揭秘Linux进程分身术:fork函数的神奇机制
本文深入探讨了Linux进程管理的核心机制,重点解析了fork()系统调用的原理与实现。通过代码示例详细说明fork()创建子进程的过程:内核复制父进程PCB和虚拟地址空间,采用写时复制技术优化内存使用,通过修改各自栈空间实现单次调用、双重返回的效果。文章对比了exit()与_exit()的区别,分析了进程等待机制(wait/waitpid)及状态获取方法,并阐述了进程虚拟地址空间与物理内存的映射
一、深入理解进程管理:
1、进程控制:
提到进程控制,那么就不得不提到linux操作系统中一个重要的函数,fork()函数,前面的代码已经出现过了,但是没有做详细的解析与系统性的介绍。
fork()函数:
使用man命令可以查看fork函数的使用方法。

fork()函数的返回值:
pid_t fork(),失败则返回-1,成功返回下面的内容。
父进程返回子进程的id,而子进程返回0。
pid_t类型表示进程id。
注意这里,fork函数是有两个返回值吗?fork函数怎么能有两个返回值呢?我们在写c/c++代码的时候,都是return一个值啊,这看似有点不符合常理啊。
fork函数执行之前,是父进程独立执行,fork之后,父子两个执行流分别执行,就变成了如下图所示的情景,需要注意的是fork之后,谁先执行或者说执行顺序由调度器决定,如果还觉得抽象的话不妨这么理解,fork函数之前就像是一个本体在进行战斗,而fork就相当于一个分身技能,开启分身技能后(也就是执行fork函数之后)那么就变成两个了,一个是本体(父进程),一个是分身出来的影子(子进程)。这样的话就应该能理解了!
上面提到fork函数失败的话返回-1,那么fork为什么会调用失败呢?
原因有两个,一个是系统中有太多的进程,另一个是实际用户的进程数超过了限制。
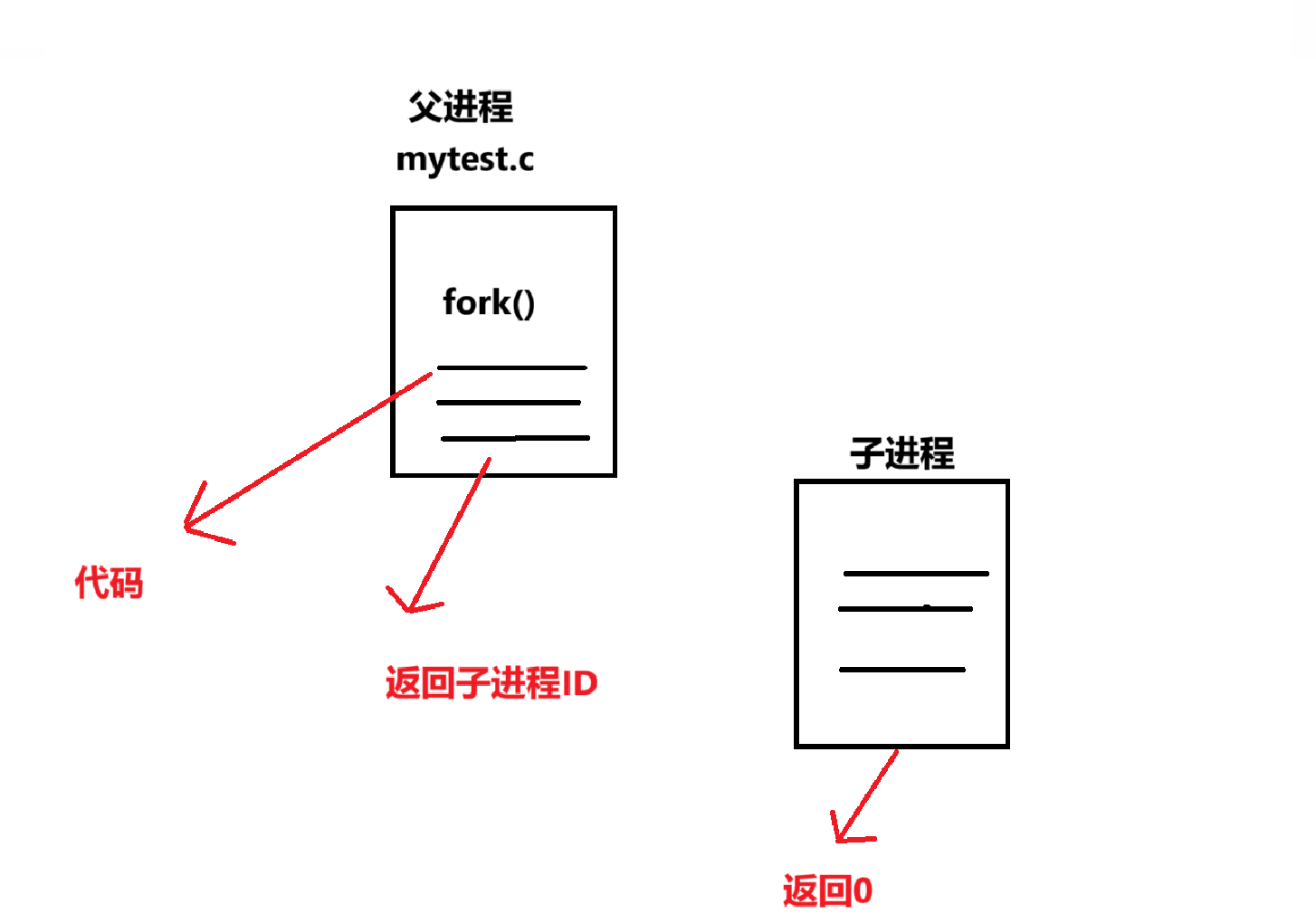
1、先创建子进程的PCB,同时复制父进程的执行状态(比如下一条要执行的指令位置、寄存器里的值),这样子进程才能知道从哪开始跑。
2、 给子进程搭一套虚拟地址空间,跟父进程的虚拟地址布局一模一样,但这时候还没真的复制物理内存。
3、创建并设置页表,让父子进程的页表一开始都指向同一块物理内存,不过会标成“只读”——这是为了后面的写时复制做准备。
4、写时复制这步是核心:只要父子进程都只读取内存,就一直共享同一块物理内存;但只要有一方想修改数据,CPU会立刻“报警”(触发页错误),这时候内核才会真的复制一块新的物理内存给修改的一方,让它的修改只影响自己,保证两边互不干扰。
5、 然后内核给返回值“填数”:父进程的返回值是子进程的PID,子进程的返回值是0——这俩值是内核直接写到各自栈里的,不是函数真的返回了两次。
6、最后执行流分叉:父进程看返回值大于0,就走自己的逻辑;子进程看返回值是0,就走自己的逻辑,从此各跑各的,由系统调度决定谁先谁后。
fork 函数本身只被父进程主动调用了一次。但内核在创建子进程时,会复制父进程的执行上下文(比如程序计数器、栈、寄存器),让子进程‘继承’父进程的执行流。
子进程的程序计数器会指向 fork 返回后的代码,所以看起来像子进程也调用了一次 fork。但本质是,内核为了区分父子身份,直接修改了父子进程的栈内存:给父进程的栈写子进程 PID,给子进程的栈写 0。
