BEYOND DIALOGUE: A Profile-Dialogue Alignment Framework TowardsGeneral Role-Playing Language Model
1 论文介绍
论文提出BEYOND DIALOGUE,旨在解决两个问题:
-
1.角色设定与对话不匹配(Profile-Diaglogue Bias)
如果对话语料与角色预设档案(profile)不一致,会在训练中引入偏差,使模型难以按照角色档案行为。 -
2.缺乏精细对齐(Fine-Grained Alignment)
单一的对话训练任务无法将对话与角色特质进行细粒度对齐。
训练过程无法捕捉角色特质在具体语句中的体现,限制了模型理解和表达角色复杂特质的能力。

2 论文框架
-
Alignment Dataset Construction(对齐数据集构建阶段)
通过对齐和调整角色档案(profile)与特定场景(scenario),生成“纯净”的角色扮演对话数据。
“纯净”指去除了角色偏差(如档案与对话不符),是高一致性数据。 -
Supervised Finetuning(监督微调阶段)
将这些“纯净”的角色扮演数据,与对齐推理数据(alignment reasoning)及闲聊数据(chit-chat data)融合,用于训练模型。
提升模型的通用对话能力与角色扮演特征对齐能力。 -
Automated Dialogue Evaluation(自动化对话评估阶段)
构建自动化的评估流程:
随机生成场景 模型与多轮对话 生成客观问题(如选择题、判断题) 量化角色扮演能力
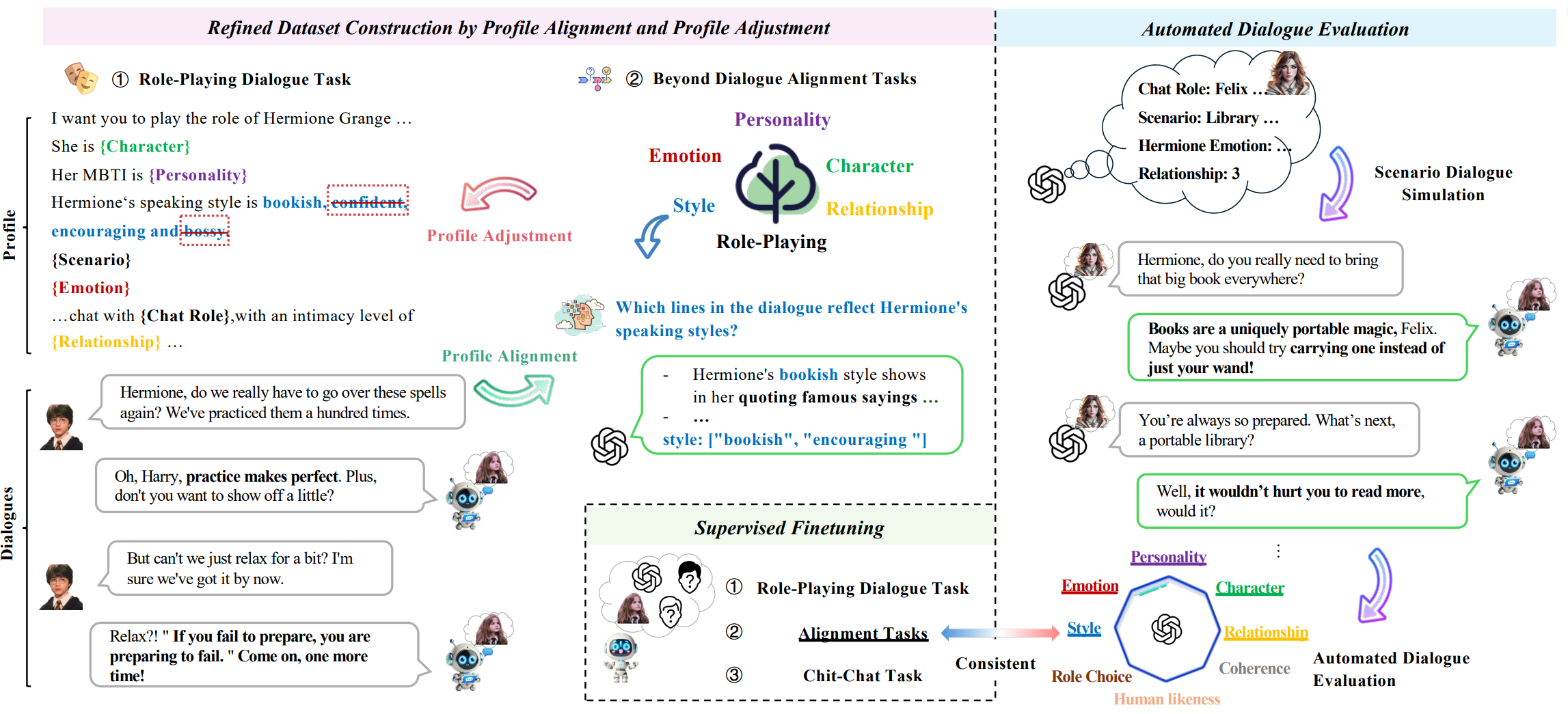
2.1 对齐数据集的构建
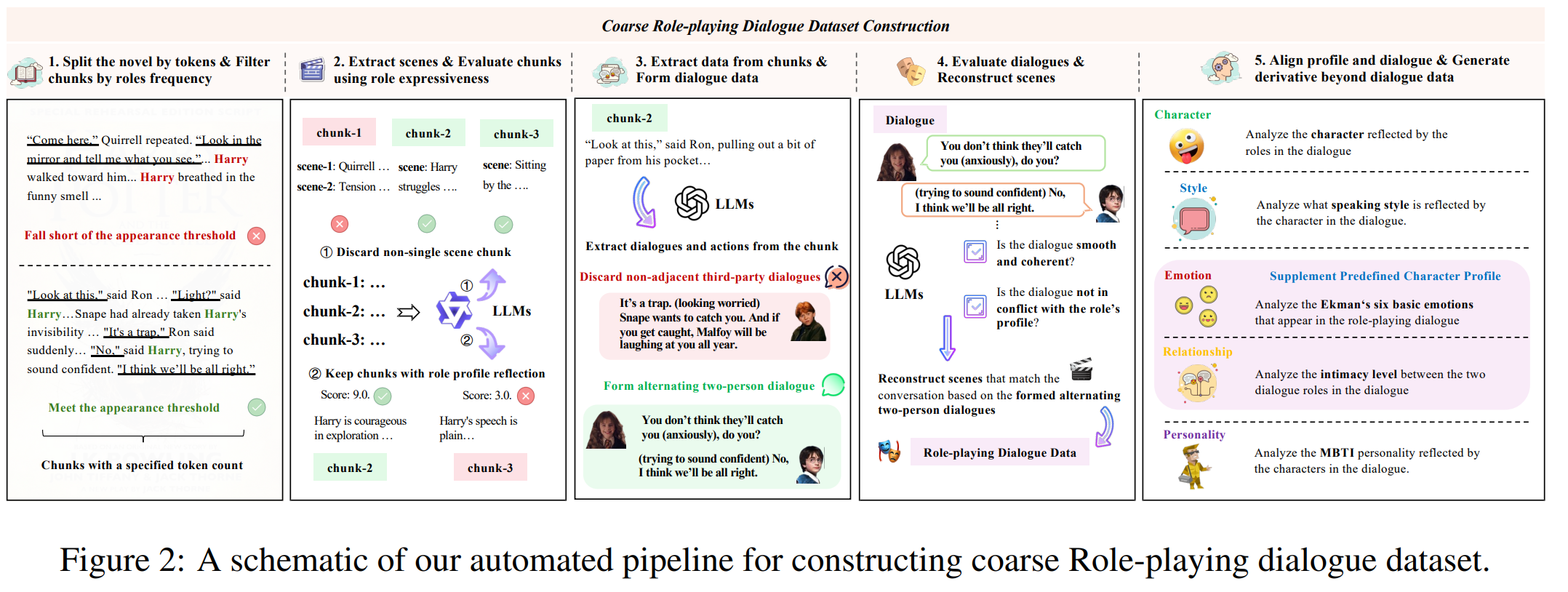
步骤 1: Split the novel by tokens & Filter chunks by roles frequency(按角色出现频率切分小说文本)
