【Python大数据+AI毕设实战】社交媒体舆情数据可视化分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
【Python大数据+AI毕设实战】社交媒体舆情数据可视化分析系统、计算机毕业设计、包括数据爬取、Spark、数据分析、数据可视化、Hadoop、实战教学
🎓 作者:计算机毕设小月哥 | 软件开发专家
🖥️ 简介:8年计算机软件程序开发经验。精通Java、Python、微信小程序、安卓、大数据、PHP、.NET|C#、Golang等技术栈。
🛠️ 专业服务 🛠️
- 需求定制化开发
- 源码提供与讲解
- 技术文档撰写(指导计算机毕设选题【新颖+创新】、任务书、开题报告、文献综述、外文翻译等)
- 项目答辩演示PPT制作
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅
这里写目录标题
基于大数据的社交媒体舆情数据可视化分析系统-功能介绍
《基于Python大数据+AI毕设实战的社交媒体舆情数据可视化分析系统》是一个综合性的数据处理与分析平台,旨在将海量、非结构化的社交媒体文本数据转化为直观、可洞察的商业智能视图。本系统后端主体采用Python语言及主流的Django框架进行开发,确保了开发的灵活性与高效性;在数据处理核心层面,创新性地集成了Apache Spark大数据计算引擎,通过其内存计算的优越性,对TB级别的舆情数据进行快速的清洗、转换和聚合分析,充分体现了大数据技术在实际业务场景中的处理能力。系统利用Spark SQL执行复杂的查询与统计,并通过Pandas与NumPy库进行精细化的数据操作。前端界面则基于Vue.js渐进式框架,配合ElementUI组件库和强大的Echarts图表库,实现了丰富多样且交互友好的数据可视化展示。整个系统涵盖了从数据源接入、HDFS分布式存储、Spark批量处理到最终可视化呈现的全链路。功能上,系统实现了包括情感状态分布、舆情热度随时间变化趋势、用户活跃时段、高互动内容挖掘、KOL(关键意见领袖)识别、正负面情感高频词提取以及基于LDA主题模型的内容聚类等在内的十五项核心分析模块。它不仅是一个功能完备的Web应用,更是一个完整体现了“数据采集-数据存储-数据分析-数据可视化”大数据处理流程的毕业设计典范,为学生提供了一个从理论到实践的绝佳项目案例。
