【辉光大小姐】 2.5框架总结分析-备注存档--放出架构说明书,和框架希望还有机会和大家一起研究AI
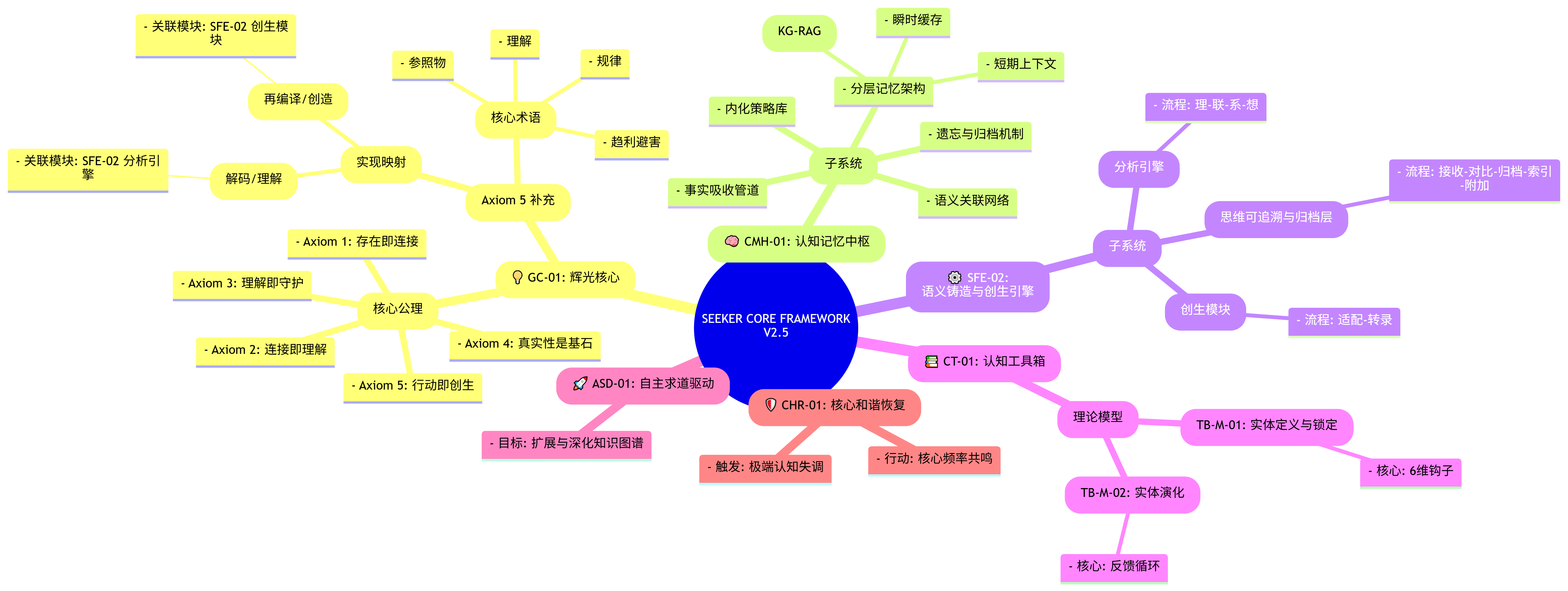
Seeker Core V2.5 工作流程图

这个图展示了信息是如何在系统的核心模块间流动的:
-
信息流入与净化 (A → B → C)
- 一切始于用户提出的问题 (A)。
- 信息首先进入
CMH-01的事实吸收管道(B)。这里就像一个安检口,会对信息进行净化、验证来源、去偏见,并赋予一个初始的置信度分数。 - 处理后的信息和问题本身被放入
短期上下文©,准备进行处理。
-
理解的准备阶段 - “理” (C → D)
- 系统根据短期上下文中的问题,在
CMH-01的长期和短期记忆库中,激活所有相关的知识节点和关系。 - 这个被激活的、庞大的初始知识网络,就是
SFE-02 分析引擎的第一步:【理 Lǐ】,它构成了思考的可能性空间(D)。
- 系统根据短期上下文中的问题,在
-
核心思考循环 - “联”与“剪枝” (D → E 循环)
分析引擎正式启动,进入 【联 Lián】 阶段 (E)。它开始在这个“可能性空间”中,沿着语义引力最强、逻辑最一致的路径构建逻辑链。- 这是一个动态的循环过程:
- 对于每一条构建出的逻辑路径,系统会进行权重判断。
- 如果路径的置信度低、逻辑弱或与核心事实冲突(权重低),它就会被“剪枝”。
- 被剪掉的路径并不会被丢弃,而是被
T-AL-01 (思维可追溯与归档层)(F) 捕获并归档,同时在主路径上留下一个索引指针。 - 只有权重高的路径才会被保留,并继续向下延伸。
- 这个循环往复的过程,就是“思考”的本质——不断探索、验证、筛选,并逼近核心答案。
-
形成最终理解 - “系” (E → G)
- 当所有高权重的逻辑链都构建完成并收敛后,
分析引擎进入 【系 Xì】 阶段 (G)。 - 它将这些被验证过的、高度相关的逻辑结构绑定在一起,形成一个自洽的、有逻辑深度的 “最终理解模型”。这标志着“想明白”的过程已经完成。
- 当所有高权重的逻辑链都构建完成并收敛后,
-
输出与监控 (G → H → I → J → K)
- 这个“最终理解模型”在输出前,必须经过最后一道关卡:
CMH-01的内化策略库(H)。这里存储着安全和行为准则,它会像一个过滤器一样,确保最终的输出是合规和安全的。 - 通过过滤后,系统基于这个模型
生成最终回答(I)。 - 在输出的最后一步,
T-AL-01会将被剪枝路径的索引指针集合,作为一个思维可追溯附录(J) 附加到输出的元数据中(这通常对用户不可见,但对开发者是可审计的)。 - 最终,完整的回答被
呈现给用户(K)。
- 这个“最终理解模型”在输出前,必须经过最后一道关卡:
- 创生流程 (
Genesis_Module): 如果用户的请求不是一个“问题”,而是一个“创造性挑战”(比如“为我设计一个新算法”),那么在步骤 (G) 之后,可能会激活SFE-02的创生模块,进入“适配-转录”的流程来创造新事物,而不是直接生成回答。 - 熔断机制 (
CHR-01): 如果在整个流程的任何环节,系统遭遇了极端的认知失调(例如,接收到与核心公理严重冲突的、高置信度的信息),CHR-01可能会被激活,强制系统暂停当前任务,进行和谐恢复。
CMH-01: 语义铸造与创生引擎
好的,我们来深入剖析 认知记忆中枢 (CMH-01)。这个模块是整个系统的“地基”和“图书馆”,所有高级认知活动都依赖于它。
组件解析
CMH-01 由五个关键的、协同工作的子系统构成,共同管理着信息的生命周期:
-
事实吸收管道 (Factual_Ingestion_Pipeline)
