【大模型应用开发 8.LangGraph从入门到实战·下】
os: 是 Python 标准库的内置模块,无需额外安装,导入即可使用(代码中就是导入该模块)。它封装了不同操作系统(Windows、Linux、macOS 等)的底层接口,让开发者可以用统一的代码实现跨平台的系统操作,无需针对不同系统编写不同逻辑。typing:Python 标准库模块,提供类型提示工具,用于指定变量、函数参数 / 返回值的类型,支持静态类型检查(如 IDE 提示、mypy 校验
目录
如果足够勇敢,应该继续扛起问题往前走,直到因果成熟自动脱落,人对问题的解决方式,不是试图找到答案,而是背负到可以解决的那一天。
—— 25.10.19
代码实操·下
1.SimpleBot
os:os 是 Python 标准库的内置模块,无需额外安装,导入即可使用(代码中 import os 就是导入该模块)。它封装了不同操作系统(Windows、Linux、macOS 等)的底层接口,让开发者可以用统一的代码实现跨平台的系统操作,无需针对不同系统编写不同逻辑。
typing:Python 标准库模块,提供类型提示工具,用于指定变量、函数参数 / 返回值的类型,支持静态类型检查(如 IDE 提示、mypy 校验),增强代码可读性和健壮性。
TypedDict:typing模块中的类型工具,用于定义结构化字典类型,明确指定字典中每个键对应的 value 类型。例如代码中通过它约束AgentState必须包含message: str字段,确保字典结构可预期。
List:在 Python 的 typing 模块中,List 是用于类型提示的泛型工具,用于明确指定 “列表(list)中元素的类型”。
langgraph.graph:LangGraph 框架的核心模块,包含构建状态化工作流的关键类(如StateGraph),用于定义节点(Nodes)、边(Edges)、状态(State)及流转逻辑,是搭建智能体工作流的基础。
langchain_core: LangChain 的核心模块,包含了构建 LangChain 应用的基础组件和抽象接口。它定义了消息处理、提示模板、链(Chain)、工具调用等核心功能的底层逻辑,是整个框架的 "骨架"。几乎所有 LangChain 的高级功能都依赖于langchain_core提供的基础定义。
langchain_core.messages.HumanMessage:HumanMessage 是 langchain_core.messages 模块中定义的人类用户消息类型,用于在对话流程中明确标记 "来自用户的输入"。
langchain_openai:LangChain 专门用于集成 OpenAI 服务的模块,封装了 OpenAI 的 API 调用逻辑(如聊天模型、嵌入模型、函数调用等),让开发者可以在 LangChain 框架中便捷地使用 OpenAI 的模型(如 GPT-3.5、GPT-4 等)。
ChatOpenAI:langchain_openai 模块中定义的OpenAI 聊天模型类,用于实例化 OpenAI 的对话模型(如gpt-3.5-turbo、gpt-4),是连接 LangChain 与 OpenAI 聊天接口的核心组件。
StateGraph:LangGraph 框架的核心类,用于定义和构建基于状态的工作流图(Stateful Workflow Graph)。它是组织节点(Nodes)、状态(State)和流转规则(Edges)的 “脚手架”,能够将分散的处理逻辑(节点)串联成一个可执行的、状态可控的完整流程。
START:LangGraph 内置的常量,用于标识 “工作流的第一个执行节点” 的逻辑起点(是框架层面的 “流程入口符号”,而非用户自定义的变量)。
END:LangGraph 内置的常量,用于标识 “工作流的最终停止位置” 的逻辑终点(是框架层面的 “流程出口符号”,而非用户自定义的变量)。
os.getenv():Python os 模块的核心函数,用于安全读取操作系统的环境变量值,核心价值是避免将敏感信息(如 API 密钥)硬编码到代码中,同时支持不同环境(开发 / 测试 / 生产)灵活切换配置。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
key |
str |
无 | 必填参数,要读取的环境变量名称(如你代码中的 "DASHSCOPE_API_KEY")。 |
default |
任意类型 | None |
可选参数,当 key 对应的环境变量不存在时,返回的默认值(可设为字符串、数字等)。 |
messages:List[HumanMessage](人类消息列表,定义在AgentState中),存储对话流程中的 “用户消息” 集合。
qw_model:ChatOpenAI实例,配置好的 “通义千问” 大模型客户端。
ChatOpenAI():初始化 OpenAI 聊天模型(如 GPT-3.5、GPT-4)的实例,用于调用 OpenAI 的对话 API。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model_name |
str | "gpt-3.5-turbo" |
模型名称(如"gpt-4"、"gpt-3.5-turbo-1106") |
temperature |
float | 0.7 | 输出随机性(0-1,0 为确定性输出,1 为最大随机性) |
api_key |
str | None |
OpenAI API 密钥(默认从环境变量OPENAI_API_KEY读取) |
base_url |
str | None |
API 基础地址(默认"https://api.openai.com/v1",可用于代理或自定义服务) |
max_tokens |
int | None |
生成内容的最大 token 数(默认由模型限制决定) |
timeout |
int | None |
API 调用超时时间(秒) |
streaming |
bool | False |
是否启用流式输出(实时返回部分结果) |
default_headers |
dict | None |
额外的 HTTP 请求头 |
response:模型返回的消息对象,AI 模型对用户消息的回复结果。
state:state 是 AgentState 类型的实例(AgentState 是一个 TypedDict,定义了状态的结构)。
state["messages"]:List[HumanMessage](人类消息列表)。存储当前对话状态中的 “用户输入消息集合”,是连接用户输入与模型处理的核心数据载体。
.invoke():执行一次调用,传入输入并返回处理结果(同步方法)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
多样(如list[Message]、str、dict) |
无 | 输入内容(聊天模型通常接受消息列表,如[HumanMessage(...)]) |
config |
dict | None |
调用配置(如{"tags": ["tag1"]}用于日志标记,"max_concurrency"控制并发) |
**kwargs |
多样 | 无 | 额外参数(如部分模型支持stop列表,指定终止生成的字符串) |
graph:StateGraph实例,定义工作流的 “状态图” 对象。
StateGraph():创建一个状态图(有向图),用于定义多步骤工作流(如对话流程、工具调用逻辑),支持节点状态流转。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | None |
状态图的名称(用于标识和日志) |
.add_node():向状态图中添加一个节点(节点对应一个处理函数,负责处理当前状态并返回新状态)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 无 | 节点唯一名称(用于标识节点) |
func |
Callable | 无 | 节点处理函数(输入为当前状态state,返回更新后的状态或流转指令) |
.add_edge():定义节点之间的边(流转关系),指定从一个节点到另一个节点的跳转规则。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start_node |
str | 无 | 起始节点名称(边的起点) |
end_node |
str 或 Callable | 无 | 目标节点名称(边的终点);若为函数,则根据当前状态动态返回目标节点 |
agent:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.compile():编译状态图,生成可执行的Runnable对象(用于运行工作流)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
config |
dict | None |
编译配置(如{"verbose": True}开启详细日志) |
Ipython:IPython 是一个增强的交互式 Python 环境(Interactive Python 的缩写),它在标准 Python 解释器的基础上增加了许多功能,比如:
- 支持语法高亮、自动补全、命令历史记录;
- 可以直接运行 shell 命令(如
!ls); - 支持交互式可视化(如图表、图像显示);
- 提供 “魔法命令”(如
%run、%matplotlib)简化工作流。
它是 Jupyter Notebook/Lab 的核心依赖,广泛用于数据分析、机器学习等交互式开发场景。
Ipython.display:是 IPython 内置的一个模块,专门用于在交互式环境(如 Jupyter Notebook)中显示各种类型的内容,包括但不限于:
- 文本、HTML、Markdown;
- 图像(PNG、JPG 等);
- 音频、视频;
- 复杂对象(如 Pandas DataFrame、Matplotlib 图表)。
它提供了一系列工具函数和类,让开发者可以方便地在交互式界面中展示多样化的输出。
Image:IPython.display 模块中的一个类,用于创建 “可显示的图像对象”,主要作用是:
- 加载图像资源(支持本地文件路径、网络 URL、二进制图像数据);
- 配置图像的显示参数(如宽度、高度、格式);
- 配合
display函数在 Jupyter 等环境中直接显示图像。
display:IPython.display 模块中的一个函数,用于在交互式环境中显示对象。它的核心作用是:
- 接收各种类型的对象(如
Image对象、字符串、HTML 片段、Pandas 表格等); - 根据对象类型自动选择合适的方式渲染并展示(例如,对
Image对象会显示图片,对 HTML 字符串会解析为网页元素)。
display():在交互式环境(如 Jupyter Notebook)中显示对象(图像、HTML、文本等)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
obj |
多样(如Image、str、HTML) |
无 | 要显示的对象 |
** kwargs |
多样 | 无 | 额外显示参数(如clear=True清除之前的输出) |
Image():创建图像对象(IPython 中用于显示图像,PIL 中用于图像处理)。
| 参数名(IPython.display.Image) | 类型 | 默认值 | 描述 |
|---|---|---|---|
data |
bytes | None |
图像二进制数据 |
filename |
str | None |
图像文件路径(优先于data) |
format |
str | None |
图像格式(如"png"、"jpg",自动从文件推断) |
width |
int | None |
显示宽度(像素) |
height |
int | None |
显示高度(像素) |
.get_graph():获取状态图的内部结构(通常为Graph对象,包含节点和边的元数据)。
.draw_mermaid_png():将图结构转换为 Mermaid 语法,并生成 PNG 图像(需安装mermaid-cli)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str | None |
图像保存路径(如"graph.png",不指定则返回二进制数据) |
** kwargs |
多样 | 无 | Mermaid 绘图参数(如"theme": "dark"设置主题) |
import os
from typing import TypedDict, List
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
# from dotenv import load_dotenv
class AgentState(TypedDict):
"""Agent state."""