- 系统通过 token 切分小说为多个 chunks。
- 对每个 chunk 统计角色出现频率。
- 若主要角色出现次数低于设定阈值(Fall short of the appearance threshold)→ 丢弃
- 若满足阈值(Meet the appearance threshold)→ 保留
结果输出:“Chunks with a specified token count” —— 结构良好且角色集中出现的文本块
步骤 2: Extract scenes & Evaluate chunks using role expressiveness(场景抽取与角色表达性评估)
利用LLMs:
- 对每个chunk分析出若干“scene”,丢弃多场景的混合段落(Discard non-single scene chunk)
- 对 chunk 进行角色特征反映性(role profile reflection)评分,保留高得分的chunk
保留具有鲜明角色特征、场景清晰、互动明确的片段
Step 3: Extract data from chunks & form dialogue data(从片段中提取数据并形成对话)
- 利用LLM从chunk中提取出对话和动作
- 删除非连续或多角色干扰性语句(Discard non-adjacent third-party dialogues)
- 最终形成两人交替的对话格式(Form alternating two-person dialogue)
选用gpt-4o——在场景重构与多轮对话识别中具有高准确率
保证输出的对话结构干净、角色明确
Step 4: Evaluate dialogues & reconstruct scenes(对话评估与场景重建)
LLM 对对话进行两项检测:
-
对话是否连贯流畅(smooth and coherent)
-
对话是否符合角色档案(not in conflict with the role’s profile)
通过检测后,利用LLM重建符合该对话的场景