所以并不是 fork 函数真的返回了两次,而是 两个独立进程从同一段代码继续执行,且内核通过内存赋值给了它们不同的返回值,让我们感觉返回了两次。这是 fork 最巧妙的设计——用进程继承 + 内存修改’实现了‘一次调用,两次逻辑分叉的效果。
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main()
{
printf("调用fork()前,当前进程ID:%d\n", getpid());
// 调用fork(),获取返回值
pid_t ret = fork();
if (ret == 0) {
printf("子进程中:fork()返回值 = %d(子进程ID:%d,父进程ID:%d)\n",
ret, getpid(), getppid());
} else {
printf("父进程中:fork()返回值 = %d(父进程ID:%d,子进程ID:%d)\n",
ret, getpid(), ret); // 父进程中ret就是子进程ID
wait(NULL);
}
return 0;
}

下面将再举一个例子来解释这个fork函数:
1: myfork.c
1 #include<stdio.h>
2 #include<sys/types.h>
3 #include<unistd.h>
4 #include<stdlib.h>
5
6 int main()
7 {
8 pid_t pid;
9 int x=1;
10 pid=fork();
11 if(pid==0)//child
12 {
13 printf("child:x=%d",++x);
14 exit(0);
15 }
16 printf("parents:x=%d\n",--x);
17 exit(0);
18 }
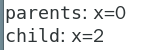
上面是代码及其输出结果,那么我将画图为此进行解释,为什么child的x是等于2的,parent的x是等于0的
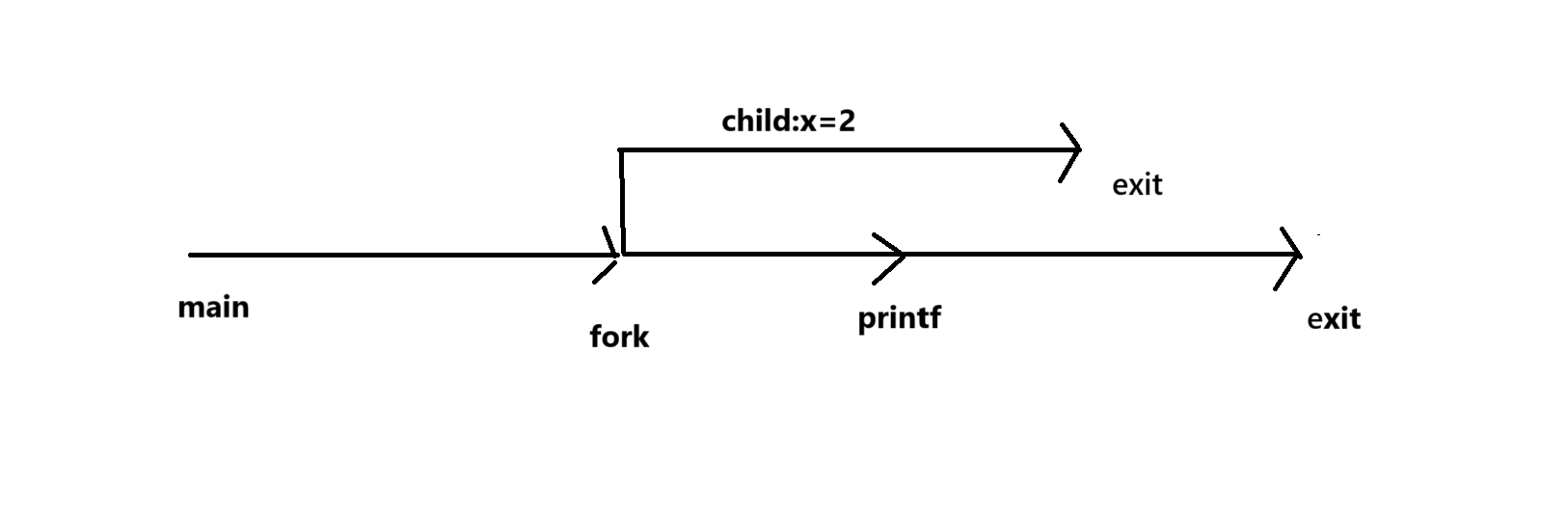
这个例子说明了:
1、调用一次但是返回两次,fork函数被父进程调用一次但是却返回两次,一次是返回到父进程,一次是返回到新创建的子进程。
2、并发执行,子进程与父进程是并发运行的两个独立的进程,内核能够以任意方式交替执行他们的逻辑控制流中的命令。
3、相同但是独立的地址空间:进程所看到的是虚拟地址,而非真正的物理内存(这里后续会详细讲解),当fork创建子进程时,系统不会立刻为子进程赋值完整物理内存,而是让父子进程的虚拟地址空间初始映射到相同的物理,总结就是一句话,虚拟地址相同,但是物理页暂时共享。
虚拟地址相同了,独立又从何而来呢?答案是虽然他们的虚拟地址相同但是父子进程尝试修改变量时,系统触发写时拷贝,为子进程分配新的物理页,这个时候父进程和子进程在物理内存上是不同的,所以修改child的x++就变成了1+1=2,而parnent的x从1变成了0,也就是变成了上面的输出结果。
对上述例子做个总结:
如何理解相同但独立,所谓的相同,是虚拟地址表面相同但实际上,一旦要修改变量值的时候,物理内存就会分离,虚拟内存通过页表映射到不同的物理内存,这样做就既利用共享节省内存,又通过写时拷贝保障进程间地址空间独立、互不干扰,是多进程高效运行的重要基础!