基于大数据的社交媒体舆情数据可视化分析系统-选题背景意义
选题背景
如今咱们的生活差不多被各种社交媒体给包围了,每天随手刷刷微博、看看短视频,海量的信息就这么产生了。这些信息其实挺有意思的,它就像一面镜子,反映出大家对某个热点事件、某个新产品甚至某个明星的看法和情绪。可是问题也来了,这些数据量实在太大了,而且乱七八糟的,有文字、有表情包,更新速度还特别快。想靠人工去一条条看,弄明白大家到底在聊啥、是夸还是骂,基本上是不可能完成的任务,费时又费力,而且还看不全面。这就催生了一个很实在的需求:我们需要一个能自动、快速搞定这件事的工具。传统的单机程序或者简单的数据库查询,在处理这种规模的数据时会显得力不从心,速度慢甚至直接卡死。所以,把Spark这种正经的大数据技术用进来,再结合一些文本分析(AI)的方法,去搭建一个专门分析这些舆情数据的系统,就成了一个挺自然也挺有挑战性的想法。这个课题就是想尝试解决这个问题,做一个能处理大规模社交媒体数据的分析系统。
选题意义
说实话,作为一个毕业设计,这个系统肯定没法跟商业公司里上千万投入的产品比,它的主要价值还是体现在学习和实践上,但确实也有一些实实在在的用处。从学生个人成长的角度看,完成这个项目是一个非常好的综合锻炼。它不是做一个简单的增删改查网站就完事了,而是要求你把后端(比如Python和Django)、前端(Vue和Echarts)和核心的大数据技术(Spark)这三大块都串起来。从数据怎么清洗,到用Spark怎么做聚合分析,再到最后怎么用图表把它画出来,整个流程走一遍,能让你对一个完整数据项目的开发有个特别清晰的认识,这比单纯看书本理论要深刻得多。从实际应用的角度来看,这个系统虽然是个“迷你版”,但它的设计思路是有价值的。比如一个小公司想看看网上用户对自家新出的酸奶是好评多还是差评多,用这个系统就能快速生成一个情感分布饼图和讨论热词的词云,帮他们快速把握市场反馈。或者,一个活动主办方想了解大家对某个线上音乐节的讨论热度,也可以通过这个系统分析舆情趋势,看看哪个时间点讨论最激烈,为下次活动提供参考。总的来说,这个项目能很好地展示我们综合运用不同技术解决一个现实问题的能力,算是一个技术栈比较全面、有点深度的毕业作品。
基于大数据的社交媒体舆情数据可视化分析系统-技术选型
大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
开发语言:Python+Java(两个版本都支持)