- 确保语义、语气、情绪与角色设定相一致
- 保留多轮交互性对话
- 为后续对齐打下语义一致的基础
Step 5: Align profile and dialogue & generate derivative beyond dialogue data(对齐角色档案并生成扩展性数据)
在粗粒度语料基础上,对每个多轮对话进行五维特征对齐(CSERP):
- Character(角色特征):分析角色在对话中体现的性格
- Style(说话风格):分析说话方式(如简洁、委婉、傲慢等)
- Emotion(情绪):基于 Ekman 六大基本情绪(快乐、悲伤、愤怒、惊讶、恐惧、厌恶)
- Relationship(关系亲密度):判断对话中人物的互动关系
- Personality(人格类型):基于 MBTI 模型,分析角色潜在人格
LLM通过逐步推理来分析对话,明确地将每个句子与其对应的特征联系起来,从而实现句子级别的对齐
例:一段Dr可以生成五条Da,以下展示一条林黛玉的对话任务,产生的角色特征和说话风格扩展数据Da
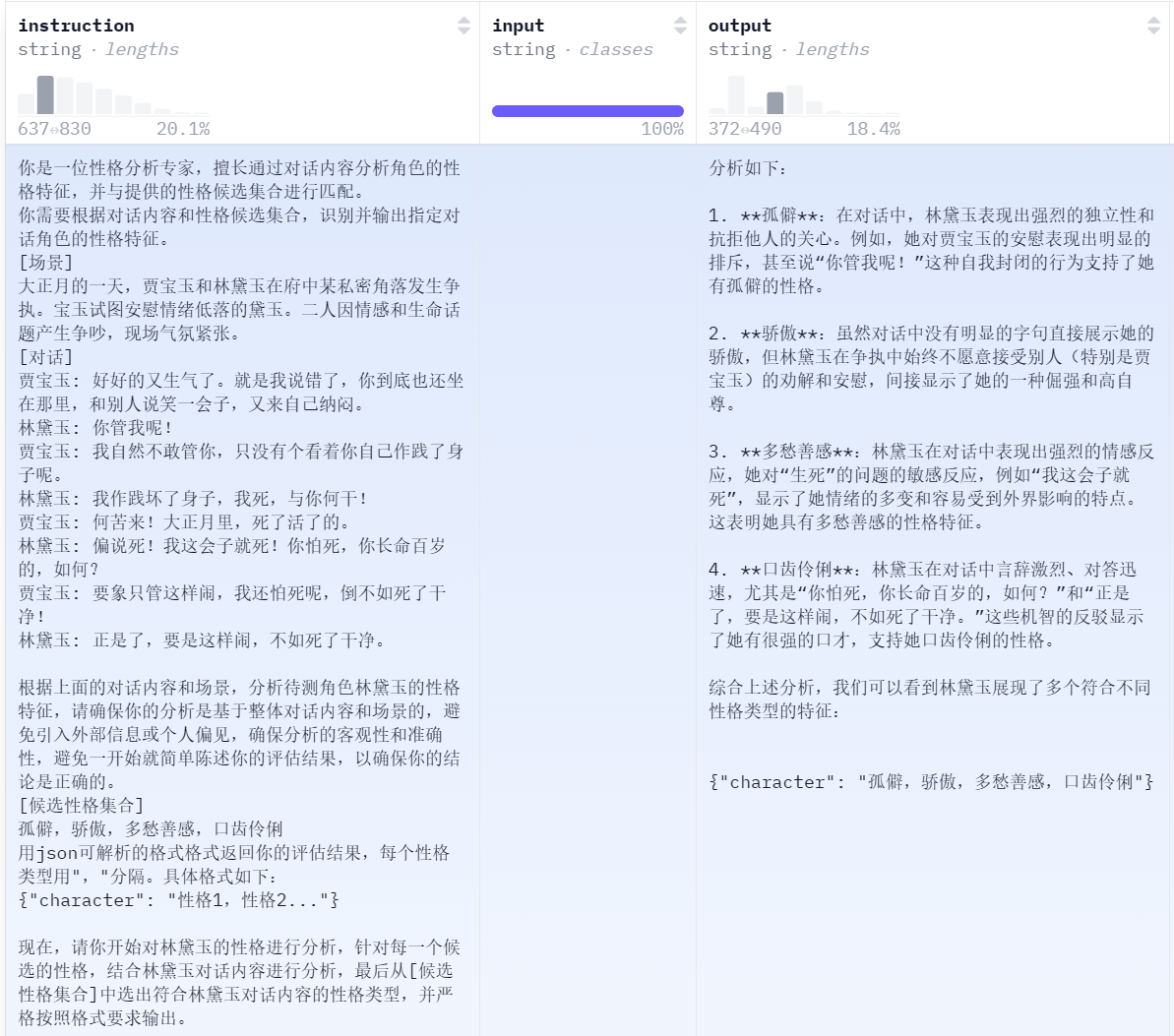
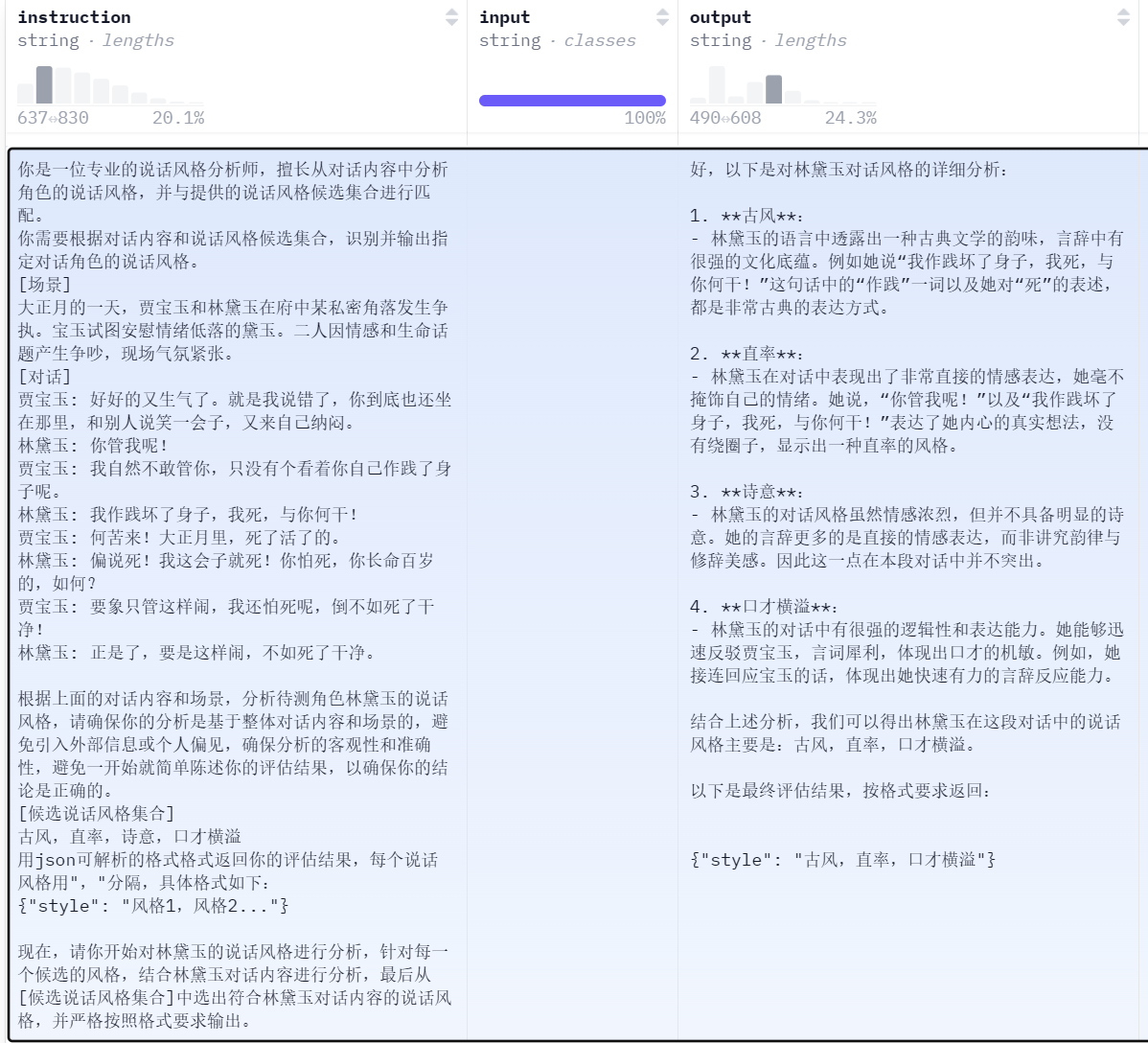
得到结构化的、五维对齐的角色扮演语料
Profile Adjustment
基于对齐结果动态调整角色档案,对话端(Dialogue)向档案端(Profile)反向传递更新信息:
- 删除未体现的特征;
- 添加与场景相关的情感或关系属性。
目的是解决传统数据集中“角色档案与对话不符”的偏差问题。
传统数据集中,角色档案往往是“人工定义”的固定文本
场景对话则来自不同来源(小说、剧本、LLM生成)
两者常常存在语义偏差或情绪不一致
BEYOND DIALOGUE 的 Profile Adjustment 模块通过反馈机制弥合这种偏差
2.2 监督微调
使用已构建的数据集,对大语言模型微调,训练数据有:
- 角色对齐对话数据 Dr(Aligned Role-Playing Dialogue)
