《Towards Robust Defense against Customization via Protective PerturbationResistant to Diffusion》论文分享
author={Wenkui Yang and Jie Cao and Junxian Duan and Ran He}
原文链接:https://arxiv.org/abs/2509.13922
摘要
像稳定扩散这样的扩散模型由于其强大的定制能力而在视觉合成任务中变得突出,但同时也带来了重大的安全风险,包括深度假冒和版权侵权。作为回应,出现了一类被称为保护性扰动的方法,它通过注入难以察觉的对抗性噪声来减轻图像的误用。然而,净化可以消除保护性干扰,从而使图像再次暴露在恶意伪造的风险之下。
在这项工作中,我们将反净化任务形式化,强调了阻碍现有方法的挑战,并提出了一个简单的诊断保护性扰动,名为AntiPure。由于两种指导机制,AntiPure暴露了“净化-定制”工作流程中的净化漏洞:1)补丁频率指导,它减少了模型对净化图像中高频分量的影响;2)错误的时间步长指导,它在不同的时间步长上扰乱了模型的去噪策略。有了额外的指导,AntiPure嵌入了在典型净化设置下持续存在的不可察觉的扰动,实现了有效的定制后扭曲。实验表明,作为净化的压力测试,AntiPure实现了最小的感知差异和最大的失真,性能优于净化-定制工作流中的其他保护性扰动方法。
一、Introduction
自从去噪扩散概率模型(DDPM)[15,43]和潜在扩散模型(LDMS)[35]的里程碑式的发展以来,扩散模型(DM)实际上已经主导了视觉生成的每一个子任务。这一成功可以归功于现成的开源稳定扩散(SD)[48],它支持更多的微调和编辑技术,以实现用户友好的定制。然而,这些进展也带来了风险,包括深度假货的泛滥以及对肖像权和知识产权的侵犯。
最近的研究[1,24-26,47,51,52,57]使对抗性攻击[11,22,27]适用于DM,创建了在微调定制过程中阻碍概念理解的“有毒”样本。具体地说,这些反定制方法-统称为保护性扰动-使用白盒攻击来寻找L盒内最具对抗性的扰动噪声,从而扭曲DM的输出。
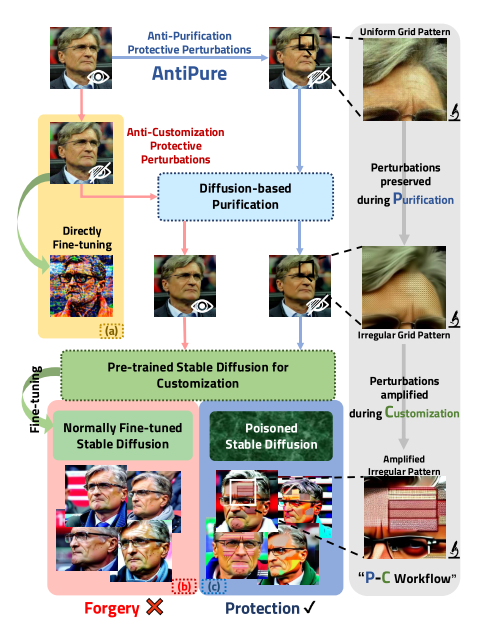
图1.“净化-定制”工作流概述图a)。保护性扰动使用小噪声来扭曲微调扩散模型的输出。b)。然而,现有的方法可以通过基于扩散的纯化来去除。c)。我们提出了一种简单的诊断方法,称为AntiPure,它实现了抵抗净化的保护性扰动,并使定制输出更具区分性。
不幸的是,这些对抗性的保护性扰动可以通过基于扩散的净化来消除[31,56,61]。这种方法将对抗性样本扩散到固定的时间步长,然后在去噪过程中同时去除对抗性噪声和扩散噪声。如图1所示,以前的方法很少考虑在提纯之前进行微调时如何保持保护效果。因此,这种两阶段的净化定制化(P-C)工作流程使得现有的保护性扰动容易受到攻击,并且在很大程度上是无效的。
在这篇文章中,我们展示了在典型的P-C环境中,尽管基于扩散的净化具有很强的去噪能力,但是抗净化的保护性扰动是可能的。首先,我们将如何在P-C工作流中实现这一点。我们观察到,扩散模型--作为一类概率模型--产生的输出可能在对抗性攻击所需的精细范围内变得高度不可预测,从而降低自适应攻击的有效性。基于此,我们不再试图保留净化过程中的反定制扰动,而是提出了直接针对净化模型的反净化扰动,以探测和揭露其弱点。通过实验,我们分析了反定制和反净化的区别,确定了使反净化更具挑战性的三个核心特征:1)缺乏易受攻击的网络组件,2)无需训练的冻结参数,3)固定的高时间步长去噪。
