清华大学朱军教授团队与英伟达联手:rCM让百亿参数AI生成图像与视频加速50倍
清华大学朱军教授团队与英伟达Deep Imagination研究组联合提出rCM(Score-Regularized Continuous-Time Consistency Model,分数正则化连续时间一致性模型)。将百亿参数扩散模型的上百步推理过程压缩至1-4步,实现了高达50倍的加速,同时保证了生成质量与多样性。Wan2.1 T2V 14B 4步生成的视频扩散模型在图像与视频合成等领域已经是
清华大学朱军教授团队与英伟达Deep Imagination研究组联合提出rCM(Score-Regularized Continuous-Time Consistency Model,分数正则化连续时间一致性模型)。

将百亿参数扩散模型的上百步推理过程压缩至1-4步,实现了高达50倍的加速,同时保证了生成质量与多样性。

Wan2.1 T2V 14B 4步生成的视频
扩散模型在图像与视频合成等领域已经是基石,但生成较慢。生成一张高质量图片,模型需要迭代计算数十步甚至上百步,这极大地限制了其在实时应用中的普及。
为了让扩散模型跑得更快,学术界和工业界提出各种各样的蒸馏方案,将庞大模型的知识压缩,用更少的步数完成高质量生成。
其中,连续时间一致性模型(sCM)因其理论上的优美,在学术数据集上表现突出,备受关注。
优雅模型的现实困境
sCM在ImageNet数据集上成功蒸馏了高达15亿参数的模型,展现了不错的扩展性。但这与真实世界的需求相去甚远。
现代大规模模型的训练,依赖于一系列复杂的工程技术,例如BF16混合精度、FlashAttention和上下文并行(Context Parallelism, CP)。这些技术是为了在有限的硬件资源下,训练动辄百亿参数的模型。sCM的核心计算之一是雅可比-向量积(Jacobian-vector product, JVP),它在这些现代训练基础设施上,计算过程变得异常复杂,并会产生难以忽视的数值误差。
更严重的问题出现在生成质量上。以往的学术评估,多集中在用FID(Fréchet Inception Distance)指标衡量的弱条件图像生成任务上,比如ImageNet分类。而现实中的文生图(T2I)和文生视频(T2V)任务,是强条件的,并且对细节的要求远超FID所能衡量的范畴。
当研究人员将纯sCM蒸馏方法应用于T2I和T2V任务时,质量问题立刻显现出来。对于一些简单的提示词,sCM生成的图片看起来和原模型(教师模型)差不多。可一旦遇到需要精细细节的挑战性场景,比如在图片中渲染微小的文字,其生成质量便会断崖式下跌。这种问题并非简单地扩大模型规模就能解决。
视频生成任务对质量的要求更加苛刻,因为人眼对时间上的不一致性极为敏感。sCM蒸馏后的视频模型,生成的画面出现了模糊的纹理和不稳定的物体几何形状,比如物体之间会莫名其妙地相互穿透,这些视觉失真非常明显。
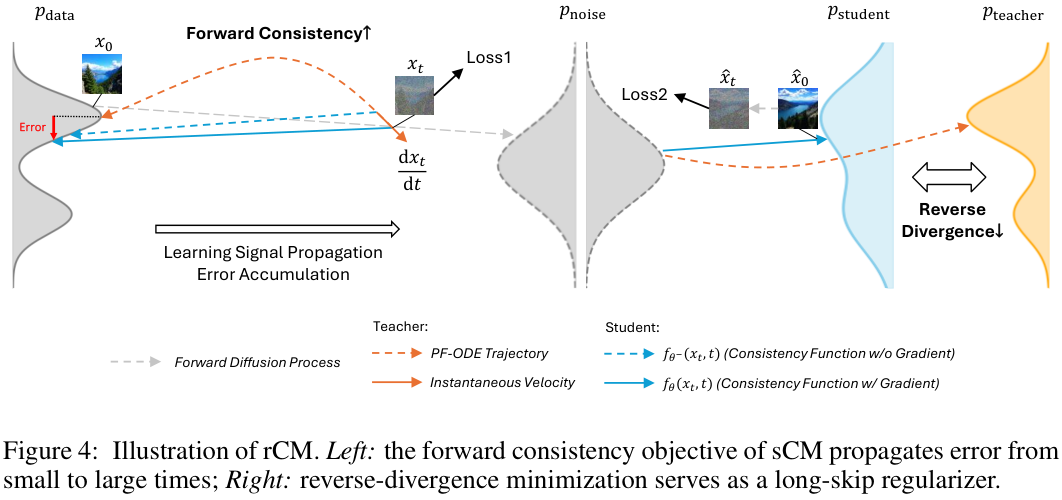
这些失真的背后,是误差累积的恶果。
一致性模型的目标,是学习一步到位直接求解教师模型的常微分方程(Ordinary Differential Equation, ODE),本质上是学习一个积分过程。在这个学习过程中,误差会随着积分时间t的增加而不断累积。
为了解决sCM的质量短板,研究人员提出用一种名为分数蒸馏(Score Distillation)的方法对其进行正则化约束。分数蒸馏旨在让学生模型生成的样本分布与教师模型的分布相匹配,它通过最小化两者之间的某种反向散度来实现。
在多种分数蒸馏方法中,团队最终选择了内存效率更高的分布匹配蒸馏(Distribution Matching Distillation, DMD),其损失函数如下:
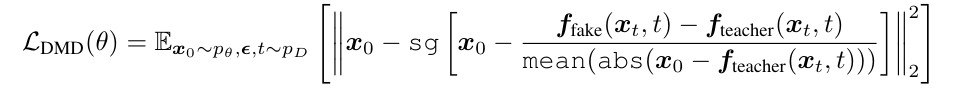
新的模型,即分数正则化连续时间一致性模型rCM,其总目标函数由两部分构成:原始的sCM损失和新增的DMD损失。
![]()
λ是一个平衡权重。实验发现,当λ取值为0.01时,在所有模型和任务上都能取得很好的泛化效果。
这个新框架巧妙地结合了两种不同的散度优化。sCM本质上是一种前向散度(forward divergence)最小化,这种方法擅长覆盖数据的全部模式,保证生成结果的多样性,但容易在模式之间产生低密度区域,导致质量下降。而DMD是一种反向散度(reverse divergence)最小化,它倾向于聚焦在数据的高密度区域,保证生成结果的质量和保真度,但有模式崩溃、损失多样性的风险。
sCM、DMD2、rCM三者比较:

rCM将两者结合,形成了一个前向-反向散度的联合优化框架。sCM保证了生成的多样性,而DMD作为正则项,有效修复了sCM的质量缺陷,防止模型在细节上漂移,从而在保持高多样性的同时,实现了高质量的生成。
质量、多样性与速度的全面胜利
研究团队在多个大规模模型上验证了rCM的性能,包括Cosmos-Predict2 T2I模型(6亿、20亿、140亿参数)和Wan2.1 T2V模型(13亿、140亿参数)。
在文生图(T2I)任务中,他们使用GenEval基准进行评估,该基准专门测试模型在复杂组合提示下的表现,如物体计数、空间关系和属性绑定。
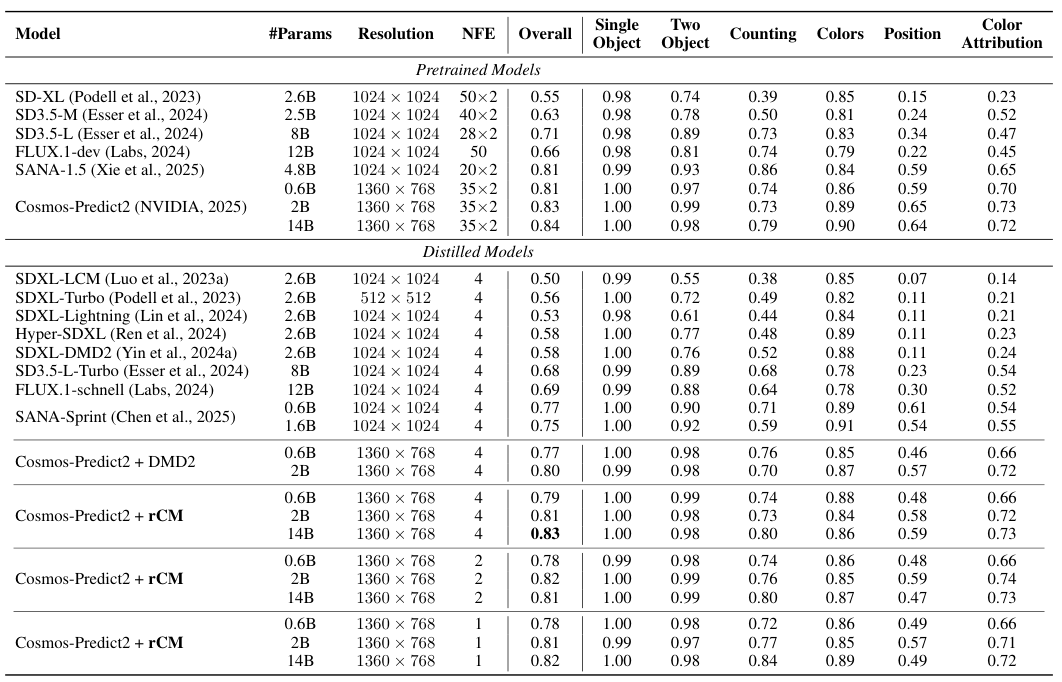
结果显示,rCM蒸馏后的Cosmos-Predict2模型,性能非常接近教师模型,并且展现出良好的扩展性。
其中,140亿参数的rCM模型仅用4步采样,就在GenEval上取得了0.83的总体得分,达到了业界领先水平。在处理带有细小文字渲染等高难度提示时,rCM的视觉质量也与顶尖的少步模型FLUX.1-schnell相当。
在文生视频(T2V)任务中,rCM的表现甚至更加亮眼。在VBench基准测试上,经过rCM蒸馏的Wan2.1 140亿参数模型,总分达到了85,甚至超过了需要更多步数生成的教师模型。
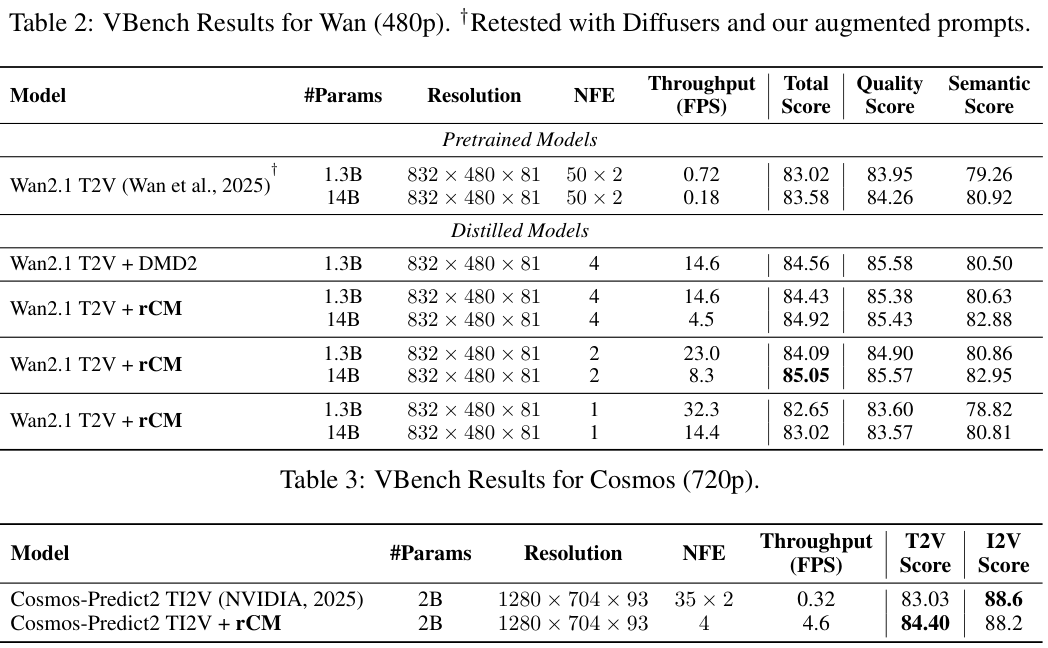
这种青出于蓝的现象也出现在更高分辨率(720p)的Cosmos-Predict2视频模型上。这并非说明蒸馏模型在所有方面都超越了教师模型(比如在物理一致性上可能还有差距),但它有力地证明了rCM在极少步数下维持高质量生成的能力。
