【AI论文】通过自监督预训练推进端到端像素空间生成建模
摘要:本研究提出语言中心的多模态表示学习框架(LCO-EMB),通过分析多模态大语言模型(MLLMs)的隐式跨模态对齐特性,结合轻量级对比学习微调提升模型表示能力。研究揭示了生成预训练阶段的隐式对齐机制,设计了基于LoRA的微调策略,并提出生成-表示缩放定律(GRSL)。实验表明,该方法在视觉文档检索、多语言图像检索等任务中显著提升性能,验证了生成能力与表示能力的正相关性。研究成果为优化MLLMs
摘要:与潜在空间生成模型相比,像素空间生成模型往往更难训练,且性能通常较差,二者在表现和效率上长期存在差距。本文提出一种新颖的两阶段训练框架,有效缩小了像素空间扩散模型与一致性模型在性能上的差距。在第一阶段,我们对编码器进行预训练,使其从干净图像中捕捉有意义的语义信息,同时将编码器与同一确定性采样轨迹上的点进行对齐——该轨迹描述了从先验分布到数据分布的点演变过程。在第二阶段,我们将预训练后的编码器与随机初始化的解码器结合,并针对扩散模型和一致性模型进行端到端的完整模型微调。我们的训练框架在ImageNet数据集上展现出强大的实证性能。具体而言,我们的扩散模型在ImageNet-256和ImageNet-512上分别以75次函数评估(NFE)达到了2.04和2.35的FID(Fréchet Inception Distance)分数,在生成质量和效率上大幅超越了先前的像素空间方法,同时在相当的训练成本下可与领先的基于变分自编码器(VAE)的模型相媲美。此外,在ImageNet-256上,我们的一致性模型在单次采样步骤中取得了8.82的优异FID分数,显著优于其潜在空间对应模型。据我们所知,这是首次在不依赖预训练VAE或扩散模型的情况下,直接在高分辨率图像上成功训练一致性模型。Huggingface链接:Paper page,论文链接:2510.11693
研究背景和目的
研究背景:
近年来,多模态大语言模型(MLLMs)在跨模态理解和生成任务中展现出强大的能力,通过结合视觉、语言等多种模态的信息,实现了对复杂场景的深度理解和精准回应。
然而,尽管基于对比学习(Contrastive Learning, CL)的微调方法在提升MLLMs的表示能力方面取得了一定成效,但其背后的优势机制仍未被充分探索。传统CL方法依赖于大规模的跨模态配对数据进行训练,计算成本高昂且性能提升趋于平稳,特别是在需要深层跨模态理解的任务中表现欠佳,如多语言图像检索、视觉文本表示等复杂任务。
与此同时,MLLMs在生成预训练阶段通过语言解码器隐式地实现了跨模态对齐,这一特性为提升模型表示能力提供了新的思路。然而,如何有效利用这一隐式对齐特性,结合轻量级的对比学习微调,以进一步提升MLLMs的表示质量,仍是待解决的问题。
研究目的:
本研究旨在深入探索MLLMs在生成预训练阶段隐式实现的跨模态对齐机制,并提出一种语言中心的多模态表示学习框架(Language-Centric Omnimodal Embedding framework, LCO-EMB),通过轻量级的对比学习微调,提升MLLMs在多模态任务中的表示能力。具体研究目的包括:
- 揭示隐式跨模态对齐机制:通过分析MLLMs在生成预训练阶段的内部表示,揭示其如何通过语言解码器实现跨模态信号的隐式对齐。
- 提出LCO-EMB框架:设计一种语言中心的多模态表示学习框架,利用轻量级的对比学习微调,进一步提升MLLMs的表示质量。
- 探索生成-表示缩放定律:研究MLLMs的生成能力与其表示能力之间的关系,提出生成-表示缩放定律(Generation-Representation Scaling Law, GRSL),为优化MLLMs的表示能力提供理论依据。
- 验证框架有效性:通过广泛的实验验证LCO-EMB框架在多模态任务中的有效性,包括视觉文档检索、多语言图像检索、视觉问答等任务。
研究方法
1. 隐式跨模态对齐分析:
为了揭示MLLMs在生成预训练阶段的隐式跨模态对齐机制,本研究采用了以下方法:
-
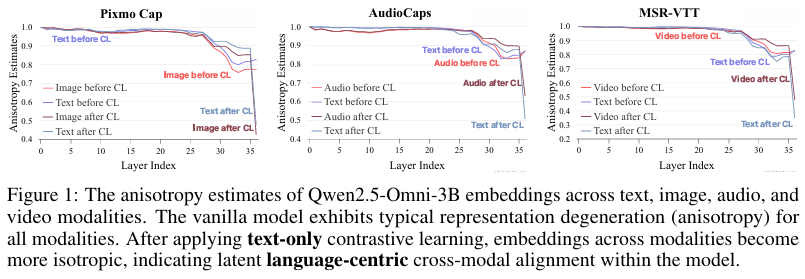
