音频分类-----Efficient Pre-Trained CNNs for Audio Pattern Recognition (EfficientAT)复现及tensorflow架构下推理
本文介绍了作者在音频分类任务中的实践,重点关注环境声音分类的工程化实现。作者使用EfficientAT模型,通过知识蒸馏方法将Transformer模型的能力迁移到轻量级CNN上,并结合动态卷积技术提升性能。针对公司内部数据样本不均衡问题,采用自定义CBLoss损失函数进行优化。为实现TensorFlow架构下的部署,作者将PyTorch前处理代码复写成TensorFlow版本,并将训练好的模型转
好久没写博客了,突然发现之前的一些博文被莫名奇妙加了VIP免费阅读的情况,已经手动改回全免费了。
最近涉及到了音频分类的任务,于是拿来写下博客加深下使用。
目录
简单介绍下写此CSDN的目的:
①当作笔记,后续如果涉及到相关任务,可以回过头来看看。
②分享一些思想(音频分类任务网上的资料还是比较少的)。
前言:
本人所做任务介绍:环境声音频分类任务方向,因此后续只讨论音频分类相关任务,且偏向于工程化的代码。主要看重于结果的ACC和Speed。 最终任务是进行 t e n s o r f l o w 架构下的推理,也就是说最终落地的代码不依赖于 p y t o r c h \textcolor{red}{最终任务是进行tensorflow架构下的推理,也就是说最终落地的代码不依赖于pytorch} 最终任务是进行tensorflow架构下的推理,也就是说最终落地的代码不依赖于pytorch);(这一点挺头疼的,额外多了好多pytorch代码转tensorflow代码的任务)。
涉及的类别有
labels = [
'Rain', 'Wind', 'Thunder', 'Bird', 'Frog', 'Insect', 'Dog', 'Honk', 'Background',
'Person', 'Other', '011Drill', 'Knock', 'Aerodynamic', 'Mech_work', 'Changming', 'Cat', 'FireCracker','Chicken','Airplane']
训练样本个数:
[14562, 9007, 8266, 15027, 6334, 11761, 5067, 3827, 9314, 7505, 5938, 7138, 4332, 3196, 4524, 5127, 2942, 3482, 3019, 9261]
目标: 在tensorflow架构上进行部署推理,进行音频分类(这也是为什么标题中提到tensorflow,也是为什么后续的实现代码都是tensorflow语言)。
由于公司保密协议,公司内部音频数据不予公开,不过复现思想是可以分享的。我想用到其它音频分类任务是可以直接复用的。
补充说明:
可以看到本人做的音频分类任务中,出现样本不均衡问题,后续本人会使用自定义CBLoss损失函数来约束样本不均衡问题。关于CBLoss的具体实现,后续会给出tensorflow架构代码,CBLoss为何有用,还请读者自行查找相关资料。简言之CBLOSS可以看作 权重值*CE,其中权重值是样本个数倒数相关的函数)。
后续代码的主要实现过程是:
训练阶段:①用tensorflow复现pytorch的前处理过程(waveform—stft----logmel—归一化);②修改作者开源pytorch训练代码,使用自定义CBLoss+SupConLoss(tensorflow代码实现)进行训练。
测试,推理阶段: ① pt/ pth转为onnx模型 ② tensorflow前处理+onnx推理,以实现纯tensorflow架构下的模型推理。
论文简介:
原作者开源代码,论文地址:
https://github.com/fschmid56/EfficientAT
第一篇论文(蒸馏):Efficient Large-Scale Audio Tagging Via Transformer-To-CNN Knowledge Distillation.