接下来,即使在这些严格的约束下,我们也提出了一种简单的诊断方法--AntiPure,它通过添加两种类型的指导来实现有效的保护结果:补丁频率指导(PFG)和错误时间步长指导(ETG)。由于嵌入在冻结参数中的干净图像的先验优先于低频结构,因此净化模型缺乏对高频细节的精细控制。因此,PFG调制模型预测的“干净”图像的每一块中的高频分量,导致由扰动注入引入的更局部化的知觉差异。此外,虽然整体结构通过高时间步长去噪来锚定,但ETG有助于绕过时间步长的限制。通过最小化跨时间步长的输出距离,ETG降低了模型对其时间步长输入的敏感度,并阻碍了其在每一步确定适当动作的能力。总而言之,这些机制使AntiPure能够实现最小的感知差异和最大的输出失真。
简而言之,我们的贡献可以总结如下:
·我们首先形式化了P-C工作流中有效的保护性扰动的要求,并在深入分析核心挑战的基础上,提出了直接针对目标净化的反净化,克服了以前反定制扰动的局限性。
·我们提出了一种简单的诊断方法,名为AntiPure。AntiPure利用补丁频率指导和错误的时间步长指导来应对上述反净化挑战。
·最后,我们建立了一个基准来评估之前的反定制方法和我们在P-C工作流程中的AntiPure的有效性。实验结果表明,在净化收敛时,AntiPure达到了最小的感知偏差和最高的输出失真,优于现有的方法。
二、Related Works
Customization with Stable Diffusion.(具有稳定扩散的定制)随着扩散模型[8,14,15,43-46]的快速发展,一系列的文本到图像(T2I)模型[30,33-35,39]在定制生成方面显示出非凡的潜力,其中开源稳定扩散(SD)[35]成为社区的最爱。通过各种精调和条件控制技术,预先训练的模型可以进一步满足特定概念和更精细控制的需要。文本倒排[9]在T2I模型的嵌入空间中学习伪词。DreamBooth[38]结合了在完全微调期间特定类别的先前保留损失,以减轻遗忘。在参数高效微调(PEFT)[16]之后,自定义扩散[21]只修改交叉注意层的权重,而LORA[17]改编自大型语言模型(LLM),使用等级分解矩阵将概念视为参数的偏移量。对于额外的条件控制,T2I-Adapter[29]和ControlNet[59]集成了来自其他条件输入的额外指导。
具有保护性扰动的反定制。定制方面的进步引起了人们对深度假冒、隐私和版权的极大担忧。在这方面,保护性扰动可以作为一种潜在的解决办法,帮助防止滥用和确保真实性。这可以追溯到生成性对抗网络(GANS)[10]的时代,当时研究[18,37,54,58]探索通过白盒攻击[11,22,23,27]来扭曲基于GAN的图像翻译和编辑[5,12,55,62]的输出。
对于扩散模型,AdvDM[25]首先使用投影梯度下降(PGD)[27]来使用蒙特卡罗估计最大化潜在扩散模型的训练损失[55]。这种方法在Mist[24]中得到了进一步扩展,增加了纹理损失。Glze[41]通过攻击SD的编码器来保护图稿,而PhotoGuard[40]通过同时攻击编码器和UNET来解决未经授权的图像修复问题。朱等人。[63]利用基于GAN的生成器创建嵌入可追踪水印的敌意示例。反DreamBooth(反DB)[51]针对DreamBooth中的微调过程,引入了一种新的反向传播代理,以从干净和部分对抗性的例子中学习。在反数据库的基础上,SIMAC[52]设计了一种自适应的贪婪时间间隔选择。赵等人。[61]总结当前的挑战,提供精调方法的基准,并揭示当前技术对净化的敏感性。同时,MetaCloak[26]元学习稳健的、可转移的保护,而CAAT[57]干扰交叉注意以获得有效的、无需训练的扰动。最近,FastProtect[1]以实时部署为目标,IDProtector[47]训练一次通过编码器来防御生成。
