'] for m in self.metrics['treatment']]
from scipy.stats import ttest_ind
t_stat, p_value = ttest_ind(control_ndcg, treatment_ndcg)
return {
'p_value': p_value,
'significant': p_value < 0.05,
'control_mean': np.mean(control_ndcg),
'treatment_mean': np.mean(treatment_ndcg),
'lift': (np.mean(treatment_ndcg) - np.mean(control_ndcg)) / np.mean(control_ndcg)
}
6.4 错误案例分析
建立错误案例库并进行分析是持续改进的关键:
class RerankerErrorAnalyzer:
def __init__(self):
self.error_cases = []
def log_error(self, query, docs, reranked_docs,
true_relevance, reranker_scores):
"""记录重排序失败的案例"""
# 检测错误类型
error_type = self._classify_error(
docs, reranked_docs, true_relevance
)
self.error_cases.append({
'query': query,
'error_type': error_type,
'initial_ranking': [doc['id'] for doc in docs],
'reranked_ranking': [doc['id'] for doc in reranked_docs],
'true_relevance': true_relevance,
'reranker_scores': reranker_scores,
'timestamp': time.time()
})
def _classify_error(self, docs, reranked_docs, true_relevance):
"""分类错误类型"""
# 检查是否有相关文档被降级
initial_top3_relevant = sum(true_relevance[:3])
reranked_top3_relevant = sum([
true_relevance[i] for i in [
docs.index(doc) for doc in reranked_docs[:3]
]
])
if reranked_top3_relevant < initial_top3_relevant:
return "relevant_document_demoted"
# 检查是否有不相关文档被提升
if reranked_top3_relevant == 0 and initial_top3_relevant > 0:
return "irrelevant_document_promoted"
return "other"
def analyze_patterns(self):
"""分析错误模式"""
error_types = [case['error_type'] for case in self.error_cases]
from collections import Counter
error_distribution = Counter(error_types)
# 按查询类型分析
query_patterns = self._extract_query_patterns()
return {
'error_distribution': error_distribution,
'query_patterns': query_patterns,
'total_errors': len(self.error_cases)
}
七、常见模型与性能对比
7.1 主流Reranker模型
7.1.1 BAAI BGE系列
BGE (BAAI General Embedding) 是北京智源人工智能研究院开发的系列模型:
模型对比:
| 模型 | 参数 | 最大长度 | 语言 | NDCG@10 | 推理速度 |
|---|---|---|---|---|---|
| bge-reranker-base | 278M | 512 | 多语言 | 0.67 | 快 |
| bge-reranker-large | 560M | 512 | 多语言 | 0.71 | 中等 |
| bge-reranker-v2-m3 | 568M | 8192 | 100+ | 0.74 | 中等 |
| bge-reranker-v2-gemma | 2B | 8192 | 多语言 | 0.76 | 慢 |
| bge-reranker-v2-minicpm | 2.4B | 8192 | 多语言 | 0.77 | 慢 |
特点:
- 开源免费: 可本地部署
- 多语言支持: 尤其对中文支持好
- 持续更新: 定期发布新版本
- 易于微调: 提供完整训练代码
使用示例:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "BAAI/bge-reranker-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
model.eval()
pairs = [
["query", "document1"],
["query", "document2"]
]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True,
return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1,).float()
print(scores)
7.1.2 Jina AI Reranker
特点:
- 长上下文: 支持8192 tokens
- 嵌入无关: 可与任何embedding模型配合
- 高性能: 在多个基准测试中表现优异
性能数据 (基于LlamaIndex评估):
| 嵌入模型 | 无Reranker | + Jina Reranker | 提升 |
|---|---|---|---|
| OpenAI | HR: 0.791, MRR: 0.531 | HR: 0.855, MRR: 0.709 | HR: +8%, MRR: +34% |
| BGE-large | HR: 0.764, MRR: 0.548 | HR: 0.837, MRR: 0.694 | HR: +10%, MRR: +27% |
7.1.3 Cohere Rerank
商业模型,但性能领先:
版本对比:
| 版本 | 发布时间 | NDCG@10 | 延迟 | 价格 |
|---|---|---|---|---|
| rerank-english-v2.0 | 2023-06 | 0.72 | 中 | $0.002/次 |
| rerank-english-v3.0 | 2024-01 | 0.76 | 低 | $0.002/次 |
| rerank-multilingual-v3.0 | 2024-01 | 0.74 | 低 | $0.002/次 |
优势:
- 最高准确率: 在多个基准测试中排名第一
- 低延迟: v3版本大幅优化速度
- 支持半结构化数据: 可处理JSON等格式
- 无需部署: API调用即可使用
使用示例:
import cohere
co = cohere.Client('YOUR_API_KEY')
results = co.rerank(
query="How to configure API keys in Elasticsearch?",
documents=[
"Elasticsearch security features...",
"API keys provide secure access...",
"S3 bucket configuration..."
