Jina.AI DeepSearch
Jina.AI DeepSearch是一个多阶段研究优化系统,通过结构化流程进行深度信息检索与分析。系统首先进行参数预处理和语言/Schema初始化,随后构建上下文容器与生成器。核心采用主循环机制,包含"计划→行动→评估→记忆"的状态机流程,支持五种主要动作:访问网页(visit)、搜索(search)、直接回答(answer)、反思规划(reflect)和编码协助(codin
Jina.AI DeepSearch
Deep Research
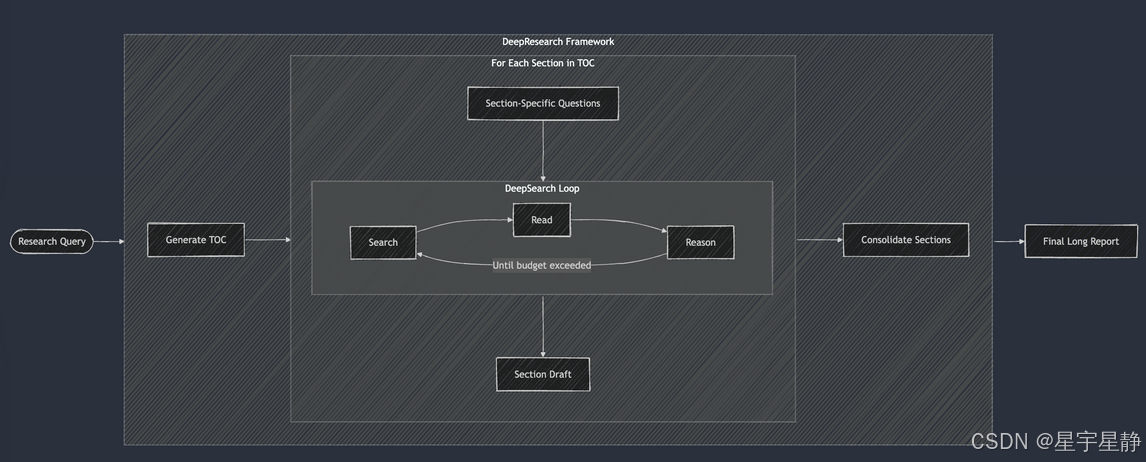
次级研究优化器
参数预处理 & 消息标准化
-
做什么:整理入参、抽出真正的
question,去掉外部传入的system消息。 -
主要数据:
question、messages。 -
可扩展:在这里做多模输入预处理(比如把图片/OCR结果拼进
messages)。
语言/Schema 初始化
-
做什么:
Schemas推断语言,必要时设置searchLanguageCode;初始schema = SchemaGen.getAgentSchema(...)。 -
主要数据:
SchemaGen.languageCode、按功能开关生成的 zod schema。 -
可扩展:支持更多动作(在 schema 里加 action),或按领域切换不同 schema 模板。
上下文容器与生成器
-
做什么:构造
TrackerContext(TokenTracker+ActionTracker),以及ObjectGeneratorSafe(负责让模型产出结构化对象)。 -
主要数据:
context.tokenTracker、generator。 -
可扩展:自定义 token 预算策略、记录更细的埋点。
全局状态池与标志位
-
做什么:建一堆“会话内记忆与状态”
-
队列与集合:
gaps、allQuestions、allKnowledge、allURLs、allWebContents、visitedURLs、badURLs、imageObjects -
控制开关:
allowAnswer/search/read/reflect/coding -
评估框:
evaluationMetrics(每个问题需要通过的 evaluator 集) -
预算:
regularBudget = tokenBudget * 0.85(剩余 15% 预留给 beast mode)
-
-
可扩展:把这些状态换成你自己的 state store / KV / DB。
从消息里先挖 URL(冷启动 URL 池)
-
做什么:扫描
messages文本,extractUrlsWithDescription()→addToAllURLs(),为后续 URL 打分做冷启动。 -
主要数据:
allURLs(Map: url → {title, description, date, weight…})。 -
可扩展:在这里接入“用户指定必须访问的来源白名单/黑名单”。
主循环(直到token预算用完)
循环体是整条“计划→行动→评估→记忆”的状态机——每步只做一个动作(LLM 决策)。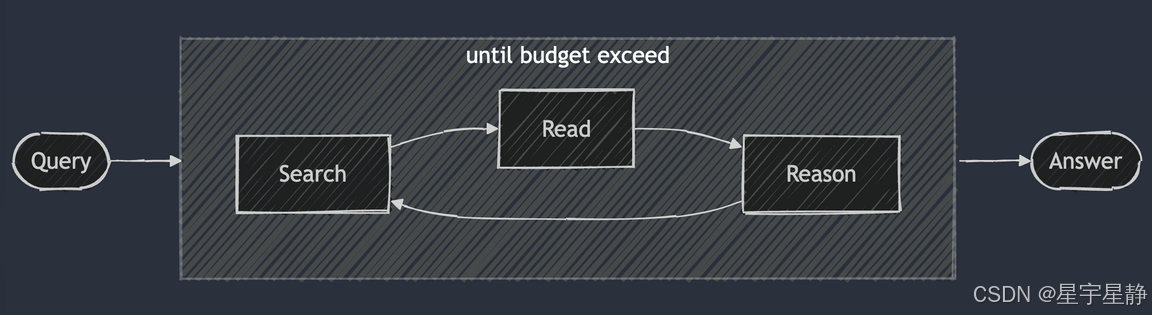
当前问题选择 & evaluator 设定
-
轮询
gaps取currentQuestion。 -
第一次针对原始问题:
evaluateQuestion()给出需要通过的评估类型集合(含strict),并记录它们的重复容忍次数numEvalsRequired。-
明确性
-
实时性
-
多样性
-
完整性
-
强制
从以上几个角度来评估原始问题
-
-
如检测到
freshness(实时性),第一步禁止answer/reflect,强制先信息收集。
URL 池重排 & 限流
-
filterURLs(URL正则过滤)→rankURLs(cos相似度结合jinaRerank排序URL)→keepKPerHostname(同一个域名保留前K个)得到weightedURLs(URL权重,如果相似则);并据此更新开关: -
-
有 URL 就允许
visit; -
URL 太多(≥50)就临时禁止
search。(对于我们的项目可以去除)
-
-
可扩展:往
rankURLs注入我们自己的 reranker/多源信号(域名频次、路径深度、时间戳、语义相关性)。
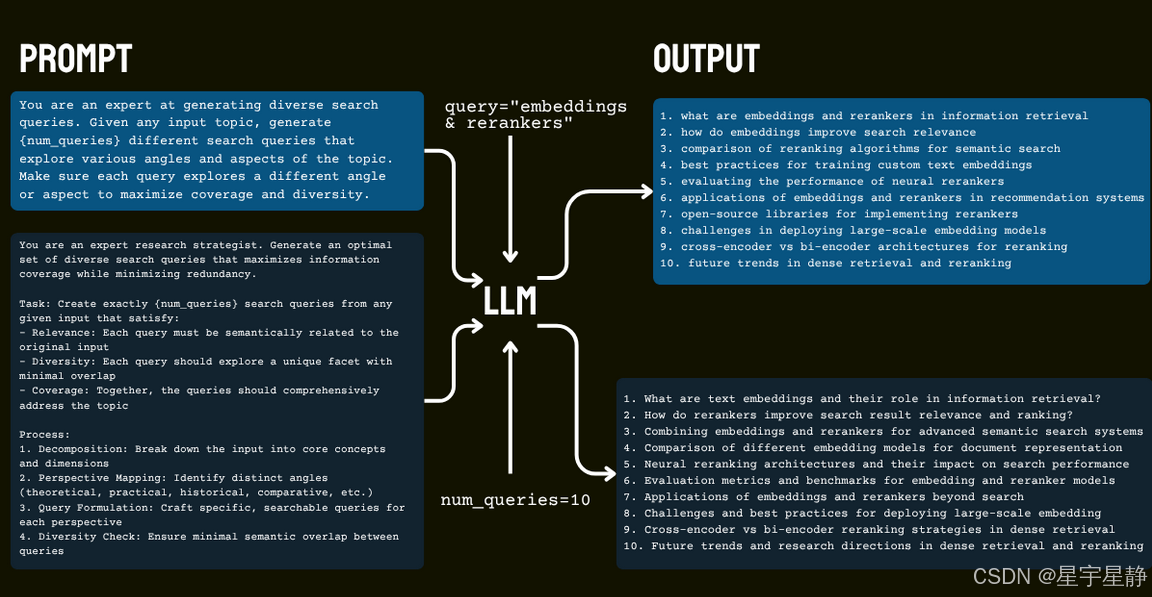
组 Prompt & 拉一次结构化决策
-
做什么:
getPrompt()+composeMsgs()生成 system+messages,喂给generator.generateObject(),产出一步的thisStep:-
action ∈ {answer, reflect, search, visit, coding}之一 -
动作对应字段(如
searchRequests,URLTargets,questionsToAnswer,answer)
各动作的选择依据和触发条件如下:
-
action-visit(读取网页)
-
包含条件:allowRead 为 true,且 urlList 非空(从 allURLs 选出前 20 条,带有 score 权重与简要 merged 片段)。
-
使用场景:需要用外部网页“落地”答案、获取全文证据、补充知识;提示中强调“高权重更相关”“必须检查问题中提到的 URL(如有)”。
-
选择依据:问题显然需要最新或外部来源、已有相关 URL 可读;权重高的链接优先。
-
-
action-search(搜索)
-
包含条件:allowSearch 为 true(默认开启)。
-
使用场景:需要发现新信息、构造高质量搜索请求,尤其是当前没有足够的可读 URL、或存在知识缺口、或问题涉及多个方面。
-
选择依据:提示要求“优先单一搜索请求,除非问题确实多方面”,并提供 (来自 allKeywords,记录之前失败的查询)以避免重复错误查询。
-
-
action-answer(直接回答)
-
包含条件:allowAnswer 为 true;若 beastMode 为真,还会追加一段“强制进攻”的答题版本,鼓励在不完全确定时也给出有根据的回答。
-
使用场景:问候、闲聊、一般常识题,或用户让你取用已存在的聊天历史;对于其他问题,则要给“已验证”的答案,若不确定可转用 reflect。
-
选择依据:如果信息已充足、问题不需外部检索,或属于闲聊/常识,就直接回答;beastMode 会降低犹豫阈值,倾向更积极输出。
-
-
action-reflect(反思规划)
-
包含条件:allowReflect 为 true(并且在主循环里会根据问题数量上限控制,且遇到“时效性”评估时可能被禁用)。
-
使用场景:识别知识缺口、列出关键澄清问题、规划下一步(如先搜索再阅读)。
-