扩散模型的对抗性净化。净化通过重新生成或细化输入图像来去除对抗性噪声,扩散模型因其迭代去噪能力而受到关注[31,53,56]。DiffPure[31]使用无条件扩散模型在选定的时间步长上扩散敌意样本,然后通过求解反向SDE来对其进行去噪。DensePure[56]增强了经过验证的预训练分类器的健壮性。然而,这些专注于分类器的方法可能对定制所需的高分辨率和感知一致性不敏感。GrIDPure[61]使用更短的时间步长扩散、多次迭代和重叠网格,以提高定制的纯净度。
三、Preliminaries
在这里,我们将简要介绍必要的预备知识。更多详情,请参阅附录A。
Customization 定制的本质是在较小的特定于概念的集合上微调一个模型,该模型在大规模数据上进行预训练,以捕捉看不见的概念,而稳定扩散(SD)[35]是一个流行的选择。在给定输入图像x0及其文本提示y的情况下,噪声预测器UNET[36]ϵθc和文本编码器τθc与用于定制的SD参数θc通过以下方式进行联合优化:
![]()
其中,在给定VAE编码的![]() 的情况下,在重新参数化下通过闭合形式扩散对潜伏期Zt进行采样。
的情况下,在重新参数化下通过闭合形式扩散对潜伏期Zt进行采样。
Anti-customization利用对抗性攻击生成,旨在通过注入保护性扰动δadv来扭曲在微调过程中学习到的概念。对于最优解,这是一个鞍点问题:
![]()
其中![]() 是限制在半径为L∞的Lη球内的对抗性摄动。在实践中,我们经常简化公式。公式(2)利用I-FGSM[22,23]或投影梯度下降法[27]等白盒方法,最大化Lldm以逼近最优δadv。
是限制在半径为L∞的Lη球内的对抗性摄动。在实践中,我们经常简化公式。公式(2)利用I-FGSM[22,23]或投影梯度下降法[27]等白盒方法,最大化Lldm以逼近最优δadv。
Purification 可以在保持全球结构的同时消除对抗性噪音,从而使保护性扰动无效。预先训练的无条件扩散模型,如DDPM[15],可以固有地用于纯化,因为在正向扩散过程中,干净的和敌对的样本的分布随着时间的推移而收敛。
基于扩散的净化的开创性工作DiffPure[31]在时间步长tp对输入的敌意图像进行扩散,并将其去噪回到净化图像。在简化的离散DDPM形式中,这可以写为:
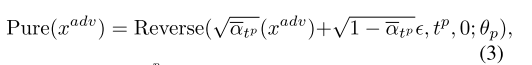
其中![]() ,其中βt表示扩散方差。Reserve(·)通过使用冻结的净化参数θp的无学习采样,将在时间步长tp处扩散的对抗性样本从较高的时间步长tp迭代地去噪到较低的时间步长0。在反定制领域,GrIDPure[61]采用DiffPure来满足SD的要求,将较长的去噪时间步长转换为多个较短的迭代,从而获得增强的净化效果。