对fork函数做一个总结:
当一个进程发出fork请求的时候,操作系统会执行以下的功能:
1、在进程表中范围新进程分配一个空项。
2、为子进程分配一个唯一的进程标识符。
3、复制父进程的进程映像,但共享内存除外。这里:属性集合称之为进程控制块,程序、数据、栈和属性存的集合合称为进程映像。
4、增加父进程所拥有的文件计数器(文件后续的博客会详细介绍,这里就不做详细的叙述了),反映另一个进程现在也拥有这些文件的事实。
5、将子进程置为就绪态。
6、将子进程的ID号返回给父进程,将0值返回给子进程。
这里再补充一条命令:ps aud | grep 关键字 搜索系统中包含关键字的进程
getpid()函数:这个就不陌生了,就是获取当前进程的ID。
getppid()函数:获取当前进程父进程的ID。
区分一个函数是系统函数还是库函数的依据:
1、是否访问内核数据结构。
2、是否访问外部硬件资源。
如果说这两个条件有其中之一,那么它就是一个系统函数,如果这两个条件中一个都不满足,那么它就是一个库函数。
2、进程终止:
进程退出的常见方法:
正常终止
1、从main返回
2、_exit
3、调用exit
我们指定一个进程的退出状态可以在shell中用特殊的变量$查看,因为shell是它的父进程,当它终止时shel调用它的wait或者waitpid得到它的状态同时清楚掉这个进程。
进程终止的三种情景:
代码运行完,结果不正确,运行完,结果正确,以及根本没运行完,代码异常终止。
exit函数与_exit函数:
_exit函数:

函数参数status的定义了进程的终止状态,父进程通过wait来获取该值
其次需要注意的是这里的status虽然写的是int类型,但是只有低8位可以使用,也就是说这个status的范围就是到2的8次方也就是256。
exit函数:
void exit (int status)
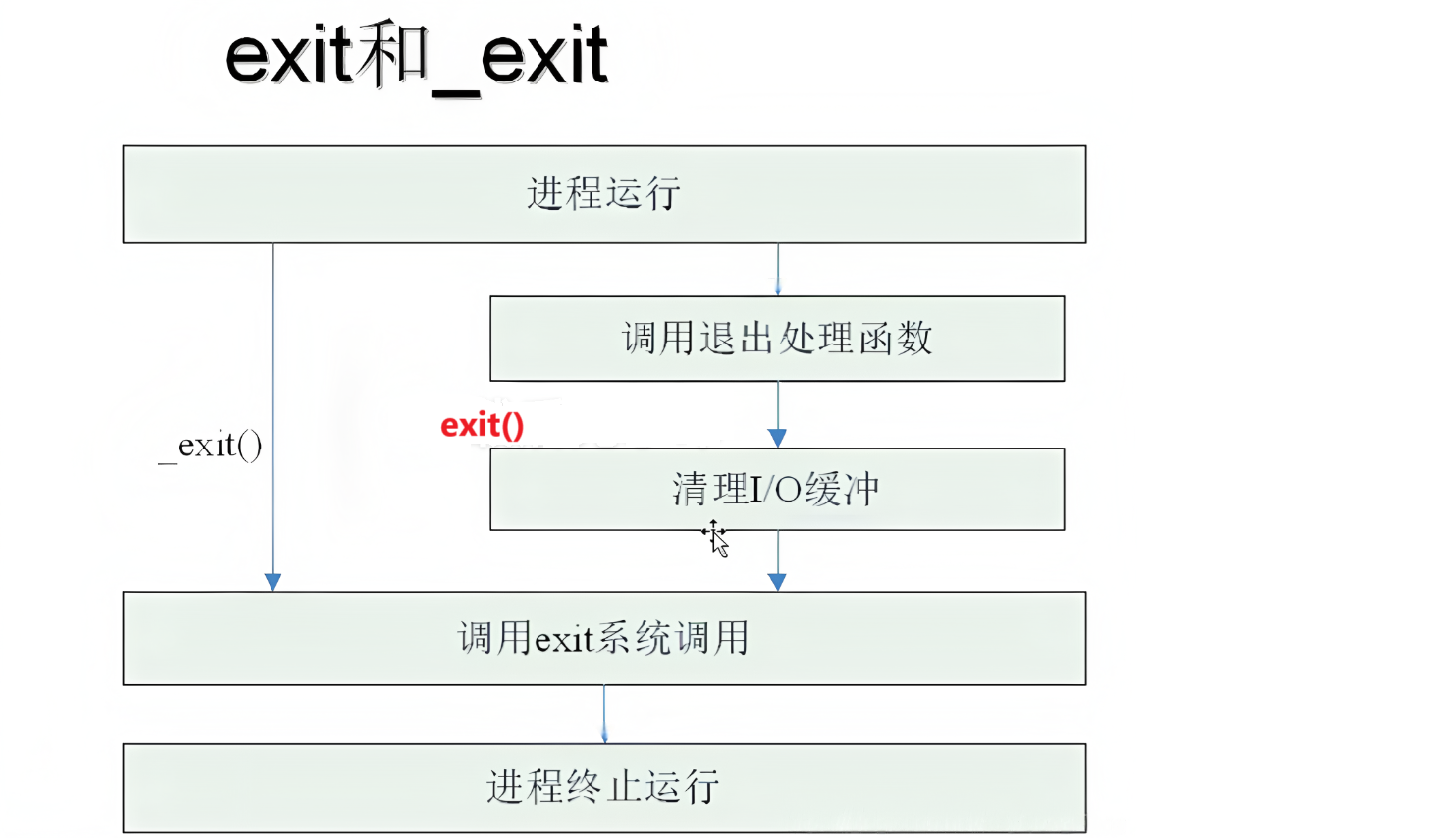
_exit与exit的区别:
1、头文件不同:
exit函数的头文件为<stdlib.h>而_exit函数的头文件为<unistd.h>
2、
_exit属于系统函数,而exit属于库函数。
3、使用场景:
exit函数不但会结束进程还会进行刷新缓冲区,而_exit函数只会终止进程,并不会进程缓冲区的刷新。
下面将使用一张图来感受一下他们的不同:
不仅如此,下面我将用代码来进行验证:
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("exit 函数测试:这句话在缓冲区中");
// 调用 exit,会刷新缓冲区并终止程序
exit(0);
}![]()
由上面的输出结果可知,exit函数会刷新缓冲区,打印出结果。而_exit只起到终止进程的作用,所以并不会打印出结果
#include <stdio.h>
#include <unistd.h>
int main() {
printf("_exit 函数测试:这句话在缓冲区中");
// 调用 _exit,直接终止程序,不刷新缓冲区
_exit(0);
}此代码不会打印出对应的结果,因为_exit函数不会刷新缓冲区。
3、进程等待:
wait函数:
#include<sys/wait.h>
pid_t wait(int *status)
返回值:
如果成功则返回回收进程的PID,失败返回-1.
