强化学习-ppo简单自学
针对于这两点,可以修改公式,首先对reward求和,不是对整个tragectory进行求和,而是从当前到结束的reward的求和,第二点是引入衰减因子,距离当前t越远,当前动作对reward的影响越小,呈指数衰减。那么一个策略的概率,就是在这个策略中的所有的state和这个state下给出的action的概率的连乘。优势函数,做出某一个具体动作得到的回报,比这个状态的期望回报的差值,表示这个动作相
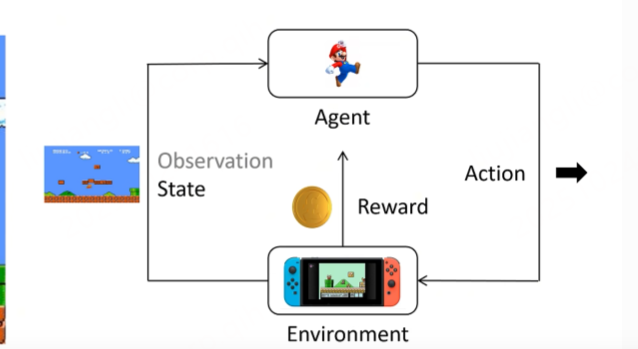
环境,负责产生游戏画面,生成敌人,奖励、决定游戏何时结束
agent,智能体,观察环境,根据自己的策略做出动作,争取获得更多的得分,强化学习就是让程序学习策略,去获得奖励
state,是当前的状态,agent根据状态做出决定。
action就是agent做出的动作,根据当前的state和策略做出动作,前上跳之类的
reward是奖励,吃蘑菇给分,被敌人打倒扣一百分
agent会尽可能让得到的reward尽可能的大
action space:可选择的动作
policy:策略函数,输入是state,输出action的概率分布,一般使用Π表示
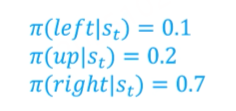
trajectory:轨迹,用 表示,一连串的状态和动作的序列,episode(回合),rollout(展开、推演、采样轨迹){s0,a0,s1,a1..}
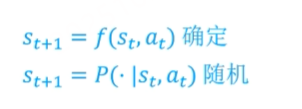
这里指的是状态转移是确定的还是不确定的
reward:回报
再看一下期望的定义,就是概率乘以对应数值之和

强化学习的目的就是:训练一个policy神经网络Π,在所有状态s下,给出相应的action,得到的return的期望最大
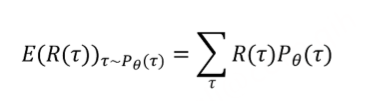
如何让期望尽可能的大?一个是奖励 一个是概率
τ:表示从某个初始状态开始,按照策略 π 执行的一系列状态、动作、奖励的序列
我们计算的是回报 R(τ) 的期望值,而 τ 是从策略 π_θ 所决定的概率分布 P_θ(τ) 中采样得到的
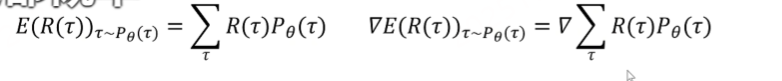
我们只能改变神经网络的参数,而不能对环境的reward进行改变,对θ求梯度
策略Π_θ决定了智能体在每个状态选择动作的概率。由于环境可能产生随机行,即使策略固定,每次运行也可能得到不同的轨迹t.所以t是一个随机变量,它的取值是由策略Π_θ和环境共同决定,即概率分布P_θ(τ) (在策略参数为 θ 的条件下,产生轨迹 τ 的概率。一次完整的经历:τ = (s₀, a₀, r₁, s₁, a₁, r₂, s₂, a₂, r₃))
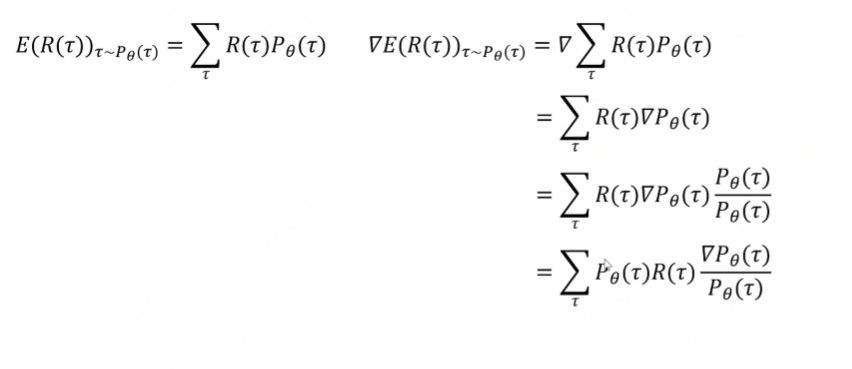
看到这样一个变形,