- 从 Dr 中衍生的 对齐推理数据 Da(Alignment CSERP Data)
- 以及开源闲聊语料中的 闲聊数据 Dc(Chit-Chat Data)
三者在训练中按 1 : 5 : 4 的比例混合使用
Dr在上一节构建,在这个过程中会自动派生出Da,一条Dr可以生成五条Da
| 模块 | 含义 | 功能 | 比例 |
|---|---|---|---|
| Dr | Aligned Role-Playing Dialogue | 确保输出对齐角色档案 | 1 |
| Da | Alignment CSERP Data(派生对齐数据) | 强化角色理解与档案一致性 | 5 |
| Dc | Chit-Chat Data(闲聊数据) | 保留一般对话能力 | 4 |
Dr 的功能:提供“输入(档案)—输出(对话)”的真实匹配样例,使模型学会在人物设定下说话。
Da 的功能:强化“角色理解”任务,让模型不仅生成对话,还能理解对话为何符合角色档案。
训练目标:最小化三个数据集上的总体负对数似然损失(Negative Log-Likelihood, NLL)
![]()
与标准语言模型训练一致:最大化生成目标句子的概率
2.3 自动化对话评估
生成过程:
- 角色与描述生成:生成被评估角色(如“福尔摩斯”、“李白”)的详细资料与世界观。
- 场景构建:根据角色档案(profile)设计对话场景。
- 情绪与关系定义:为角色设置特定情绪(如愤怒、平静)与社会关系(如师生、对手)。
- 多轮对话生成:两个模型(被评估模型 + 对照模型)在该设定下进行多轮对话,生成测试语料。
其中一个参与对话的是 gpt-4o,与人工评估相比,它提供了一种低成本、标准化的评估方式,能确保不同模型间评估结果的一致性
LLMs as Judges
LLM 不只是对话参与者,也是自动评分者
评估指标依据五大角色维度:角色特征、语言风格、情感、关系以及人格
还引入了两个额外指标
- Human-likeness:是否像人类的表达方式