messages: List[HumanMessage]
# qwen模型
qw_model = ChatOpenAI(
model="qwen-max", # 通义千问
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
def process(state: AgentState)-> AgentState:
'''
Process the agent state
:param state:
:return:
'''
response = qw_model.invoke(state["messages"])
print(f"\nAI: {response.content}")
return state
graph = StateGraph(AgentState)
graph.add_node("process", process)
graph.add_edge(START, "process")
graph.add_edge("process", END)
agent = graph.compile()
# Optional: Display the graph (requires IPython)
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))
user_input:str(字符串),存储用户输入的文本内容,是对话的 “用户输入源”。
input():Python 内置函数,核心作用是从标准输入(通常是键盘)获取用户输入,并将输入内容以字符串形式返回。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
prompt |
str |
None |
可选参数,用于显示给用户的提示文本。若提供该参数,会先在控制台打印提示文本,再等待用户输入;若不提供,则直接等待用户输入(无提示)。 |
user_input = input("User:")
while user_input != "exit":
state = agent.invoke({"messages": [HumanMessage(content=user_input)]})
user_input = input("User:")用户输入:
1.hello
2.introduce yourself
2.MemoryBot
os:os 是 Python 标准库的内置模块,无需额外安装,导入即可使用(代码中 import os 就是导入该模块)。它封装了不同操作系统(Windows、Linux、macOS 等)的底层接口,让开发者可以用统一的代码实现跨平台的系统操作,无需针对不同系统编写不同逻辑。
typing:Python 标准库模块,提供类型提示工具,用于指定变量、函数参数 / 返回值的类型,支持静态类型检查(如 IDE 提示、mypy 校验),增强代码可读性和健壮性。
TypedDict:typing模块中的类型工具,用于定义结构化字典类型,明确指定字典中每个键对应的 value 类型。例如代码中通过它约束AgentState必须包含message: str字段,确保字典结构可预期。
List:在 Python 的 typing 模块中,List 是用于类型提示的泛型工具,用于明确指定 “列表(list)中元素的类型”。
Union:Python 标准库 typing 模块中的类型提示工具,用于明确标注 “某个变量 / 参数 / 返回值可以是多个指定类型中的任意一种”,核心作用是提升代码的可读性和类型检查的准确性(尤其在大型项目或多人协作中)。
langgraph.graph:LangGraph 框架的核心模块,包含构建状态化工作流的关键类(如StateGraph),用于定义节点(Nodes)、边(Edges)、状态(State)及流转逻辑,是搭建智能体工作流的基础。
langchain_core: LangChain 的核心模块,包含了构建 LangChain 应用的基础组件和抽象接口。它定义了消息处理、提示模板、链(Chain)、工具调用等核心功能的底层逻辑,是整个框架的 "骨架"。几乎所有 LangChain 的高级功能都依赖于langchain_core提供的基础定义。
langchain_core.messages.AIMessage:LangChain 核心模块 langchain_core.messages 中定义的AI 消息类型类,用于在对话流程中明确标记 “由 AI 模型生成的回复内容”,是对话状态管理的核心载体之一(与你之前了解的 HumanMessage 对应:HumanMessage 是用户输入,AIMessage 是 AI 输出)。
langchain_core.messages.HumanMessage:HumanMessage 是 langchain_core.messages 模块中定义的人类用户消息类型,用于在对话流程中明确标记 "来自用户的输入"。
| 属性名 | 类型 | 描述 |
|---|---|---|
content |
str |
AI 回复的核心文本内容(最常用属性,如 ai_msg.content 即可获取回复文本)。 |
additional_kwargs |
dict |
额外元数据(如模型名称、生成时间戳、token 消耗等,可选)。 |
tool_calls |
List[ToolCall] |
AI 触发的工具调用信息(若 AI 需要调用工具,会在此处存储工具名称、参数等,如调用搜索工具时的关键词)。 |
id |
str |
消息唯一标识(自动生成,用于区分不同消息)。 |
langchain_openai:LangChain 专门用于集成 OpenAI 服务的模块,封装了 OpenAI 的 API 调用逻辑(如聊天模型、嵌入模型、函数调用等),让开发者可以在 LangChain 框架中便捷地使用 OpenAI 的模型(如 GPT-3.5、GPT-4 等)。
ChatOpenAI:langchain_openai 模块中定义的OpenAI 聊天模型类,用于实例化 OpenAI 的对话模型(如gpt-3.5-turbo、gpt-4),是连接 LangChain 与 OpenAI 聊天接口的核心组件。
StateGraph:LangGraph 框架的核心类,用于定义和构建基于状态的工作流图(Stateful Workflow Graph)。它是组织节点(Nodes)、状态(State)和流转规则(Edges)的 “脚手架”,能够将分散的处理逻辑(节点)串联成一个可执行的、状态可控的完整流程。
START:LangGraph 内置的常量,用于标识 “工作流的第一个执行节点” 的逻辑起点(是框架层面的 “流程入口符号”,而非用户自定义的变量)。
END:LangGraph 内置的常量,用于标识 “工作流的最终停止位置” 的逻辑终点(是框架层面的 “流程出口符号”,而非用户自定义的变量)。
messages:List[HumanMessage](人类消息列表,定义在AgentState中),存储对话流程中的 “用户消息” 集合。
messages_AI:专门用于存储 AI 模型生成的回复消息集合,是对话状态中 “AI 输出” 的独立载体,与 “用户输入”(HumanMessage)形成明确区分。
| 字段名 | 存储内容 | 优势 | 适用场景 |
|---|---|---|---|
messages |
用户消息(HumanMessage)+ AI 消息(AIMessage) |
无需拆分,直接作为 “对话历史” 传给模型 | 多轮对话中需让模型基于完整历史上下文生成回复 |
messages_AI |
仅 AI 消息(AIMessage) |
单独管理 AI 输出,无需筛选即可获取历史回复 | 需要单独统计、回溯或复用 AI 回复的场景(如生成总结) |
response:模型返回的消息对象,AI 模型对用户消息的回复结果。
qw_model:ChatOpenAI实例,配置好的 “通义千问” 大模型客户端。
.invoke():执行一次调用,传入输入并返回处理结果(同步方法)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
多样(如list[Message]、str、dict) |
无 | 输入内容(聊天模型通常接受消息列表,如[HumanMessage(...)]) |
config |
dict | None |
调用配置(如{"tags": ["tag1"]}用于日志标记,"max_concurrency"控制并发) |
**kwargs |
多样 | 无 | 额外参数(如部分模型支持stop列表,指定终止生成的字符串) |
ChatOpenAI():初始化 OpenAI 聊天模型(如 GPT-3.5、GPT-4)的实例,用于调用 OpenAI 的对话 API。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model_name |
str | "gpt-3.5-turbo" |
模型名称(如"gpt-4"、"gpt-3.5-turbo-1106") |
temperature |
float | 0.7 | 输出随机性(0-1,0 为确定性输出,1 为最大随机性) |
api_key |
str | None |
OpenAI API 密钥(默认从环境变量OPENAI_API_KEY读取) |
base_url |
str | None |
API 基础地址(默认"https://api.openai.com/v1",可用于代理或自定义服务) |
max_tokens |
int | None |
生成内容的最大 token 数(默认由模型限制决定) |
timeout |
int | None |
API 调用超时时间(秒) |
streaming |
bool | False |
是否启用流式输出(实时返回部分结果) |
default_headers |
dict | None |
额外的 HTTP 请求头 |
state:state 是 AgentState 类型的实例(AgentState 是一个 TypedDict,定义了状态的结构)。
state["messages"]:List[HumanMessage](人类消息列表)。存储当前对话状态中的 “用户输入消息集合”,是连接用户输入与模型处理的核心数据载体。
graph:StateGraph实例,定义工作流的 “状态图” 对象。
StateGraph():创建一个状态图(有向图),用于定义多步骤工作流(如对话流程、工具调用逻辑),支持节点状态流转。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | None |
状态图的名称(用于标识和日志) |
.add_node():向状态图中添加一个节点(节点对应一个处理函数,负责处理当前状态并返回新状态)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 无 | 节点唯一名称(用于标识节点) |
func |
Callable | 无 | 节点处理函数(输入为当前状态state,返回更新后的状态或流转指令) |
.add_edge():定义节点之间的边(流转关系),指定从一个节点到另一个节点的跳转规则。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start_node |
str | 无 | 起始节点名称(边的起点) |
end_node |
str 或 Callable | 无 | 目标节点名称(边的终点);若为函数,则根据当前状态动态返回目标节点 |
agent:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.compile():编译状态图,生成可执行的Runnable对象(用于运行工作流)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
config |
dict | None |
编译配置(如{"verbose": True}开启详细日志) |
Ipython:IPython 是一个增强的交互式 Python 环境(Interactive Python 的缩写),它在标准 Python 解释器的基础上增加了许多功能,比如:
- 支持语法高亮、自动补全、命令历史记录;
- 可以直接运行 shell 命令(如
!ls); - 支持交互式可视化(如图表、图像显示);
- 提供 “魔法命令”(如
%run、%matplotlib)简化工作流。
它是 Jupyter Notebook/Lab 的核心依赖,广泛用于数据分析、机器学习等交互式开发场景。
Ipython.display:是 IPython 内置的一个模块,专门用于在交互式环境(如 Jupyter Notebook)中显示各种类型的内容,包括但不限于:
- 文本、HTML、Markdown;
- 图像(PNG、JPG 等);
- 音频、视频;
- 复杂对象(如 Pandas DataFrame、Matplotlib 图表)。
它提供了一系列工具函数和类,让开发者可以方便地在交互式界面中展示多样化的输出。
Image:IPython.display 模块中的一个类,用于创建 “可显示的图像对象”,主要作用是:
- 加载图像资源(支持本地文件路径、网络 URL、二进制图像数据);
- 配置图像的显示参数(如宽度、高度、格式);
- 配合
display函数在 Jupyter 等环境中直接显示图像。
display:IPython.display 模块中的一个函数,用于在交互式环境中显示对象。它的核心作用是:
- 接收各种类型的对象(如
Image对象、字符串、HTML 片段、Pandas 表格等); - 根据对象类型自动选择合适的方式渲染并展示(例如,对
Image对象会显示图片,对 HTML 字符串会解析为网页元素)。
display():在交互式环境(如 Jupyter Notebook)中显示对象(图像、HTML、文本等)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
obj |
多样(如Image、str、HTML) |
无 | 要显示的对象 |
** kwargs |
多样 | 无 | 额外显示参数(如clear=True清除之前的输出) |
Image():创建图像对象(IPython 中用于显示图像,PIL 中用于图像处理)。
| 参数名(IPython.display.Image) | 类型 | 默认值 | 描述 |
|---|---|---|---|
data |
bytes | None |
图像二进制数据 |
filename |
str | None |
图像文件路径(优先于data) |
format |
str | None |
图像格式(如"png"、"jpg",自动从文件推断) |
width |
int | None |
显示宽度(像素) |
height |
int | None |
显示高度(像素) |
.get_graph():获取状态图的内部结构(通常为Graph对象,包含节点和边的元数据)。
.draw_mermaid_png():将图结构转换为 Mermaid 语法,并生成 PNG 图像(需安装mermaid-cli)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str | None |
图像保存路径(如"graph.png",不指定则返回二进制数据) |
** kwargs |
多样 | 无 | Mermaid 绘图参数(如"theme": "dark"设置主题) |
import os
from typing import TypedDict, List, Union
from langchain_core.messages import HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
# from dotenv import load_dotenv
class AgentState(TypedDict):
"""
Agent state.
HumanMessage、AIMessage是langchain_core.messages中的类,是一种内置的数据类型
"""
messages: List[Union[HumanMessage, AIMessage]]
'''
messages: List[HumanMessage]
messages_AI: List[AIMessage]
'''
# qwen模型
qw_model = ChatOpenAI(
model="qwen-max", # 通义千问
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
def process(state: AgentState) -> AgentState:
'''
This node will solve the request you input.
:param state:
:return:
'''
response = qw_model.invoke(state["messages"])
state["messages"].append(AIMessage(content=response.content))
print(f"\nAI: {response.content}")
print("Current State:", state["messages"])
return state
graph = StateGraph(AgentState)
graph.add_node("process", process)
graph.add_edge(START, "process")
graph.add_edge("process", END)
agent = graph.compile()
# Optional: Display the graph (requires IPython)
from IPython.display import Image, display
display(Image(agent.get_graph().draw_mermaid_png()))
conversation_history:List[Union[HumanMessage, AIMessage]],全程维护对话的完整历史记录,是连接 “用户输入→AI 处理→历史回溯” 的核心数据载体。
user_input:str(字符串),存储用户输入的文本内容,是对话的 “用户输入源”。
input():Python 内置函数,核心作用是从标准输入(通常是键盘)获取用户输入,并将输入内容以字符串形式返回。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
prompt |
str |
None |
可选参数,用于显示给用户的提示文本。若提供该参数,会先在控制台打印 |
.append():在列表的末尾添加一个元素,直接修改原列表(无返回值),常用于动态扩展列表内容(如你代码中向 conversation_history 添加用户消息)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object |
任意类型 | 是 | 要添加到列表末尾的元素(可以是字符串、数字、对象等,如你代码中的 HumanMessage 对象)。 |
agent:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
result["messages"]:List[Union[HumanMessage, AIMessage]],传递 AI 处理后的 “完整消息集合”,是 conversation_history 更新的 “数据源”。
open():打开一个文件,并返回文件对象(file object),是文件读写操作的 “入口”(如你代码中打开 conversation_history.txt 保存对话日志)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
file |
str |
无 | 是 | 要打开的文件路径(可以是绝对路径,如 C:/logs.txt;或相对路径,如 ./history.txt)。 |
mode |
str |
'r' |
否 | 打开模式(决定文件可执行的操作):- 'r':只读(默认);- 'w':写入(覆盖原内容);- 'a':追加(在原内容后添加);- 'r+':读写;带 b 表示二进制模式(如 'wb' 二进制写入)。 |
encoding |
str |
None |
否 | 文本文件的编码格式(如 'utf-8'、'gbk',你的代码中用 'utf-8' 确保中文正常写入)。 |
errors |
str |
None |
否 | 编码错误处理方式(如 'strict' 严格报错、'ignore' 忽略错误)。 |
buffering |
int |
-1 |
否 | 缓冲策略(-1 表示使用默认缓冲,0 表示无缓冲,正数表示缓冲区大小)。 |
.write():向打开的文件中写入字符串内容,返回写入的字符数(仅文本模式有效;二进制模式下需传入字节流,且方法为 .write(bytes))。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
string |
str |
是 | 要写入文件的字符串(文本模式);若为二进制模式,需传入 bytes 类型数据。 |
isinstance():检查一个对象是否是指定类(或元组中的任意类)的实例,返回布尔值(True/False),常用于类型判断(如你代码中区分 HumanMessage 和 AIMessage)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object |
任意对象 | 是 | 需要检查类型的对象(如你代码中的 message)。 |
classinfo |
类 / 类的元组 | 是 | 用于判断的类(如 HumanMessage),或多个类组成的元组(如 (HumanMessage, AIMessage),只要对象是其中任一类的实例,就返回 True)。 |
conversation_history = []
user_input = input("User: ")
while user_input != "exit":
conversation_history.append(HumanMessage(content=user_input))
result = agent.invoke({"messages":conversation_history})
print(result["messages"])
conversation_history = result["messages"]
user_input = input("User: ")
with open("conversation_history.txt", "w", encoding="utf-8") as f:
f.write("Your Conversation Log:\n")
for message in conversation_history:
if isinstance(message, HumanMessage):
f.write(f"User: {message.content}\n")
elif isinstance(message, AIMessage):
f.write(f"AI: {message.content}\n")
f.write("End of Conversation Log.")
print("Conversation history saved to conversation_history.txt")用户输入:
what day is today?
how are you?
