Camouflage Anything Learning to Hide using Controlled Out-painting and Representation论文笔记
本文提出了一种创新的伪装图像生成框架Camouflage Anything,通过控制外绘和表示增强技术实现了高质量的伪装图像生成。研究贡献包括:1)开发了集成ControlNet和CLIP表示增强的生成框架;2)设计了基于最优传输的CamOT评估指标,专门量化伪装效果;3)提出BiRefNet+LoRA微调策略,提升了检测模型在未知场景的泛化能力。实验表明,该方法在生成质量和伪装效果上优于现有技术
Camouflage Anything: Learning to Hide using Controlled Out-painting and Representation论文笔记
1. 研究背景
1.1 伪装视觉理解的挑战
伪装视觉理解是计算机视觉中一个具有挑战性的研究方向,旨在理解和检测那些与背景高度融合的物体。传统的视觉任务如目标检测和分割在伪装场景下表现不佳,因为:
- 前景物体与背景在颜色、纹理、亮度等方面高度相似
- 边界模糊,缺乏明显的轮廓特征
- 语义信息不明确
1.2 现有任务分类
根据Fan等人的分类,伪装视觉理解主要包括:
- 伪装目标分割(COS):像素级的伪装物体分割
- 伪装目标定位(COL):定位伪装物体的位置
- 伪装实例分割(CIS):实例级别的伪装物体分割