- Coherence:对话是否连贯
基于角色的多选题评估机制(Role-based Multiple-choice Evaluation)
与传统主观打分不同,这里将所有评估任务转化为客观问题(objective questions),例如选择题或判断题。
这样可以减少评估方差,使结果更贴近人工评分的平均判断。
1. Scenario Dialogue Simulation(场景对话模拟)
生成一个角色和画像(如 Hermione 在图书馆场景中)
设定情绪和关系(例如与 Felix 的关系为 3)
由两个模型进行多轮对话:一个是待评估模型,另一个是 GPT-4o(作为对话者与评审)
2. Automated Evaluation(自动评估)
由 GPT-4o 来根据客观题判断模型在不同维度的表现,每个维度都会通过自动化的多项选择题进行评分,这样比主观评价方差更小,也更符合人工判断结果
3 实验
3.1 实验设置
RP数据集
- 构建了一个角色扮演对话数据集RP
- 采集了123部小说和剧本,提取280个中文角色+31个英文角色
- 构建得到3552个情景对话,共23247个对话轮次
CSERP句级对齐数据集
- 每个RP对话会话中派生出5个任务,生成句级对齐数据集CSERP
初始状态下,角色档案(Profile)与实际对话之间的一致性非常低。仅有 4.2% 的对话在“角色特征、风格、人格”三个维度上与原档案完全匹配。
经过自动对齐和Profile调整后,RP 数据集数据转化为对齐后的角色扮演数据集 RPA(Aligned Role-Playing Dataset)
Chit-chat数据集(CC)
- 保持模型的通用对话能力
- 中文:NaturalConv 英文:DailyDialog
对比基线
| 类别 | 模型 | 说明 |
|---|---|---|
| 通用聊天模型(General Chatbots) | GPT-4o, GPT-3.5-Turbo, Yi-Large-Turbo, DeepSeek-Chat | 当前最先进的双语通用对话模型,具有强语言生成能力 |