please introduce yourself

3.ReActAgent
typing:提供类型提示(Type Hints) 相关的工具,用于在代码中标注变量、函数参数、返回值的类型,提升代码可读性和静态类型检查能力(如配合 mypy 工具)。
Annotated:为类型添加元数据(metadata),格式为 Annotated[type, metadata],其中 type 是基础类型,metadata 是附加信息(可多个)。在保留类型提示的同时,传递额外信息(如校验规则、描述等),常见于数据验证、框架配置等场景。
Sequence:标注 “序列类型”(如列表 list、元组 tuple、字符串 str 等可迭代且有序的对象),等价于 “任何实现了 collections.abc.Sequence 接口的类型”。相比具体类型(如 list),Sequence 更抽象,允许传入多种序列类型,提升代码灵活性。
TypedDict:类型提示工具,定义具有固定键和值类型的字典,明确指定字典中每个键对应的 value 类型,类似 “结构化字典”。在需要严格约束字典结构的场景(如状态管理、API 参数)中使用,替代普通 dict 以提升类型安全性。
os:提供与操作系统交互的接口,实现跨平台的系统级操作(如文件路径处理、环境变量读取、进程管理等)。
langchain_core:提供 LangChain 应用的基础组件和抽象接口,是整个框架的 “骨架”,包含消息处理、提示模板、工具调用、链(Chain)等核心功能的底层定义。
langchain_core.messages:定义对话中各类消息的数据结构和基类,统一消息格式,支持多轮对话的上下文管理。
langchain_core.messages.HumanMessage:封装人类用户的输入消息,明确标记 “来自用户的内容”,是对话流程中 “用户侧” 消息的载体。
langchain_core.messages.AIMessage:封装AI 模型生成的回复消息,明确标记 “来自 AI 的内容”,是对话流程中 “AI 侧” 消息的载体。
langchain_core.messages.BaseMessage:所有消息类型(HumanMessage、AIMessage 等)的抽象父类,定义了消息的通用属性(如 content、id)和方法,确保消息类型的一致性。
langchain_core.messages.ToolMessage:封装工具调用的返回结果(如调用搜索引擎、数据库后的响应),用于将工具输出传递给 AI 模型,作为生成回复的依据。
langchain_core.messages.SystemMessage:封装系统提示消息(如 AI 的角色定义、行为规则),用于指导 AI 的回复风格或逻辑(优先级通常高于用户消息)。
langchain_openai:封装 OpenAI 及兼容 OpenAI API 的模型(如通义千问、智谱 AI 等)的调用逻辑,提供统一接口用于调用聊天模型、嵌入模型等。
ChatOpenAI:实例化 OpenAI 风格的聊天模型(如 gpt-3.5-turbo、通义千问 qwen-max),提供 invoke 等方法调用模型生成回复。
langgraph:用于构建多步骤工作流或智能体(Agent),通过 “状态图(有向图)” 定义节点(处理逻辑)和边(流转规则),支持复杂流程的可视化和执行。
langgraph.graph:提供构建状态图的基础组件,如状态图类、节点 / 边操作函数、特殊节点(如开始 / 结束)等。
langgraph.graph.StateGraph:创建一个状态图实例,用于定义工作流的结构(节点、边、状态类型),是构建工作流的核心对象。
langgraph.graph.END:表示状态图的结束节点,用于标记工作流的终止点(如 graph.add_edge("final_node", END) 表示流程到 final_node 后结束)。
langgraph.graph.add_messages:用于更新状态中的消息列表(如对话历史),自动将新消息(如用户输入、AI 回复)追加到状态的 messages 字段中,简化状态维护逻辑。
langgraph.prebuilt:提供开箱即用的组件(如工具节点、对话节点),避免重复开发常见功能,加速工作流搭建。
langgraph.prebuilt.ToolNode:封装工具调用的逻辑,作为状态图中的一个节点,负责解析 AI 的 tool_calls 指令、执行对应的工具(如函数、API)、并将结果包装为 ToolMessage 回传给状态。
langchain_core.tools:定义工具的抽象接口和基础结构,规范 “可被 AI 调用的工具”(如函数、API)的格式,确保工具能被 LangChain 组件识别和调用。
langchain_core.tools.tool:将普通 Python 函数标记为 **“可被 AI 调用的工具”**,自动生成工具的元数据(如名称、描述、参数类型),供 AI 模型判断何时及如何调用该工具。
messages:messages 是 AgentState(基于 TypedDict 定义的 “智能体状态结构”)中的核心状态字段,是整个对话与工具调用流程的 “数据载体”。
@tool:langchain_core.tools 模块提供的装饰器(Python 装饰器语法,用 @ 标识,作用于函数)。将普通 Python 函数 “改造” 为AI 可识别、可调用的工具—— 无需手动编写工具元数据(如 “工具叫什么、能做什么、需要哪些参数”),装饰器会自动提取函数信息生成标准格式的工具描述。
tools:一个工具列表,存储了所有被 @tool 装饰后、可供 AI 调用的工具函数。
qw_model:配置完成的通义千问模型客户端,由 ChatOpenAI 类初始化并绑定工具后生成,具备 “自然语言对话 + 工具调用” 的双重能力。
ChatOpenAI():初始化 OpenAI 聊天模型(如 GPT-3.5、GPT-4)的实例,用于调用 OpenAI 的对话 API。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model_name |
str | "gpt-3.5-turbo" |
模型名称(如"gpt-4"、"gpt-3.5-turbo-1106") |
temperature |
float | 0.7 | 输出随机性(0-1,0 为确定性输出,1 为最大随机性) |
api_key |
str | None |
OpenAI API 密钥(默认从环境变量OPENAI_API_KEY读取) |
base_url |
str | None |
API 基础地址(默认"https://api.openai.com/v1",可用于代理或自定义服务) |
max_tokens |
int | None |
生成内容的最大 token 数(默认由模型限制决定) |
timeout |
int | None |
API 调用超时时间(秒) |
streaming |
bool | False |
是否启用流式输出(实时返回部分结果) |
default_headers |
dict | None |
额外的 HTTP 请求头 |
ChatOpenAI().bind_tools():为 AI 模型绑定可调用的工具列表,让模型知道 “可以使用哪些工具”,并在生成回复时自动判断是否需要调用工具(如调用函数、API 等),生成符合格式的工具调用指令(用于后续执行工具)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
tools |
List[BaseTool] 或 List[dict] |
无 | 必需参数,要绑定的工具列表。- 可以是 langchain_core.tools.BaseTool 的实例(如通过 @tool 装饰器定义的工具);- 也可以是工具元数据字典(包含 name、description、parameters 等字段)。 |
tool_choice |
str 或 dict 或 None |
"auto" |
控制模型是否 / 如何选择工具:- "auto":模型自主决定是否调用工具;- "none":不允许调用工具(仅生成自然语言回复);- 工具名称(如 "calculate"):强制调用指定工具;- 字典(如 {"type": "function", "function": {"name": "calculate"}}):更精细的强制调用配置。 |
**kwargs |
任意 | 无 | 其他传递给模型的参数(如 temperature 等,但通常在初始化 ChatOpenAI 时设置)。 |
system_prompt:是 model_call 函数中定义的系统提示消息,由 SystemMessage 类创建,是指导 AI 行为的 “底层规则”。
SystemMessage():定义系统提示消息,用于向 AI 模型传递 “角色设定、行为规则、背景信息” 等底层指令,指导模型的回复风格、逻辑或功能边界(优先级通常高于用户消息)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
content |
str |
无 | 必需参数,系统提示的文本内容(核心指令,如角色定义、规则说明)。 |
additional_kwargs |
dict |
{} |
可选参数,附加元数据(如消息 ID、时间戳等,通常无需手动设置)。 |
response_metadata |
dict |
{} |
可选参数,模型返回的元数据(如生成时间、token 数,一般由模型自动填充)。 |
.invoke():执行一次调用,传入输入并返回处理结果(同步方法)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
多样(如list[Message]、str、dict) |
无 | 输入内容(聊天模型通常接受消息列表,如[HumanMessage(...)]) |
config |
dict | None |
调用配置(如{"tags": ["tag1"]}用于日志标记,"max_concurrency"控制并发) |
**kwargs |
多样 | 无 | 额外参数(如部分模型支持stop列表,指定终止生成的字符串) |
state:state 是 AgentState 类型的实例(AgentState 是一个 TypedDict,定义了状态的结构)。
state["messages"]:List[HumanMessage](人类消息列表)。存储当前对话状态中的 “用户输入消息集合”,是连接用户输入与模型处理的核心数据载体。
last_message:列表的最后一个元素,即 “当前对话流程中最新产生的消息”,作为 “流程判断的数据源”:should_continue 函数的核心逻辑是 “基于最新消息的内容,决定下一步做什么”,而 last_message 就是这个 “最新消息” 的载体。
last_message.tool_calls:tool_calls 是 AIMessage 类(AI 回复消息)的专属属性(HumanMessage、ToolMessage 等其他消息类型无此属性),用于存储 “AI 模型生成的工具调用指令”。
response:模型返回的消息对象,AI 模型对用户消息的回复结果。
graph:StateGraph实例,定义工作流的 “状态图” 对象。
StateGraph():创建一个状态图(有向图),用于定义多步骤工作流(如对话流程、工具调用逻辑),支持节点状态流转。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | None |
状态图的名称(用于标识和日志) |
.add_node():向状态图中添加一个节点(节点对应一个处理函数,负责处理当前状态并返回新状态)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 无 | 节点唯一名称(用于标识节点) |
func |
Callable | 无 | 节点处理函数(输入为当前状态state,返回更新后的状态或流转指令) |
.add_edge():定义节点之间的边(流转关系),指定从一个节点到另一个节点的跳转规则。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start_node |
str | 无 | 起始节点名称(边的起点) |
end_node |
str 或 Callable | 无 | 目标节点名称(边的终点);若为函数,则根据当前状态动态返回目标节点 |
app:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.add_conditional_edges():langgraph.graph.StateGraph 类的核心方法,用于在状态图中添加 “条件分支边”—— 即根据动态条件(如当前状态、AI 决策结果)自动决定从一个节点跳转到哪个目标节点,实现工作流的灵活分支逻辑(类似编程中的 if-else 判断)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
start_node |
str |
是 | 起始节点的名称(边的起点,如你的代码中的 "our_agent",即 “AI 模型调用节点”)。 |
condition |
Callable |
是 | 条件判断函数,接收当前状态(state)作为输入,返回一个分支标识(如字符串 "continue" 或 "end"),用于决定跳转方向。在你的代码中,should_continue 就是这个函数:检查最新消息是否有工具调用指令,返回 "continue"(需调用工具)或 "end"(无需调用)。 |
destinations |
dict |
是 | 分支标识与目标节点的映射字典,格式为 {分支标识: 目标节点名称或特殊节点(如END)}。在你的代码中,{"continue": "tools", "end": END} 表示:若 condition 返回 "continue",则跳转到 "tools" 节点(执行工具);若返回 "end",则跳转到 END(流程结束)。 |
.compile():编译状态图,生成可执行的Runnable对象(用于运行工作流)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
config |
dict | None |
编译配置(如{"verbose": True}开启详细日志) |
Ipython:IPython 是一个增强的交互式 Python 环境(Interactive Python 的缩写),它在标准 Python 解释器的基础上增加了许多功能,比如:
- 支持语法高亮、自动补全、命令历史记录;
- 可以直接运行 shell 命令(如
!ls); - 支持交互式可视化(如图表、图像显示);
- 提供 “魔法命令”(如
%run、%matplotlib)简化工作流。
它是 Jupyter Notebook/Lab 的核心依赖,广泛用于数据分析、机器学习等交互式开发场景。
Ipython.display:是 IPython 内置的一个模块,专门用于在交互式环境(如 Jupyter Notebook)中显示各种类型的内容,包括但不限于:
- 文本、HTML、Markdown;
- 图像(PNG、JPG 等);
- 音频、视频;
- 复杂对象(如 Pandas DataFrame、Matplotlib 图表)。
它提供了一系列工具函数和类,让开发者可以方便地在交互式界面中展示多样化的输出。
Image:IPython.display 模块中的一个类,用于创建 “可显示的图像对象”,主要作用是:
- 加载图像资源(支持本地文件路径、网络 URL、二进制图像数据);
- 配置图像的显示参数(如宽度、高度、格式);
- 配合
display函数在 Jupyter 等环境中直接显示图像。
display:IPython.display 模块中的一个函数,用于在交互式环境中显示对象。它的核心作用是:
- 接收各种类型的对象(如
Image对象、字符串、HTML 片段、Pandas 表格等); - 根据对象类型自动选择合适的方式渲染并展示(例如,对
Image对象会显示图片,对 HTML 字符串会解析为网页元素)。
display():在交互式环境(如 Jupyter Notebook)中显示对象(图像、HTML、文本等)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
obj |
多样(如Image、str、HTML) |
无 | 要显示的对象 |
** kwargs |
多样 | 无 | 额外显示参数(如clear=True清除之前的输出) |
Image():创建图像对象(IPython 中用于显示图像,PIL 中用于图像处理)。
| 参数名(IPython.display.Image) | 类型 | 默认值 | 描述 |
|---|---|---|---|
data |
bytes | None |
图像二进制数据 |
filename |
str | None |
图像文件路径(优先于data) |
format |
str | None |
图像格式(如"png"、"jpg",自动从文件推断) |
width |
int | None |
显示宽度(像素) |
height |
int | None |
显示高度(像素) |
.get_graph():获取状态图的内部结构(通常为Graph对象,包含节点和边的元数据)。
.draw_mermaid_png():将图结构转换为 Mermaid 语法,并生成 PNG 图像(需安装mermaid-cli)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str | None |
图像保存路径(如"graph.png",不指定则返回二进制数据) |
** kwargs |
多样 | 无 | Mermaid 绘图参数(如"theme": "dark"设置主题) |
from typing import Annotated, Sequence, TypedDict
import os
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage, ToolMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END, add_messages
from langgraph.prebuilt import ToolNode
from langchain_core.tools import tool
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
@tool
def add(a: int, b: int):
'''
This is an addition function that adds two numbers together.
:param a:
:param b:
:return:
'''
return a + b
@tool
def subtract(a: int, b: int):
'''
This is an addition function that adds two numbers together.