1.3 现有方法的局限性
现有伪装图像生成方法如LAKE-RED存在以下问题:
- 生成的伪装图像质量不高
- 缺乏专门评估伪装效果的指标
- 传统指标(FID/KID)无法准确衡量伪装程度

2. 主要贡献
本文做出了以下重要贡献:
2.1 方法论贡献
- 提出了Camouflage Anything框架,集成了控制外绘和表示增强
- 设计了CamOT评估指标,专门用于量化伪装效果
- 开发了BiRefNet+LoRA微调策略,提升检测模型泛化能力
2.2 技术贡献
- 改进了ControlNet在伪装生成中的应用
- 提出了表示增强模块,提升文本引导的生成质量
- 建立了完整的伪装图像生成和评估pipeline
3. 解决的问题
3.1 核心问题
- 生成质量问题:如何生成既真实又具有高度伪装效果的图像
- 评估标准问题:如何客观量化生成图像的伪装程度
- 模型泛化问题:如何提升伪装检测模型在未知场景下的性能
3.2 具体挑战
- 传统生成模型难以在保持真实性的同时实现高度伪装
- FID/KID等指标与人类对伪装效果的感知不一致
- 现有检测模型在非标准伪装场景下性能下降明显
4. 核心方法
4.1 整体框架
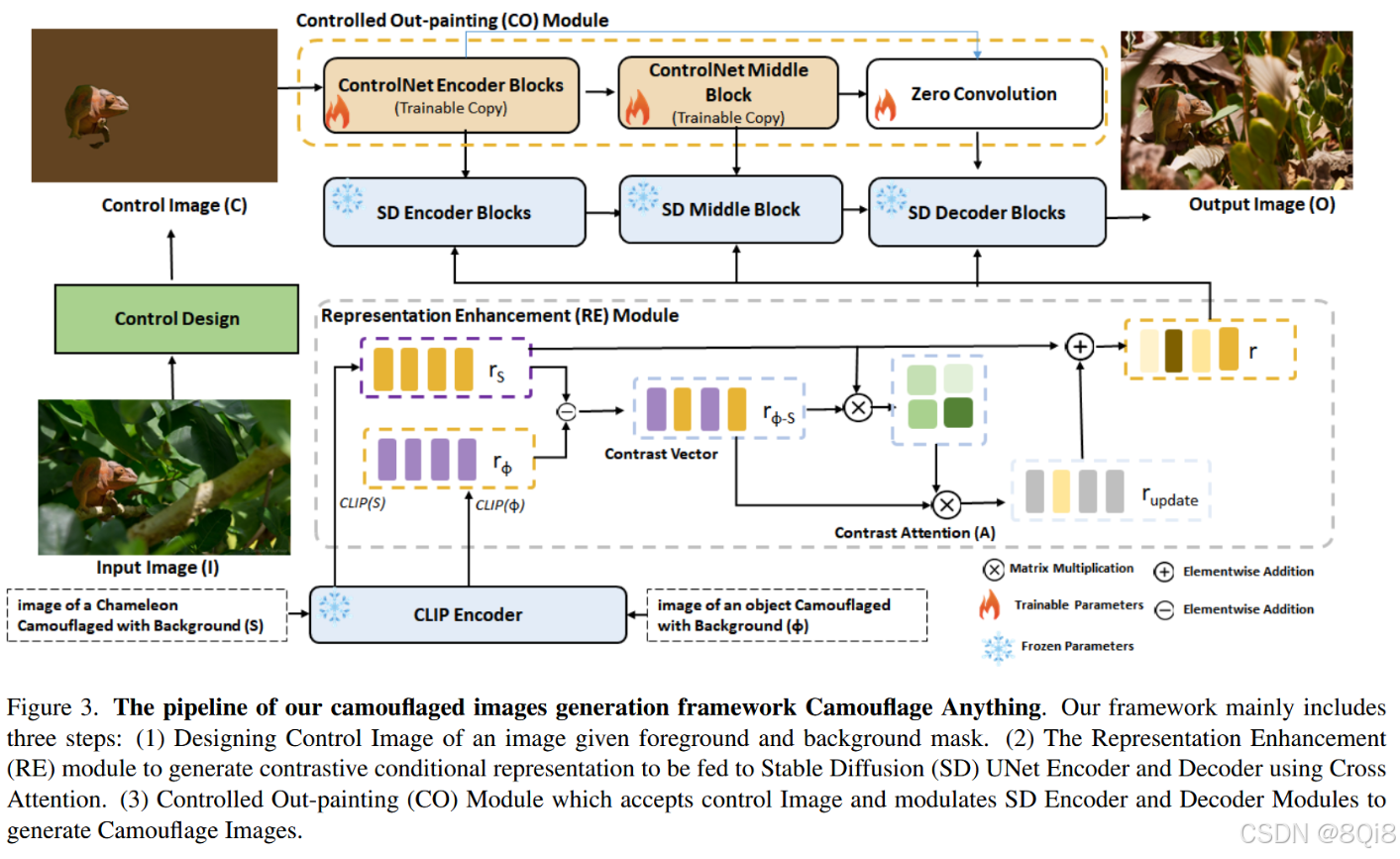
Camouflage Anything框架包含三个主要组件:
4.1.1 控制图像设计
基于ControlNet的架构:
yc=Ψ(x;Θ)+Z(Ψc(x+Z(ΓC;Θx1));Θc);Θx2) y_c = Ψ(x;Θ) + Z(Ψ_c(x + Z(Γ_C;Θ_x1));Θ_c);Θ_x2) yc=Ψ(x;Θ)+Z(Ψc(x+Z(ΓC;Θx1));Θc);Θx2)
4.1.2 表示增强模块(RE)
基于CLIP模型的表示优化:
- 源表示:r_S = R(S)
- 空表示:r_φ = R(φ)
- 对比向量:c = r_S - r_φ
- 注意力增强:A = softmax((r_S · c^T)/√d)
- 最终表示:r = r_S + α · (A · c)
4.1.3 控制外绘模块(CO)
训练阶段:Ci,j=Ii,j,ifMi,j=1elseμB推理阶段:背景颜色设置为前景平均颜色μF 训练阶段:C_{i,j} = I_{i,j} ,if M_{i,j}=1 \\else μ_B\\ 推理阶段:背景颜色设置为前景平均颜色μ_F 训练阶段:Ci,j=Ii,j,ifMi,j=1elseμB推理阶段:背景颜色设置为前景平均颜色μF
4.2 CamOT评估指标
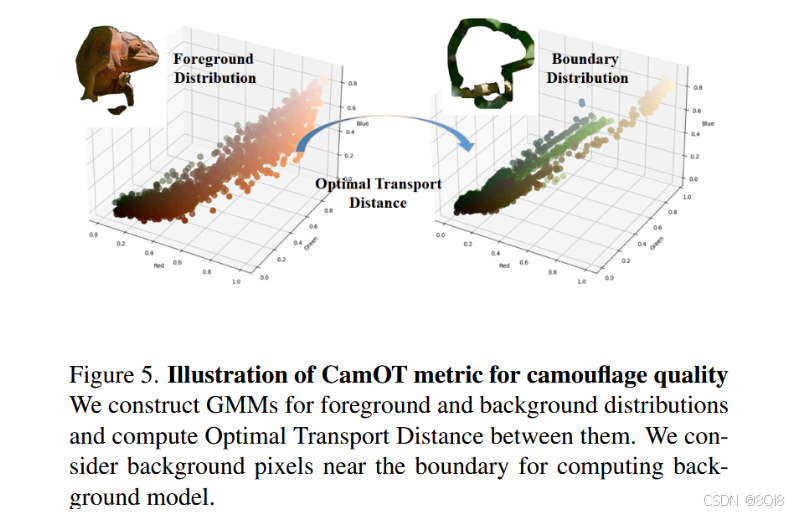
4.2.1 高斯混合模型建模
- 前景模型:(π_0, μ_0, Σ_0)
- 背景模型:(π_1, μ_1, Σ_1)
- 使用EM算法进行参数估计
4.2.2 最优传输距离计算