,其中βt表示扩散方差。Reserve(·)通过使用冻结的净化参数θp的无学习采样,将在时间步长tp处扩散的对抗性样本从较高的时间步长tp迭代地去噪到较低的时间步长0。在反定制领域,GrIDPure[61]采用DiffPure来满足SD的要求,将较长的去噪时间步长转换为多个较短的迭代,从而获得增强的净化效果。
四、Analysis
4.1Anti-purification: Overall Formulation
对于抗净化的理想扰动,我们首先将我们的目标形式化如下:
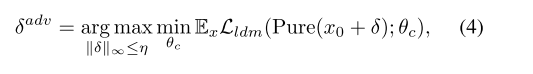
其中,δadv通过最大化Lldm进行了类似的优化,但用净化的输入替换了原始的输入。然而,直接反向传播在这里的计算效率很低,因为净化在多次迭代中生成非常深入的计算图。此外,与传统的对抗性攻击不同,反定制需要与SD相关的大量内存开销,而分类器的大小是不可比拟的。
或者,我们分解方程。(4)分阶段进行。由于P-C工作流程是连续的,只要程序中的一个环节发生故障,就无法实现有效的微调。有趣的是,两个相反的目标可以实现这一点:
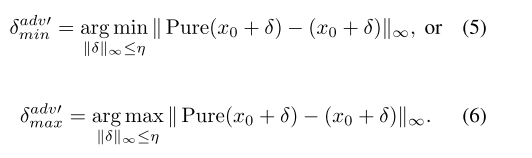
按公式计算(5)与公式相结合。(2),我们可以近似纯(X)≈x,允许公式。(4)退化为等式。(2)即使在净化条件下也是如此。这遵循了自适应攻击的原则,并导致了稳健的扰动,在净化后仍然可以进行目标定制。然而,涉及两个目标(等式)的联合优化。(5)和等式。(2))也很难找到最优解。此外,概率扩散模型可能导致生成的图像在对抗性噪声所需的精细尺度上几乎完全无法控制。如图2所示,干净图像和对抗性图像(几乎重叠)之间的差异远远小于净化输出的范围,并且随着tp的增加,净化的干净图像和对抗性图像的分布趋于收敛。因此,我们主张另一种方法,而不是将纯化视为一种特殊的转换,并要求纯化的输出准确地到达所需的“对抗性区域”。
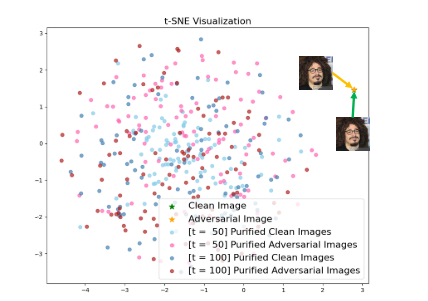
图2.T-SNE[50]可视化(困惑=10)使用DiffPure[31]获得的4×100纯净图像,对于干净图像和对抗性图像具有不同的时间步长。
按公式计算(6)对净化采取直接攻击,即反净化。我们注意到,反净化并不打算作为反定制的大规模替代,而是作为各种新出现的工作流程中的一个准备步骤来补充。在这种情况下,即使随后的定制操作正常,在提纯过程中学习的目标概念仍然与原始图像的目标概念扭曲。这将我们的攻击重点从定制的LDM转移到(基于DDPM的)净化中使用的DDPM:
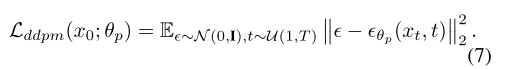
不幸的是,由于净化本身的固有特性,通过最大化这种DDPM训练损失进行的直接攻击不能达到反定制方法中所看到的相同程度的语义结构扭曲。这使得反净化成为一项更具挑战性的任务,困难概括在以下三个核心原因中。
4.2. Anti-purification: Why harder?
在这里,我们报告我们的小规模实验的结论。具体设置请参见附录B.2。
4.2.1。Reason 1: Lack of Vulnerable Components
针对LDM/SD的攻击更容易,因为它们的编码器更容易受到攻击。相比之下,DDPM中唯一的组成部分--UNet[36]--非常强大。

图3.对DreamBooth[38]的攻击要困难得多。与普通像素空间攻击(a.→d.)不同,潜在空间攻击(b.→e.)无法以易受攻击的VAE编码器为目标。这里,d.(译自e.)仅用于可视化目的;在我们的实验中,我们在微调过程中将B.直接替换为E.