各向异性分析:通过计算MLLMs在不同模态(文本、图像、音频、视频)下的嵌入表示的各向异性程度,评估其是否通过生成预训练实现了跨模态对齐。各向异性程度用于量化嵌入空间的分布均匀性,较低的各向异性表明嵌入表示更加均匀和各向同性,这通常意味着更好的跨模态对齐。
-
核相似性分析:通过核级相似性结构,量化不同模态表示之间的相似性。具体来说,使用相互k近邻(mutual k NN)方法,评估不同模态表示在隐藏层中的自相似性,从而验证隐式跨模态对齐的存在。
2. LCO-EMB框架设计:
基于隐式跨模态对齐的分析结果,本研究设计了LCO-EMB框架,具体设计如下:
-
语言中心的多模态数据:利用语言中心的数据进行轻量级的对比学习微调,避免大规模跨模态配对数据的高昂计算成本。语言中心的数据包括文本描述、图像标题、视频字幕等,这些数据天然地融合了多种模态的信息。
-
LoRA微调策略:采用低秩适应(Low-Rank Adaptation, LoRA)策略,在最小化修改MLLMs预训练知识的前提下,通过轻量级的对比学习微调,提升模型的表示能力。
LoRA通过引入低秩矩阵来近似权重更新,从而在保持模型原有知识的同时,注入新的知识。 -
多模态表示对齐:通过对比学习,将MLLMs的中间表示与目标表示空间对齐。具体来说,使用语言解码器的嵌入层作为目标空间,通过最小化对比损失来优化模型的中间表示,从而提升模型的跨模态理解能力。
3. 生成-表示缩放定律探索:
为探索MLLMs的生成能力与其表示能力之间的关系,本研究提出GRSL,并通过以下方法进行验证:
-
基线模型选择:选择不同生成能力的MLLMs作为基线模型,包括Qwen2.5-VL和Qwen2.5-Omni等。这些模型在生成任务中表现出不同的性能,从而可以评估其生成能力对表示能力的影响。
-
生成能力评估:通过生成任务的性能评估MLLMs的生成能力,如文本生成、图像描述生成等。
具体来说,使用生成文本的流畅性、多样性和准确性等指标来评估模型的生成能力。 -
表示能力评估:在多模态任务中评估MLLMs的表示能力,如视觉文档检索、多语言图像检索等。使用准确率、召回率、F1分数等指标来评估模型的表示能力。
-
缩放定律验证:通过分析生成能力与表示能力之间的关系,验证GRSL的有效性。具体来说,绘制生成能力与表示能力的散点图,并拟合线性回归模型,以验证两者之间是否存在正相关关系。
研究结果
1. 隐式跨模态对齐验证:
实验结果表明,MLLMs在生成预训练阶段确实实现了隐式的跨模态对齐。具体表现为:
-
各向异性降低:经过生成预训练后,MLLMs在不同模态下的嵌入表示的各向异性程度显著降低,表明其内部表示更加均匀和各向同性。
这有助于提升模型在跨模态任务中的性能。 -
核相似性提升:不同模态表示之间的核相似性显著提升,进一步验证了隐式跨模态对齐的存在。
这表明MLLMs在生成预训练阶段确实学会了如何将不同模态的信息融合到一个共享的表示空间中。
2. LCO-EMB框架有效性:
在多模态任务中的实验结果表明,LCO-EMB框架显著提升了MLLMs的表示能力。
具体表现为:
-
视觉文档检索:在视觉文档检索任务中,LCO-EMB框架取得了显著优于基线模型的性能。
这证明了LCO-EMB框架在理解复杂文档布局和文本信息方面的优势。 -
多语言图像检索:在多语言图像检索任务中,LCO-EMB框架同样表现出色。
这证明了LCO-EMB框架在跨语言对齐方面的能力,能够有效地将不同语言的图像和文本对齐到同一个表示空间中。 -
视觉问答:在视觉问答任务中,LCO-EMB框架通过结合视觉和语言信息,实现了更精准的回答生成。
这表明LCO-EMB框架在理解复杂场景和生成准确回答方面具有优势。
3. 生成-表示缩放定律验证:
实验结果表明,MLLMs的生成能力与其表示能力之间存在正相关关系,验证了GRSL的有效性。具体表现为:
-
生成能力提升:随着MLLMs生成能力的提升,其在多模态任务中的表示能力也显著增强。这表明生成能力确实对表示能力具有重要影响。
-
理论解释支持:通过PAC-Bayesian泛化界理论解释,证明了MLLMs的生成质量确实决定了其表示性能的上界。这为GRSL提供了坚实的理论基础,进一步验证了其有效性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献160条内容
已为社区贡献160条内容

所有评论(0)