dW2=W2(π0,π1,μ0,μ1,Σ0,Σ1)d=1/(1+exp(−β⋅dW2))CamOT=2×(1−d) d_{W_2} = W_2(π_0, π_1, μ_0, μ_1, Σ_0, Σ_1)\\ d = 1/(1 + exp(-β·d_{W_2}))\\ CamOT = 2 × (1 - d) dW2=W2(π0,π1,μ0,μ1,Σ0,Σ1)d=1/(1+exp(−β⋅dW2))CamOT=2×(1−d)
4.3 BiRefNet + LoRA微调
- 在BiRefNet解码器中集成LoRA模块
- 使用生成的伪装图像进行微调
- 提升模型在通用场景下的分割性能
5. 实验设置
5.1 数据集
- 训练数据:COD10K数据集中的5,066张图像
- 测试数据:LAKE-RED数据集
- 伪装物体(COD):来自COD10K、CAMO、NCAK
- 显著物体(SOD):从相关数据集中采样
- 通用分割物体(SEG):来自COCO数据集
- 总计:6,473个图像-掩码对
5.2 实验配置
- 基础模型:Stable Diffusion v1-5
- 训练设置:
- Batch size: 4
- 迭代次数: 600,000
- GPU: A6000 48GB
- 对比配置:
- CO + RE + BG(使用背景颜色)
- CO + RE - BG(背景设置为白色)
6. 实验结果与分析
6.1 生成质量评估
6.1.1 定量结果
在LAKE-RED测试集上的表现:
- 整体FID:40.53 (CO+RE-BG),优于LAKE-RED的64.27
