OmniGuard:让AI篡改“无处遁形”的混合取证框架
OmniGuard提出了一种融合主动水印与被动检测的混合图像取证框架,能精准识别AI编辑痕迹。传统水印方案易受压缩影响,被动检测易误判。
过去几年,生成式AI在图像编辑领域几乎无所不能——它可以修复老照片、改变天气、甚至让人“凭空消失”。但与此同时,图像的真实性也变得越来越难以保证。我们怎么知道这张图是原始的,还是被AI“加工”过的?
最近读到一个非常有意思的工作——OmniGuard。它提出了一种融合“主动水印”和“被动篡改检测”的混合取证框架,在面对各种AIGC编辑、压缩和噪声等复杂场景时,依然能精准地检测和定位图像篡改区域。这种方法给图像取证带来了一种全新的思路。

为什么传统方法不够用?
以往的水印方案大致可以分成两类:
-
主动方法:在图像中预先嵌入水印,例如版权信息或定位码。当图像被修改后,系统通过对比水印变化来识别篡改。
➤ 缺点:需要提前嵌入;鲁棒性有限,一压缩或亮度变换就容易失效。 -
被动方法:不依赖任何水印,通过分析图像内容的不一致性(纹理断裂、噪声分布等)来判断是否被改动。
➤ 缺点:容易误判,比如JPEG压缩伪影也可能被当作“篡改痕迹”。
OmniGuard 的独特之处在于,它不再二选一,而是同时利用两者的优势。

OmniGuard的核心思路:主动 + 被动的“混合取证”
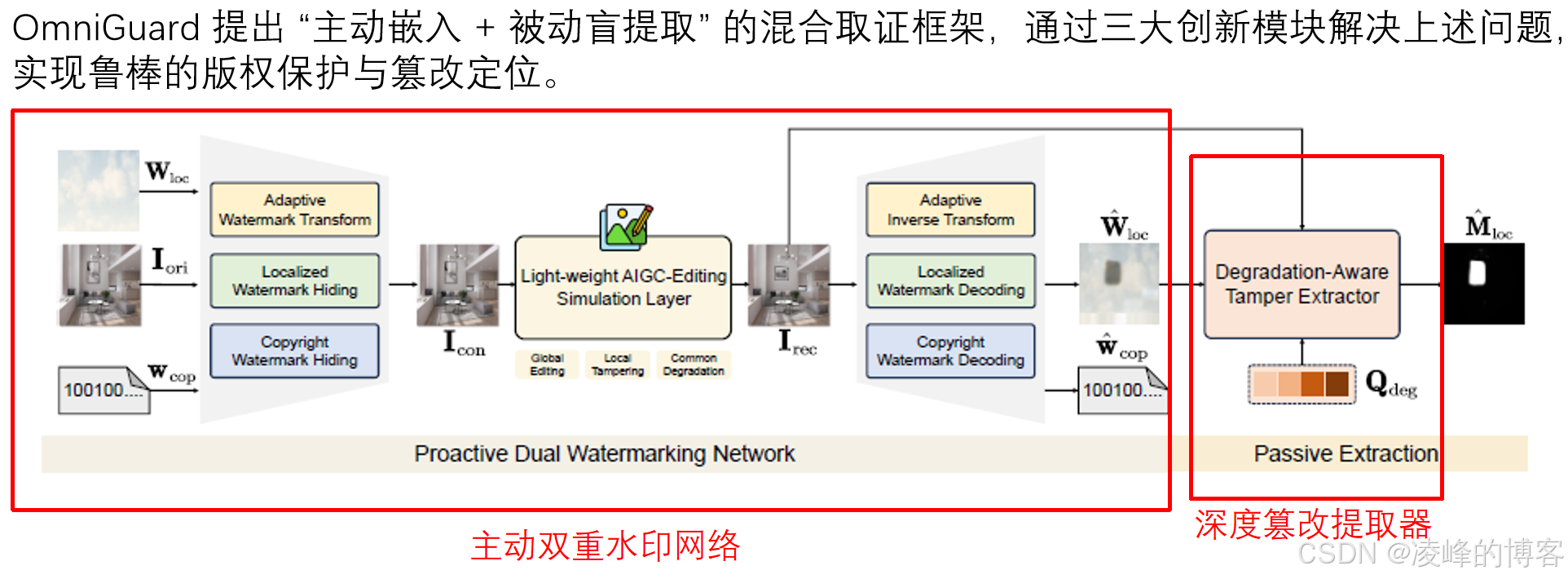
OmniGuard 的框架中有三个核心模块:
-
主动双重水印网络:系统在图像中嵌入两种不同的水印——一种用于定位篡改区域(定位水印),一种用于验证版权(版权水印)。有趣的是,它采用了“自适应向前变换”算法,让水印与图像内容更加融合,在恢复时能有效抵抗编辑带来的结构变化。
-
轻量级AIGC编辑模拟层:这是一个非常聪明的设计。研究者用一个模拟层,模仿常见的AI编辑操作(比如局部擦除、颜色变化、全局风格迁移等),在训练阶段让水印网络“提前见识”各种篡改方式,从而学会更鲁棒地嵌入与解码。
-
被动深度退化感知提取器:当没有任何水印信息可依赖时,这个模块可以“盲提取”篡改痕迹。它结合了退化特征(比如JPEG压缩、模糊)与视觉上下文,通过Swin-ViT和特征金字塔网络捕捉跨区域依赖关系,从而在复杂环境下仍能准确定位篡改区域。
性能表现如何?