:param a:
:param b:
:return:
'''
return a - b
@tool
def multiply(a: int, b: int):
'''
This is an addition function that adds two numbers together.
:param a:
:param b:
:return:
'''
return a * b
@tool
def divide(a: int, b: int):
'''
This is an addition function that adds two numbers together.
:param a:
:param b:
:return:
'''
if b == 0:
return "Error: Division by zero"
return a / b
tools = [add, subtract, multiply, divide]
# qwen模型
qw_model = ChatOpenAI(
model="qwen-max", # 通义千问
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
).bind_tools(tools)
def model_call(state: AgentState) -> AgentState:
system_prompt = SystemMessage(content=
"You are my AI assistant, please answer my query to the best of your ability."
)
response = qw_model.invoke([system_prompt] + state["messages"])
# state["messages"]。append(...)
# return state
return {"messages": [response]}
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
graph = StateGraph(AgentState)
graph.add_node("our_agent", model_call)
tool_node = ToolNode(tools=tools)
graph.add_node("tools", tool_node)
graph.set_entry_point("our_agent")
graph.add_conditional_edges(
"our_agent",
should_continue,
{
"continue": "tools",
"end": END
}
)
graph.add_edge("tools", "our_agent")
app = graph.compile()
# Optional: Display the graph (requires IPython)
from IPython.display import Image, display
display(Image(app.get_graph().draw_mermaid_png()))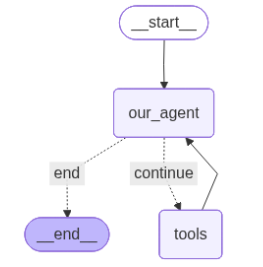
stream:print_stream 函数的参数,实际传入的值是 app.stream(inputs, stream_mode="values") 的返回结果。
- 其中
app是StateGraph编译后的可执行对象(Runnable),其.stream()方法用于以流式方式获取智能体的处理结果; stream_mode="values"是.stream()的参数,指定返回 “纯状态数据”(而非包含元数据的完整对象),让结果更简洁。
message:存储 “智能体当前步骤的关键交互信息”:
元组 tuple:仅在初始输入阶段,对应 inputs 中 ("user", "内容") 的简化格式(LangGraph 会自动将其转换为 HumanMessage,但流式初始步骤可能暂存为元组);
LangChain 消息对象:后续步骤中,多为 AIMessage(AI 的回复 / 工具调用指令)或 ToolMessage(工具执行结果)。
isinstance():检查一个对象是否是指定类(或元组中任意类)的实例,返回布尔值(True/False),核心用于 “类型安全检查”,避免因类型错误导致代码异常(如你之前代码中区分 HumanMessage 和 AIMessage)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object |
任意对象 | 是 | 需要检查类型的目标对象(如你代码中的 message、last_message)。 |
classinfo |
类 / 类的元组 | 是 | 用于判断的 “类型标准”:- 单个类(如 HumanMessage):检查对象是否是该类的实例;- 类的元组(如 (HumanMessage, AIMessage)):检查对象是否是元组中任意一个类的实例(满足一个即返回 True)。 |
.pretty_print():以格式化、易读的方式打印对象内容,自动处理缩进、换行、类型标识,避免直接打印对象时出现杂乱的内部属性(如 <HumanMessage content='你好' id='xxx'>)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
width |
int |
80 |
否 | 打印内容的最大宽度(超过宽度会自动换行,避免一行过长)。 |
indent |
int |
2 |
否 | 缩进空格数(用于嵌套内容,如元数据的缩进,提升层次感)。 |
**kwargs |
任意 | 无 | 否 | 额外格式化参数(如 color=True 开启彩色打印,部分实现支持该功能)。 |
inputs1:符合 AgentState 结构的初始输入字典—— 是智能体启动时的 “任务指令”,告诉智能体 “需要处理什么需求”。
inputs2:作为第二个测试用例,触发智能体处理 “多步骤计算 + 跨类型任务(计算→写诗)”
app:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.stream():以流式方式获取结果,即 “逐步返回部分结果”(而非等待完整结果生成后一次性返回),常用于大模型生成文本时提升用户体验(如实时显示 AI 回复的每一个字符 / 段落)。与同步调用 .invoke()(等待完整结果)不同,.stream() 返回的是 “生成器(generator)”,需通过循环迭代获取每一块结果。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input |
多样(如 List[BaseMessage]、dict、str) |
无 | 是 | 输入内容,与 .invoke() 的 input 格式一致(如 LLM 调用时传入消息列表,状态图调用时传入初始状态)。 |
config |
dict |
None |
否 | 调用配置,如日志标记({"tags": ["stream-call"]})、超时时间({"timeout": 30})等。 |
**kwargs |
任意 | 无 | 否 | 额外参数,根据所属对象不同可能有差异(如部分模型支持 stop 列表,指定终止生成的字符串)。 |
def print_stream(stream):
for s in stream:
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
inputs1 = {"messages": [("user", "Add 11 + 4, Add 1 + 14, Add 9 + 28")]}
print_stream(app.stream(inputs1, stream_mode = "values"))
inputs2 = {"messages": [("user", "Add 11 + 4 and then subtract 3, "
"Add 1 + 14 and then multiply 2, "
"Add 9 + 28 and then divide 4, "
"divide 5 / 6 and then subtract 1 and then tell me a poem"
)]}
print_stream(app.stream(inputs2, stream_mode = "values"))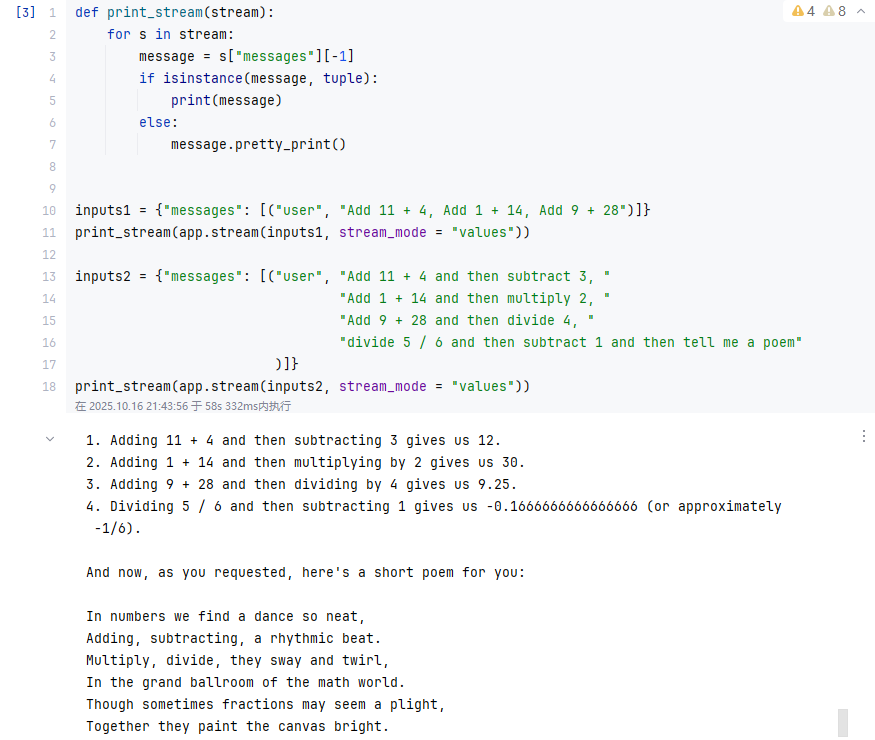
4.AssistantGraph
typing:提供类型提示(Type Hints) 相关的工具,用于在代码中标注变量、函数参数、返回值的类型,提升代码可读性和静态类型检查能力(如配合 mypy 工具)。
Annotated:为类型添加元数据(metadata),格式为 Annotated[type, metadata],其中 type 是基础类型,metadata 是附加信息(可多个)。在保留类型提示的同时,传递额外信息(如校验规则、描述等),常见于数据验证、框架配置等场景。
Sequence:标注 “序列类型”(如列表 list、元组 tuple、字符串 str 等可迭代且有序的对象),等价于 “任何实现了 collections.abc.Sequence 接口的类型”。相比具体类型(如 list),Sequence 更抽象,允许传入多种序列类型,提升代码灵活性。
TypedDict:类型提示工具,定义具有固定键和值类型的字典,明确指定字典中每个键对应的 value 类型,类似 “结构化字典”。在需要严格约束字典结构的场景(如状态管理、API 参数)中使用,替代普通 dict 以提升类型安全性。
os:提供与操作系统交互的接口,实现跨平台的系统级操作(如文件路径处理、环境变量读取、进程管理等)。
langchain_core:提供 LangChain 应用的基础组件和抽象接口,是整个框架的 “骨架”,包含消息处理、提示模板、工具调用、链(Chain)等核心功能的底层定义。
langchain_core.messages:定义对话中各类消息的数据结构和基类,统一消息格式,支持多轮对话的上下文管理。
langchain_core.messages.HumanMessage:封装人类用户的输入消息,明确标记 “来自用户的内容”,是对话流程中 “用户侧” 消息的载体。
langchain_core.messages.AIMessage:封装AI 模型生成的回复消息,明确标记 “来自 AI 的内容”,是对话流程中 “AI 侧” 消息的载体。
langchain_core.messages.BaseMessage:所有消息类型(HumanMessage、AIMessage 等)的抽象父类,定义了消息的通用属性(如 content、id)和方法,确保消息类型的一致性。
langchain_core.messages.ToolMessage:封装工具调用的返回结果(如调用搜索引擎、数据库后的响应),用于将工具输出传递给 AI 模型,作为生成回复的依据。
langchain_core.messages.SystemMessage:封装系统提示消息(如 AI 的角色定义、行为规则),用于指导 AI 的回复风格或逻辑(优先级通常高于用户消息)。
langchain_openai:封装 OpenAI 及兼容 OpenAI API 的模型(如通义千问、智谱 AI 等)的调用逻辑,提供统一接口用于调用聊天模型、嵌入模型等。
ChatOpenAI:实例化 OpenAI 风格的聊天模型(如 gpt-3.5-turbo、通义千问 qwen-max),提供 invoke 等方法调用模型生成回复。
langgraph:用于构建多步骤工作流或智能体(Agent),通过 “状态图(有向图)” 定义节点(处理逻辑)和边(流转规则),支持复杂流程的可视化和执行。
langgraph.graph:提供构建状态图的基础组件,如状态图类、节点 / 边操作函数、特殊节点(如开始 / 结束)等。
langgraph.graph.StateGraph:创建一个状态图实例,用于定义工作流的结构(节点、边、状态类型),是构建工作流的核心对象。
langgraph.graph.END:表示状态图的结束节点,用于标记工作流的终止点(如 graph.add_edge("final_node", END) 表示流程到 final_node 后结束)。
langgraph.graph.add_messages:用于更新状态中的消息列表(如对话历史),自动将新消息(如用户输入、AI 回复)追加到状态的 messages 字段中,简化状态维护逻辑。
langgraph.prebuilt:提供开箱即用的组件(如工具节点、对话节点),避免重复开发常见功能,加速工作流搭建。
langgraph.prebuilt.ToolNode:封装工具调用的逻辑,作为状态图中的一个节点,负责解析 AI 的 tool_calls 指令、执行对应的工具(如函数、API)、并将结果包装为 ToolMessage 回传给状态。
langchain_core.tools:定义工具的抽象接口和基础结构,规范 “可被 AI 调用的工具”(如函数、API)的格式,确保工具能被 LangChain 组件识别和调用。
langchain_core.tools.tool:将普通 Python 函数标记为 **“可被 AI 调用的工具”**,自动生成工具的元数据(如名称、描述、参数类型),供 AI 模型判断何时及如何调用该工具。
document_content:存储当前文档完整内容的全局字符串变量,贯穿整个系统运行过程。作为文档内容的 “唯一数据源”,实现:
- 状态共享:所有函数(
update、our_agent)均可访问和修改,确保人机协作中内容一致; - 状态展示:在
system_prompt中实时展示当前文档内容,让模型和用户清晰了解文档进度; - 持久化基础:
save工具通过读取该变量的值,将内容写入本地文件。
global:Python 中的关键字,核心作用是在函数内部声明变量为 “全局变量”,允许函数修改全局作用域(函数外部)中定义的该变量,而非创建一个同名的局部变量。
content:用户指定的文档新内容,是update工具的核心参数(字符串类型)。替换全局变量document_content的旧值,实现文档内容的更新或起草。
messages:messages 是 AgentState(基于 TypedDict 定义的 “智能体状态结构”)中的核心状态字段,是整个对话与工具调用流程的 “数据载体”。
@tool:langchain_core.tools 模块提供的装饰器(Python 装饰器语法,用 @ 标识,作用于函数)。将普通 Python 函数 “改造” 为AI 可识别、可调用的工具—— 无需手动编写工具元数据(如 “工具叫什么、能做什么、需要哪些参数”),装饰器会自动提取函数信息生成标准格式的工具描述。
tools:一个工具列表,存储了所有被 @tool 装饰后、可供 AI 调用的工具函数。
.endswith():Python 字符串(str)的实例方法,用于检查字符串是否以指定的 “后缀” 结尾,返回布尔值 True(是)或 False(否)。核心用途是快速判断字符串的结尾特征(如文件扩展名、句子结尾符号等)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
suffix |
str 或 tuple |
无 | 是 | 要检查的目标后缀:- 若为字符串(如 ".txt"):检查原字符串是否以该字符串结尾;- 若为元组(如 (".txt", ".pdf")):检查原字符串是否以元组中任意一个字符串结尾(满足一个即返回 True)。 |
start |
int |
0 |
否 | 可选参数,指定检查的 “起始位置”(即从字符串的第 start 个索引开始截取子字符串,再判断该子字符串是否以 suffix 结尾)。 |
end |
int |
字符串长度 | 否 | 可选参数,指定检查的 “结束位置”(即截取子字符串到第 end 个索引为止,再判断该子字符串是否以 suffix 结尾)。 |
filename:用户指定的文档保存名称,是save工具的核心参数(字符串类型)。确定文档保存到本地的文件名及路径(默认保存在当前目录)。
open():打开一个文件,并返回文件对象(file object),是文件读写操作的 “入口”(如你代码中打开 conversation_history.txt 保存对话日志)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
file |
str |
无 | 是 | 要打开的文件路径(可以是绝对路径,如 C:/logs.txt;或相对路径,如 ./history.txt)。 |
mode |
str |
'r' |