- 整体KID:0.0155,显著优于基线方法
- 在所有三个子集(COD/SOD/SEG)上均取得最佳性能
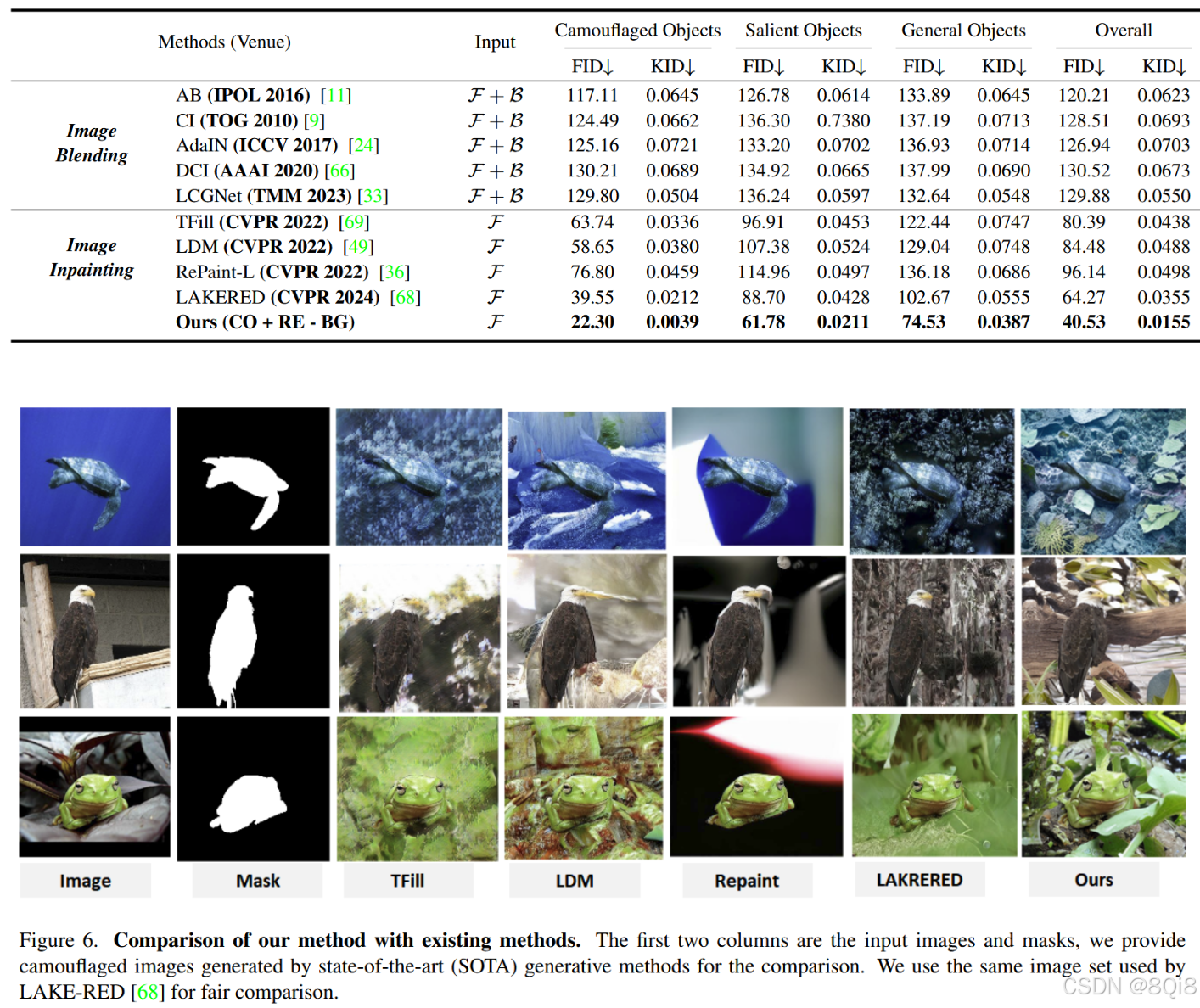
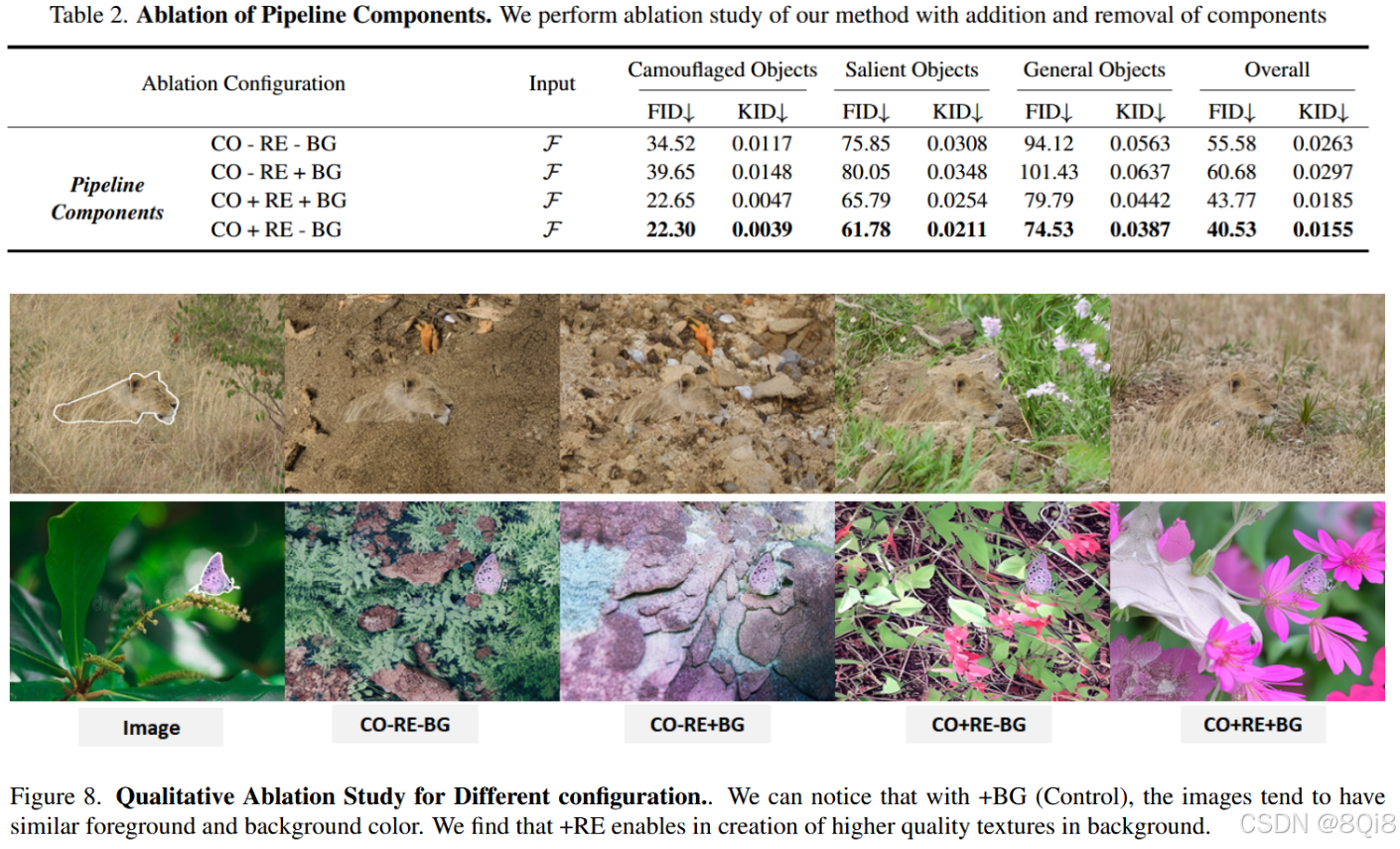
6.1.2 定性分析
- 纹理质量:+RE配置显著改善背景纹理真实性
- 颜色一致性:+BG配置促进前景背景颜色融合
- 伪装效果:CO+RE+BG在视觉伪装效果上最佳
6.2 CamOT指标验证
6.2.1 不同配置的CamOT得分
- CO-RE+BG:0.8621 (SOD), 0.8431 (SEG), 0.9244 (COD)
- CO+RE+BG:0.8403 (SOD), 0.8300 (SEG), 0.8975 (COD)
- LAKE-RED:0.7154 (SOD), 0.6772 (SEG), 0.7922 (COD)

6.2.2 指标相关性分析
- CamOT与人类对伪装效果的感知高度一致
- 与传统指标(FID/KID)形成互补评估维度
6.3 检测模型性能提升
6.3.1 BiRefNet微调结果
在生成数据集上的性能提升:
- SOD分割:Smeasure从0.722提升至0.916
- SEG分割:Smeasure从0.646提升至0.885
- MAE误差:显著降低,表明分割精度提升
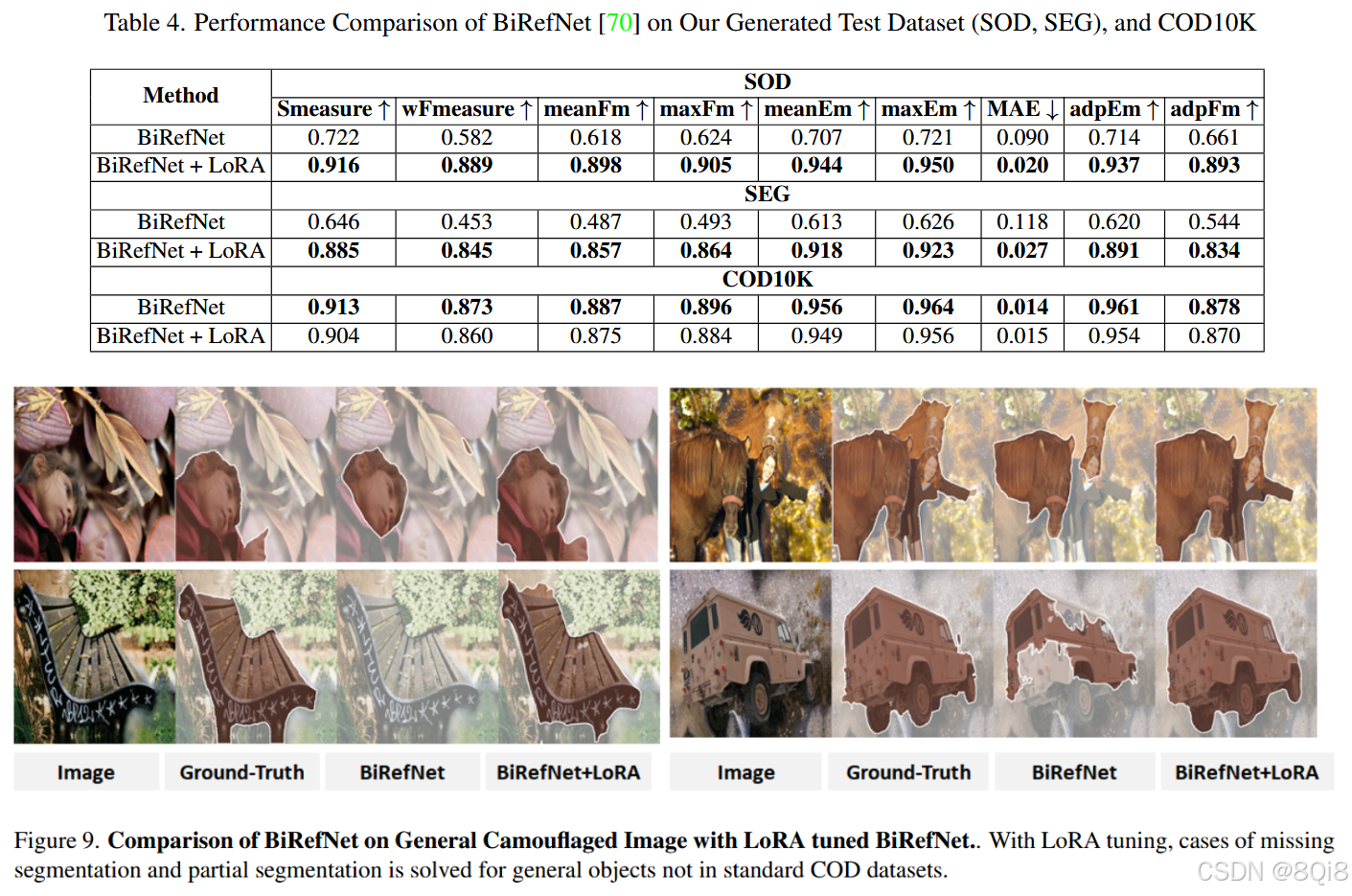