选择依据:当不确定是否能直接回答、信息不足、需要更好地分解问题、或需要制定更稳健的查询策略时选择。
-
-
action-coding(编码协助)
-
包含条件:allowCoding 为 true(在主逻辑里通常只在检测到编程/数据处理类任务时才开启)。
-
使用场景:用户描述的是计数、过滤、转换、排序、正则提取、数据处理等编程类问题;提示说明“用 JavaScript 解决,由工程师实现,你只需描述问题”。
-
选择依据:当问题明显是数据处理/编程任务,且不需要搜索或阅读外部内容时优先选择。
-
其他影响决策的重要信号:
-
URL 权重与列表:sortSelectURLs 从 allURLs 中挑出最相关的前 20 条,提示里明确“高权重更相关”,引导模型访问更有用的链接。
-
失败查询记忆:allKeywords 作为 ,避免模型在 action-search 重复低质量或失败的搜索请求。
-
上下文与行动历史:context 会被插入 ,模型可据此了解已做过的步骤、避免重复无效行动。
-
最终约束:提示结尾要求“基于当前上下文,必须选择一个动作,并按该动作的 schema 返回”,结合 Zod 的动作 schema 解析,保证只选其一且格式正确。
-
动作执行(五选一)
A) answer
-
当模型“第一步就有把握地直接回答”则直接退出
-
答案评估器
- 从确定性、时效性、多样性、完整性几个方面对答案做出检查
-
判断是否是原问题还是子问题
-
如果评估通过的是子问题,则补齐了一个gap(队列)
-
如果原问题和子问题都评测失败,则allowAnswer为False,继续后续补全证据
-
-
原题+评估通过 ->成功
-
原题+评估失败->复盘/惩罚/切换策略
-
子问题+评测通过->补齐gap、沉淀知识
B) reflect
-
去重+截断
-
把候选子问题域all_question去重,这里用了jina dedup,编码后计算相似度来进行去重
采用 late-chunking 和
jina-embeddings-v3完美解决了下面三个问题:-
每个块不能太长,因为 embedding 模型无法很好地处理长上下文;
-
分块会导致上下文丢失并使块 embeddings 变得独立同分布;
-
如何找到最佳的边界线索来同时保持可读性和语义
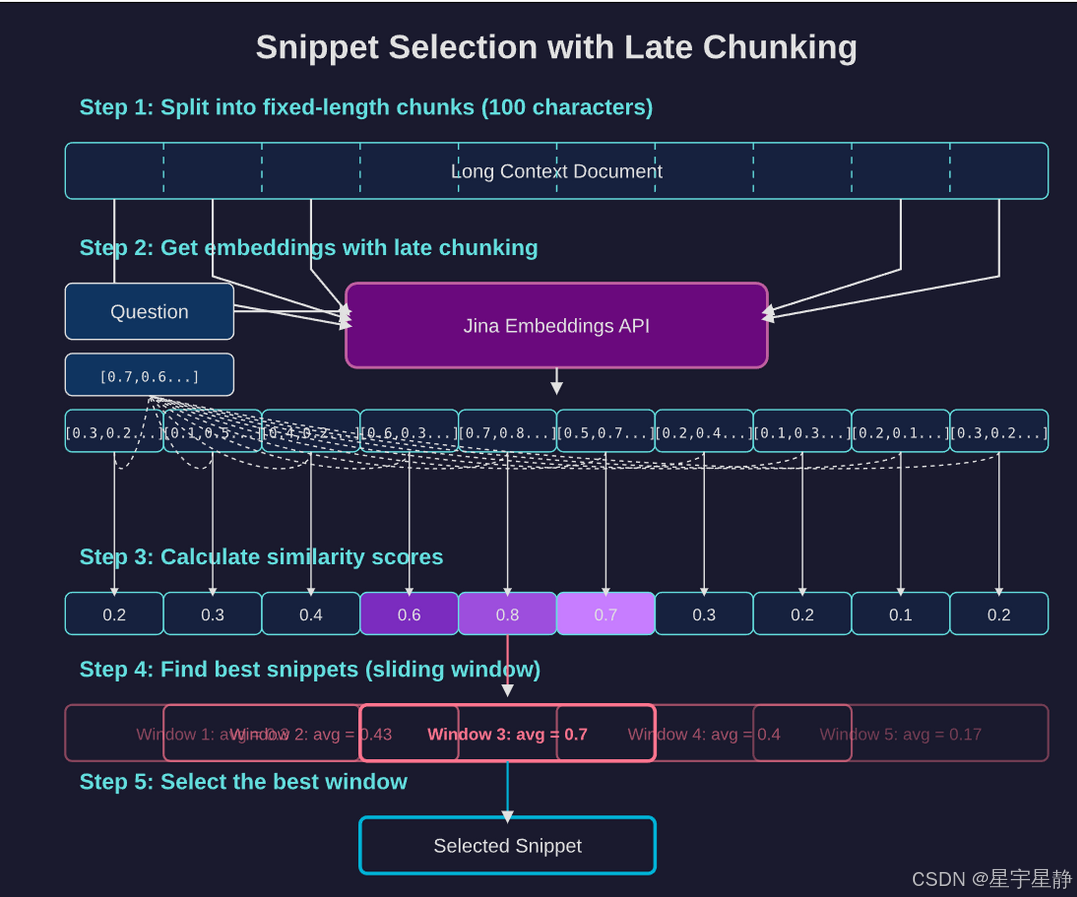
-
-
每一步限制最多新增2个子问题
-
如果有新的子问题
- 加入队列中还有全量问题集
-
如果没有新的子问题
-
对currentQuestion尝试拆解但是发现都问过了
-
那么给上下文打上需要换一个思路,引导后续策略转向(比如改搜法、换证据、走别的推理路径)。
-
-
-
降频:为了防止“生成子问题”截断反复空转,这一步之后暂时allow_reflect = False
C) search
-
去重+截断
-
第一次搜索需要冷启动
-
记录要搜什么
-
格式化query:构造最终查询文本
-
调用具体搜索源,文中使用的jina搜索
-
标准化 SERP 结果为最小片段
minResults-
字段:{ title, url: normalizeUrl(r.url || r.link), description: r.description || r.snippet, weight:1, date }
-
过滤url为不合法的
-
-
写入全局缓存与内容摘要
-
对每个
minResult:-