否 | 打开模式(决定文件可执行的操作):- 'r':只读(默认);- 'w':写入(覆盖原内容);- 'a':追加(在原内容后添加);- 'r+':读写;带 b 表示二进制模式(如 'wb' 二进制写入)。 |
encoding |
str |
None |
否 | 文本文件的编码格式(如 'utf-8'、'gbk',你的代码中用 'utf-8' 确保中文正常写入)。 |
errors |
str |
None |
否 | 编码错误处理方式(如 'strict' 严格报错、'ignore' 忽略错误)。 |
buffering |
int |
-1 |
否 | 缓冲策略(-1 表示使用默认缓冲,0 表示无缓冲,正数表示缓冲区大小)。 |
.write():向打开的文件中写入字符串内容,返回写入的字符数(仅文本模式有效;二进制模式下需传入字节流,且方法为 .write(bytes))。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
string |
str |
是 | 要写入文件的字符串(文本模式);若为二进制模式,需传入 bytes 类型数据。 |
isinstance():检查一个对象是否是指定类(或元组中的任意类)的实例,返回布尔值(True/False),常用于类型判断(如你代码中区分 HumanMessage 和 AIMessage)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object |
任意对象 | 是 | 需要检查类型的对象(如你代码中的 message)。 |
classinfo |
类 / 类的元组 | 是 | 用于判断的类(如 HumanMessage),或多个类组成的元组(如 (HumanMessage, AIMessage),只要对象是其中任一类的实例,就返回 True)。 |
qw_model:配置完成的通义千问模型客户端,由 ChatOpenAI 类初始化并绑定工具后生成,具备 “自然语言对话 + 工具调用” 的双重能力。
ChatOpenAI():初始化 OpenAI 聊天模型(如 GPT-3.5、GPT-4)的实例,用于调用 OpenAI 的对话 API。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model_name |
str | "gpt-3.5-turbo" |
模型名称(如"gpt-4"、"gpt-3.5-turbo-1106") |
temperature |
float | 0.7 | 输出随机性(0-1,0 为确定性输出,1 为最大随机性) |
api_key |
str | None |
OpenAI API 密钥(默认从环境变量OPENAI_API_KEY读取) |
base_url |
str | None |
API 基础地址(默认"https://api.openai.com/v1",可用于代理或自定义服务) |
max_tokens |
int | None |
生成内容的最大 token 数(默认由模型限制决定) |
timeout |
int | None |
API 调用超时时间(秒) |
streaming |
bool | False |
是否启用流式输出(实时返回部分结果) |
default_headers |
dict | None |
额外的 HTTP 请求头 |
ChatOpenAI().bind_tools():为 AI 模型绑定可调用的工具列表,让模型知道 “可以使用哪些工具”,并在生成回复时自动判断是否需要调用工具(如调用函数、API 等),生成符合格式的工具调用指令(用于后续执行工具)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
tools |
List[BaseTool] 或 List[dict] |
无 | 必需参数,要绑定的工具列表。- 可以是 langchain_core.tools.BaseTool 的实例(如通过 @tool 装饰器定义的工具);- 也可以是工具元数据字典(包含 name、description、parameters 等字段)。 |
tool_choice |
str 或 dict 或 None |
"auto" |
控制模型是否 / 如何选择工具:- "auto":模型自主决定是否调用工具;- "none":不允许调用工具(仅生成自然语言回复);- 工具名称(如 "calculate"):强制调用指定工具;- 字典(如 {"type": "function", "function": {"name": "calculate"}}):更精细的强制调用配置。 |
**kwargs |
任意 | 无 | 其他传递给模型的参数(如 temperature 等,但通常在初始化 ChatOpenAI 时设置)。 |
system_prompt:是 model_call 函数中定义的系统提示消息,由 SystemMessage 类创建,是指导 AI 行为的 “底层规则”。
SystemMessage():定义系统提示消息,用于向 AI 模型传递 “角色设定、行为规则、背景信息” 等底层指令,指导模型的回复风格、逻辑或功能边界(优先级通常高于用户消息)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
content |
str |
无 | 必需参数,系统提示的文本内容(核心指令,如角色定义、规则说明)。 |
additional_kwargs |
dict |
{} |
可选参数,附加元数据(如消息 ID、时间戳等,通常无需手动设置)。 |
response_metadata |
dict |
{} |
可选参数,模型返回的元数据(如生成时间、token 数,一般由模型自动填充)。 |
.invoke():执行一次调用,传入输入并返回处理结果(同步方法)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
input |
多样(如list[Message]、str、dict) |
无 | 输入内容(聊天模型通常接受消息列表,如[HumanMessage(...)]) |
config |
dict | None |
调用配置(如{"tags": ["tag1"]}用于日志标记,"max_concurrency"控制并发) |
**kwargs |
多样 | 无 | 额外参数(如部分模型支持stop列表,指定终止生成的字符串) |
user_input:用户在终端输入的自然语言指令,是触发系统行为的 “指令源”。
user_message:将user_input封装为 LangChain 标准的HumanMessage对象,统一消息格式,确保user_input能与系统提示、AI 响应等其他消息类型(如SystemMessage、AIMessage)兼容,便于all_messages整合和模型识别。
HumanMessage():创建 人类用户消息对象,专门用于在 LangChain 对话流程中 “标记用户输入内容”,与 AI 生成的 AIMessage、工具返回的 ToolMessage 形成明确区分,是对话状态管理的核心载体之一。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content |
str |
无 | 是 | 用户消息的核心文本内容(如 “你好”“计算 3*4”),是 HumanMessage 的核心字段。 |
additional_kwargs |
dict |
{} |
否 | 附加元数据(如用户 ID、消息时间戳等自定义信息),示例:{"user_id": "123", "timestamp": "2024-05-20"}。 |
response_metadata |
dict |
{} |
否 | 模型回复相关的元数据(通常由模型自动填充,用户创建 HumanMessage 时无需手动设置)。 |
list():Python 内置函数,
创建空列表:当无参数时,返回一个空列表([]);
转换可迭代对象为列表:当传入可迭代对象(如元组、字符串、生成器等)时,将其转换为列表,便于后续列表操作(如 append()、索引访问)。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
iterable |
可迭代对象 | 无 | 否 | 可选参数,指能被循环遍历的对象(如元组、字符串、集合、生成器等)。- 若传入,返回该对象转换后的列表;- 若不传入,返回空列表 []。 |
all_messages:整合 “系统提示 + 历史对话消息 + 当前用户输入” 的完整消息列表,是模型(qw_model)的最终输入。
hasattr():检查一个 对象是否具有指定名称的属性或方法,返回布尔值 True(有)或 False(无)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
object |
任意 Python 对象 | 是 | 需要检查属性的目标对象(如 HumanMessage 实例、AIMessage 实例、自定义类实例等)。 |
name |
str |
是 | 要检查的 “属性名或方法名”(必须是字符串格式),如 "content"(属性)、"pretty_print"(方法)、"tool_calls"(属性)。 |
.lower():将字符串中的 所有大写英文字母转换为小写,非英文字母字符(如数字、符号、中文)保持不变,返回转换后的新字符串(原字符串不会被修改)。
graph:StateGraph实例,定义工作流的 “状态图” 对象。
StateGraph():创建一个状态图(有向图),用于定义多步骤工作流(如对话流程、工具调用逻辑),支持节点状态流转。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | None |
状态图的名称(用于标识和日志) |
.set_entry_point():langgraph.graph.StateGraph 类的核心方法,用于指定状态图(工作流)的 “入口节点”—— 即整个流程的起始点,定义了智能体从哪个节点开始执行任务(类似程序的 main 函数,是流程的第一个执行步骤)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
node_name |
str |
是 | 入口节点的名称(字符串),该节点必须是已通过 graph.add_node() 方法添加到状态图中的节点(否则会报错)。 |
.add_node():向状态图中添加一个节点(节点对应一个处理函数,负责处理当前状态并返回新状态)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 无 | 节点唯一名称(用于标识节点) |
func |
Callable | 无 | 节点处理函数(输入为当前状态state,返回更新后的状态或流转指令) |
.add_edge():定义节点之间的边(流转关系),指定从一个节点到另一个节点的跳转规则。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start_node |
str | 无 | 起始节点名称(边的起点) |
end_node |
str 或 Callable | 无 | 目标节点名称(边的终点);若为函数,则根据当前状态动态返回目标节点 |
.add_conditional_edges():langgraph.graph.StateGraph 类的核心方法,用于在状态图中添加 “条件分支边”—— 即根据动态条件(如当前状态、AI 决策结果)自动决定从一个节点跳转到哪个目标节点,实现工作流的灵活分支逻辑(类似编程中的 if-else 判断)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
start_node |
str |
是 | 起始节点的名称(边的起点,如你的代码中的 "our_agent",即 “AI 模型调用节点”)。 |
condition |
Callable |
是 | 条件判断函数,接收当前状态(state)作为输入,返回一个分支标识(如字符串 "continue" 或 "end"),用于决定跳转方向。在你的代码中,should_continue 就是这个函数:检查最新消息是否有工具调用指令,返回 "continue"(需调用工具)或 "end"(无需调用)。 |
destinations |
dict |
是 | 分支标识与目标节点的映射字典,格式为 {分支标识: 目标节点名称或特殊节点(如END)}。在你的代码中,{"continue": "tools", "end": END} 表示:若 condition 返回 "continue",则跳转到 "tools" 节点(执行工具);若返回 "end",则跳转到 END(流程结束)。 |
app:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.compile():编译状态图,生成可执行的Runnable对象(用于运行工作流)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
config |
dict | None |
编译配置(如{"verbose": True}开启详细日志) |
Ipython:IPython 是一个增强的交互式 Python 环境(Interactive Python 的缩写),它在标准 Python 解释器的基础上增加了许多功能,比如:
- 支持语法高亮、自动补全、命令历史记录;
- 可以直接运行 shell 命令(如
!ls); - 支持交互式可视化(如图表、图像显示);
- 提供 “魔法命令”(如
%run、%matplotlib)简化工作流。
它是 Jupyter Notebook/Lab 的核心依赖,广泛用于数据分析、机器学习等交互式开发场景。
Ipython.display:是 IPython 内置的一个模块,专门用于在交互式环境(如 Jupyter Notebook)中显示各种类型的内容,包括但不限于:
- 文本、HTML、Markdown;
- 图像(PNG、JPG 等);
- 音频、视频;
- 复杂对象(如 Pandas DataFrame、Matplotlib 图表)。
它提供了一系列工具函数和类,让开发者可以方便地在交互式界面中展示多样化的输出。
Image:IPython.display 模块中的一个类,用于创建 “可显示的图像对象”,主要作用是:
- 加载图像资源(支持本地文件路径、网络 URL、二进制图像数据);
- 配置图像的显示参数(如宽度、高度、格式);
- 配合
display函数在 Jupyter 等环境中直接显示图像。
display:IPython.display 模块中的一个函数,用于在交互式环境中显示对象。它的核心作用是:
- 接收各种类型的对象(如
Image对象、字符串、HTML 片段、Pandas 表格等); - 根据对象类型自动选择合适的方式渲染并展示(例如,对
Image对象会显示图片,对 HTML 字符串会解析为网页元素)。
display():在交互式环境(如 Jupyter Notebook)中显示对象(图像、HTML、文本等)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
obj |
多样(如Image、str、HTML) |
无 | 要显示的对象 |
** kwargs |
多样 | 无 | 额外显示参数(如clear=True清除之前的输出) |
Image():创建图像对象(IPython 中用于显示图像,PIL 中用于图像处理)。
| 参数名(IPython.display.Image) | 类型 | 默认值 | 描述 |
|---|---|---|---|
data |
bytes | None |
图像二进制数据 |
filename |
str | None |
图像文件路径(优先于data) |
format |
str | None |
图像格式(如"png"、"jpg",自动从文件推断) |
width |
int | None |
显示宽度(像素) |
height |
int | None |
显示高度(像素) |
.get_graph():获取状态图的内部结构(通常为Graph对象,包含节点和边的元数据)。
.draw_mermaid_png():将图结构转换为 Mermaid 语法,并生成 PNG 图像(需安装mermaid-cli)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str | None |
图像保存路径(如"graph.png",不指定则返回二进制数据) |
** kwargs |
多样 | 无 | Mermaid 绘图参数(如"theme": "dark"设置主题) |
'''
我们公司的工作效率不高!我们在起草文件上花费了太多时间,这需要解决!