可以转化为下图的形式
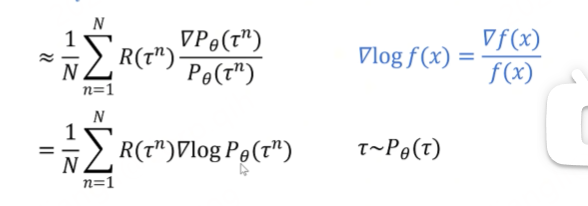
认为下一个状态完全是由当前状态和当前动作决定的

那么一个策略的概率,就是在这个策略中的所有的state和这个state下给出的action的概率的连乘。
对所有的tragection期望最大的梯度,用这个梯度乘以学习了进行更新神经网络里面的参数,这就是梯度策略算法。去掉对梯度的求导,
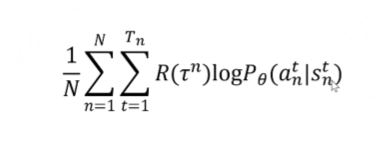
如果一个trajectory得到的reward是大于0的,那么就增大这个trajectory里面所有状态下采取当前action的概率。如果一个trajectory得到的reward是小于0的,那么就减小这个trajectory里面所有状态下采取当前action的概率。(看整条轨迹的回报是否相对最好)
实际应该如何训练一个Policy network 。
首先需要定义一个损失函数: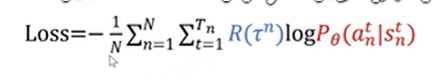
最大化目标函数取负数,让优化器最小这个东西
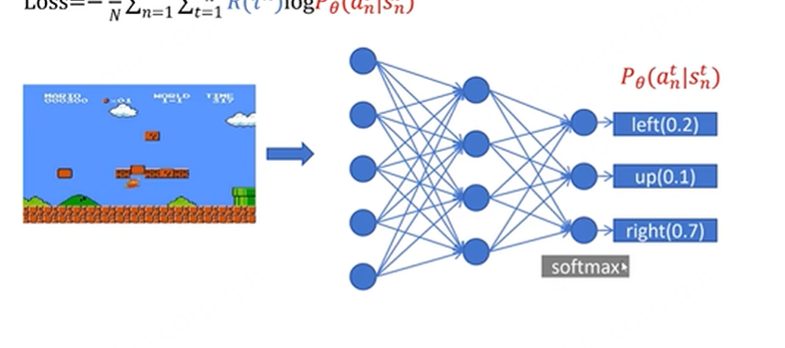
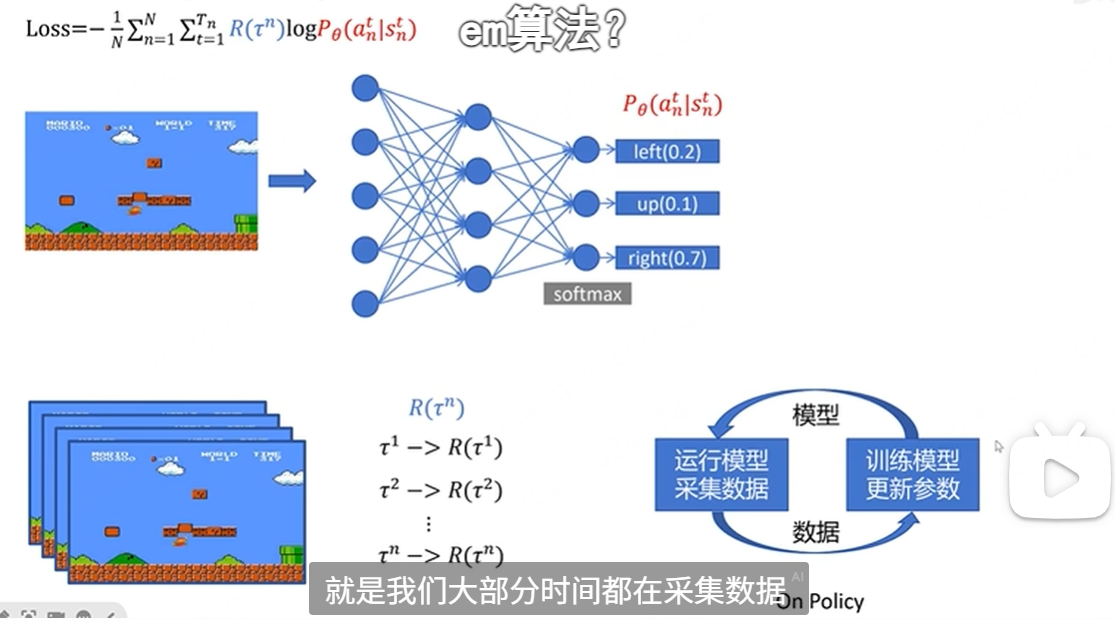
采集数据,数据包括每一步的状态、动作、奖励、最终的总回报
玩n场游戏,得到n个tragectory和n个return值,这个return值就是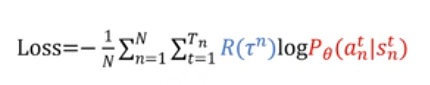 这个里面的蓝色部分。对每一步的action都是按照概率进行采样,不是采取最大值,这样就得到loss中的所有的值。可以进行一个batch的训练来更新网络。更新网络,再玩n场游戏,采集数据、训练一个batch,往复循环。这种更新策略叫做 on policy 就是采集数据和训练用的是同一个,这个问题就是大部分时间都在采集数据,非常慢。
这个里面的蓝色部分。对每一步的action都是按照概率进行采样,不是采取最大值,这样就得到loss中的所有的值。可以进行一个batch的训练来更新网络。更新网络,再玩n场游戏,采集数据、训练一个batch,往复循环。这种更新策略叫做 on policy 就是采集数据和训练用的是同一个,这个问题就是大部分时间都在采集数据,非常慢。
改进空间:是否增大或减小在状态s下做动作a的概率,应该看做了这个动作之后,到游戏结束累积的reward,而不是整个tragetory累积的reward。因为一个动作只能影响他后面的reward不能影响之前的
第二点:一个动作是可以对接下来的reward产生影响,但是只可能影响接下来的几步,而且影响会逐渐衰减,后面的reward更多是由当时的动作影响
针对于这两点,可以修改公式,首先对reward求和,不是对整个tragectory进行求和,而是从当前到结束的reward的求和,第二点是引入衰减因子,距离当前t越远,当前动作对reward的影响越小,呈指数衰减。距离当前越远的reward受当前动作的影响越小
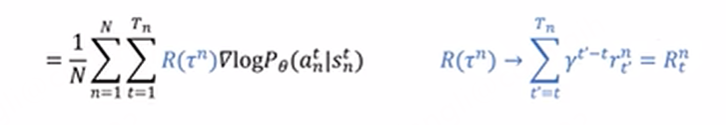
在好的局势下,做任何动作都是正的reward。相反
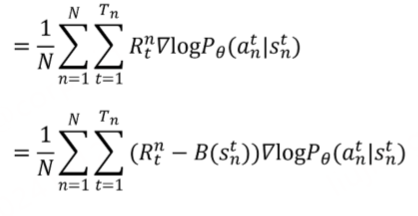
在好的局势下,会增大所有概率,但是这样会让训练减慢。所以要让相对好的动作概率增加。设置一个baseline,减去一个baseline。这个动作相对于其他动作的baseline。这个baseline如何确定,也需要使用神经网络来进行估算。
用来做动作的神经网络就是actor.对动作打分的网络就是critic网络。

