OmniParser: 微软为AI装上「慧眼」,让大模型真正「看懂」并「操控」电脑
微软开源OmniParser工具,为AI赋予"视觉操控"能力。该工具通过计算机视觉技术识别屏幕元素(如按钮、输入框等),并转换为结构化数据,使大语言模型能理解和操作图形界面。V2版本显著提升检测精度和速度,延迟降低60%,与GPT-4o配合使用时界面理解准确率提升近50倍。应用场景包括办公自动化、软件测试、无障碍辅助等。开发者可通过下载模型权重进行本地部署体验。这一技术突破标志
OmniParser: 微软为AI装上「慧眼」,让大模型真正「看懂」并「操控」电脑
想象一下,如果AI不仅能理解文字,还能像人类一样「看见」电脑屏幕上的按钮、输入框,甚至能自己动手点击操作——这不再是科幻,而是微软最新开源工具OmniParser带来的现实!
OmniParser 是微软开发的纯视觉基GUI智能体解析工具,可将屏幕截图转换为结构化元素,帮助大语言模型(LLM)理解和操控计算机。
核心功能
OmniParser通过计算机视觉技术识别UI中的可交互元素(如按钮、图标),生成边界框及唯一ID,并与大语言模型结合实现自动化操作。例如,在网页中定位“餐厅”选项、输入关键词、筛选素食餐厅等任务。
技术升级
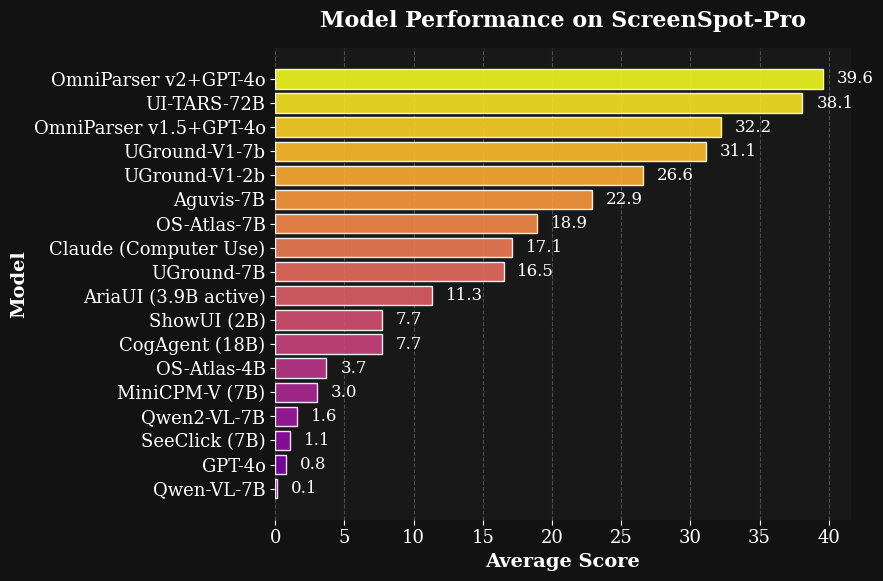
OmniParser V2通过更大规模数据训练,显著提升检测小图标和推理速度,推理延迟降低60%。其兼容OpenAI GPT-4V、DeepSeek R1等主流模型,在高分辨率基准测试中准确率达39.6%,远超原始GPT-4V(0.8%)。

应用场景
适用于图形界面自动化、智能客服、游戏辅助等领域。例如,在旅行规划任务中,OmniParser可完成餐厅筛选、行程添加等复杂操作
🤔 OmniParser究竟是什么?
OmniParser是微软研究院开发的一款基于纯视觉的AI工具,简单来说,它就像是给AI装上了一双「电子眼」,让AI能够通过屏幕截图「看」懂电脑界面上的各种元素,并理解它们的功能。
以往的AI虽然聪明,但在操作电脑界面时常常「视而不见」,无法准确识别屏幕上的按钮、输入框等元素。而OmniParser解决了这个关键问题,它能:
- 精准识别屏幕上的每一个可交互元素(按钮、输入框、下拉菜单、链接等)
- 理解这些元素的功能(比如「这是一个搜索按钮」「这是一个提交表单的按钮」)
- 将视觉信息转换为结构化数据(如JSON格式),方便AI处理
- 与GPT-4o、DeepSeek等大模型协同工作,让AI能够像人类一样操作电脑
🔍 它是如何工作的?