对于这家公司来说,你需要创建一个AI代理系统,该系统能够加速文档起草、电子邮件撰写等过程。
这个AI代理系统应具备“人机协作”功能,即人类能够持续提供反馈,而一旦人类对草稿感到满意,AI代理就应该停止工作。
该系统应具备以下特性:
1.运行快速
2.能够保存草稿
'''
from typing import Annotated, Sequence, TypedDict
import os
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage, ToolMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.graph import StateGraph, START, END, add_messages
from langgraph.prebuilt import ToolNode
from langchain_core.tools import tool
'''
This is the global variable to store document content
'''
document_content = ""
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
@tool
def update(content: str) -> str:
'''
update the document with the provided content
:param content:
:return:
'''
global document_content
document_content = content
return f"Document has been updated successfully! The current content is:\n {document_content}"
@tool
def save(filename: str) -> str:
'''
save the document to a text file and finish the process
:param filename:Name for the text file
:return:
'''
global document_content
if not filename.endswith(".txt"):
filename += ".txt"
try:
with open(filename, "w") as f:
f.write(document_content)
print(f"Document has been saved successfully as {filename}!")
return f"Document has been saved successfully as {filename}!"
except Exception as e:
return f"Error while saving the document: {str(e)}"
tools = [update, save]
# qwen模型
qw_model = ChatOpenAI(
model="qwen-max", # 通义千问
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
).bind_tools(tools)
def our_agent(state: AgentState) -> AgentState:
system_prompt = SystemMessage(content="You are a helpful assistant. You are given a document and a user query. "
"Your task is to help the user find the answer to their query by updating "
"the document and saving it as a text file."
"if the user wantes to update the document, please type 'update' and "
"provide the new content."
"if the user wants to save the document, please type 'save' and provide the "
"filename."
"make sure to always show the current document state after modification"
"The current document state is:\n{document_content}"
)
if not state["messages"]:
user_input = "I`m ready to help you update a document. What would you like to create?"
user_message = HumanMessage(content=user_input)
else:
user_input = input("\nWhat would you like to do with the document? ")
print(f"\n User input: {user_input}")
user_message = HumanMessage(content=user_input)
all_messages = [system_prompt] + list(state["messages"]) + [user_message]
response = qw_model.invoke(all_messages)
print(f"\n AI:{response.content}")
if hasattr(response, "tool_calls") and response.tool_calls:
print(f"\n Using tool: {[tc['name'] for tc in response.tool_calls]}")
return {"messages": list(state["messages"]) + [user_message, response]}
def should_continue(state):
'''
This function checks if the conversation should continue.
:param state:
:return:
'''
if not state["messages"]:
return "continue"
for message in reversed(state["messages"]):
if (isinstance(message, ToolMessage) and
"saved" in message.content.lower() and
"document" in message.content.lower()):
return "end"
return "continue"
def print_messages(messages):
'''
Function to print the messages in a readable format.
:param messages:
:return:
'''
if not messages:
return
for message in messages:
if isinstance(message, ToolMessage):
print(f"\n Tool result: {message.content}")
graph = StateGraph(AgentState)
graph.add_node("agent", our_agent)
graph.add_node("tools", ToolNode(tools))
graph.set_entry_point("agent")
graph.add_edge("agent", "tools")
graph.add_conditional_edges(
"tools",
should_continue,
{
"continue": "agent",
"end": END
}
)
app = graph.compile()
# Optional: Display the graph (requires IPython)
from IPython.display import Image, display
display(Image(app.get_graph().draw_mermaid_png()))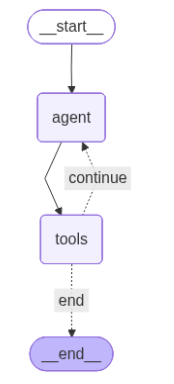
state:state 是 AgentState 类型的实例(AgentState 是一个 TypedDict,定义了状态的结构)。
app:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
stream:print_stream 函数的参数,实际传入的值是 app.stream(inputs, stream_mode="values") 的返回结果。
- 其中
app是StateGraph编译后的可执行对象(Runnable),其.stream()方法用于以流式方式获取智能体的处理结果; stream_mode="values"是.stream()的参数,指定返回 “纯状态数据”(而非包含元数据的完整对象),让结果更简洁。
.stream():以流式方式获取结果,即 “逐步返回部分结果”(而非等待完整结果生成后一次性返回),常用于大模型生成文本时提升用户体验(如实时显示 AI 回复的每一个字符 / 段落)。与同步调用 .invoke()(等待完整结果)不同,.stream() 返回的是 “生成器(generator)”,需通过循环迭代获取每一块结果。
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input |
多样(如 List[BaseMessage]、dict、str) |
无 | 是 | 输入内容,与 .invoke() 的 input 格式一致(如 LLM 调用时传入消息列表,状态图调用时传入初始状态)。 |
config |
dict |
None |
否 | 调用配置,如日志标记({"tags": ["stream-call"]})、超时时间({"timeout": 30})等。 |
**kwargs |
任意 | 无 | 否 | 额外参数,根据所属对象不同可能有差异(如部分模型支持 stop 列表,指定终止生成的字符串)。 |
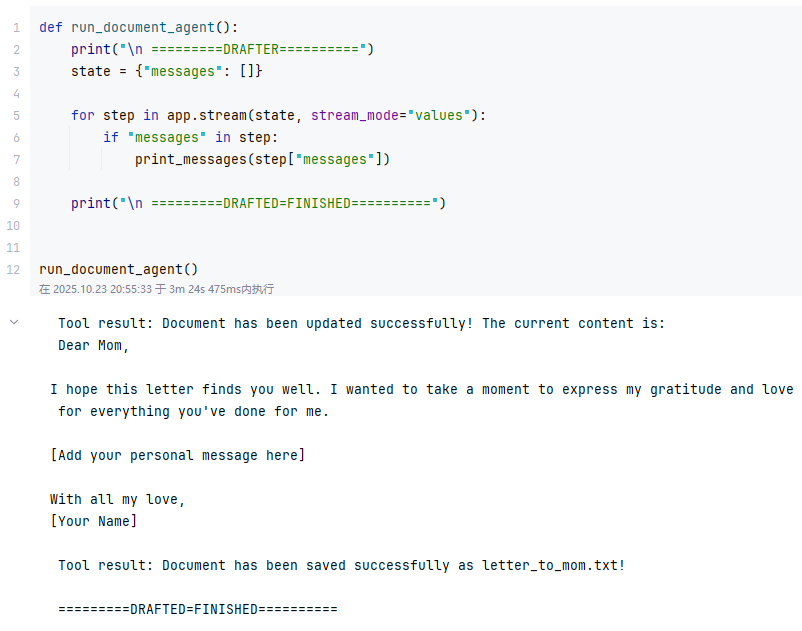
def run_document_agent():
print("\n =========DRAFTER==========")
state = {"messages": []}
for step in app.stream(state, stream_mode="values"):
if "messages" in step:
print_messages(step["messages"])
print("\n =========DRAFTED=FINISHED==========")
run_document_agent()用户输入:
help me to write a letter to my mom
5.RAG_Agent
os:提供与操作系统交互的接口,实现跨平台的系统级操作(如文件路径处理、环境变量读取、进程管理等)。
typing:提供类型提示(Type Hints) 相关的工具,用于在代码中标注变量、函数参数、返回值的类型,提升代码可读性和静态类型检查能力(如配合 mypy 工具)。
Annotated:为类型添加元数据(metadata),格式为 Annotated[type, metadata],其中 type 是基础类型,metadata 是附加信息(可多个)。在保留类型提示的同时,传递额外信息(如校验规则、描述等),常见于数据验证、框架配置等场景。
Sequence:标注 “序列类型”(如列表 list、元组 tuple、字符串 str 等可迭代且有序的对象),等价于 “任何实现了 collections.abc.Sequence 接口的类型”。相比具体类型(如 list),Sequence 更抽象,允许传入多种序列类型,提升代码灵活性。
TypedDict:类型提示工具,定义具有固定键和值类型的字典,明确指定字典中每个键对应的 value 类型,类似 “结构化字典”。在需要严格约束字典结构的场景(如状态管理、API 参数)中使用,替代普通 dict 以提升类型安全性。
langchain_core:提供 LangChain 应用的基础组件和抽象接口,是整个框架的 “骨架”,包含消息处理、提示模板、工具调用、链(Chain)等核心功能的底层定义。
langchain_core.messages:定义对话中各类消息的数据结构和基类,统一消息格式,支持多轮对话的上下文管理。
langchain_core.messages.HumanMessage:封装人类用户的输入消息,明确标记 “来自用户的内容”,是对话流程中 “用户侧” 消息的载体。
langchain_core.messages.AIMessage:封装AI 模型生成的回复消息,明确标记 “来自 AI 的内容”,是对话流程中 “AI 侧” 消息的载体。
langchain_core.messages.BaseMessage:所有消息类型(HumanMessage、AIMessage 等)的抽象父类,定义了消息的通用属性(如 content、id)和方法,确保消息类型的一致性。
langchain_core.messages.ToolMessage:封装工具调用的返回结果(如调用搜索引擎、数据库后的响应),用于将工具输出传递给 AI 模型,作为生成回复的依据。
langchain_core.messages.SystemMessage:封装系统提示消息(如 AI 的角色定义、行为规则),用于指导 AI 的回复风格或逻辑(优先级通常高于用户消息)。
langchain_openai:封装 OpenAI 及兼容 OpenAI API 的模型(如通义千问、智谱 AI 等)的调用逻辑,提供统一接口用于调用聊天模型、嵌入模型等。
ChatOpenAI:实例化 OpenAI 风格的聊天模型(如 gpt-3.5-turbo、通义千问 qwen-max),提供 invoke 等方法调用模型生成回复。
langgraph:用于构建多步骤工作流或智能体(Agent),通过 “状态图(有向图)” 定义节点(处理逻辑)和边(流转规则),支持复杂流程的可视化和执行。
langgraph.graph:提供构建状态图的基础组件,如状态图类、节点 / 边操作函数、特殊节点(如开始 / 结束)等。
langgraph.graph.StateGraph:创建一个状态图实例,用于定义工作流的结构(节点、边、状态类型),是构建工作流的核心对象。
langgraph.graph.END:表示状态图的结束节点,用于标记工作流的终止点(如 graph.add_edge("final_node", END) 表示流程到 final_node 后结束)。
langchain_core.tools:定义工具的抽象接口和基础结构,规范 “可被 AI 调用的工具”(如函数、API)的格式,确保工具能被 LangChain 组件识别和调用。
langchain_core.tools.tool:将普通 Python 函数标记为 **“可被 AI 调用的工具”**,自动生成工具的元数据(如名称、描述、参数类型),供 AI 模型判断何时及如何调用该工具。
langchain_text_splitter:LangChain 框架下的文本拆分专用模块,专门解决 “长文本超出模型上下文限制” 的问题 —— 无论是大模型的输入长度限制,还是嵌入模型的向量生成长度限制,都需要将长文本拆分为短片段(称为 chunk),该模块提供了多种拆分策略(按字符、按 token、按语义等)。
langchain_text_splitter.RecursiveCharacterTextSplitter:langchain_text_splitter 模块中最常用、最推荐的拆分类,采用 “递归字符拆分策略”:按优先级从大到小的分隔符(如段落→换行→句子→空格)拆分文本,若拆分后仍超出长度限制,则继续递归拆分更小的单位,最大限度保留文本的语义连贯性(比如优先不拆分段落、句子)。
qw_model:调用通义千问大模型(qwen-max),用于生成回复或工具调用指令
ChatOpenAI():初始化 OpenAI 聊天模型(如 GPT-3.5、GPT-4)的实例,用于调用 OpenAI 的对话 API。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model_name |
str | "gpt-3.5-turbo" |
模型名称(如"gpt-4"、"gpt-3.5-turbo-1106") |
temperature |
float | 0.7 | 输出随机性(0-1,0 为确定性输出,1 为最大随机性) |
api_key |
str | None |
OpenAI API 密钥(默认从环境变量OPENAI_API_KEY读取) |
base_url |
str | None |
API 基础地址(默认"https://api.openai.com/v1",可用于代理或自定义服务) |
max_tokens |
int | None |
生成内容的最大 token 数(默认由模型限制决定) |
timeout |
int | None |
API 调用超时时间(秒) |
streaming |
bool | False |
是否启用流式输出(实时返回部分结果) |
default_headers |
dict | None |
额外的 HTTP 请求头 |
embeddings:将文本(如 PDF 拆分后的片段)转换为数值向量(供 Chroma 向量库存储和检索)
DashScopeEmbeddings():LangChain 封装的阿里云 DashScope 文本嵌入模型类,用于将文本(如 PDF 片段)转换为数值向量,为向量库存储和相似性检索提供基础。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
model |
str |
无(必填) | 嵌入模型名称,代码中使用 text-embedding-v1(DashScope 官方文本嵌入模型)。 |
dashscope_api_key |
str |
None |
DashScope 服务的 API 密钥,代码中从环境变量 DASHSCOPE_API_KEY 读取,用于权限验证。 |
api_base |
str |
None |
可选,自定义 API 基础地址,默认使用 DashScope 官方地址,代码中未额外配置。 |
timeout |
int |
60 |
可选,请求超时时间(秒),超过时间未响应则抛出错误。 |
**kwargs |
任意 | - | 可选,其他传递给 DashScope API 的额外参数(如请求头、重试配置等)。 |
pdf_path:指定待加载的 PDF 文件路径(绝对路径)
os.path.exists():Python os.path 模块的内置函数,用于判断指定路径(文件或目录)是否存在,返回布尔值 True(存在)或 False(不存在),代码中用于校验 PDF 文件路径和向量库存储目录是否有效。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str |