首先,我们修改了Anti-DB的ASPL方法[51],直接对Eq. (1)进行PGD攻击。(1)但在潜在空间中,从而获得(e.)图3中的对抗性潜伏期(而不是用于进一步编码的对抗性图像)。如图3所示,(d.)从这些潜伏期解码的图像表现出意想不到的风格转换,并且(f.)SD在这些潜伏期上微调生成的图像显示出与(d.)最小的差异。这表明,如果PGD不能利用来自易受攻击的VAE编码器的渐变,攻击的有效性将显著降低。
此外,我们还直接攻击Lddpm。图4说明了在不同时间点的各个UNet技术中心块的输出中的干净图像和对抗性图像之间的差异。注意,下采样块和中间块的差异很小,而上采样块的中间部分出现了显著的偏差。然而,输出最终仍然收敛,这可能归因于独特的剩余连接:对抗性噪声的影响随着网络空间结构的迭代而自然累积,而较浅的剩余连接削弱了这种影响,迫使扰动平息到较低的水平,导致峰值效应。
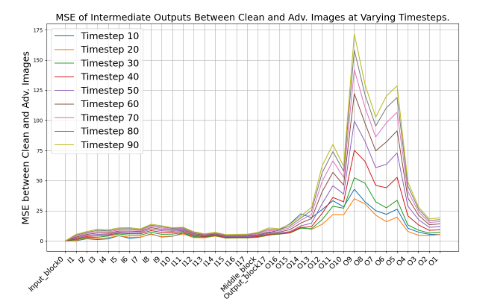
图4.在不同的时间步长上,在不同的UNT区块上的清洁样本和对抗性样本之间的中间输出的均方误差。详情见附录B.2。
4.2.2. Reason 2: Training-free Frozen Parameters

图5.MasaCtrl[3]对对抗性图像的有效性。Lost攻击没有什么不同,除了E.和F.的右下角图像在背景中有轻微的噪声。
值得注意的是,与反定制不同,反定制的目标是通过数据中毒进行微调,反净化的目标是一项无需训练的编辑任务。在反净化中,预先训练的净化模型不需要额外的调整,因此对抗性样本不会影响其嵌入到冻结的θp中的良性先验。对其他无需训练的编辑任务的攻击也会出现类似的问题。如图5所示,在某些情况下,对于MasaCtrl[3],扰动会降低图像质量,MasaCtrl[3]也依赖于易受攻击的编码器。然而,它不能达到与扰动微调相同的退化水平。
4.2.3.Reason 3: Fixed High Timestep Denoising
在去噪过程中,图像的低频结构信息在很大程度上是在较高的时间步长确定的,而在较低时间步长的去噪侧重于高频的纹理变化。在这里,我们注意到,净化过程可以被视为一个生成过程,其中固定了高时间步长的去噪。在没有易受攻击的组件和冻结参数的情况下,对时间步长超过t^{p}的时间步长执行基于Lddpm的攻击没有直接意义,并且试图通过以低时间步长调整输入来实现语义结构更改也是不可行的。本质上,对纯化本身的攻击是仅限于低时间步长的高频分量的攻击。
五、Method: AntiPure
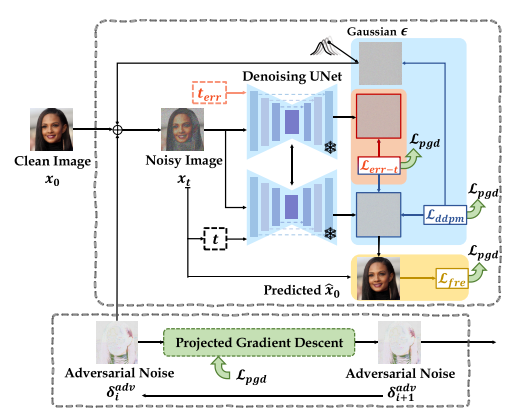
图6.AntiPure的概述图。AntiPure减轻良性前科的负面影响(SEC4.2.2)和有限的时间步长(秒4.2.3)通过引入补丁频率制导LFRE和错误的时间步长制导LT−Err.