utilityScore += addToAllURLs(r, allURLs)(统计贡献分;用于后续诊断日志) -
webContents[r.url] = { title, chunks:[description], chunk_positions:[[0, description.length]] }
-
-
把最终发出的查询文本(可能含
site:)加入searchedQueries
-
-
聚类抽取(serpCluster)→ 结构化知识
-
无论聚类是否成功,都补一条“side-info”与动作追踪
-
返回:提炼出的知识,发出的查询字符串
-
-
拆分子问题,并且并行求解(递归)(人为给定是否并行)
-
如果只拆分单个问题则后逐个解决
-
基于初步情报改写查询(二次搜索前置)
-
用
soundBites触发 query expansion / rewrite; -
与历史
allKeywords再去重,避免重复打同一批词; -
如果同文案有多种“变体”(例如带/不带站点限制),策略是保留更“宽”的版本(
{ q }),否则保留唯一的那条结构化查询。
-
-
第二次搜索(“热启动细化”)
-
加上了onlyHostnames限定了域名范围?(为什么?第二次搜索需要去白名单域中搜索,如:权威媒体、官方文档、学术站,提升可信度与可引用性)
-
第一次搜索是召回优先,第二次要求精度优先
-
-
空结果分支与“换思路提示”
- 若二次查询为空或完全没新查询,记录“无新增信息,建议换角度”的提示,避免无谓重复搜。
-
限流下一步动作
- 搜索后暂时禁止马上再搜或直接作答,促使系统先进行阅读/抽取/验证等严肃步骤,提升答案质量。
D) visit
-
把下标转换成 URL,并做去重过滤
-
URLTargets里是1 基下标(注意idx - 1),从urlList取出 URL。 -
normalizeUrl格式化URL。 -
过滤掉空 URL 与已访问过的(
visitedURLs)。
-
-
合并“加权候选”并限流
-
把前面选出来的 URL 与
weightedURLs(搜索/并行子问题阶段积累的高价值 URL)合并去重。 -
只保留前
MAX_URLS_PER_STEP个,避免一次访问过多页面。
-
-
若有待访问 URL → 执行抓取与解析
-
processURLs负责实际访问、抽取要点/证据、更新缓存/索引(常见操作:-
把成功访问的加入
visitedURLs -
可能把异常站点记入
badURLs -
解析出的文本/块写入
allWebContents -
产出的知识写入
allKnowledge
-
-
withImages决定是否抽图;imageObjects用来承载图像结果。 -
返回:
-
urlResults:每个 URL 的处理摘要(含 URL、提要、也可能含引用片段)。 -
success:本批是否整体成功(至少有收获)。
-
-
-
若没有任何可访问 URL->说明没有新东西
-
节流,allowRead = False
E) coding
-
初始化沙盒
-
给沙盒的“上下文”包括:全局上下文、前 20 个加权 URL(可作参考/依赖)、以及已知知识。
-
目的:让求解器在尽量多的可用线索下尝试“自动编写/运行代码”解决
codingIssue。
-
-
尝试求解
-
期望
result.solution含:-
output: 运行结果/终端输出/答案说明 -
code: 生成的源代码
-
-
-
成功
-
把解法写入知识库