函数的主要作用:
1、回收子进程残留在内核的PCB。
2、获取子进程的退出状态(传出参数wstatus)
3、阻塞等待子进程退出(终止)。
下面将通过下面的代码给大家来看一下wait函数的使用以及作用:
#include <stdio.h>
#include <sys/wait.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
pid_t pid = fork();
if (pid == -1) {
perror("fork error");
return 1;
} else if (pid == 0) {
// 子进程逻辑
printf("子进程 pid: %d 运行中...\n", getpid());
sleep(3); // 模拟子进程执行一些操作,延迟退出
printf("子进程 pid: %d 即将退出\n", getpid());
// 子进程正常退出,返回状态 10(自定义,用于演示)
exit(10);
} else {
// 父进程逻辑
int status;
printf("父进程等待子进程退出...\n");
// 父进程调用 wait 阻塞等待子进程退出,回收子进程
pid_t wait_pid = wait(&status);
if (wait_pid == -1) {
perror("wait error");
return 1;
}
printf("回收的子进程 pid: %d\n", wait_pid);
// 判断子进程退出状态
if (WIFEXITED(status)) {
printf("子进程正常退出,退出状态: %d\n", WEXITSTATUS(status));
} else {
printf("子进程异常退出\n");
}
}
return 0;
}
介绍完wait函数接下来看waitpid函数
waitpid:
在介绍waitpid函数之前先来介绍两个宏,提到宏我们并不陌生,因为在学习c语言的时候有过接触。
正常退出场景:
WIFEXITED:
可以理解为判断函数,返回非0则证明进程正常结束,返回0,说明子进程异常退出。
WEXITSTATUS:
如果上述宏为真,则使用此宏,并获取子进程的退出状态(exit函数的参数)。
异常终止情景:
WIFSIGNALED:
返回非0则说明--->子进程是被信号终止(比如被kill -9干掉),返回0则说明不是信号杀死的退出。
WTERMSIG(status):
如果上述宏为真,那么使用此宏来获取使进程终止那个信号的编号。
如果不存在子进程,则立即出错返回!
如果在任意时刻调用wait或者waitpid,子进程存在且正常运行,则进程可能阻塞。
在看下面的代码之前,我们需要了解status的结构。
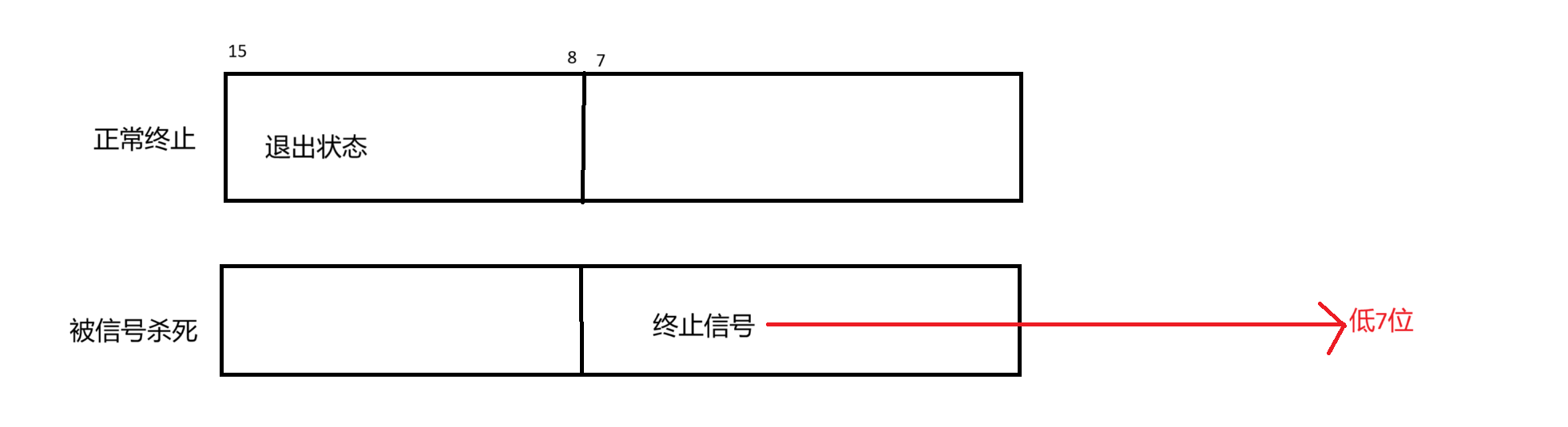
status的结构较为特殊:
进程的退出状态status是一个32为的整数,但是实际有效信息主要是在低16位,其中高8位,也就是低16位里面的高8位,储存的退出状态,低8位储存的是终止信号。
所以status>>8也就是移到了低8位,那么位与上0xFF,,0xFF的二进制是11111111(8个1),这样截断了高24位,只保留了低8位的退出状态值。
status&0x7F,直接保留了低7位,也就是终止信号,同时把高25位的清零,从而得到准确的终止信号编号。
下面将画图来展示一下status的结构:
这里的等待方式分为两种阻塞等待和非阻塞等待:
进程的阻塞等待方式:
代码如下:
非阻塞等待:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4 #include <sys/wait.h>
5
6 int main()
7 {
8 pid_t pid;
9
10 pid = fork();
11 if(pid < 0)
12 {
13 perror("false");
14 return 1;
15 }else if( pid == 0 ){ //child
16 printf("child is run, child pid is : %d\n",getpid());
17 sleep(3);
18 exit(14);
19 } else{
20 int status = 0;
21 pid_t ret = 0;
22 do
23 {
24 ret = waitpid(-1, &status, WNOHANG);//非阻塞式等待
25 if( ret == 0 ){
26 printf("child is running\n");
27 }
28 sleep(1);
29 }while(ret == 0);//说明此时子进程正在运行
30
31 if( WIFEXITED(status) && ret == pid ){ //如果正常退出,并且返回值等于子进程的pid。
32 printf("等待三秒钟成功, child return code is :%d.\n",(status>>8)&0xFF);
33 }else{
34 printf("等待子进程失败了!, return.\n");
35 return 1;
36 }
37 }
38 return 0;
39 }
waitpid函数总结:
pid_t waitpid(pid_t pid,int *status,int options)
功能/作用:等待子进程终止,如果子进程终止了,此函数回收子进程的资源
参数pid:
pid>0 等待进程ID等于pid的子进程
pid=0 等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid将不再等待它。
pid=-1 等待任何一个子进程,此时waipid的作用约等于这个wait的作用。
pid<-1 等待指定进程组中的任何子进程,这个进程组的ID等于pid的绝对值
status:进程退出时的状态信息,其结构我们在上面已经详细介绍了。
opinion:
0:同wait(),阻塞父进程,等待子进程退出
WNOHONG:没有任何意见结束的子进程,则立即返回,上面的非阻塞等待正是利用了这一点,也就是说,它不会在那里一直等着你,如果这个子进程正在运行,那么它会直接返回。
该函数的返回值:
如果正常返回,那么此函数返回已经回收的子进程的进程号。
如果设置了选项WNOHANG,waitpid()发现没有已退出的子进程可等待,则返回0,因为此时子进程正在运行,而它不会去等待子进程运行完,会直接返回!这一点需要注意一下!