6.3.2 泛化能力验证
虽然在COD10K上性能略有下降,但在通用场景下的分割能力显著增强,证明模型泛化能力提升。
7. 创新点总结
7.1 方法创新
- 一体化生成框架:首次将控制外绘与表示增强结合用于伪装图像生成
- 条件控制策略:创新的控制图像设计,区分训练和推理阶段
- 表示优化机制:基于对比学习的文本表示增强方法
7.2 评估创新
- 专用评估指标:提出CamOT指标,专门量化伪装程度
- 多维度评估体系:结合传统图像质量指标与专用伪装指标
- 最优传输应用:将Wasserstein距离引入伪装评估
7.3 应用创新
- 检测模型增强:利用生成数据提升现有检测模型性能
- LoRA适配策略:高效微调方法,平衡性能与计算成本
- 开放领域适应:拓展伪装检测到通用物体场景
8. 总结
文章在伪装图像生成领域做出了重要贡献,主要体现在:
- 提出了一个完整的伪装图像生成框架,在生成质量和伪装效果方面均优于现有方法
- 设计了专门的伪装评估指标CamOT,解决了传统指标在伪装任务上的不适用性问题
- 证明了生成数据对提升检测模型泛化能力的有效性,为数据增强提供了新思路
该研究为伪装视觉理解领域提供了新的方法论和评估标准,具有重要的理论价值和实际应用意义。未来的工作可以在基础模型优化、控制精度提升和应用场景拓展等方面继续深入探索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)