【大模型面试】校招面试加分项:深度解析Deepseek-OCR模型及其多模态突破!
这看似随意的一问,却很可能拉开不同候选人的差距,尤其是在中大厂面试中。他不是想听八股,而是想看看你有没有持续关注前沿、能不能聊出自己对新技术的思考。比如前几天爆火的 Deepseek-OCR,如果你能讲清楚这个,那几乎是稳稳加分。它不只是个识别模型,更是 DeepSeek 在多模态方向的关键突破。那它到底做了什么?为什么能被 Karpathy 等大牛亲自点赞?这篇文章,我们就从面试场景切入,一起来
不少同学在校招面试的时候,都会被问到这么一个问题:“你最近有没有关注过什么新的模型啊?或者有没有 follow 什么新的技术?”
这看似随意的一问,却很可能拉开不同候选人的差距,尤其是在中大厂面试中。他不是想听八股,而是想看看你有没有持续关注前沿、能不能聊出自己对新技术的思考。
比如前几天爆火的 Deepseek-OCR,如果你能讲清楚这个,那几乎是稳稳加分。它不只是个识别模型,更是 DeepSeek 在多模态方向的关键突破。
那它到底做了什么?为什么能被 Karpathy 等大牛亲自点赞?这篇文章,我们就从面试场景切入,一起来分析拆解一下。
一、面试官心理分析
首先还是来分析一下面试官的心理,面试官问这个问题,主要是想考察以下三个方面:
第一,你是否对新技术有足够的敏感度。面试场上面试官对新技术的考察是时有的,一方面考察你对新技术的认知和理解,另一方面还可以观察你是否有持续 follow 最新的技术工作。
第二,DeepSeek-OCR 是怎么做的,主要解决了什么问题?你既然提到了 Deepseek-OCR,就要用自己的话给面试官讲清楚这个框架的基本思路,它这样的设计有什么创新之处,相比之前的 idea 有哪些不同。
第三,也是最重要的,一般这种 hot paper,主流媒体都有很多解读,那你有没有自己的一些见解呢?这是面试官非常希望听到的。
好,那接下来我们就沿着面试官的心理预期,拆解一下这道题目!
二、面试题解析
先说下实际的效果,最近网上对 DeepSeek-OCR 的讨论非常热烈,我也读了这个工作的技术报告,并且下载开源模型用实际数据测试了模型的效果。模型大小是 3B,整体识别率还是不错,但还是比 dots.ocr 差一点。
那 DeepSeek-OCR 究竟是怎么做的?为什么会引起这么大的讨论?
这篇论文本质还是一篇做 OCR 的工作,先说结论,其思路的核心就是:输入高分辨率图片,但做低激活, 从而实现高压缩比 ,减少视觉 token 数量的同时,也能保留关键信息。
因此,DeepSeek-OCR 的定位,其实做的是图像的压缩问题。那么问题来了,**为什么图像可以做压缩?**之前有没有相关的工作?如果有,是怎么做的?
首先,图像为什么可以做压缩,这个很好理解,不是什么新鲜思路。比如,这样一张图片,我们只需要拿到里面的文字和图形对应的像素格子就 OK 了,其他的空白处都是无效 token,都是可以被压缩的。
那之前有没有类似工作呢?其实是有的,之前的 qwen-vl、intern-vl 等都做了许多类似工作,但是 DeepSeek-OCR 提出了一个新的解决方案。
DeepSeek 是这样做的,看图,采用了 MOE 架构,总参数量 3B,推理时仅激活 570M 参数,核心包含 DeepEncoder,也就是一个编码器,实现高分辨率输入下低激活与高压缩比。
由 SAM 和 CLIP 串联并搭配 16 倍的卷积压缩器,最后由 DeepSeek-3B-MoE 解码输出。
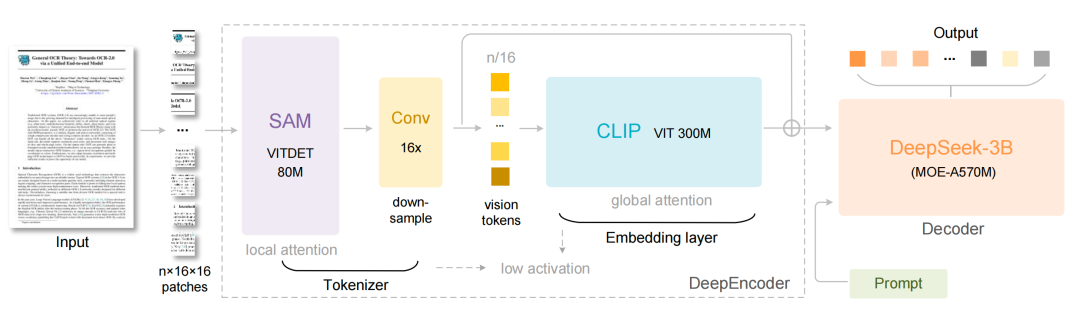
讲讲核心点思路,最开始输入图片 token 数量很大,1024×1024 图像生成 4096 个 token,DeepSeek-OCR 就采用 SAM 做初始高分辨率 token,采用窗口注意力仅关注局部区域,避免全局计算导致的高激活,这是第一层。
然后第二层,采用高压缩比的卷积模块,即图上的 16 倍下采样的卷积压缩器,将 4096 个 token 压缩至 256 个,这一步就是为了减少后续全局注意力的计算量。然后输入给 CLIP 模型以密集全局注意力提取全局语义信息。
所以总结起来就是一个局部+全局信息感知和计算的思想。
怎么衡量它的效果呢?论文其实主打的是压缩率。比如一个 1 页的中文文档有 100 token,就去测试不同压缩比下的 OCR 的识别准确率。可以通过 resize 去调节输入到模型的实际尺寸,从而去调节视觉的实际 tokens 数。
当“文本 tokens 数 / 视觉 tokens 数 = 10”,即压缩比为 10 的时候,ocr 的的准确度是 97%;当压缩比为 20 时,ocr 的准确度保持约 60%;
以上就是 DeepSeek-OCR 这个工作的核心思想了。那我们看一下第三层,对于这个工作,你是怎么看的?
DeepSeek-OCR 的成功不应归功于把文本转化成图像来表示,我们可以把图像表示成视觉 token,也可以反向操作把文字 token 表示成图像,都只是一种编码信息的载体,没有哪一种具有根本性的优越性。
从结果来看,它本质还是在做 OCR,也就是输入文档图片去做文字的识别,而不是在压缩 prompt,比如你要做 RAG,输入的 prompt 很长,几千甚至上万的 tokens。
你就把长文本转换成图片输入给模型去理解并输出,这种做法从这篇工作来看还做不到实用的程度。但相信后续会有更多的改进工作出来,大家可以持续关注。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
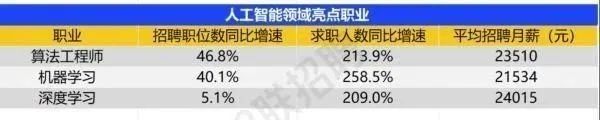
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献295条内容
已为社区贡献295条内容

所有评论(0)