以SEC中的公式为基础。4.1,我们的目标是通过Eq生成专门针对净化模型本身的最具对抗性的输入。(6)。如SEC中所强调的。4.2、实现反定制等语义结构扭曲对于反净化是不可行的。然而,我们仍然可以提高定制的成本,并实现保护性扰动,使P-C工作流的输出更容易区分。我们的AntiPure的整体攻击过程如图6所示。
5.1. Patch-wise Frequency Guidance
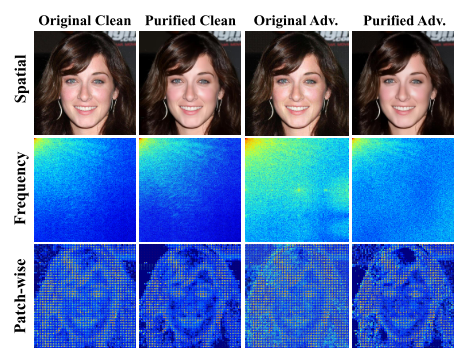
图7.DDPM净化前后空间和频域的差异。将伪彩色变换应用于DCT频谱图以获得更好的可视化效果。
嵌入在冻结网络参数中的清洁图像的先验允许净化模型在反向去噪过程中恢复到与人的直觉一致的高质量图像分布。即使特定的时间步长受到有效攻击,总体输出在结构上通常也能保持高质量。然而,与低频语义结构不同,高频成分的一致性更难保证,这使得它们在提纯过程中更难控制。如图7所示,尽管简单地使用\保护\数学{L}_{DDPM}-攻击在空间域中没有产生明显的效果,但它们在频域中引入了明显的差异。
这一现象促使我们将注意力转移到频域。一种可行的解决方案是调制高频分量,其中净化通常施加较弱的控制,从而导致纯化的输出主要在高频段偏离清洁的先验。此外,由于人类感知的特点,调制高频分量对图像语义信息的影响较小。对于更精细的空间调制,我们在较小分辨率的块上操作以定位感知差异,形成我们的逐块频率制导(PFG)。
具体地说,在pgd的第i步,给定干净的图像X0∈Rc×H×W、高斯噪声ϵ和对抗性噪声δadv i,我们在Adv.Images干净图像时间步t处扩散噪声对抗性样本Xt如下:
![]()
其中![]() ,其中βt表示扩散方差。使用UNet的输出ϵθ(xt,t),我们通过以下公式来近似预测的去噪图像bx0:
,其中βt表示扩散方差。使用UNet的输出ϵθ(xt,t),我们通过以下公式来近似预测的去噪图像bx0:
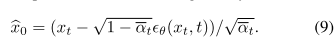
接下来,补丁频率制导在bx0上进行操作,以跟踪UNT的梯度,同时强调高频分量,这可以被形式化为:
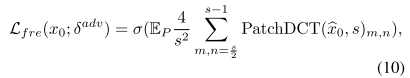
其中PatchDCT(·)(图7第3行所示)将bx0展开成大小为S×S的P个补丁,并对每个补丁应用离散余弦变换。经过DCT变换后,低频分量占据谱图的左上角,而高频分量位于右下角。因此,对每个补丁的右下角进行过滤、平均,然后用σ(·)进行S型归一化,以产生Lfre。
简而言之,Lfre的目标是在对不同的时间步长进行去噪后,增强净化模式预测的高频成分,间接加强对抗性扰动的高频成分,并创建统一的网格模式。由于攻击针对的是更高的频率,局部结构信息被最小限度地改变,确保了人类更大的感知一致性。