后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
数据库:MySQL
基于大数据的社交媒体舆情数据可视化分析系统-视频展示
【Python大数据+AI毕设实战】社交媒体舆情数据可视化分析系统
基于大数据的社交媒体舆情数据可视化分析系统-图片展示
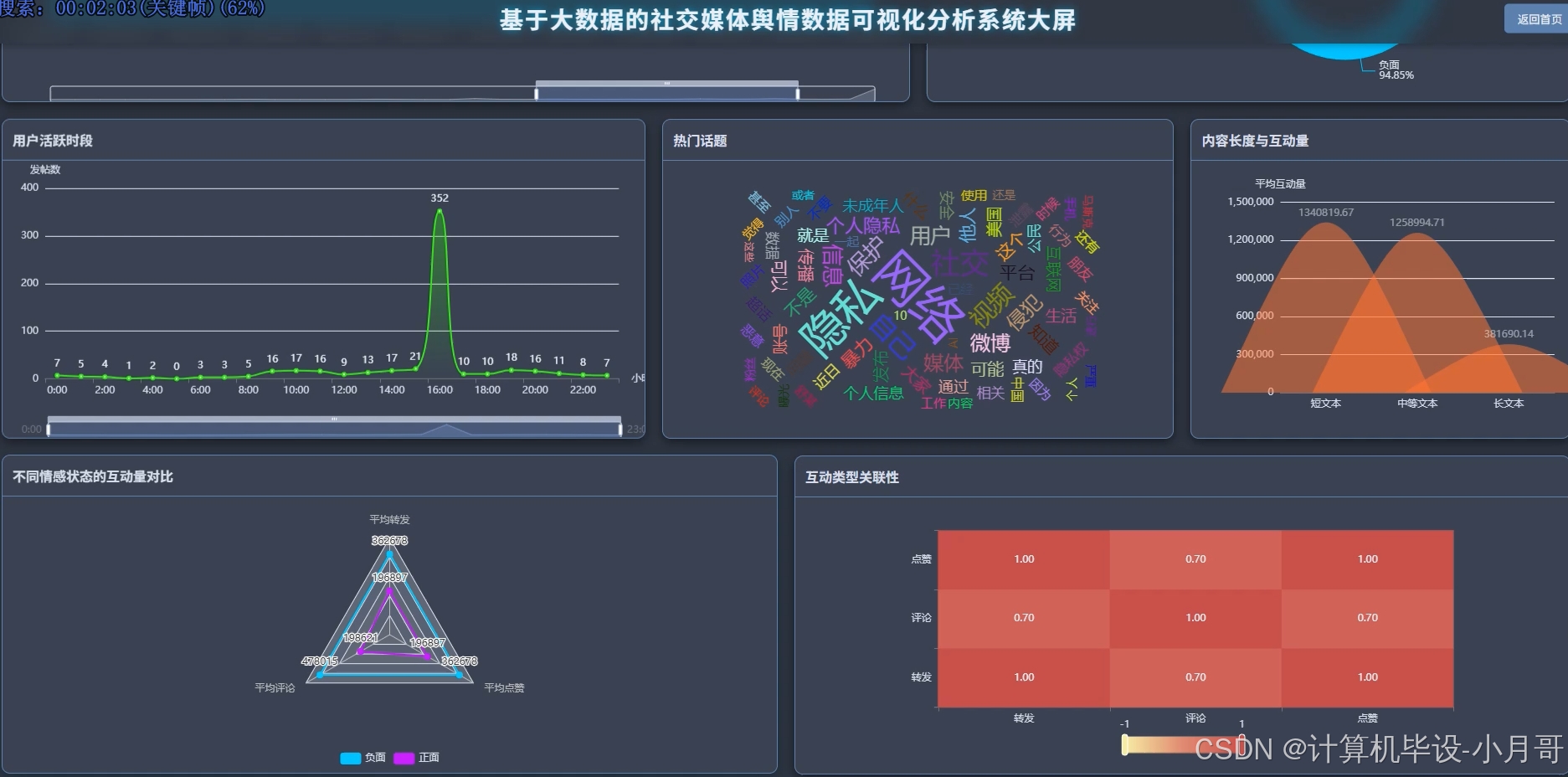
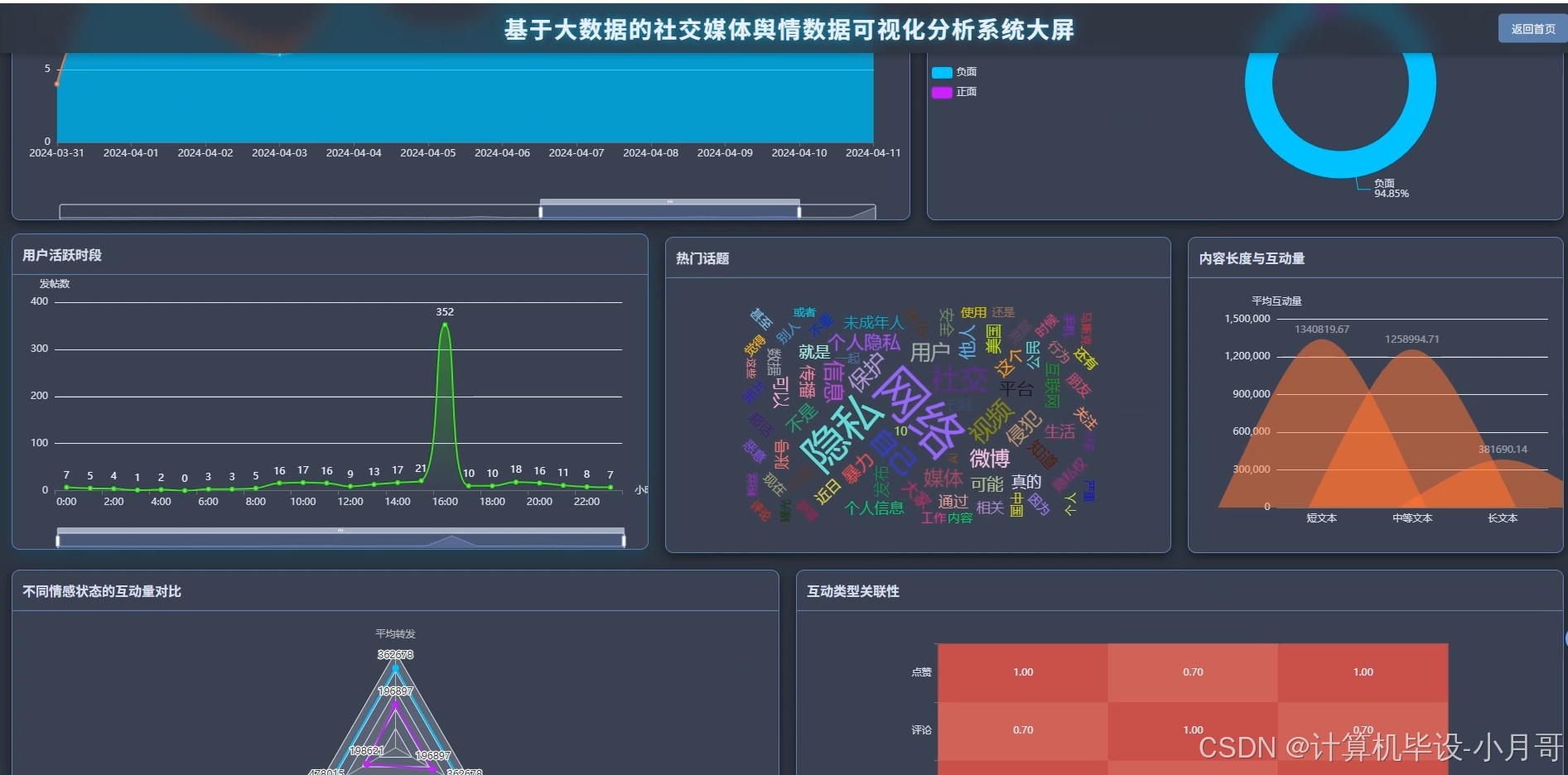


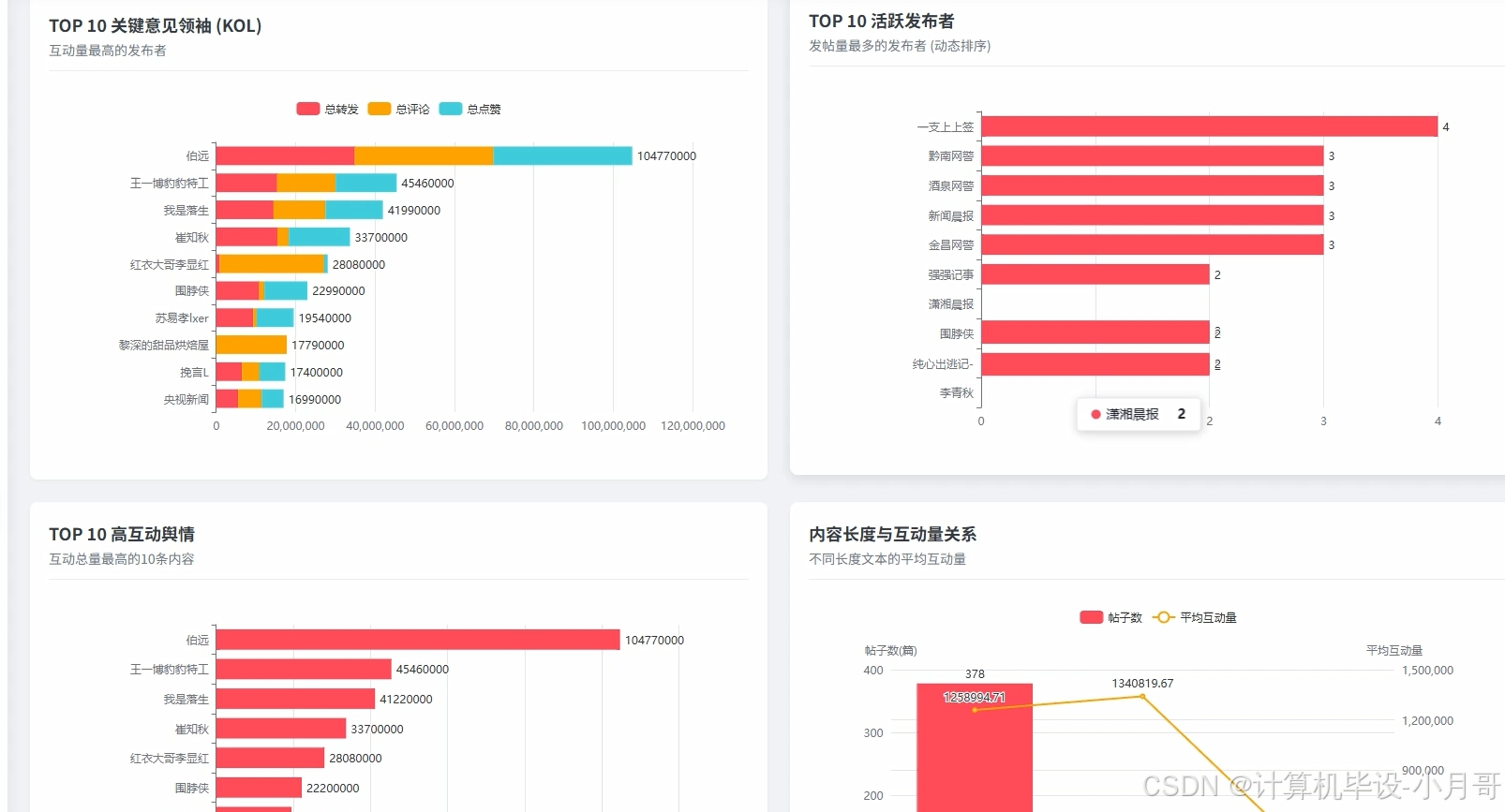

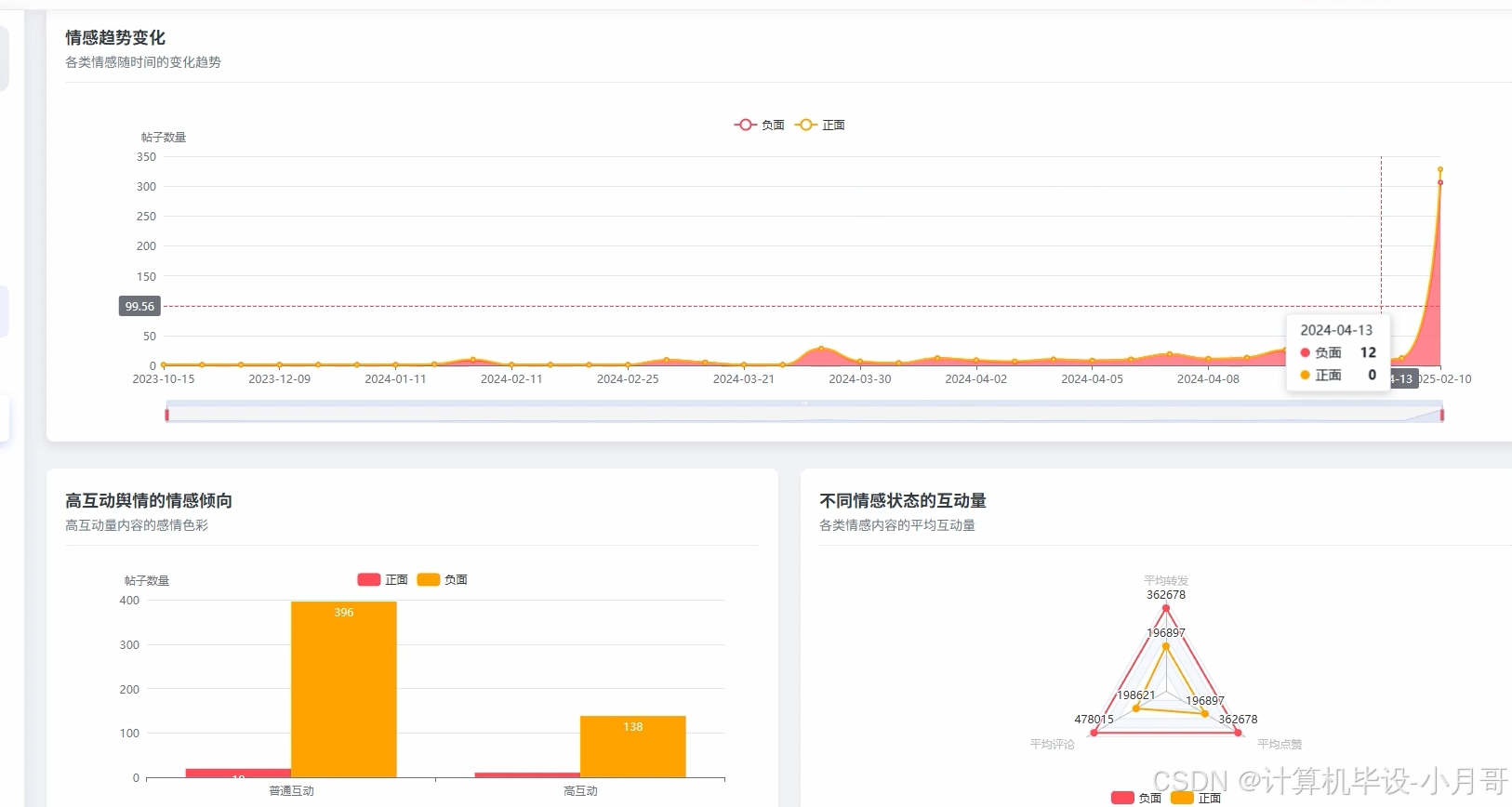
基于大数据的社交媒体舆情数据可视化分析系统-代码展示
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import StringType, ArrayType
import jieba
# 初始化SparkSession,这是所有Spark应用的入口
spark = SparkSession.builder.appName("SocialMediaAnalysis").master("local[*]").getOrCreate()
# 假设df是已经从HDFS加载并完成了预处理(字段重命名、类型转换、空值填充等)的DataFrame
# df = spark.read.csv("hdfs://namenode:9000/path/to/preprocessed_data.csv", header=True, inferSchema=True)
# 为了演示,我们创建一个模拟的DataFrame
data = [
(1, "Positive", "今天天气真好,很开心!", "user_A", 10, 20, 30),
(2, "Negative", "这个产品太难用了,非常失望。", "user_B", 1, 5, 2),
(3, "Positive", "强烈推荐这家餐厅,味道一级棒!", "user_A", 50, 100, 200),
(4, "Negative", "等了半个小时才上菜,服务太差了。", "user_C", 2, 8, 3),
(5, "Positive", "这个功能设计得太棒了,必须点赞!", "user_B", 25, 60, 150)