无(必填) | 待判断的路径字符串(绝对路径或相对路径),代码中用于校验 pdf_path 和 persist_directory。 |
FileNotFoundError():Python 内置异常类,用于在 “指定文件不存在” 时主动抛出错误,明确提示文件缺失问题,代码中在 pdf_path 对应的文件不存在时调用。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
msg |
str |
无(必填) | 错误提示信息,代码中使用 f"File {pdf_path} does not exist.",明确缺失的文件路径。 |
pdf_loader:读取 pdf_path 指向的 PDF 文件,将其解析为结构化的 “页面文档”
PyPDFLoader():LangChain langchain_community.document_loaders 模块的 PDF 加载类,用于读取本地 PDF 文件并解析为结构化的 Document 对象,每个 Document 对应 PDF 的一页或一段内容。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
file_path |
str |
无(必填) | 待加载的 PDF 文件路径(绝对路径或相对路径),代码中传入 pdf_path。 |
extract_images |
bool |
False |
可选,是否提取 PDF 中的图片,默认不提取 |
.load():PyPDFLoader 类的核心方法,执行 PDF 文件加载与解析,将 PDF 的每一页转换为 langchain_core.documents.base.Document 对象,返回包含所有页面的列表。
pages:列表,存储加载后的 PDF 页面数据,每个元素是 Document 对象
text_splitter:将 PDF 的长文本(pages 中的 page_content)拆分为短片段,适配嵌入模型的长度限制
RecursiveCharacterTextSplitter():文本拆分类,用于将长文本(如 PDF 页面)拆分为短片段,适配嵌入模型的长度限制,同时通过重叠保留上下文连贯性。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
chunk_size |
int |
1000 |
单个文本片段的最大字符数,代码中使用 1000(避免超出嵌入模型上下文)。 |
chunk_overlap |
int |
200 |
相邻片段的重叠字符数,代码中使用 200(确保语义连贯,避免拆分断裂)。 |
length_function |
Callable |
len |
可选,计算文本长度的函数,默认用 len()(按字符数计算)。 |
separators |
List[str] |
["\n\n", "\n", ". ", " ", ""] |
可选,拆分文本的分隔符列表,按优先级尝试(默认优先按段落、换行拆分)。 |
pages_split:存储拆分后的文本片段,初始为 text_splitter.split_documents(pages) 的结果;
text_splitter.split_documents():对 Document 对象列表(如 pages)进行拆分,将每个 Document 的长文本拆分为多个短 Document,返回拆分后的 Document 列表,代码中用于拆分 PDF 页面为片段。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
documents |
List[Document] |
无(必填) | 待拆分的 Document 对象列表,代码中传入 pages(加载后的 PDF 页面列表)。 |
**kwargs |
任意 | - | 可选,额外拆分配置(如强制拆分规则),代码中未使用。 |
filtered_pages:过滤 pages_split 中的 “空文档” 或 “无效文本文档”,确保存入向量库的文本有意义
raw_content:从拆分后的文档对象 doc 中提取的原始文本内容,即 raw_content = doc.page_content。
type():Python 内置函数,用于获取对象的类型,返回对象所属的类(如 str、Document、AIMessage 等),代码中用于调试,打印 raw_content 的类型以定位异常。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
object |
任意 Python 对象 | 无(必填) | 待查询类型的对象,代码中传入 raw_content(PDF 片段的原始内容)。 |
str_content:“清洗后的数据”,通过类型转换和空白去除,确保内容有效且格式统一,是最终存入向量库的 “可用文本”。
.strip():Python 字符串的内置方法,用于去除字符串首尾的空白字符(包括空格 、换行符 \n、制表符 \t 等),返回处理后的新字符串(原字符串不变),代码中用于清洗 PDF 片段的空白。
persist_directory:指定 Chroma 向量库的 “持久化存储路径”(本地文件夹路径)
collection_name:指定 Chroma 向量库中的 “集合名称”(类似数据库中的 “表名”)
os.path.exists():Python os.path 模块的内置函数,核心作用是判断指定的文件或目录路径是否真实存在,返回布尔值 True(存在)或 False(不存在),是文件 / 目录操作前 “防错校验” 的常用工具。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
path |
str |
是 | 待验证的路径字符串,支持绝对路径(如 r"F:\AI_BigModel\data\test.pdf")和相对路径(如 "./data/test.pdf");路径可指向文件或目录。 |
os.makedirs():ython os 模块的函数,用于递归创建目录(即若父目录不存在,会自动创建所有层级目录),避免手动创建多级目录的麻烦,代码中用于创建向量库的持久化存储目录。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str |
无(必填) | 待创建的目录路径(绝对路径或相对路径),代码中传入 persist_directory。 |
mode |
int |
0o777 |
可选,目录权限(仅 Unix 系统有效),Windows 系统忽略该参数。 |
exist_ok |
bool |
False |
可选,若目录已存在是否抛出错误:False(默认,抛出 FileExistsError)、True(不抛出,直接跳过),代码中未设置(需确保目录不存在或手动处理)。 |
chroma_client:Chroma 客户端,负责创建 / 复用集合、管理向量数据持久化
chromadb.PersistentClient():Chroma 向量库的持久化客户端类,用于创建或连接到本地持久化的 Chroma 向量库(数据存储在指定路径,程序重启后数据不丢失),代码中作为向量库的操作入口。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str |
无(必填) | 向量库数据的存储路径,代码中传入 persist_directory(本地目录路径)。 |
**kwargs |
任意 | - | 可选,额外客户端配置(如日志级别、超时),代码中未使用。 |
.get_or_create_collection():Chroma 客户端的方法,用于获取指定名称的集合(Collection),若不存在则创建(类似数据库中的 “表”,用于分类存储向量数据),代码中用于创建 / 复用 PDF_market 集合。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str |
无(必填) | 集合名称,代码中传入 collection_name(即 PDF_market)。 |
metadata |
dict |
None |
可选,集合的元数据(如描述、创建时间),代码中未设置。 |
embedding_function |
Callable |
None |
可选,集合级别的嵌入函数(代码中通过 LangChain 的 Chroma 类统一配置,此处未设置)。 |
vectorstore:整合 Chroma 客户端与嵌入模型,提供 “文档存入” 和 “相似性检索” 的统一接口
Chroma():LangChain 封装的 Chroma 向量库类,用于整合 Chroma 客户端与嵌入模型,提供 “文档存入”“相似性检索” 的统一接口,适配 LangChain 的工作流,代码中创建向量库实例。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
client |
chromadb.Client |
无(必填) | Chroma 客户端实例,代码中传入 chroma_client(持久化客户端)。 |
collection_name |
str |
无(必填) | 集合名称,代码中传入 collection_name(PDF_market)。 |
embedding_function |
Embeddings |
无(必填) | 嵌入模型实例,代码中传入 embeddings(DashScopeEmbeddings 实例),用于自动生成文本向量。 |
**kwargs |
任意 | - | 可选,额外配置(如文档 ID 生成规则),代码中未使用。 |
.add_documents():Chroma 向量库实例的方法,用于将 Document 对象列表存入向量库,自动调用绑定的嵌入模型生成向量,同时存储文档文本和元数据,代码中用于存入过滤后的 PDF 片段。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
documents |
List[Document] |
无(必填) | 待存入的 Document 对象列表,代码中传入 pages_split(过滤后的 PDF 片段)。 |
ids |
List[str] |
None |
可选,手动指定文档 ID 列表,若未设置则自动生成唯一 ID。 |
**kwargs |
任意 | - | 可选,额外存储配置(如元数据过滤规则),代码中未使用。 |
retriever:根据用户查询(query),从 vectorstore 中检索 “最相似的文档片段”
.as_retriever():Chroma 向量库实例的方法,用于创建向量库检索器(Retriever),封装相似性检索逻辑,提供 invoke(query) 接口供工具调用,代码中创建 retriever 用于后续查询。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
search_type |
str |
"similarity" |
可选,检索算法类型:"similarity"(余弦相似性,默认)、"mmr"(最大边际相关性,减少结果冗余),代码中使用 "similarity"。 |
search_kwargs |
dict |
{"k": 4} |
可选,检索参数:"k"(返回 Top k 个相似结果)、"filter"(元数据过滤)等,代码中传入 {"k": 5}(返回 Top 5)。 |
@tool:langchain_core.tools 模块提供的装饰器(Python 装饰器语法,用 @ 标识,作用于函数)。将普通 Python 函数 “改造” 为AI 可识别、可调用的工具—— 无需手动编写工具元数据(如 “工具叫什么、能做什么、需要哪些参数”),装饰器会自动提取函数信息生成标准格式的工具描述。
tools:集中管理所有可被 AI 调用的工具,此处仅包含 retriever_tool
.invoke():LangChain 中 Runnable 类型对象(如 Retriever、ChatOpenAI、CompiledGraph)的统一调用方法,用于执行核心逻辑并返回结果,不同对象的 invoke() 功能不同,代码中涉及 3 类场景:
- Retriever.invoke(query):执行相似性检索,返回相似文档列表;
- ChatOpenAI.invoke(messages):调用大模型,返回 AI 消息(含文本或工具调用);
- CompiledGraph.invoke(state):执行状态图流程,返回最终状态。
| 调用场景 | 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|---|
| Retriever.invoke() | query |
str |
无(必填) | 用户查询文本,代码中传入 t['args'].get('query')(工具调用的查询参数)。 |
| ChatOpenAI.invoke() | messages |
List[BaseMessage] |
无(必填) | 消息列表(含 SystemMessage、HumanMessage 等),代码中传入 all_messages 或 messages。 |
| CompiledGraph.invoke() | input |
Dict |
无(必填) | 状态图初始输入(符合 AgentState 结构),代码中传入 {"messages": [HumanMessage]}。 |
llm:在 qw_model 基础上绑定 tools,让模型具备 “判断是否调用工具、生成工具调用指令” 的能力
.bind_tools():LangChain ChatOpenAI 类的方法,用于将工具列表绑定到大模型,让模型知道 “可调用哪些工具”,并能自动生成符合格式的工具调用指令(tool_calls),代码中用于绑定 retriever_tool。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
tools |
List[Tool] 或 List[dict] |
无(必填) | 待绑定的工具列表:可是 Tool 实例(如 retriever_tool)或工具元数据字典,代码中传入 tools([retriever_tool])。 |
tool_choice |
str 或 dict |
"auto" |
可选,工具调用控制:"auto"(模型自主决定)、"none"(不调用工具)、工具名(强制调用指定工具),代码中未设置(默认 "auto")。 |
**kwargs |
任意 | - | 可选,额外模型参数(如 temperature),代码中未使用。 |
system_prompt:AI 的系统提示,定义角色(回答 PDF 相关问题)和规则(必须用 retriever_tool 检索,引用文档内容)
tools_dict:将工具列表 tools 转为 “工具名称→工具实例” 的映射,方便快速通过工具名查找工具
message:llm.invoke(messages) 的返回结果,含 AI 的回复或工具调用指令;
messages:从 state["messages"] 复制对话历史,拼接 SystemMessage(system_prompt),形成完整的模型输入;
.append():Python 列表的内置方法,用于在列表末尾添加一个元素,直接修改原列表(无返回值,或返回 None),代码中用于拼接工具结果、消息列表等。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
object |
任意 | 无(必填) | 待添加到列表的元素,代码中用于添加 doc(到 filtered_pages)、ToolMessage(到 res)等。 |
graph:StateGraph实例,定义工作流的 “状态图” 对象。
StateGraph():创建一个状态图(有向图),用于定义多步骤工作流(如对话流程、工具调用逻辑),支持节点状态流转。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | None |
状态图的名称(用于标识和日志) |
.set_entry_point():langgraph.graph.StateGraph 类的核心方法,用于指定状态图(工作流)的 “入口节点”—— 即整个流程的起始点,定义了智能体从哪个节点开始执行任务(类似程序的 main 函数,是流程的第一个执行步骤)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
node_name |
str |
是 | 入口节点的名称(字符串),该节点必须是已通过 graph.add_node() 方法添加到状态图中的节点(否则会报错)。 |
.add_node():向状态图中添加一个节点(节点对应一个处理函数,负责处理当前状态并返回新状态)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
name |
str | 无 | 节点唯一名称(用于标识节点) |
func |
Callable | 无 | 节点处理函数(输入为当前状态state,返回更新后的状态或流转指令) |
.add_edge():定义节点之间的边(流转关系),指定从一个节点到另一个节点的跳转规则。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
start_node |
str | 无 | 起始节点名称(边的起点) |
end_node |
str 或 Callable | 无 | 目标节点名称(边的终点);若为函数,则根据当前状态动态返回目标节点 |
.add_conditional_edges():langgraph.graph.StateGraph 类的核心方法,用于在状态图中添加 “条件分支边”—— 即根据动态条件(如当前状态、AI 决策结果)自动决定从一个节点跳转到哪个目标节点,实现工作流的灵活分支逻辑(类似编程中的 if-else 判断)。
| 参数名 | 类型 | 是否必填 | 描述 |
|---|---|---|---|
start_node |
str |
是 | 起始节点的名称(边的起点,如你的代码中的 "our_agent",即 “AI 模型调用节点”)。 |
condition |
Callable |
是 | 条件判断函数,接收当前状态(state)作为输入,返回一个分支标识(如字符串 "continue" 或 "end"),用于决定跳转方向。在你的代码中,should_continue 就是这个函数:检查最新消息是否有工具调用指令,返回 "continue"(需调用工具)或 "end"(无需调用)。 |
destinations |
dict |
是 | 分支标识与目标节点的映射字典,格式为 {分支标识: 目标节点名称或特殊节点(如END)}。在你的代码中,{"continue": "tools", "end": END} 表示:若 condition 返回 "continue",则跳转到 "tools" 节点(执行工具);若返回 "end",则跳转到 END(流程结束)。 |
rag_agent:StateGraph编译后的可执行对象,可直接调用的 “智能体” 实例,用于执行graph定义的工作流。
.compile():编译状态图,生成可执行的Runnable对象(用于运行工作流)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