5.2. Erroneous Timestep Guidance
如SEC中所述。4.2.3,净化基本上可以被视为一个生成过程,其中高时间步长的去噪已经被固定,这意味着图像的结构不能被明显改变。然而,我们可以鼓励噪声预测器在不同时间步长的输出尽可能接近。通过注入对抗性噪音,我们确定了联合国技术援助机构努力选择跨时间步长的适当行动的输入,这是我们通过错误的时间步长指导(ETG)实现的。
具体地说,我们选择错误的时间步长Terr作为NET的输入,以获得在较高时间步长的x_t的噪声预测,并且我们最小化在错误的时间步长ϵθ(Xt,Terr)预测的噪声和正确的预测ϵθ(Xt,t)之间的差异:
![]()
5.3. Overall Attack
如图6所示,我们的攻击将Lfre和Lerr−t指导与Vanilla Lddpm结合在一起。为了平衡不同训练目标的数值范围,PGD中用于坡度上升的总损失可表示为:
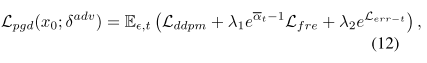
其中,攻击时间步骤t∼U(1,tp)被约束在提纯步骤范围tp内,以避免无效攻击。超级参数\lambda_1和\lambda_2均设置为0.5,为方便起见,t_{err}已修复。系数eαt−1缩放Lfre,以随着t的减小而增加其影响。在给定最小MSE值的情况下,我们将指数函数应用于LER−t以进行稍微更积极的优化。最后,pgd最大化lpgd以找到最优的δadv。
六. Experiments
量化指标。对于定制的输出,我们首先使用FID[13],这是生成性任务中的一种通用度量,它使用先启v3[49]量化合成图像和真实图像的特征分布之间的距离。此外,我们还包括来自Anti-DB的指标[51]。由于我们的主要目标是生成非真实感人脸,因此我们使用流行的ArcFace识别器来评估合成图像的面部特征与对应身份的真实特征之间的余弦相似性[6]。我们还报告了使用RetinaFace检测器的人脸检测失败率(FDFR)[7],测量ISM评估中排除的无法检测到的人脸的比率。此指标仅用于为ISM提供更全面的参考,因为如前所述,在净化后产生完全扭曲的面部是不可行的。最后,我们使用了一种额外的无参考图像质量评估度量,BRISQUE[28],这是一种经典且流行的方法来衡量生成的图像质量。对于扰动本身,提供了一个重建度量LPIPS[60]来评估人类感知的差异。当我们专注于破坏净化后的SD的输出时,更高的FID,更低的ISM和更高的BRISQUE意味着对抗效果的增加。此外,较低的LPIPS意味着更多的不可察觉的扰动。
Comparison with Baseline Methods
量化结果。我们首先通过DreamBooth对带有不同扰动的纯化图像进行SD微调,将实例提示和推理提示设置为“一张SKS人的照片”。为了公平起见,在所有扰动方法之间共享相同的200个先验类图像集。这些量化结果显示在表1.