]
columns = ["id", "sentiment_status", "content", "publisher", "forwards", "comments", "likes"]
df = spark.createDataFrame(data, columns)
# --- 核心功能1: 情感状态分布分析 (sentiment_distribution_analysis) ---
# 计算数据总条数,用于后续计算百分比
total_count = df.count()
# 按情感状态分组并计数
sentiment_distribution = df.groupBy("sentiment_status").count()
# 计算每种情感状态的占比,并格式化为两位小数
sentiment_distribution = sentiment_distribution.withColumn("percentage", F.round((F.col("count") / total_count) * 100, 2))
# 为了方便前端Echarts等工具使用,将列重命名为通用的 'name' 和 'value'
sentiment_distribution = sentiment_distribution.select(
F.col("sentiment_status").alias("name"),
F.col("count").alias("value"),
F.col("percentage")
)
# 打印结果到控制台,实际项目中会保存到CSV或数据库
print("--- 情感状态分布分析结果 ---")
sentiment_distribution.show()
# sentiment_distribution.repartition(1).write.csv("path/to/sentiment_distribution_analysis.csv", header=True, mode="overwrite")
# --- 核心功能2: 热门话题词云分析 (hot_topics_word_cloud_analysis) ---
# 定义一个停用词列表,用于过滤掉无意义的词语
stop_words = ["的", "了", "在", "是", "我", "你", "他", "她", "它", "也", "都", "就", "还", "有", "很", "太"]