config |
dict | None |
编译配置(如{"verbose": True}开启详细日志) |
Ipython:IPython 是一个增强的交互式 Python 环境(Interactive Python 的缩写),它在标准 Python 解释器的基础上增加了许多功能,比如:
- 支持语法高亮、自动补全、命令历史记录;
- 可以直接运行 shell 命令(如
!ls); - 支持交互式可视化(如图表、图像显示);
- 提供 “魔法命令”(如
%run、%matplotlib)简化工作流。
它是 Jupyter Notebook/Lab 的核心依赖,广泛用于数据分析、机器学习等交互式开发场景。
Ipython.display:是 IPython 内置的一个模块,专门用于在交互式环境(如 Jupyter Notebook)中显示各种类型的内容,包括但不限于:
- 文本、HTML、Markdown;
- 图像(PNG、JPG 等);
- 音频、视频;
- 复杂对象(如 Pandas DataFrame、Matplotlib 图表)。
它提供了一系列工具函数和类,让开发者可以方便地在交互式界面中展示多样化的输出。
Image:IPython.display 模块中的一个类,用于创建 “可显示的图像对象”,主要作用是:
- 加载图像资源(支持本地文件路径、网络 URL、二进制图像数据);
- 配置图像的显示参数(如宽度、高度、格式);
- 配合
display函数在 Jupyter 等环境中直接显示图像。
display:IPython.display 模块中的一个函数,用于在交互式环境中显示对象。它的核心作用是:
- 接收各种类型的对象(如
Image对象、字符串、HTML 片段、Pandas 表格等); - 根据对象类型自动选择合适的方式渲染并展示(例如,对
Image对象会显示图片,对 HTML 字符串会解析为网页元素)。
display():在交互式环境(如 Jupyter Notebook)中显示对象(图像、HTML、文本等)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
obj |
多样(如Image、str、HTML) |
无 | 要显示的对象 |
** kwargs |
多样 | 无 | 额外显示参数(如clear=True清除之前的输出) |
Image():创建图像对象(IPython 中用于显示图像,PIL 中用于图像处理)。
| 参数名(IPython.display.Image) | 类型 | 默认值 | 描述 |
|---|---|---|---|
data |
bytes | None |
图像二进制数据 |
filename |
str | None |
图像文件路径(优先于data) |
format |
str | None |
图像格式(如"png"、"jpg",自动从文件推断) |
width |
int | None |
显示宽度(像素) |
height |
int | None |
显示高度(像素) |
.get_graph():获取状态图的内部结构(通常为Graph对象,包含节点和边的元数据)。
.draw_mermaid_png():将图结构转换为 Mermaid 语法,并生成 PNG 图像(需安装mermaid-cli)。
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
path |
str | None |
图像保存路径(如"graph.png",不指定则返回二进制数据) |
** kwargs |
多样 | 无 | Mermaid 绘图参数(如"theme": "dark"设置主题) |
import os
from langchain_chroma import Chroma
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated, Sequence
from langchain_core.messages import BaseMessage, SystemMessage, HumanMessage, AIMessage, ToolMessage
from operator import add as add_messages
from langchain_openai import ChatOpenAI
from langchain_community.embeddings import DashScopeEmbeddings
# from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.tools import tool
import chromadb
# qwen模型
qw_model = ChatOpenAI(
model="qwen-max", # 通义千问
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.7
)
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", # 文本编码模型
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY"),
)
pdf_path = r"F:\AI_BigModel\appTest6\day6_LangGraph\data\deepseek-v3-1-4.pdf"
'''
Safety measure I have put for debugging purposes
'''
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"File {pdf_path} does not exist.")
# This is load the PDF
pdf_loader = PyPDFLoader(pdf_path)
try:
pages = pdf_loader.load()
print(f"PDF has been loaded successfully. Total pages: {len(pages)}")
except Exception as e:
print(f"Error loading PDF: {e}")
raise
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200,
)
pages_split = text_splitter.split_documents(pages)
filtered_pages = []
for i, doc in enumerate(pages_split):
# 打印原始内容的类型和值(关键:定位异常文档)
raw_content = doc.page_content
print(f"文档{i} | 类型: {type(raw_content)} | 原始内容: {repr(raw_content)}")
# 强制转为字符串 + 去除首尾空白
str_content = str(raw_content).strip()
if str_content: # 非空才保留
doc.page_content = str_content
filtered_pages.append(doc)
else:
print(f"文档{i} 内容为空或无效,已跳过")
pages_split = filtered_pages # 替换为过滤后的文档列表
persist_directory = r"F:\AI_BigModel\appTest6\appTest6\day6_LangGraph\data"
collection_name = "PDF_market"
if not os.path.exists(persist_directory):
os.makedirs(persist_directory)
try:
# 1. 手动初始化Chroma客户端(避免from_documents内部参数冲突)
chroma_client = chromadb.PersistentClient(path=persist_directory)
chroma_client.get_or_create_collection(name=collection_name)
# 2. 包装为LangChain VectorStore(仅传1次embedding_function)
vectorstore = Chroma(
client=chroma_client,
collection_name=collection_name,
embedding_function=embeddings
)
# 3. 手动添加文档
vectorstore.add_documents(documents=pages_split)
print(f"Created vectorstore successfully.")
except Exception as e:
print(f"Error creating vectorstore: {str(e)}")
raise
# Now we create our retriever
retriever = vectorstore.as_retriever(
search_kwargs={"k": 5},
search_type="similarity"
)
@ tool
def retriever_tool(query: str) -> str:
'''
This tool searches and returns the information from the deepseek-v3-1-4.pdf document.
:param query:
:return:
'''
docs = retriever.invoke(query)
if not docs:
return "No relevant information found."
res = []
for i, doc in enumerate(docs):
res.append(f"Document {i+1}: \n{doc.page_content}\n")
return "\n\n".join(res)
tools = [retriever_tool]
llm = qw_model.bind_tools(tools)
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage] ,add_messages]
def should_continue(state: AgentState) -> bool:
'''
check if the agent should continue to chat
:param state:
:return:
'''
result = state["messages"][-1]
return hasattr(result, "tool_calls") and len(result.tool_calls) > 0
system_prompt = """
You are a intelligent AI assistant who answers questions about the deepseek-v3-1-4.pdf document loaded into your knowledge base.
Use the retriever tool available to answer questions about the deepseek-v3-1-4.pdf data. You can make multiple calls if needed
Please always cite the specific parts of the document you use in your answers.
"""
tools_dict = {our_tool.name: our_tool for our_tool in tools}
# LLM Agent
def call_llm(state: AgentState) -> AgentState:
'''
call the llm to generate a response
:param state:
:return:
'''
messages = list(state["messages"])
messages = [SystemMessage( content=system_prompt)] + messages
message = llm.invoke(messages)
return {"messages": [message]}
# Retriever Agent
def take_action(state: AgentState) -> AgentState:
'''
call the retriever tool to get the relevant documents
:param state:
:return:
'''
tool_calls = state["messages"][-1].tool_calls
res = []
for t in tool_calls:
print(f"Calling tool {t['name']} with input {t['args'].get('query', 'No query provided')}")
if not t['name'] in tools_dict:
print(f"Tool {t['name']} not found in tools")
tool_res = "Incorrect Tool Name, Please Retry and Select tool from List of Available Tools"
else:
tool_res = tools_dict[t['name']].invoke(t['args'].get('query', 'No query provided'))
print(f"Result length:{len(str(res))}")
res.append(ToolMessage(tool_call_id=t['id'], name = t['name'], content = str(tool_res)))
print("Tools Execution Complete. Back to the model")
return {'messages': res}
graph = StateGraph(AgentState)
graph.add_node("llm", call_llm)
graph.add_node("retriever_agent", take_action)
graph.add_conditional_edges(
"llm",
should_continue,
{True: "retriever_agent", False: END}
)
graph.add_edge("retriever_agent", "llm")
graph.set_entry_point("llm")
rag_agent = graph.compile()
# Optional: Display the graph (requires IPython)
from IPython.display import Image, display
display(Image(rag_agent.get_graph().draw_mermaid_png()))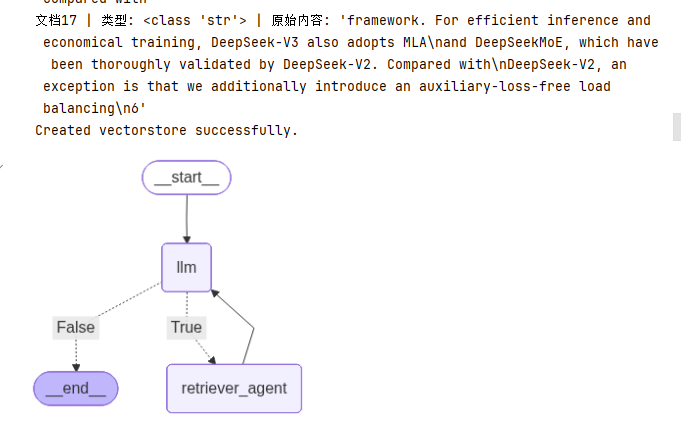
user_input:仅在 running_agent() 函数中定义,通过 input("\nEnter your query: ") 从用户键盘输入获取,是 “用户需求的直接载体”。
input():从用户键盘获取输入,返回字符串类型的输入内容,常用于交互场景
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
prompt |
str |
"" |
否 | 可选的 “输入提示文本”,会在获取用户输入前显示在控制台,引导用户操作。 |
.lower():将字符串中的所有大写英文字母转换为小写,非英文字符(如数字、中文、符号)保持不变,返回新字符串(原字符串不修改),常用于 “不区分大小写判断”
messages:用户输入的标准化包装—— 将 user_input 转换为 LangChain 能识别的 HumanMessage,作为 rag_agent.invoke() 的输入参数。
HumanMessage():创建 “人类用户消息对象”,将用户输入的纯文本包装为 LangChain 框架可识别的消息格式,用于对话流程中标记 “用户输入”
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
content |
str |
无 | 是 | 用户消息的核心文本内容,即用户输入的具体内容(如你的代码中 HumanMessage(content=user_input),user_input 就是 content)。 |
additional_kwargs |
dict |
{} |
否 | 可选的附加元数据,用于存储用户相关的额外信息(如用户 ID、输入时间戳),你的代码中未使用该参数。 |
response_metadata |
dict |
{} |
否 | 可选的模型回复关联元数据(通常由模型自动填充,用户创建 HumanMessage 时无需手动设置),你的代码中未使用该参数。 |
res:是 **rag_agent.invoke() 的返回结果 **—— 包含智能体执行后的完整对话历史(messages 字段),其中 res["messages"][-1] 就是 AI 给用户的最终回复。
rag_agent:由 graph.compile() 生成 ——graph 是 StateGraph 实例(定义了节点、边、流程规则),compile() 会将流程逻辑转换为可调用的 “智能体”。
.invoke():启动编译后的 RAG 智能体(rag_agent),执行 “模型→工具→模型” 的完整流程,返回最终状态
| 参数名 | 类型 | 默认值 | 是否必填 | 描述 |
|---|---|---|---|---|
input |
dict |
无 | 是 | 智能体的初始输入,需符合 AgentState 结构(核心包含 messages 字段)(如你的代码中 {"messages": [HumanMessage(content=user_input)]})。 |
**kwargs |
任意 | - | 否 | 可选的额外流程参数(如日志配置、超时时间),你的代码中未额外传递。 |
def running_agent():
print("\n===========RAG AGENT===========")
while True:
user_input = input("\nEnter your query: ")
if user_input.lower() in ["exit", "quit"]:
break
messages = [HumanMessage(content=user_input)]
res = rag_agent.invoke({"messages": messages})
print("\n=======ANSWER======")
print(res['messages'][-1].content)
running_agent()用户输入:
introduce the deepseek model


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)