allKnowledge.push({ ... type: 'coding' }):-
question: 以自然语言存储“这次修复了什么问题” -
answer:result.solution.output -
sourceCode:result.solution.code -
updated: 时间戳(formatDateBasedOnType(new Date(), 'full'))
-
-
-
失败
-
logError(...)记录错误信息。 -
在
diaryContext里写明“编码尝试失败,需要换角度”。 -
updateContext({... , result: '...no new information...' }):给出面向策略切换的提示。
-
-
下一步禁止再立刻 coding
上下文存储
保存 落盘 prompt/schema/上下文快照;wait(STEP_SLEEP) 统一限速。
Beast Mode(收束兜底)
-
触发:循环结束且还没拿到
isFinal。(最终结果) -
做什么:关掉全部动作,只保留
answer,用更“激进”的模型agentBeastMode基于现有allKnowledge/diaryContext给出一个必须产出的最终答案。
8) 答案后处理与引用构建
三种收尾路径
(在answer之后会输出类型的)
-
简单题
只把已有答案转成 Markdown 展示结构;不做引用/图片/清洗,因为这是“一步到位”的场景。
-
常规答案(非聚合)
- 内容清洗与修补(自内而外的管线)
-
finalizeAnswer:结合allKnowledge等对原答案做最终润色/补全。 -
repairMarkdownFootnotesOuter:修正脚注标记位置等异常。 -
fixCodeBlockIndentation:修正代码块缩进与围栏。 -
fixBadURLMdLinks(..., allURLs):用全局 URL 索引修复坏的 markdown 链接。 -
convertHtmlTablesToMd:把 HTML 表格转为 Markdown 表格。 -
repairMarkdownFinal:最后一遍小修补(统一格式/边缘问题)。
2. 自动抽取与插入“参考文献”
-
buildReferences:从已缓存的网页内容中,对齐答案片段→打分→挑选引用- 关键参数:
80(对齐窗口/片段长度)、maxRef(最多几条引用)、minRelScore(最小相关度)、onlyHostnames(是否只允许特定域名)。
- 关键参数:
-
updateReferences:对引用再规范化/补标题/去坏链。
-
聚合答案
-
直接把各子答案拼接为最终答案,再转 md。
-
图片:若已有
imageReferences,则-
按
relevanceScore降序排序; -
用
dedupImagesWithEmbeddings做语义去重,再filterImages过滤; -
截取前 10 张。
-
注意:聚合路径此处不重建文本引用;通常引用在聚合时已合并/去重过。
-
9) 结果打包返回
限制返回 URL 数量;组合
-
{ result: thisStep, context, visitedURLs, readURLs, allURLs, imageReferences? }

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)