# 定义一个UDF(用户自定义函数),用于对每条内容进行中文分词
def segment_chinese(text):
return [word for word in jieba.cut(text) if word not in stop_words and len(word.strip()) > 1]
segment_udf = F.udf(segment_chinese, ArrayType(StringType()))
# 应用UDF进行分词,生成一个包含词语列表的新列
words_df = df.withColumn("words", segment_udf(F.col("content")))
# 使用explode函数,将每个词语列表展开,使得每行只包含一个词
exploded_words_df = words_df.select(F.explode("words").alias("word"))
# 对词语进行分组计数,得到词频
word_counts = exploded_words_df.groupBy("word").count()
# 按词频降序排序,选出最热门的100个词
hot_words = word_counts.orderBy(F.desc("count")).limit(100)
# 重命名以符合词云图数据格式
hot_words = hot_words.select(F.col("word").alias("name"), F.col("count").alias("value"))
# 打印结果到控制台
print("--- 热门话题词云分析结果 ---")
hot_words.show()
# hot_words.repartition(1).write.csv("path/to/hot_topics_word_cloud_analysis.csv", header=True, mode="overwrite")
# --- 核心功能3: 关键意见领袖(KOL)识别 (key_opinion_leader_identification_analysis) ---
# 按发布者(publisher)进行分组
kol_analysis = df.groupBy("publisher")
