我用10分钟开发了一个AI助手,感觉还不错哈哈哈
·
一、AI 助手的意义
AI 助手的意义就是:
把大模型的智能能力“嵌入”到企业/产品/用户场景中,帮助人更快、更聪明、更低成本地完成任务。
它的价值在于:
- 对内:效率 + 知识沉淀
- 对外:客户体验 + 服务创新
- 长远:形成企业数字化转型的核心竞争力
二、实现方式对比
方案 1:本地部署大模型 + 应用框架(如 Dify、LangChain、Flowise)
实现思路
- 在本地或企业私有云部署一个大模型(如 Qwen2、LLaMA3、InternLM、DeepSeek 等)。
- 使用 Dify / LangChain / RAG 工具链 搭建工作流:意图解析、知识库检索、函数调用、工具调用等。
- 后端服务负责对接前端 Web 页面和工作流(REST API / WebSocket)。
优势
- 数据安全:数据不出企业内网,尤其适合涉及业务数据、隐私数据的场景。
- 可控性:模型版本、推理速度、调用链路都自己掌控,可深度定制。
- 灵活扩展:可接入知识库、调用内部 API、实现企业专属功能。
- 成本可控:长远来看如果调用量大,本地部署比云服务 API 更便宜。
劣势
- 算力开销大:需要 GPU/算力集群,特别是高并发时成本显著。
- 运维成本高:需要团队持续维护模型、升级、微调、优化推理速度。
- 模型更新滞后:跟不上云厂商快速更新迭代的节奏。
方案 2:使用云厂商 AI 助手(阿里云、百度、OpenAI、Anthropic)
实现思路
- 前端 Web 页面调用你们的后端接口。
- 后端再调用云服务的 API(例如阿里云百炼、百度千帆、OpenAI Assistant API)。
- 云厂商本身就有工作流/多模态/工具调用功能,可以快速接入。
优势
- 上手快:调用 API 即可,省去模型部署和复杂运维。
- 功能强大:模型精度、功能(语音、图像、代码)跟随厂商迭代。
- 高可用性:云厂商保证 SLA,稳定性和扩展性较好。
- 更智能:最新的 GPT-4.1、Claude 3.5、Qwen-Max 等,性能通常优于本地开源模型。
劣势
- 数据风险:即使厂商承诺不存储数据,也有数据外泄的隐忧。
- 成本不确定:按调用量计费,随着业务规模增加,费用可能非常高。
- 受限于厂商:厂商 API 升级、价格变动、政策风险不可控。
第三种思路:混合模式
未来趋势往往是 混合架构:
- 通用问答 → 用云厂商大模型(智能更强,体验更好)。
- 业务相关、敏感数据问答 → 用本地模型 + RAG(保证安全性和私有化)。
- 工作流编排 → 用 Dify / LangChain 统一管理,前端通过一个 API 网关接入,不管背后是本地还是云模型。
比如:
- 普通对话、代码解释 → 调用阿里云/DeepSeek。
- 涉及企业知识(合同、车辆数据、内部文档) → 本地部署 Qwen-7B + Dify 知识库。
- 由后端智能路由,前端只知道自己在用一个 AI 助手。
🔹 趋势分析
- 短期(1~2年):云服务更划算,模型效果好,上线快,适合先跑起来。
- 中长期:混合架构会成为主流 —— 大厂模型做通用,企业本地模型做垂直和安全,结合 RAG / 工作流。
- 未来发展:大模型逐渐走向“平台化 + 私有化”。像 Dify、LangChain 这样的 工作流编排层 会成为关键,屏蔽底层模型差异。
总而言之,AI助手如果是做简单的工具功能,问答功能等业务属性不大的工作,可以使用云平台AI助手,
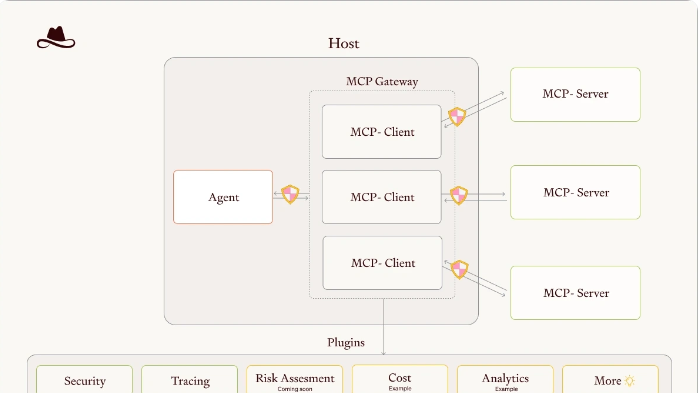
三、 AI 助手架构概览
四、 阿里云AI助手
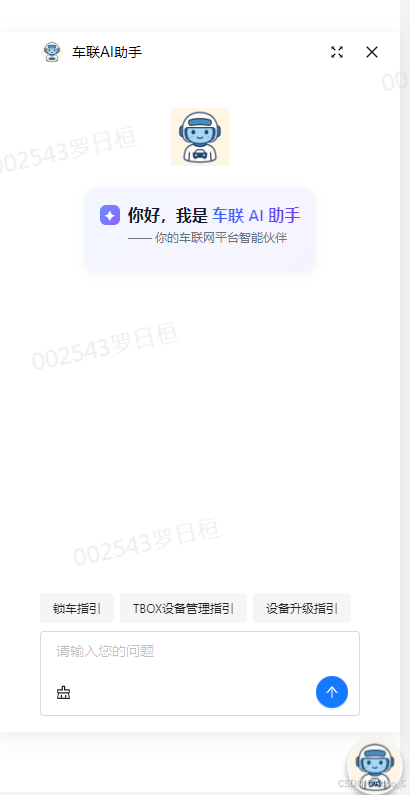