],
top_n=3,
model="rerank-english-v3.0"
)
for hit in results:
print(f"Document: {hit.document['text']}")
print(f"Relevance Score: {hit.relevance_score}")
7.1.4 NV-RerankQA (NVIDIA)
特点:
- 基于Mistral-4B: 使用先进的LLM架构
- 针对QA优化: 专为问答任务设计
- 高准确率: 在多个基准测试中领先
性能:
- NDCG@10: 0.78 (比第二名高14%)
- 延迟: ~266ms (对40个候选文档)
训练方法:
- 使用InfoNCE损失
- 对比学习 + 困难负样本挖掘
- 模型裁剪(从7B减至4B参数)
7.2 综合性能对比
7.2.1 MTEB排行榜(部分)
Reranking任务 (2024年10月数据):
| 排名 | 模型 | 平均分 | AskUbuntu | StackOverflow | 备注 |
|---|---|---|---|---|---|
| 1 | Cohere rerank-v3 | 62.89 | 71.23 | 68.45 | 商业 |
| 2 | NV-RerankQA-4B | 61.72 | 69.87 | 67.12 | 开源 |
| 3 | bge-reranker-v2-minicpm | 60.95 | 68.54 | 66.23 | 开源 |
| 4 | bge-reranker-v2-gemma | 60.21 | 67.89 | 65.67 | 开源 |
| 5 | jina-reranker-v2 | 59.87 | 67.12 | 65.01 | 开源 |
7.2.2 实际应用场景对比
场景1: 技术文档搜索 (英文为主)
| 模型 | NDCG@10 | 延迟(ms) | 成本/月 | 推荐度 |
|---|---|---|---|---|
| bge-reranker-base | 0.68 | 120 | $2,000 | ⭐⭐⭐ |
| bge-reranker-large | 0.72 | 180 | $3,500 | ⭐⭐⭐⭐ |
| Cohere v3 | 0.76 | 90 | $5,000 | ⭐⭐⭐⭐⭐ |
| jina-reranker-v2 | 0.70 | 150 | $2,500 | ⭐⭐⭐⭐ |
场景2: 多语言客服系统
| 模型 | NDCG@10 | 中文支持 | 成本/月 | 推荐度 |
|---|---|---|---|---|
| bge-reranker-v2-m3 | 0.74 | 优秀 | $3,000 | ⭐⭐⭐⭐⭐ |
| Cohere multilingual | 0.73 | 良好 | $5,500 | ⭐⭐⭐⭐ |
| jina-reranker-v2 | 0.71 | 良好 | $2,500 | ⭐⭐⭐⭐ |
场景3: 实时推荐系统 (延迟<100ms)
| 模型 | NDCG@10 | 延迟(ms) | 推荐度 | 备注 |
|---|---|---|---|---|
| bge-reranker-base | 0.68 | 80 | ⭐⭐⭐⭐ | 使用FP16 |
| BiReranker | 0.62 | 50 | ⭐⭐⭐ | 速度优先 |
| Cohere v3 | 0.76 | 90 | ⭐⭐⭐⭐⭐ | API延迟优化 |
7.3 模型选择指南
决策因素总结:
- 预算优先级:
- 高预算: Cohere (最佳性能)
- 中预算: Jina或BGE-large
- 低预算: BGE-base
- 语言需求:
- 仅英文: Cohere v3或NV-RerankQA
- 多语言: BGE-v2-m3或Cohere multilingual
- 重视中文: BGE系列
- 延迟容忍度:
- <100ms: BGE-base或BiReranker
- 100-200ms: BGE-large或Jina-v2
200ms: 可选择LLM-based或最大模型
- 部署方式:
- 云API: Cohere或Voyage
- 本地部署: BGE或Jina(开源)
- 混合: 开源模型 + 特殊场景API
八、未来发展趋势
8.1 技术演进方向
8.1.1 更长上下文支持
当前大多数reranker限制在512-1024 tokens,但实际应用常需要处理更长文档:
发展趋势:
- BGE-v2-m3: 已支持8192 tokens
- 基于LLM的reranker: 可利用100K+上下文窗口
- 挑战: 更长上下文意味着更高计算成本
解决方案:
- 稀疏注意力机制
- 层次化编码策略
- 高效的长序列建模
8.1.2 多模态重排序
未来的reranker需要处理图文混合内容:
应用场景:
- 电商搜索: 图片+描述文本
- 多媒体检索: 视频+字幕+音频
- 科学文献: 图表+正文
技术方向:
- CLIP-based cross-encoders
- 视觉-语言联合建模
- 跨模态注意力机制
8.1.3 个性化重排序
考虑用户历史和偏好的重排序:
class PersonalizedReranker:
def rerank(self, query, docs, user_profile):
# 融合用户偏好
base_scores = self.base_reranker.get_scores(query, docs)
user_scores = self.user_model.predict(user_profile, docs)
# 个性化融合
final_scores = 0.7 * base_scores + 0.3 * user_scores