OmniParser的工作原理可以用一个简单的比喻来理解:就像人类通过眼睛看到物体,再通过大脑理解物体的功能一样,OmniParser也有「看」和「理解」两个核心步骤。
1. 「看」—— 识别界面元素
OmniParser使用了经过优化的YOLOv8检测模型,专门训练用于识别界面元素。这个模型就像是AI的「视觉系统」,能够在屏幕截图中精确「定位」各种可交互元素的位置,包括:
- 按钮(无论大小、形状、颜色如何)
- 输入框和文本域
- 下拉菜单和复选框
- 链接和图标
- 甚至是小到32像素的微小图标
2. 「理解」—— 分析元素功能
在识别出元素位置后,OmniParser使用BLIP-2强化的描述模型(就像是AI的「理解系统」)来分析每个元素的功能和含义。它会生成类似人类描述的文本,比如:
- 「这是一个蓝色圆形的搜索按钮」
- 「这是一个带下拉箭头的日期选择框」
- 「这是一个用于提交表单的绿色按钮」
3. 「转化」—— 生成结构化数据
最后,OmniParser将这些视觉信息和理解结果转化为机器容易处理的结构化数据(如JSON格式),这样AI大模型就能理解界面结构并做出决策。
4. 「行动」—— 操控电脑界面
当与GPT-4o、DeepSeek等大语言模型结合使用时,AI就能根据OmniParser提供的信息,决定「点击哪个按钮」「在哪个输入框输入内容」等,从而实现对电脑界面的自动操作。
🚀 OmniParser V2.0的强大之处
微软最近发布的OmniParser V2.0版本相比V1版本有了显著提升:
1. 识别能力更强
- 能够更准确地检测更小的可交互元素
- 对不同类型界面(网页、桌面软件、手机APP等)的兼容性更好
2. 速度更快
- 推理速度大幅提升,延迟降低了60%
- 让AI的操作更加流畅自然
3. 性能更优
- 在高分辨率界面测试中,V2+GPT-4o的准确率达到了39.6%,而单独使用GPT-4o的准确率仅为0.8%
- 这意味着OmniParser让AI的界面理解能力提升了近50倍!
💡 它能用来做什么?应用场景大揭秘
1. 智能办公自动化
想象一下,你只需要对AI说一声「帮我整理一下上周的销售数据并生成报表」,AI就能:
- 自动打开Excel文件
- 识别并点击相应的功能按钮
- 找到并处理正确的数据
- 按照你的要求生成报表
这一切都不需要你手动操作,大大提高了工作效率!
2. 自动化软件测试
对于软件开发者来说,OmniParser可以:
- 自动测试各种软件界面
- 检测按钮、链接等元素是否正常工作
- 发现潜在的界面问题和漏洞
- 节省大量手动测试的时间和精力
3. 智能个人助手
结合语音识别,OmniParser可以让AI助手真正「看懂」并「操作」你的电脑:
- 「帮我打开浏览器搜索今天的天气」
- 「在Word里帮我写一份会议纪要」
- 「帮我整理邮箱里的重要邮件」
4. 无障碍应用
对于视力障碍或行动不便的用户,OmniParser可以:
- 通过AI「阅读」屏幕上的内容
- 提供语音反馈,描述界面上有哪些元素
- 帮助用户通过语音命令控制电脑
- 大大改善用户体验和生活质量
5. 跨平台应用开发
对于开发者来说,OmniParser可以:
- 帮助开发跨平台的自动化工具
- 无需为不同系统单独开发界面交互代码
- 简化应用开发流程,提高开发效率
🔧 如何体验OmniParser?
如果你也想体验这款神奇的工具,可以按照以下步骤进行本地部署:
1. 准备环境
# 创建虚拟环境
conda create -n "omni" python==3.12
conda activate omni
# 安装依赖
pip install -r requirements.txt
2. 下载模型
# 下载OmniParser V2模型权重
rm -rf weights/icon_detect weights/icon_caption weights/icon_caption_florence
for f in icon_detect/{train_args.yaml,model.pt,model.yaml} icon_caption/{config.json,generation_config.json,model.safetensors}; do
huggingface-cli download microsoft/OmniParser-v2.0 "$f" --local-dir weights;
done
mv weights/icon_caption weights/icon_caption_florence
3. 启动演示
# 运行Gradio演示
python gradio_demo.py
启动后,你就可以在浏览器中上传屏幕截图,体验OmniParser的识别能力了!
📊 技术背后的秘密
OmniParser之所以如此强大,离不开其背后的数据驱动和技术创新:
1. 海量数据训练
- 使用了67,000+精准标注的界面数据集
- 从热门网页中提取了各类界面元素的样本
- 每个元素都有详细的功能描述和标签
2. 双模型协同工作
- 检测模型:负责「看」,识别元素位置
- 描述模型:负责「理解」,分析元素功能
- 两者协同工作,形成完整的视觉解析系统
3. 与大模型无缝集成
OmniParser不仅自己强大,还能与GPT-4o、DeepSeek、Qwen、Anthropic等大模型无缝集成,让这些聪明的AI真正拥有「动手能力」。
🔮 未来展望
随着OmniParser等技术的发展,我们可以预见:
-
AI操作能力将大幅提升:未来的AI不仅能理解文字,还能像人类一样「看」和「操作」电脑
-
人机交互将更加自然:我们可以通过自然语言命令让AI帮我们完成各种电脑操作
-
自动化程度将更高:更多重复性的电脑操作将被AI接管,人类可以专注于更有创造性的工作
-
无障碍技术将更加普及:视障人士和行动不便者将能更轻松地使用电脑
💡 结语
OmniParser的出现,标志着AI从「理解文字」向「理解视觉」迈出了重要一步。它让AI不仅「听得懂」,还能「看得懂」并「做得好」,为人工智能与人类世界的交互开辟了新的可能性。
无论你是普通用户、开发者还是研究人员,OmniParser都值得关注。它不仅是一个强大的工具,更代表了AI发展的一个重要方向——让人工智能真正理解并融入我们的数字生活。
随着技术的不断进步,我们期待看到更多像OmniParser这样的创新工具,为我们的工作和生活带来更多便利和惊喜!
小贴士:如果你想体验OmniParser但不想自己部署,也可以关注微软官方发布的在线演示或相关集成产品,未来可能会有更多基于OmniParser技术的应用问世哦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)