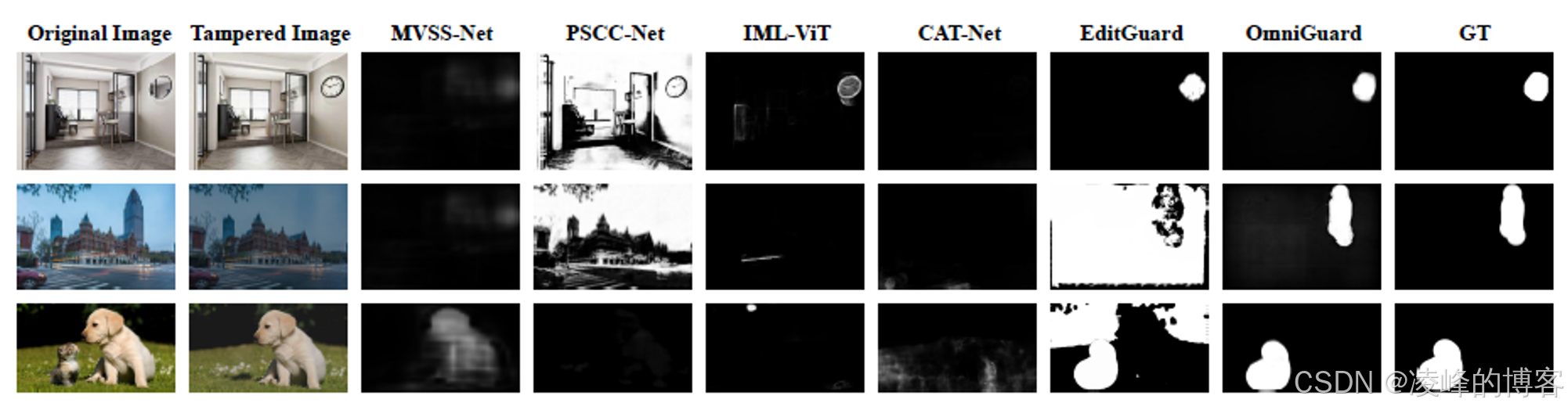
在 COCO 和 DIV2K 数据集上的实验结果相当惊人:
-
篡改定位精度:在干净条件下,F1分数 > 0.96;在退化场景(JPEG压缩、噪声干扰)下仍然保持高准确率,比 EditGuard 高出 20.7%。
-
图像保真度:同时嵌入定位和版权水印时,PSNR 达 41.78 dB、SSIM 达 0.989,几乎看不出水印存在。
-
AIGC编辑抗性:面对 InstructPix2Pix 这类复杂AI编辑,水印比特准确率仍超过 98%。
思考总结
未来的图像取证,不再是简单的“检测”或“验证”,而是一种内容与感知共融的智能防伪。它不仅在保护图像本身,更是在保护信息的可信度。
当然,它也不是完美的。论文提到在超高分辨率场景下(例如全景图),由于分辨率缩放,水印伪影会被放大;在极端退化下性能也会退化到被动检测水平。但这恰恰说明,鲁棒隐写与AIGC安全的融合仍有很大的探索空间。
未来,作者计划尝试引入扩散模型增强隐写鲁棒性,甚至建立低质量图像的取证排除标准——这会是一个值得持续关注的方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)