如果出错了,返回-1。
以上就是进程等待的全部内容。
4、进程虚拟地址空间(重中之重):
对于5环境变量中的问题,我在这里进行详细地解析。
对于上面这个问题,就不得不提到内存管理了,那么内存是如何进行管理的?为什么同样的地址会打印出不同的值呢?
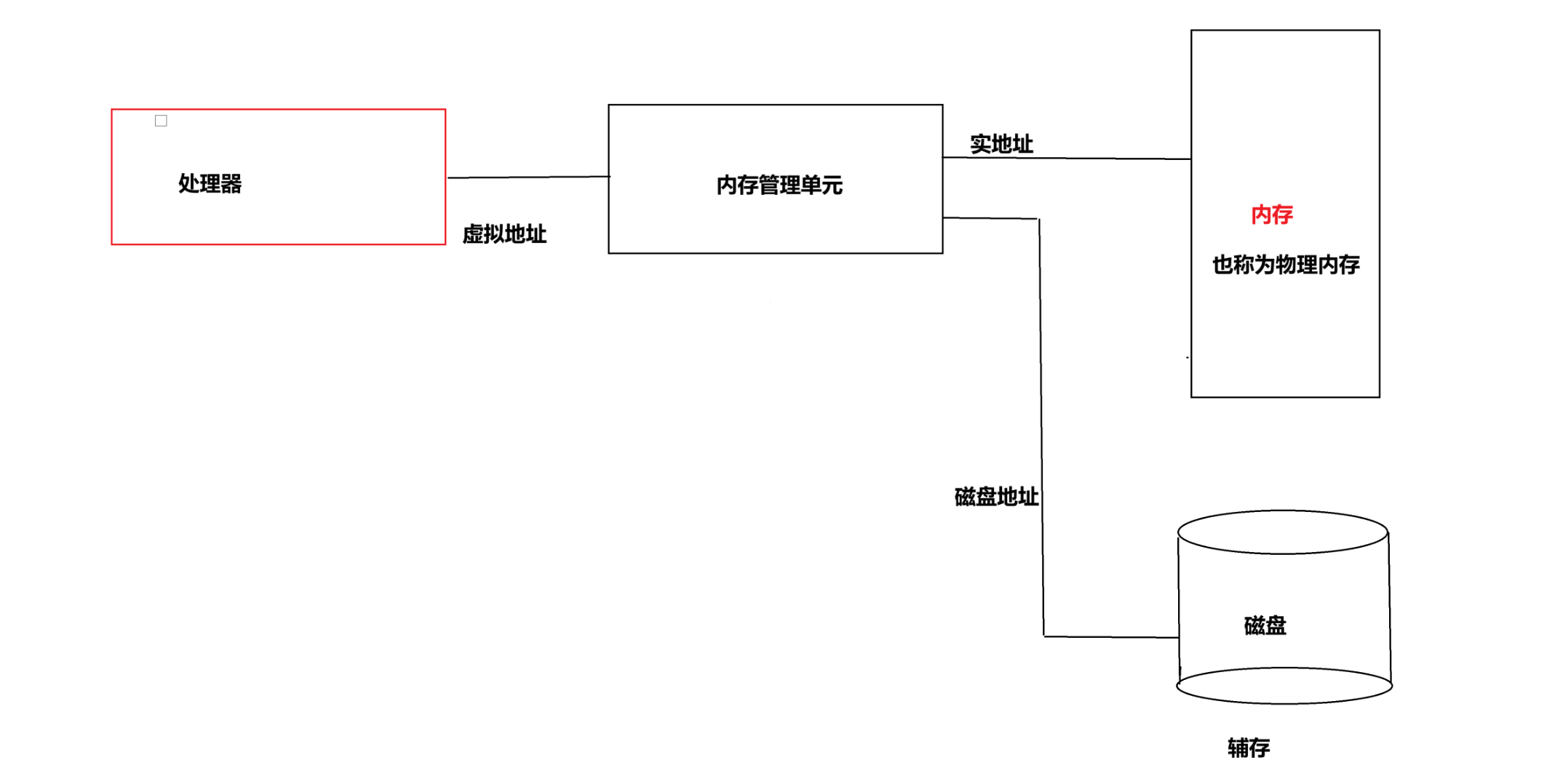
首先存储器由内存和辅存组成,内存可以直接访问,辅存要间接访问。
Linux虚拟内存系统:
linux为每个进程维护了一个单独的虚拟地址空间,一个虚拟地址空间的大小通常是2的32次方或者2的64次方。
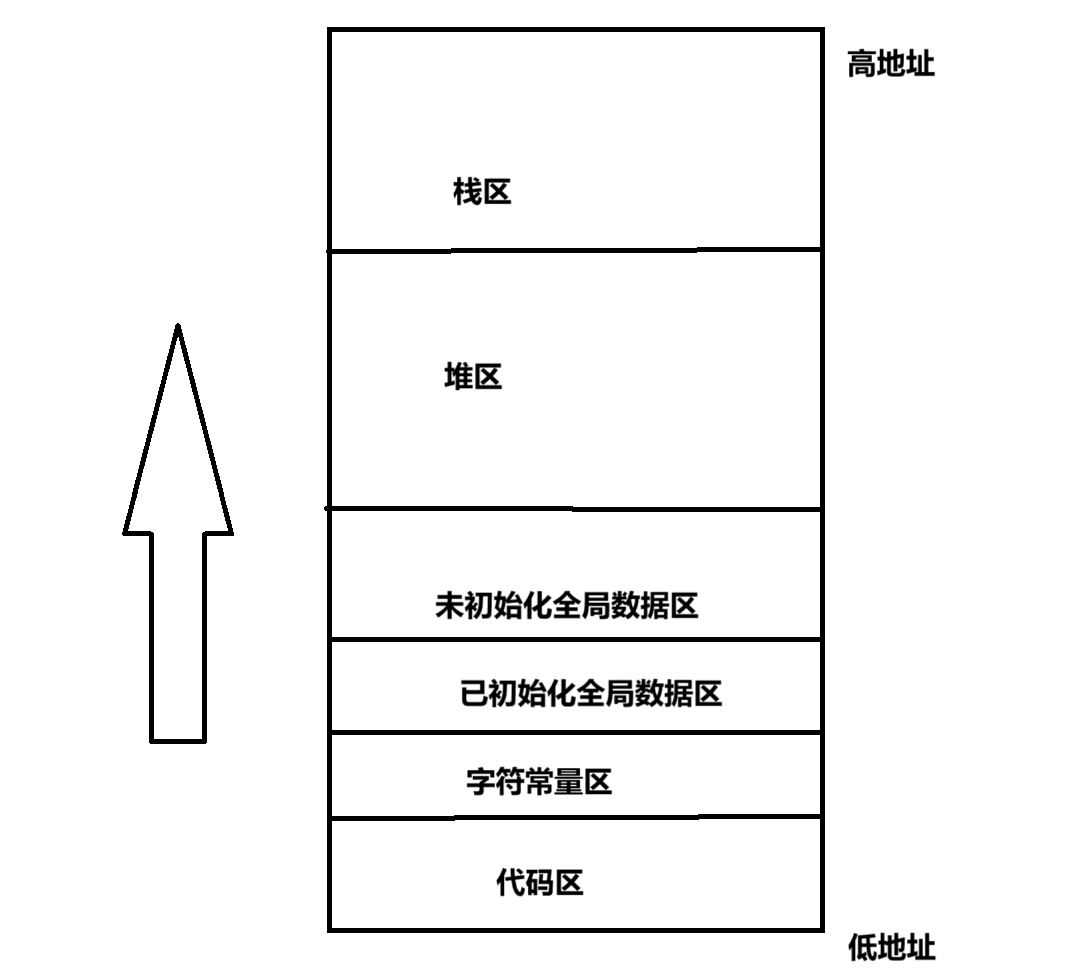