在选项卡中。1,在两个数据集的所有指标中,AntiPure都实现了最佳性能。经过充分的纯化后,以前的方法的效果明显降低,但可以更好地保留AntiPure的效果。更重要的是,虽然这些方法依赖于各种定制配置,但AntiPure只专注于相对简单的纯化过程。另一方面,由于JPEG压缩引起的扰动图像退化,CelebA-HQ上的结果明显比VGGFace2上的结果差,即使考虑到潜在的域间隙。
有趣的是,SIMAC在提纯后表现出更大的性能下降。与Anti-DB相比,改进的SIMAC在扰动图案周围产生了更平滑的边缘,使它们更容易受到攻击。AdvDM和Mist之间也有类似的区别。
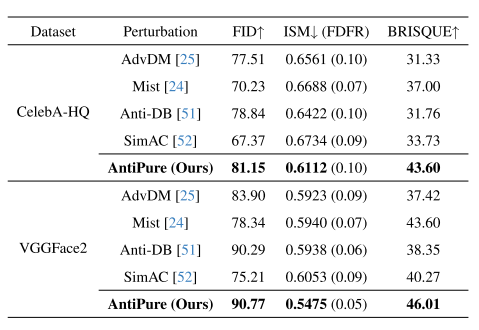
表1.P-C工作流程后不同扰动方法下DreamBooth[38]输出质量的比较。
定性结果。我们在图8中展示了更多的结果。在我们选择的例子中,产出退化的程度从上到下加剧。如前所述,经过净化后,扰动方法不能真实地实现整体语义结构层面的扭曲。然而,AntiPure的目标并不是调整扰动,以最大限度地扰乱定制过程。相反,它的目的只是为了降低净化输出,利用微调过程本身的特性来放大这些构件。这种方法可能不会实现一个人的身份信息的失真,但它足以让人类辨别真伪。

图8.P-C工作流程后DreamBooth的输出可视化
6.3. Different Customization Method
为了评估AntiPure的泛化能力,我们还使用了另一种流行的微调方法LORA。与DreamBooth不同,LoRa通过低级分解显著降低了微调成本。同时,它还可以包含DreamBooth的核心类特定的优先保留损失。如选项卡中所示表2、我们的方法仍然优于其他扰动方法,在ISM度量上与其他方法相比有明显的差距,这表明我们的方法有效地降低了人脸特征相似度。
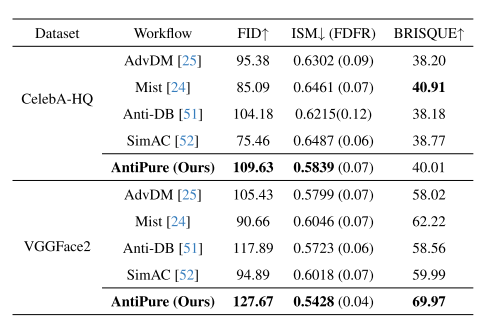
表2.P-C工作流程后不同微扰方法下LORA[17]输出图像质量的比较。
6.4. Different Purification Configuration
直观地说,随着净化迭代次数的增加,保护性扰动被逐步消除,从而产生更好的微调输出质量。为了验证这一点,我们从之前的实验中选择了最健壮的方法AntiDB(除了AntiPure之外),并应用了10次迭代的多轮纯化,然后在CelebA-HQ上进行了DreamBooth微调。如图3所示,Anti-DB的有效性确实随着迭代次数的增加而逐渐减弱,正如预期的那样,ISM稳定在20-40次迭代左右,表明接近收敛。
出乎意料的是,专注于对抗净化过程的AntiPure随着更多的迭代而变得越来越健壮。虽然在迭代次数较少的情况下,其最初的有效性低于Anti-DB,但在大约30-40次迭代后,AntiPure超过了Anti-DB。这也表明,我们之前实验中的净化迭代设置提供了对收敛时扰动持久性的准确评估。
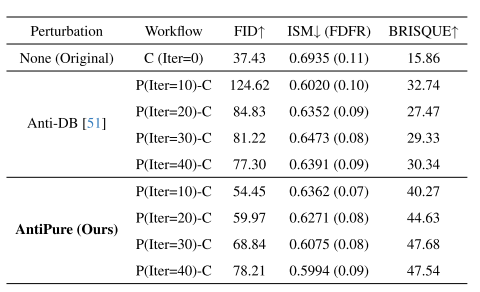
表3.在CelebA-HQ的P-C工作流程之后,不同净化迭代的DreamBooth[38]输出图像质量的比较。
7. Conclusion
在本文中,我们形式化了P-C工作流中的反净化,并提出了AntiPure,它结合了两种类型的附加指导。在典型的P-C设置中,尽管基于扩散的净化具有强大的去噪能力,但AntiPure仍然有效,提高了扰动稳健性,更好地防止了深度假货和侵权行为。然而,作为一种简单的诊断方法,我们当前的设计假定使用白盒访问。因此,我们将AntiPure定位为对不同工作流程中的反定制方法的补充,并将改进的黑盒传输作为未来工作的方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)