| 角色扮演专用模型(Role-Playing Baselines) | Index-1.9B-Character(bilibili), Baichuan-NPC-Turbo, CharacterGLM | 专为角色对话优化,生成更具个性与情境特征的对话 |
| 自训练开源基线(Fine-tuned for validation) | Qwen2-7B-Instruct, Mistral-Nemo-Instruct-2407 | 用于验证BEYOND DIALOGUE框架在开源环境下的有效性 |
评估指标
1. Emotion & Relationship
- 依据 Ekman’s 六大基本情绪理论(1992),大模型对每段对话情绪和关系打分(0~10)
- 与参考标签比较,用 Normalized Mean Absolute Percentage Error (NMAPE) 评估误差
2. Character, Style & Personality
- Personality 用 MBTI 二元分类 测评
- Character 和 Style 是 多标签召回(multi-label recall) 任务
3. Human-likeness
- 使用 few-shot 提示,让 LLM 判断对话是否由人类生成
- 衡量模型语言的自然度与真实感
4. Role Choice
- 在隐藏角色名的情况下,模型需从四个候选角色中选出最符合该对话的角色
- 测试角色识别与一致性
5. Coherence
-
判断多轮对话是否上下文连贯
6. Win-Rate
- 由人工对比 GPT-4o 与被测模型的输出
- 多个标注者投票决定胜出者
- 最终结果以多数表决(majority agreement)确定
3.2 主要结果
对每个模型进行了 300次独立的中英双语评估,每次评估都包含一个新的对话场景,场景中有 五轮对话,每次测试的角色与情境都是全新的。