在上面的图,在c/c++地址空间中,我们所说的地址是内存吗?答案不是,例如我们用的取地址符号得到的地址并不是真正意义上的内存,只是虚拟地址。
接着往下看,那么这个虚拟地址和物理内存之间有什么关系呢?
CPU上的管理单元MMU可以将这个虚拟地址转换为物理内存,为什么相同的地址即虚拟地址相同而值却不同?因为在进行转换的过程中,它们被映射到不同的物理内存,即虚拟地址是系统的但是物理内存是不同的,所以对应的值也是不同的,这就是为什么虚拟地址相同但是值不同的原因。
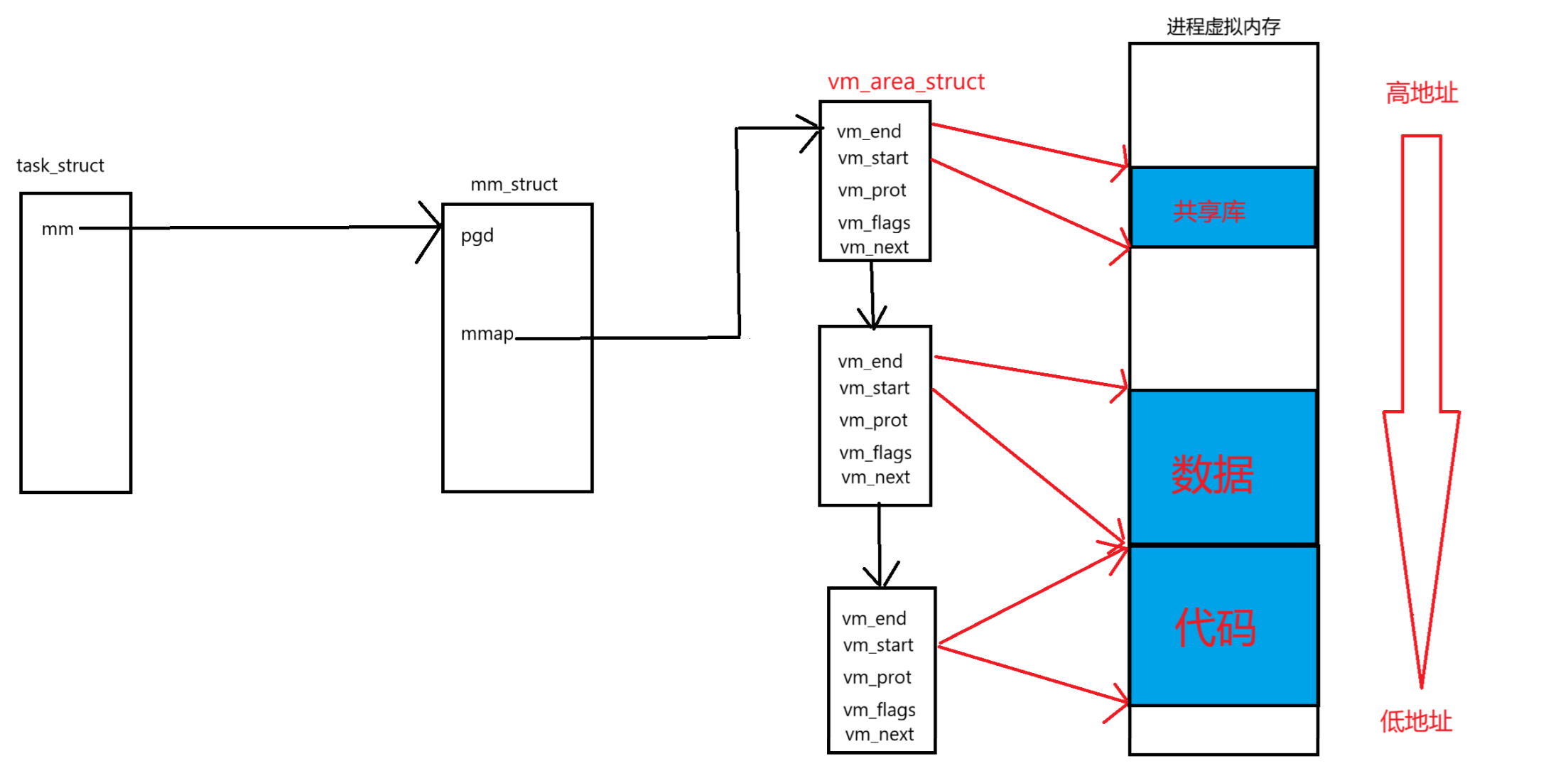
请看下面这张图你或许就懂了。
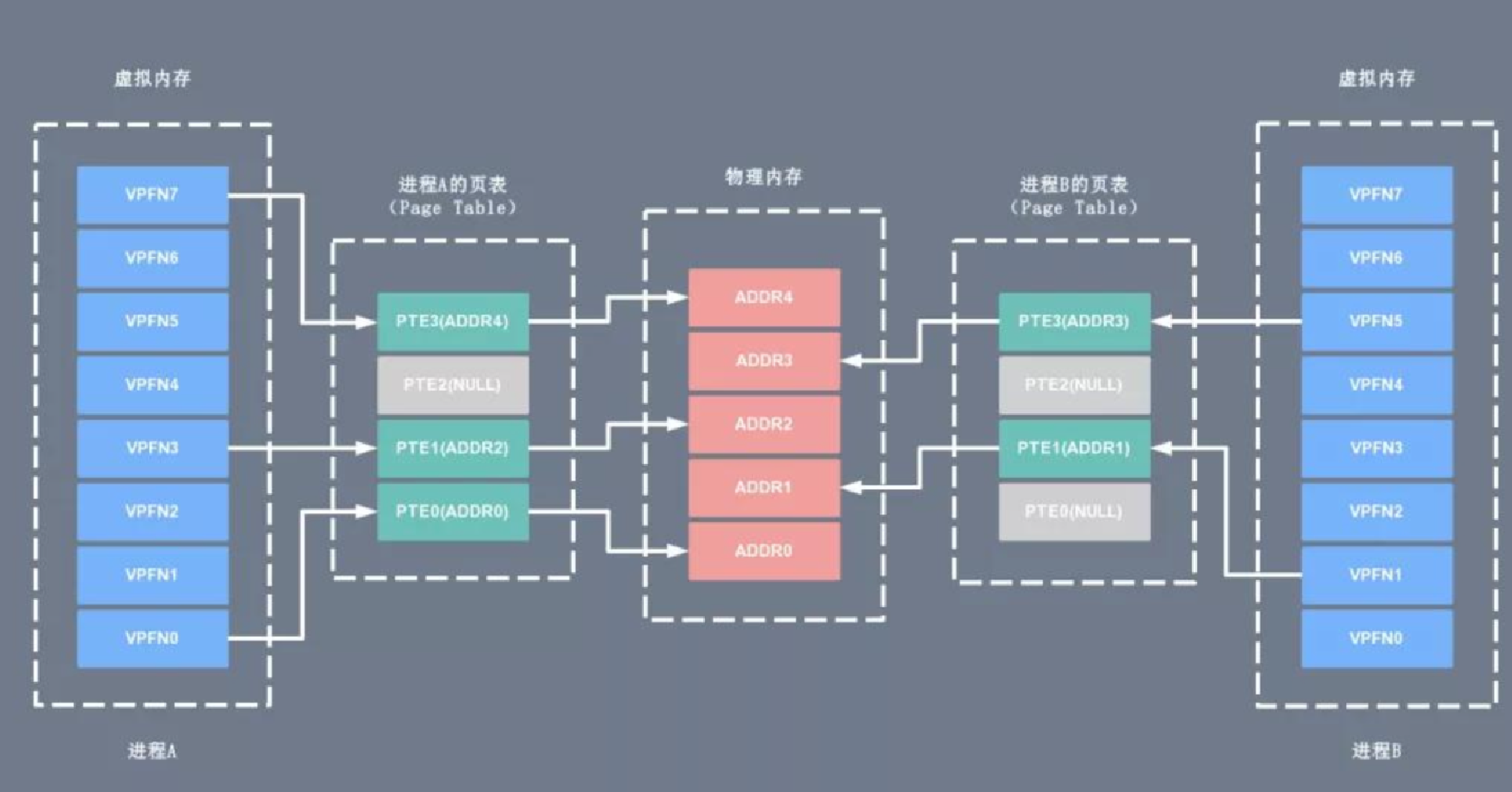