1. 阿里云搭建步骤
参考阿里云官方文档,这里阿里云已经很详细的说明如果在阿里云上快速搭建一个简单版的AI助理

2. AI助理 + MCP-Server
首先大概说明一下AI助理的调用脉络,阿里云有属于自己的AI大模型,同时也有
AI 应用开发平台(AI AppOps 平台)
- 提供可视化的 工作流编排。
- 支持 RAG、Agent、工具调用、知识库管理。
- 提供 Web 管理后台,可以直接托管 AI 应用,发布给业务人员使用。
在调用AI助理前,需要在阿里云百炼平台创建一个Agent,然后再AppFlow上,创建一个应用,该应用就调用的这个Agent,使用的也是这个Agent的能力,所以AI助理的智能能力就在这个Agent上,然后这个AI助理可以集成WEB,其实就是前端的一个窗口调用,源头在阿里云
a. Agent调用mcp的方式
Agent 调用 MCP(Message Control Protocol)时,可以考虑以下三种方式:
1. npx (Node Package Executor)
简介: npx 是一个 Node.js 包管理器(npm)工具,通常用于执行项目中临时安装的 Node.js 程序。它允许直接执行安装在项目中的包,无需全局安装。
- 优点:
-
- 灵活性:可以动态调用项目中的包,无需全局安装。
- 无需额外安装:如果包在项目中已经存在,直接调用即可。
- 开发环境友好:对于快速测试和临时工具的执行非常有用。
- 缺点:
-
- 性能问题:每次调用时会查找和下载依赖,可能导致调用延迟。
- 依赖管理:如果项目中的依赖没有正确配置,可能会出问题。
- 不适合生产环境:由于执行时需要在每次调用时解析依赖,不太适合高频率、高并发的生产环境。
- 适用场景:
-
- 适合开发和测试阶段的调用。
- 用于调用临时依赖包或工具,避免全局安装。
2. uvx (Universal Virtual Executor)
简介: uvx 是一个虚拟执行环境,常用于多种编程语言或框架中,它能够统一调度、执行和管理多个虚拟环境下的任务。
- 优点:
-
- 统一管理:支持多个语言或框架,能够简化跨平台任务的管理。
- 高效的任务调度:适合需要高效调度和多任务并行执行的场景。
- 支持隔离环境:每个任务可以在独立的虚拟环境中执行,避免了环境污染和依赖冲突。
- 缺点:
-
- 配置复杂:需要在各个语言环境中配置相应的支持。
- 资源消耗:虚拟环境的创建和管理可能带来一定的资源开销。
- 适用场景:
-
- 适用于需要跨平台执行任务的场景。
- 适合对环境隔离有较高要求的系统(例如微服务架构)。
3. sse (Server-Sent Events)
简介: SSE 是一种基于 HTTP 协议的单向推送技术,允许服务器将事件推送到客户端,通常用于实时更新数据的场景。
- 优点:
-
- 实时性强:能够实现低延迟的实时数据推送。
- 易于实现:相比 WebSocket 等技术,SSE 的实现更加简单,客户端只需使用标准的 JavaScript API。
- 节省资源:相较于传统的轮询,SSE 不需要客户端持续发送请求,减少了网络开销。
- 缺点:
-
- 单向通信:只能从服务器向客户端推送数据,客户端不能主动向服务器发送消息。
- 浏览器兼容性问题:虽然现代浏览器支持 SSE,但某些旧版浏览器可能存在兼容性问题。
- 长连接问题:SSE 依赖长连接,在网络中断或连接重置的情况下可能会中断。
- 适用场景:
-
- 实时更新场景:适用于需要实时更新数据的场景,如监控系统、即时消息系统等。
- 数据流场景:适用于需要将数据持续推送给客户端,而不要求客户端频繁请求的场景。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)