return self.sort_by_scores(docs, final_scores)
8.2 效率优化
8.2.1 模型压缩技术
知识蒸馏:
- 使用大模型教师指导小模型学生
- RankZephyr/RankVicuna的成功案例
- 可将模型大小减少10x,性能仅损失5%
剪枝和量化:
- INT8量化: 速度提升2x,准确率损失<1%
- 结构化剪枝: 减少冗余参数
- NV-RerankQA: 从7B剪枝至4B
8.2.2 早停策略
不是所有文档都需要完整的重排序:
def early_stopping_rerank(query, docs, reranker, threshold=0.1):
"""如果初始分数已经很明确,则跳过重排序"""
initial_scores = [doc['initial_score'] for doc in docs]
score_gap = max(initial_scores) - np.median(initial_scores)
if score_gap > threshold:
# 初始排序已经很明确
return sorted(docs, key=lambda x: x['initial_score'], reverse=True)
else:
# 需要重排序
return reranker.rerank(query, docs)
8.3 开放性挑战
8.3.1 领域适应
通用reranker在特定领域(如医学、法律)效果可能不佳:
解决方案:
- 领域微调: 使用少量领域数据微调
- 提示工程: 对LLM-based reranker使用领域特定提示
- 混合检索: 结合领域关键词和语义检索
8.3.2 可解释性
当前reranker大多是黑盒:
改进方向:
- 注意力可视化: 展示模型关注的关键词
- 决策解释: 说明为什么某文档排名高
- 对比分析: 解释文档间的相对排序
示例实现:
def explain_reranking(query, doc_a, doc_b, reranker):
"""解释为什么doc_a排名高于doc_b"""
# 获取注意力权重
attention_a = reranker.get_attention(query, doc_a)
attention_b = reranker.get_attention(query, doc_b)
# 识别关键匹配
key_terms_a = extract_high_attention_terms(query, doc_a, attention_a)
key_terms_b = extract_high_attention_terms(query, doc_b, attention_b)
explanation = f"""
Document A ranks higher because:
- Stronger match on terms: {key_terms_a}
- Overall relevance score: {score_a:.3f} vs {score_b:.3f}
Document B focuses more on: {key_terms_b}
"""
return explanation
九、总结与建议
9.1 核心要点回顾
重排序的本质:
- 是信息检索系统中的精准筛选环节
- 通过深度语义分析提升检索准确率
- 在速度和准确性间取得平衡的关键技术
双编码器vs交叉编码器:
| 特性 | 双编码器 | 交叉编码器 |
|---|---|---|
| 核心优势 | 速度快、可扩展 | 准确率高 |
| 核心劣势 | 准确率低 | 计算慢 |
| 典型应用 | 第一阶段召回 | 第二阶段重排序 |
何时使用:
- ✓ 语义复杂的查询
- ✓ 高准确性要求
- ✓ 长文本或长查询
- ✓ 专业领域应用
- ✗ 简单事实查询
- ✗ 极低延迟要求(<50ms)
- ✗ 小规模文档库
效果提升:
- NDCG@10: 平均提升15-30%
- 幻觉率: 降低40-60%
- 用户满意度: 提升20-30%
9.2.1 常见陷阱避免
陷阱1: 盲目追求最大模型
# ❌ 错误: 不考虑延迟直接用最大模型
reranker = load_model("bge-reranker-v2-minicpm-2.4B")
# ✓ 正确: 根据延迟需求选择
if latency_requirement < 150:
reranker = load_model("bge-reranker-base")
elif latency_requirement < 300:
reranker = load_model("bge-reranker-large")
else:
reranker = load_model("bge-reranker-v2-m3")
陷阱2: 忽略批量大小
# ❌ 错误: 固定批量大小
BATCH_SIZE = 32 # 可能导致OOM或GPU利用率低
# ✓ 正确: 动态调整
batch_size = estimate_optimal_batch_size(
model=reranker,
avg_doc_length=avg_length,
available_memory=gpu_memory
)
陷阱3: 过度依赖重排序
# ❌ 错误: 期望reranker解决所有问题
# 如果初始检索质量很差,reranker也无能为力
# ✓ 正确: 先优化初始检索
if initial_ndcg < 0.4:
print("Warning: Initial retrieval quality too low")