https://arxiv.org/pdf/2211.04772
第二篇论文(动态性)Dynamic Convolutional Neural Networks as Efficient Pre-trained Audio Models
https://arxiv.org/pdf/2310.15648
下面来简单的看一下论文方面的简述:
**背景:**在音频标签(audio tagging)任务中,如 AudioSet 这类大规模数据集,最近基于谱图的 Transformer 模型(如 Audio Spectrogram Transformer (AST))获得了很强的效果。论文指出,这些 Transformer 虽然性能高,但 模型体量大、计算开销高、推理慢。
**目标:**论文希望设计一种 高效的 CNN 模型(计算资源更少),但又能接近甚至超越现有 Transformer 模型在音频标签任务中的性能。
**方法:**使用 离线知识蒸馏(knowledge distillation, KD),即用复杂但高性能的 Transformer 模型作为「老师(teacher)」,然后训练一个轻量级 CNN 作为「学生(student)」。通过这种方式,学生模型学习老师模型的“软标签”或中间表示,从而在资源受限环境中也能获得较好的性能。
**第二篇论文:**作者引入了动态性(代码的具体实现是自适应池化,动态卷积等),用来提高高效cnn的容量CNN块,由动态非线性构成,动态卷积和注意机制。展示了这些动态cnn优于传统的高效cnn性能复杂度的权衡和参数效率
(后续效果展示确实如此,详见第二个图)
**成果:**论文展示了多个不同规模的 CNN 模型(基于 MobileNetV3 结构)在 AudioSet 上的表现。其中甚至单个模型的mAP(mean Average Precision)可达约 0.483。 大幅超越了之前音频分类的模型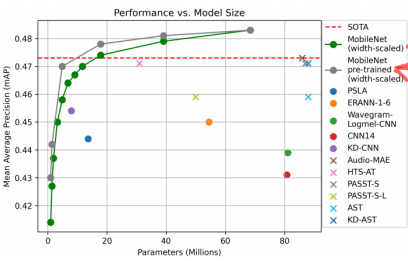
如下是github中作者给出的各模型对比(非常详细,写得很好)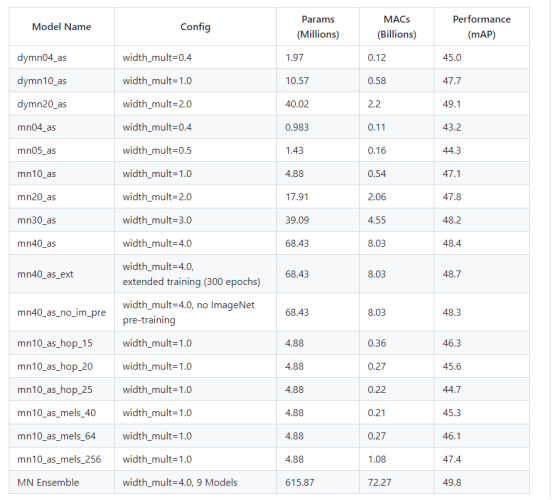
本人在工作相关任务中,对比了mn05_as , mn10_as, mn20_as. Dymn10_as,dymn20_as。 (后续本人给出的代码中,修改TYPE即可)
最终本人采用了dymn20_as,结果大致如下: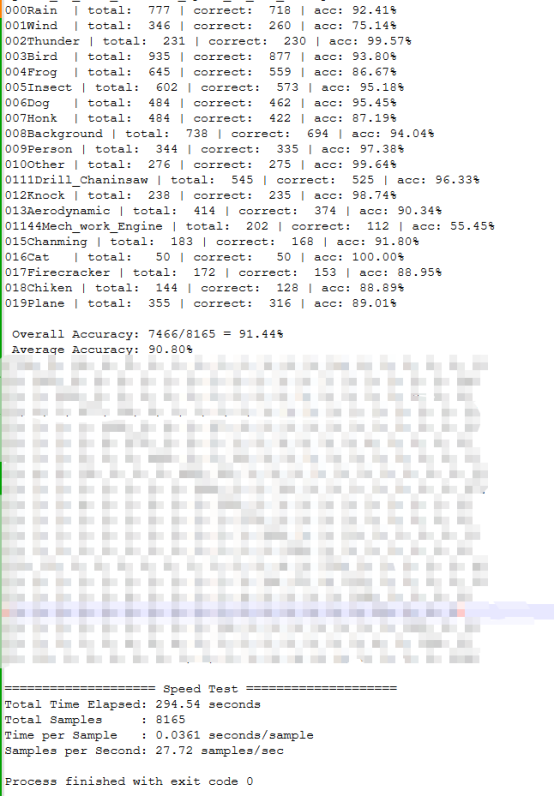
(混淆矩阵数据不予展示)
PS:以往公司内部模型的ACC仅能达到86%左右且速度在8samples/sec,后续使用此模型可以提高到91.44%且速度在27.72samples/sec。
遇到的问题:使用非dynamic的模型时(mn05_as , mn10_as, mn20_as)应用到本人任务后,ACC始终在75%左右。不知道是什么原因:①本人代码能力有限,②数据集问题,③dynamic更适用于本人任务的音频分类。
工程化方面/具体代码:
我将所有使用到的代码上传到了github:
https://github.com/refreshment-coffee/EfficientAT_tensorflow
作者有给出示例,用来训练自己数据集的代码:(pytorch架构)
可供参考
https://github.com/fschmid56/EfficientAT/blob/main/ex_fsd50k.py
下面将展示如何在tensorflow架构上进行推理。
需要得设备:装有pytorch的环境(用于训练)和装有tensorflow的环境(用于最终推理)
想法:
EAT音频分类任务的数据流程情况是
①waveform----前处理(stft)----log_mel特征 (pytorch语句实现)
②log_mel特征送入Pytorch模型进行训练。
因此只需:
①前处理代码用tensorflow进行复写,一定要确保,其输出的尺度和②的输入尺度是一致的!!!(或者这样理解,将前处理代码当作是黑盒, 输出开源代码的前处理输出shape。后续进行tensorflow语言复写时,确保输出shape是一致的)
注意这里:不需要完全去得到前处理后相同的结果。
②pytorch训练的模型无法在tensorflow架构下使用!那么可以转为中间模型格式----onnx
问题就转变成了:
①前处理代码的tensorflow复写问题
②pytorch模型(pt,pth)转为onnx的格式的问题。
问题一:
首先看pytorch源代码:
https://github.com/fschmid56/EfficientAT/blob/main/models/preprocess.py
可以发现,其实就是对waveform进行stft变换后,再进行求功率谱,最好就是生成 mel 滤波器,然后取log最后在进行归一化。
其实这些操作在tensorflow中也有对应API,
stft变换—tf.signal.stft
Mel滤波器—tf.signal.linear_to_mel_weight_matrix