优势函数,做出某一个具体动作得到的回报,比这个状态的期望回报的差值,表示这个动作相对于其他动作的优势
当前动作带来的return-baseline,实际就是表达优势函数。使用优势函数替换
怎么计算优势函数,看一下优势函数的定义:

动作价值函数-状态价值函数。看一下二者的关系
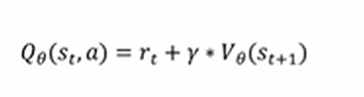
对于st时刻做出动作A期望得到的return值等于这一步得到的reward+衰减系数*下一个状态的状态价值函数,将这个等式代入优势函数
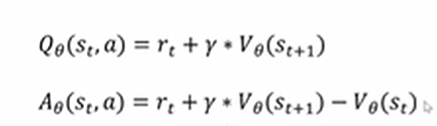
那么现在只需要管状态价值函数就行,不用管动作价值函数。
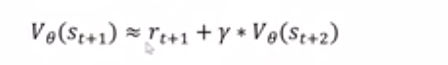
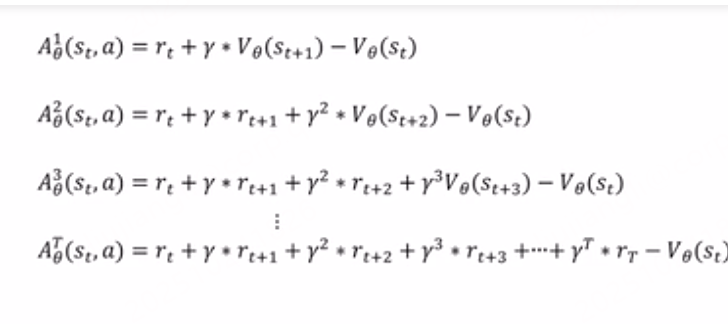
为了让式子简洁,定义一个中间变量
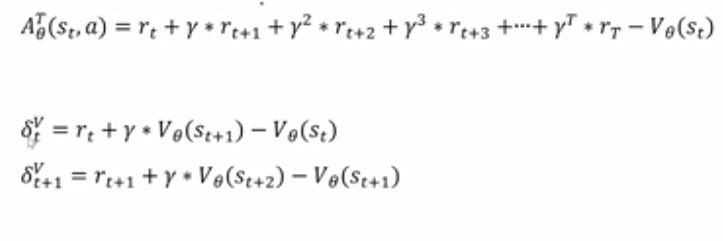
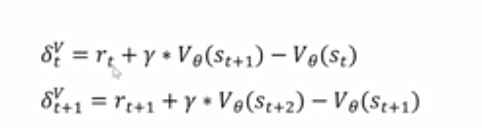
然后就可以变成这样:

完犊子开始晕了,我真服了
用西格玛表达式代入之后看起来比较简洁。GAE一步采样
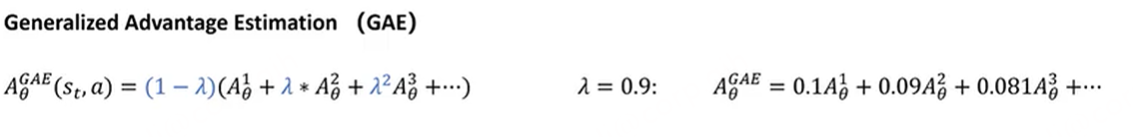
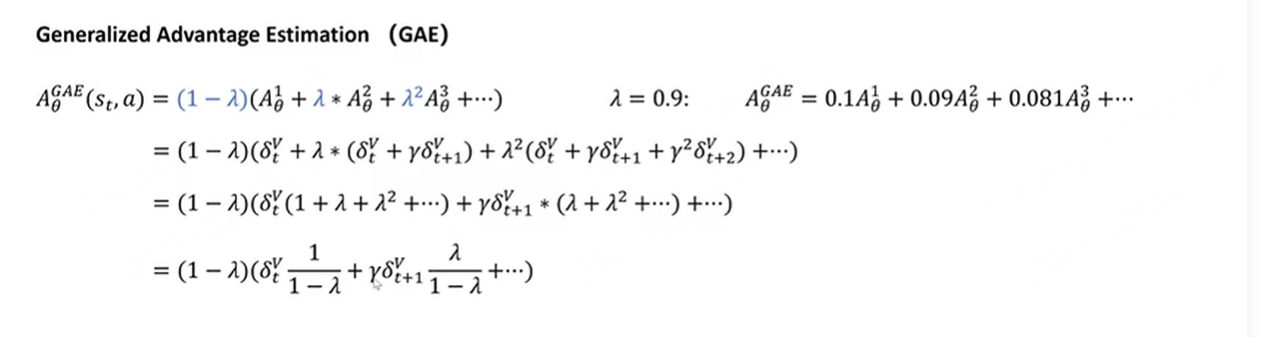
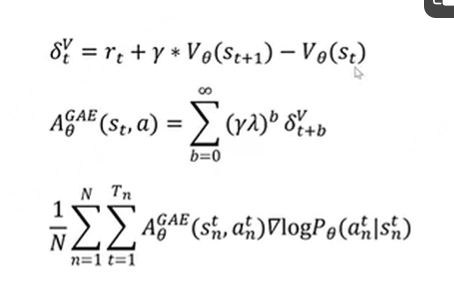
看不懂看不懂了
我不看了下次再看吧,我服了
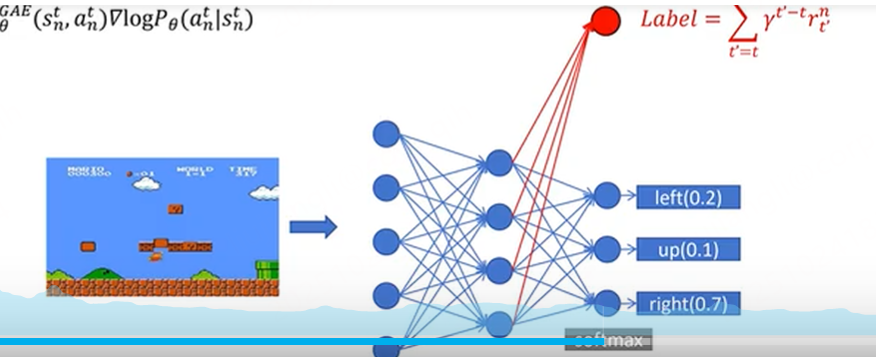
ppo邻近策略优化。
off policy同学们参考老师对小明的批评表扬,去调整自己的

不学了,下次再说吧

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)