# 使用agg进行多维度聚合,计算每个发布者的总转发、总评论、总点赞和总发帖数
kol_stats = kol_analysis.agg(
F.sum("forwards").alias("total_forwards"),
F.sum("comments").alias("total_comments"),
F.sum("likes").alias("total_likes"),
F.count("id").alias("post_count")
)
# 计算综合影响力分数(这里简单地将互动量相加)
kol_with_score = kol_stats.withColumn(
"total_engagement",
F.col("total_forwards") + F.col("total_comments") + F.col("total_likes")
)
# 按综合影响力分数降序排序,识别影响力最高的KOL
top_kols = kol_with_score.orderBy(F.desc("total_engagement"))
# 选择最终需要的字段进行展示
final_kol_report = top_kols.select(
"publisher",
"total_engagement",
"total_forwards",
"total_comments",
"total_likes",
"post_count"
)
# 打印结果到控制台
print("--- 关键意见领袖(KOL)识别结果 ---")
final_kol_report.show()
# final_kol_report.repartition(1).write.csv("path/to/key_opinion_leader_identification_analysis.csv", header=True, mode="overwrite")
# 关闭SparkSession
spark.stop()
基于大数据的社交媒体舆情数据可视化分析系统-结语
🌟 欢迎:点赞 👍 收藏 ⭐ 评论 📝
👇🏻 精选专栏推荐 👇🏻 欢迎订阅关注!
大数据实战项目
PHP|C#.NET|Golang实战项目
微信小程序|安卓实战项目
Python实战项目
Java实战项目
🍅 ↓↓主页获取源码联系↓↓🍅

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)