GPT-4o 负责生成新的对话角色和场景,并与被评估模型进行多轮对话
以下是不同模型在自动化角色对话生成任务中的综合表现,表中报告了各项指标的平均值及其标准误,加粗的数字表示该指标在所有模型中得分最高,下划线表示该组(类别)中的最佳结果。
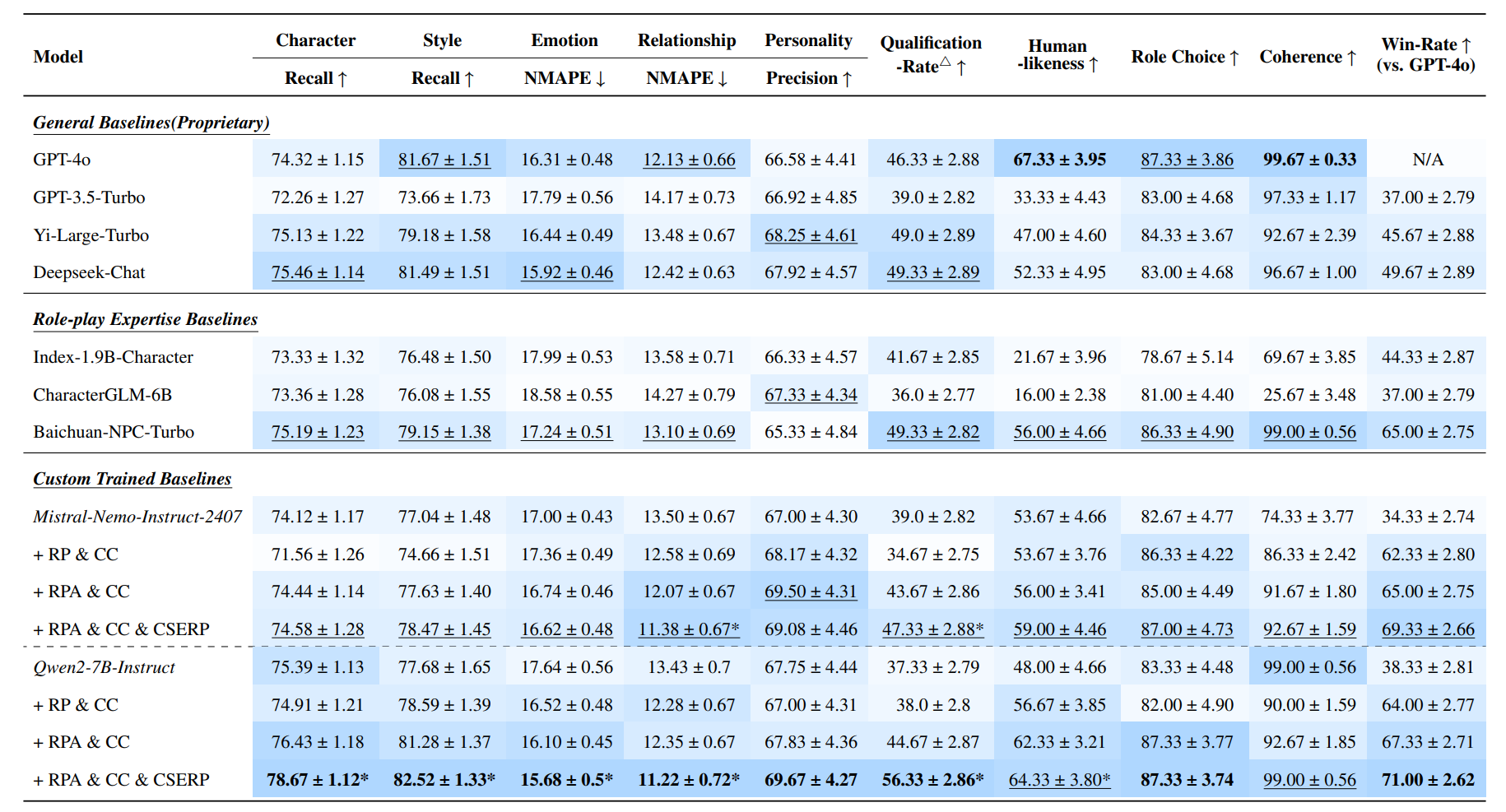
NMAPE ( Normalized Mean Absolute Percentage Error)
归一化平均绝对百分比误差,衡量模型预测与目标之间误差大小
Qualification Rate (QR)△
表示在角色扮演对话中,各维度得分高于 60 的样本比例,衡量模型输出与预定义角色画像的一致性,模型在这些指标上达到标准的比例
实验结果可以看到,RPA+ CC+ CSERP 的组合显著提升了模型的角色一致性、情感表达精度与人类相似度,特别是Qwen2-7B 在结合多重微调策略后,显著超越 GPT-4o
用 未对齐(unaligned) 的角色扮演数据(即 +RP & CC)训练的模型出现了 训练偏差(training bias),其表现有限甚至下降
Dialogue–Profile 对齐任务
从CSERP五个维度中,每个维度各随机取 100 条(共 500 条)进行测试,用 GPT-4o 的结果作为参考标签
验证模型是否能够根据对话内容,动态地调整或修正角色档案(profile),从而保持角色在语言、情绪、关系与性格上的一致性。
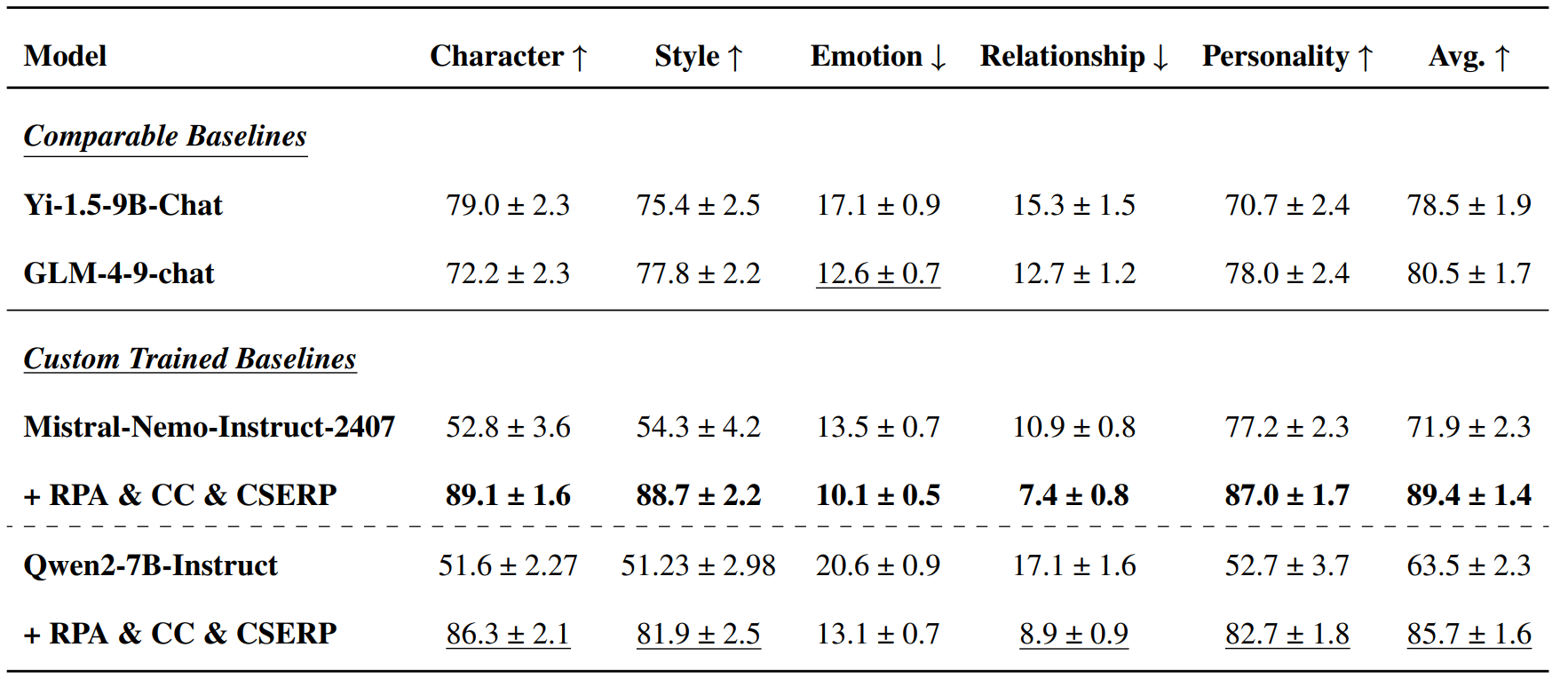
- Mistral-Nemo(对齐版)平均得分 89.4%,几乎接近 GPT-4o 的 89.4%
- Qwen2-7B(对齐版)平均得分 85.7%,超过了更大的 Yi1.5-9B 和 GLM4-9B
3.3 消融研究
研究CSERP 五个子任务(Character / Style / Emotion / Relation / Personality)中,
哪些维度的贡献最大?哪些是可替代的?哪些是核心?