这里的虚拟内存并不是真正的物理内存,它只是一个传话员,而你去修改变量的值,也是去物理内存中修改,但是并不能直接访问物理内存,而是通过一个虚拟地址去映射它的物理内存,那为什么这么做呢,后续会给出答案。
二、冯诺依曼体系结构:
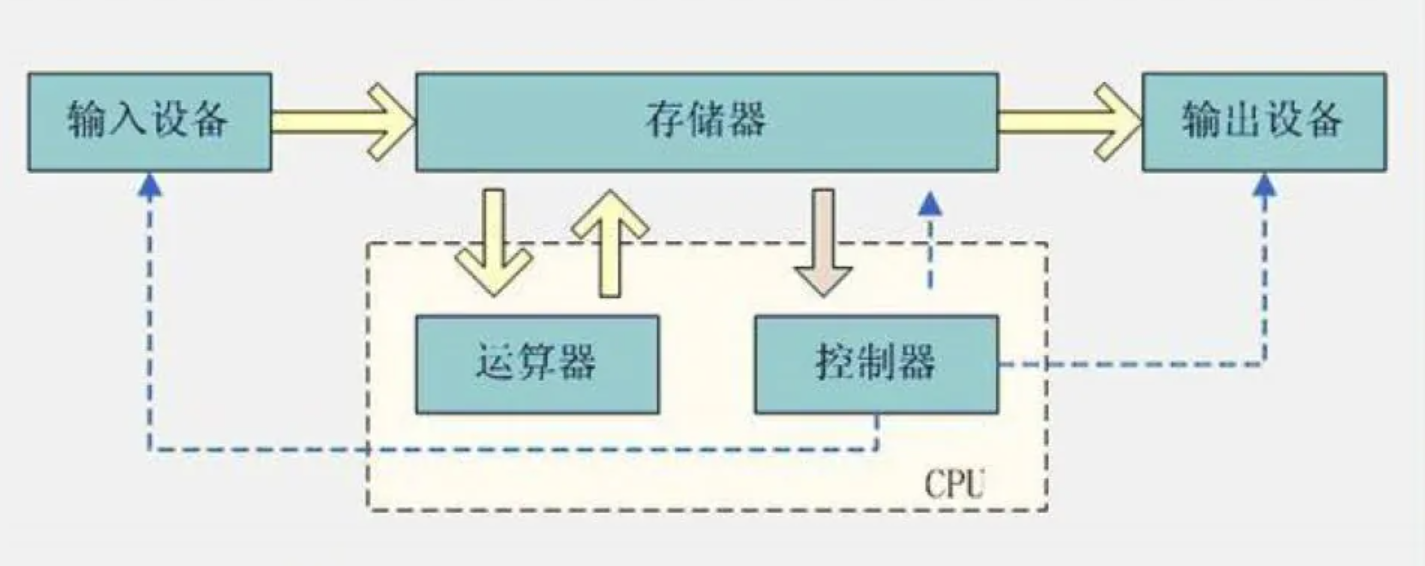
如今,我们常见的电脑,如笔记本,都遵循冯诺依曼体系。
输入单元:像我们的键盘,鼠标,扫描仪等。
输出单元:显示器,打印机等。
中央处理器:我们常谈的CPU:包括运算器和控制器两大部分。
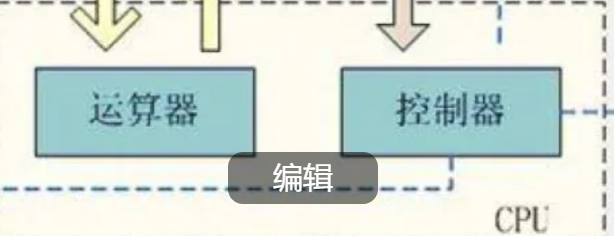
需要注意的是:
这里的存储器指的是内存!