mel_spec = tf.matmul(power_spec, mel_weight)
取log—mel_spec = tf.math.log(mel_spec + 1e-5)
因此,可以得到tensorflow的前处理代码
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1024/models/preprocess.py#L92
import tensorflow as tf
class AugmentMelSTFTTF:
def __init__(self,
sr=32000,
n_fft=1024,
hopsize=320,
win_length=800,
n_mels=128,
fmin=0.0,
fmax=15000):
self.sr = sr
self.n_fft = n_fft
self.hopsize = hopsize
self.win_length = win_length
self.n_mels = n_mels
self.fmin = fmin
self.fmax = fmax
# mel 权重矩阵可以提前计算好
self.mel_weight = tf.signal.linear_to_mel_weight_matrix(
num_mel_bins=self.n_mels,
num_spectrogram_bins=self.n_fft // 2 + 1,
sample_rate=self.sr,
lower_edge_hertz=self.fmin,
upper_edge_hertz=self.fmax
)
def __call__(self, waveform):
"""
waveform: [batch, time], tf.Tensor
返回: [batch, time_frames, n_mels]
"""
# 预加重
waveform = tf.concat([waveform[:, :1],
waveform[:, 1:] - 0.97 * waveform[:, :-1]], axis=1)
# STFT
stft = tf.signal.stft(
waveform,
frame_length=self.win_length,
frame_step=self.hopsize,
fft_length=self.n_fft,
window_fn=tf.signal.hann_window,
pad_end=True
)
power_spec = tf.abs(stft) ** 2
# mel 滤波
mel_spec = tf.matmul(power_spec, self.mel_weight)
# log
mel_spec = tf.math.log(mel_spec + 1e-5)
# fast normalization
mel_spec = (mel_spec + 4.5) / 5.
return mel_spec
问题二:
tensorflow前处理+pytorch训练代码
可以参考:
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1024/custom_train3_tensorflow_1021.py
其中数据集的情况如下:
需修改路径
路径下所要训练的部分类别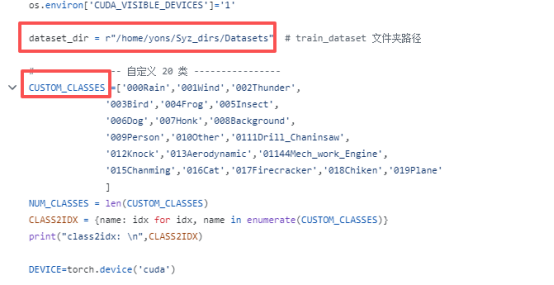

其中dataset_dir放所有的音频,后续数据集构造中,会对里面进行自动化分训练集和测试集。
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1024/customDataset.py#L154
损失函数方面
其中使用了自定义的tensorflow架构损失函数CBLoss和SupConLoss
由于EAT的pytorch模型的输出返回的是logits和features:
https://github.com/fschmid56/EfficientAT/blob/main/models/dymn/model.py#L195
这里可以看到。 因此可以使用SupConLoss。
其中CBLOSS和SupConLoss的tensorflow实现在
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1024/utils_syz.py#L81
问题三:pytorch模型(pt,pth)转为onnx的格式的问题。
其中由于本人使用的是dymn20_as的模型架构,在模型导出为onnx的时候会出现点问题
其中最需要注意的是onnx中的input_shape
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1021_ConvertOnnx_Inference/infer_pys/convert_onnx/pt2onnx.py#L54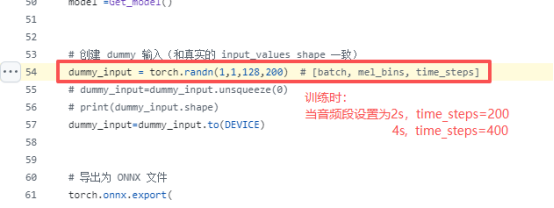
本人代码中的音频段是2s.