研究人员还将rCM与另一种先进的蒸馏方法DMD2进行了比较。结果显示,无论是在GenEval还是VBench上,rCM在生成质量上都能达到甚至超过DMD2。
rCM的强大之处还在于其在极限压缩步数下的鲁棒性。
对于T2I任务,即便是1步或2步生成,rCM也能产出合理的样本,GenEval分数仅有轻微下降。对于简单提示词,1步生成的结果与4步几乎没有区别。对于T2V这样要求更高的任务,2步生成就已经能达到接近教师模型的分数,4步生成则能进一步完善细节,甚至在复杂背景下渲染出清晰的文字。
这意味着,rCM让高质量的T2I生成进入1步时代,T2V生成进入2步时代成为可能。
看看下面Wan2.1 T2V 1.3B(1-4步)生成的表现:
1步

2步

4步

rCM范式成功将连续时间一致性蒸馏从理论推广到百亿参数级别的真实应用,其核心在于开创性地将保证多样性的前向散度(sCM)与保证质量的反向散度(DMD)相结合,并通过强大的工程实现能力,解决了大规模训练中的一系列难题。
它提供了一个高效、稳定且无需复杂调参的蒸馏方案,也揭示了结合不同散度是提升生成模型性能的统一范式。
看来,AI作画和视频生成,正在加速进入秒出时代。
参考资料:
https://github.com/NVlabs/rcm
https://research.nvidia.com/labs/dir/rcm/
https://arxiv.org/abs/2510.08431
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)