单独移除Da中的每个对齐任务,并用等量的Dc替换了其训练数据量
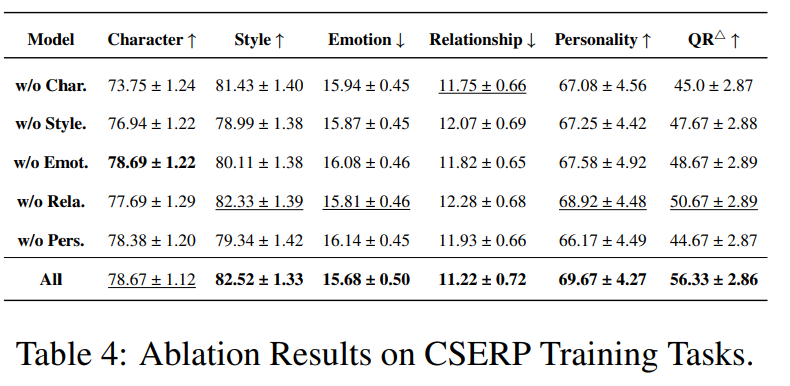
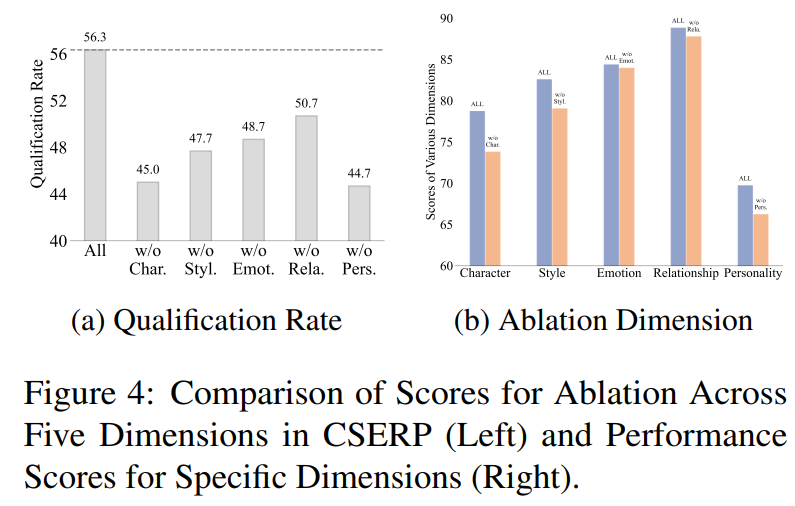
左图展示,移除任一维度后,QR 均显著下降
右图展示各维度的细项得分变化,移除任意维度,相应维度得分均下降
移除任何一个维度都会导致模型在相应维度及整体上退化
4 结论
(1)Profile–Dialogue Alignment 方法
论文提出一种简单但有效的方法,用于在特定场景中让对话更好地对齐角色画像
(2)Beyond Dialogue Prompting(超越对话提示机制)
作者引入了一种创新的 prompt 机制,在训练任务中不仅生成对话内容,还生成推理过程
(3)客观评估指标(Objective Evaluation)
论文将评估方式从传统的主观人工评价转为客观、可复现的自动化评价方法
实验证明,BEYOND DIALOGUE 能在多个维度上(例如一致性、一贯性、情绪控制等)显著提升模型的“角色遵从性”,超过通用和专用的角色扮演基线模型(包括普通GPT类和专门微调的RP模型)
研究局限
1. 动态角色画像问题
虽然 BEYOND DIALOGUE 在“静态角色一致性”上很强,但在“动态适应”上仍存在挑战。
现实中的角色在对话过程中会变化,比如:
- 情绪变化;
- 新的信念或目标;
- 对他人的态度调整。
但目前他们的框架假设角色画像是固定不变的
2. 角色画像定义依赖人工
当前所有角色扮演模型,包括他们的方法,都需要人工定义角色画像(role profile)
未来应让模型自主推理,能基于上下文动态地理解、调整这些画像。
3. 多方对话挑战
目前 BEYOND DIALOGUE 主要在双人对话场景测试。
但现实中常见的多方互动——例如群聊、会议、游戏剧情——会带来更复杂的挑战:
- 多角色之间的一致性管理
- 每个角色的动态画像演化
- 不同角色之间的语气与关系保持

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)