tensorflow前处理+onnx模型预测
import torch
# 本地加载模型
PT_NAME="./save_pts/dymn20_as_1021_custom22_epoch_25_acc_1000.pt"
save_onnx_name="../save_onnxs/EAT_dymn20_as_128_200_1022_25_1000_best.onnx"
##拆fold11 拆fold14
# CUSTOM_CLASSES =['000Rain','001Wind','002Thunder',
# '003Bird','004Frog','005Insect',
# '006Dog','007Honk','008Background',
# '009Person','010Other','011Drill',
# '012Knock','013Aerodynamic','014Mech_work',
# '015Chanming','016Cat','017Firecracker','111Chaninsaw','114Engine','018Chiken','019Plane'
# ]
CUSTOM_CLASSES =['000Rain','001Wind','002Thunder',
'003Bird','004Frog','005Insect',
'006Dog','007Honk','008Background',
'009Person','010Other','011Drill',
'012Knock','013Aerodynamic','014Mech_work',
'015Chanming','016Cat','017Firecracker','018Chiken','019Plane'
]
LABELS=CUSTOM_CLASSES
NUM_CLASSES = len(CUSTOM_CLASSES)
CLASS_DIM=NUM_CLASSES
DEVICE= torch.device('cuda')
from models.dymn.model import get_model as get_dymn
def Get_model():
model_name="dymn20_as"
device=DEVICE
strides=[2, 2, 2, 2]
head_type="mlp"
width=2.0 ### dymn20_as---width=2.0
pretrain_final_temp=1.0
model = get_dymn(width_mult=width, pretrained_name=model_name,
pretrain_final_temp=pretrain_final_temp,
num_classes=NUM_CLASSES,load_pt_path=PT_NAME)
model.to(device)
model.eval()
return model
model =Get_model()
# 创建 dummy 输入(和真实的 input_values shape 一致)
dummy_input = torch.randn(1,1,128,200) # [batch, mel_bins, time_steps]
# dummy_input=dummy_input.unsqueeze(0)
# print(dummy_input.shape)
dummy_input=dummy_input.to(DEVICE)
# 导出为 ONNX 文件
torch.onnx.export(
model,
dummy_input,
save_onnx_name,
export_params=True,
opset_version=13,
do_constant_folding=True,
input_names=["input_values"],
output_names=["logits"],
dynamic_axes={
"input_values": {0: "batch_size", 2: "time_steps"},
"logits": {0: "batch_size"}
}
)
onnx导出验证
对Pytorch训练的代码进行推理得到ACC1,
代码:
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1021_ConvertOnnx_Inference/infer_pys/custom_inference3_tf_mel_pytorch__%E5%8E%9F%E5%A7%8Blabel.py
对tensorflow+onnx推理代码得到ACC2,
代码:
https://github.com/refreshment-coffee/EfficientAT_tensorflow/blob/main/Project_EAT_1021_ConvertOnnx_Inference/infer_pys/custom_inference3_tf_log_onnx_%E5%8E%9F%E5%A7%8Blabel.py
ACC1几乎等于ACC2(误差不超过0.5%)
如果误差过大,那么可能是:
①前处理的问题
②模型转onnx中间出现问题,但不会终止转出,还是转换得到了onnx
③后处理未对齐。
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
最后,再次感谢此篇论文—EfficientAT。给予的贡献
原作者开源代码,论文地址:
https://github.com/fschmid56/EfficientAT
第一篇论文(蒸馏):Efficient Large-Scale Audio Tagging Via Transformer-To-CNN Knowledge Distillation.
https://arxiv.org/pdf/2211.04772
第二篇论文(动态性)Dynamic Convolutional Neural Networks as Efficient Pre-trained Audio Models
https://arxiv.org/pdf/2310.15648
欢迎交流
邮箱:refreshmentccoffee@gmail.com

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)