print("Consider: Better embeddings, hybrid search, query expansion")
陷阱4: 忘记缓存
# ❌ 错误: 重复查询都重新计算
for query in repeated_queries:
results = reranker.rerank(query, docs)
# ✓ 正确: 使用缓存
cached_reranker = CachedReranker(reranker, cache_size=10000)
for query in repeated_queries:
results = cached_reranker.rerank(query, docs)
9.3 展望未来
重排序技术正在快速演进,未来几年我们将看到:
- 更智能的模型: LLM与专用reranker的融合
- 更高的效率: 通过模型压缩和硬件优化实现实时重排序
- 更强的泛化: 零样本和少样本能力持续提升
- 更好的可解释性: 用户能理解为什么某些结果排名更高
对于工程师和研究者:
- 关注最新的模型发布(MTEB排行榜)
- 参与开源社区(HuggingFace, GitHub)
- 进行充分的A/B测试
- 平衡准确性、延迟和成本
重排序不是银弹,但在正确的场景下,它能显著提升RAG系统的性能,是值得投资的技术方向。
十、参考文献
学术论文
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019)
- Nils Reimers, Iryna Gurevych
- https://arxiv.org/abs/1908.10084
- 介绍了双编码器架构的基础
- Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents (2023)
- Weiwei Sun et al. (RankGPT)
- https://arxiv.org/abs/2304.09542
- 首次系统研究LLM用于重排序
- Lost in the Middle: How Language Models Use Long Contexts (2023)
- Nelson F. Liu et al.
- https://arxiv.org/abs/2307.03172
- 揭示了LLM对长上下文中间部分的注意力问题
- Fine-Tuning LLaMA for Multi-Stage Text Retrieval (2023)
- Xueguang Ma et al. (RankVicuna, RankZephyr)
- https://arxiv.org/abs/2310.08319
- 知识蒸馏方法训练小型listwise reranker
- BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings (2024)
- Jianlv Chen et al.
- https://arxiv.org/abs/2402.03216
- 介绍了支持超长上下文的多语言reranker
技术博客与文档
- The Art of RAG Part 3: Reranking with Cross Encoders - Medium
- Rerankers and Two-Stage Retrieval - Pinecone
- Cross-Encoders Documentation - Sentence Transformers
- Using Cross-Encoders as Reranker - Weaviate
- Boosting RAG: Picking the Best Embedding & Reranker Models - LlamaIndex
开源项目
- BAAI/FlagEmbedding - GitHub
- https://github.com/FlagOpen/FlagEmbedding
- BGE系列模型的官方实现
- RankLLM - GitHub
- https://github.com/castorini/rank_llm
- 支持多种LLM-based重排序方法
- LLM-Rankers - GitHub
- https://github.com/ielab/llm-rankers
- Pointwise, Pairwise, Listwise方法实现
- Sentence Transformers - GitHub
- https://github.com/UKPLab/sentence-transformers
- 双编码器和交叉编码器的标准库
商业文档
- Cohere Rerank API Documentation
- https://docs.cohere.com/reference/rerank
- 商业reranker API文档
- Jina AI Reranker
- NVIDIA NV-RerankQA Technical Report (2024)
- https://arxiv.org/abs/2409.07691
- NVIDIA基于Mistral的reranker技术报告
基准测试
- MTEB Leaderboard - Hugging Face
- https://huggingface.co/spaces/mteb/leaderboard
- 文本嵌入和重排序模型的权威排行榜
- BEIR Benchmark
- https://github.com/beir-cellar/beir
- 跨域检索任务评测基准

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)