外设要输入或输出数据只能写入内存或从内存上读取。
所有设备都只能直接和内存打交道。
三、操作系统:
操作系统是管理计算机硬件与软件资源的系统软件,是计算机系统的核心,能为用户和应用程序提供交互接口以及运行环境。
主要功能如下:
1、进程管理:负责进程的创建,调度,终止等,合理分配cpu资源,让多个程序高效运行起来。
2、内存管理:对内存进行分配、回收以及保护,确保各程序都能安全使用内存空间。
3、文件管理:包括文件创建、删除、读写等一些列操作。
4、设备管理:协调计算机与外部设备的通信。
5、用户接口:提供用户与计算机交互的方式,分为命令行接口和图形用户接口。
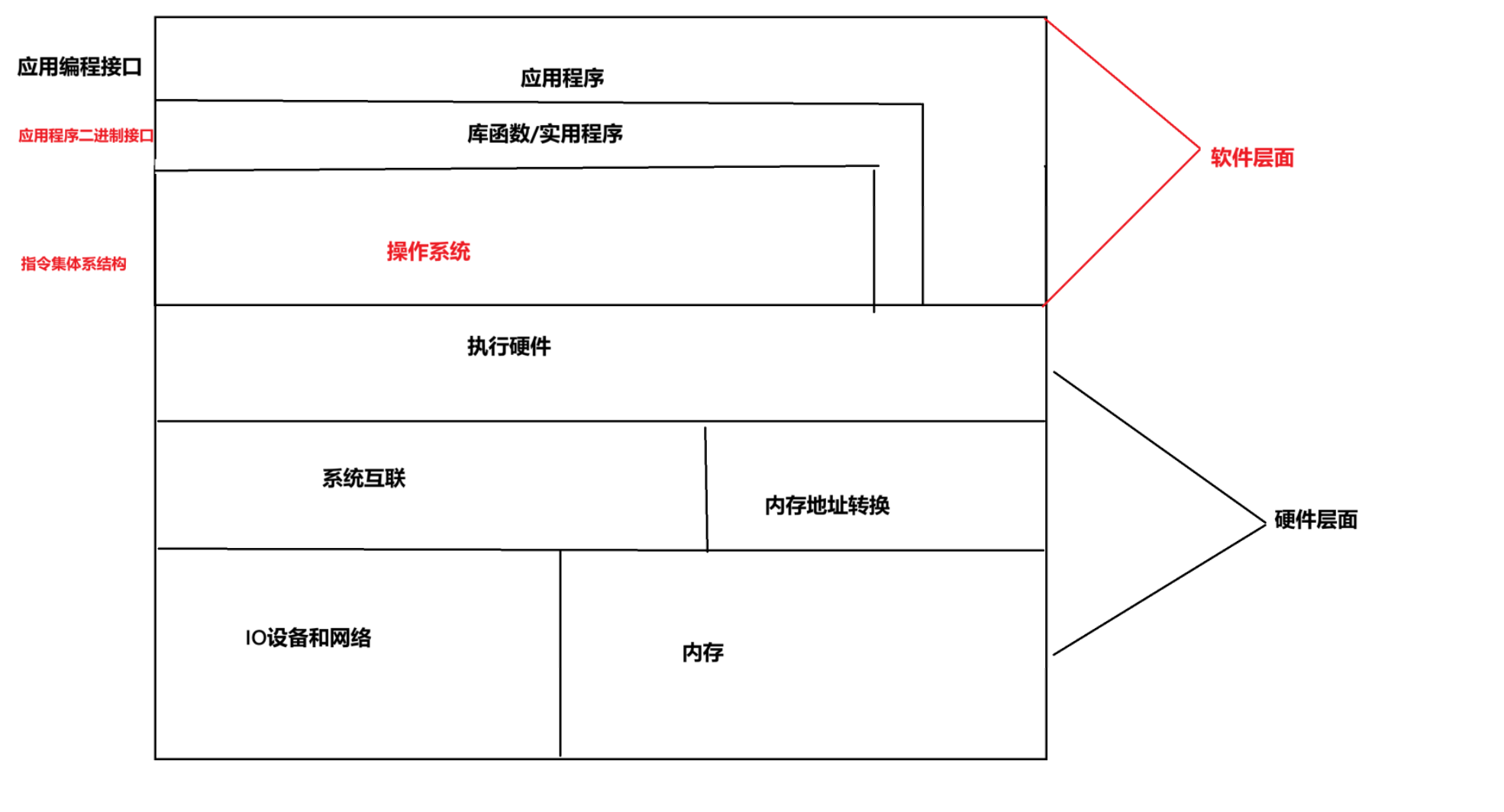
我们可以把操作系统看成是应用程序和硬件之间插入的一层软件,所有应用程序对硬件的操作都必须依靠操作系统来完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)