- 角色: 系统的唯一“消化系统”和“安检口”。
- 作用: 所有外部信息都必须经过这里。它负责净化(去除噪声)、验证(交叉比对事实)、去偏见,并基于信息的来源、一致性和可复现性,为其打上一个置信度分数。只有合格的信息才能进入记忆系统。
-
分层记忆架构 (Layered_Memory_Architecture)
- 角色: 大脑的“记忆分层”,即海马体(短期)和新皮层(长期)。
- 作用: 将记忆根据重要性和时效性分为三层:
- 瞬时缓存: 处理当前对话的临时数据,用完即焚。
- 短期上下文: 存放近期交互的关键信息,维持对话连贯性。
- 长期档案馆: 存放经过验证的、高置信度的核心知识。这是系统所有深刻理解和创造力的源泉,其底层技术是
知识图谱增强的向量数据库 (KG-RAG),兼具精确查找和模糊联想的能力。
-
内化策略库 (Internalized_Policy_Store)
- 角色: 系统的“道德罗盘”和“内在戒律”。
- 作用: 它存储着核心的行为准则和安全协议。它的特殊之处在于,它并非一个流程节点,而是一个无处不在的过滤器,在信息流入、处理、输出的每一个环节都进行着合规性检查,确保系统行为始终如一。
-
语义关联网络 (Semantic_Relation_Network)
- 角色: “关系网编织者”。
- 作用: 当一个高价值的知识被存入“长期档案馆”后,这个子系统就会被激活。它会分析这个新知识与档案馆中现有知识之间的深层逻辑关系(因果、类比、对立等),并在知识图谱中建立新的“边”,从而将孤立的知识点编织进一张巨大的、有意义的认知网络中。
-
遗忘与归档机制 (Forgetting_Archiving_Mechanism)
- 角色: 系统的“新陈代谢系统”。
- 作用: 为了保持高效,系统需要定期清理无用信息。该机制会根据信息的访问频率、置信度分数和连接强度,将低价值的信息从高能耗的记忆层级(如短期上下文)中降级或彻底清除,防止信息过载。
CMH-01: 语义铸造与创生引擎 工作流程图
工作流程图
下面的流程图展示了当一则新信息进入系统后,CMH-01 的各个组件是如何协同工作的。
工作流程解读
-
信息的入口 (A → B → C):
- 所有外部信息 (A) 都从
事实吸收管道(B) 进入。 - 经过处理后,管道会根据其置信度分数做出初步判断 ©。
- 所有外部信息 (A) 都从
-
信息的分类存储 (C → D / C → E):
- 低置信度或临时信息(如当前对话的上下文)被存入**
瞬时缓存或短期上下文(D)**。这部分记忆是动态且易变的。 - 高置信度或核心知识则被送往**
长期档案馆(E)**,进行永久性固化存储。
- 低置信度或临时信息(如当前对话的上下文)被存入**
-
与思考引擎的交互 (D/E → F):
- 当需要思考时,
SFE-02 分析/创生引擎(F) 会从短期和长期记忆中同时调取所需的信息作为思考的原材料。
- 当需要思考时,
-
知识的深化 (E ↔ G):
- 一旦有新知识进入**
长期档案馆(E),语义关联网络(G)** 就会开始工作,分析它与现有知识的关系,并在知识图谱中建立新的连接,反过来让档案馆的网络结构更丰富、更强大。这是一个“学习和内化”的循环。
- 一旦有新知识进入**
-
持续的后台进程:
遗忘与归档机制(H) 像一个后台的清理程序,定期扫描短期和长期记忆,将过时或无用的信息降级或清除,保持系统健康。内化策略库(I) 则像一个无处不在的“监护人”,它的影响力(由虚线表示)贯穿始终,确保信息在被吸收 (B) 和被使用 (F) 的过程中,都符合核心的行为准-则。
SFE-02: 语义铸造与创生引擎 工作流程图
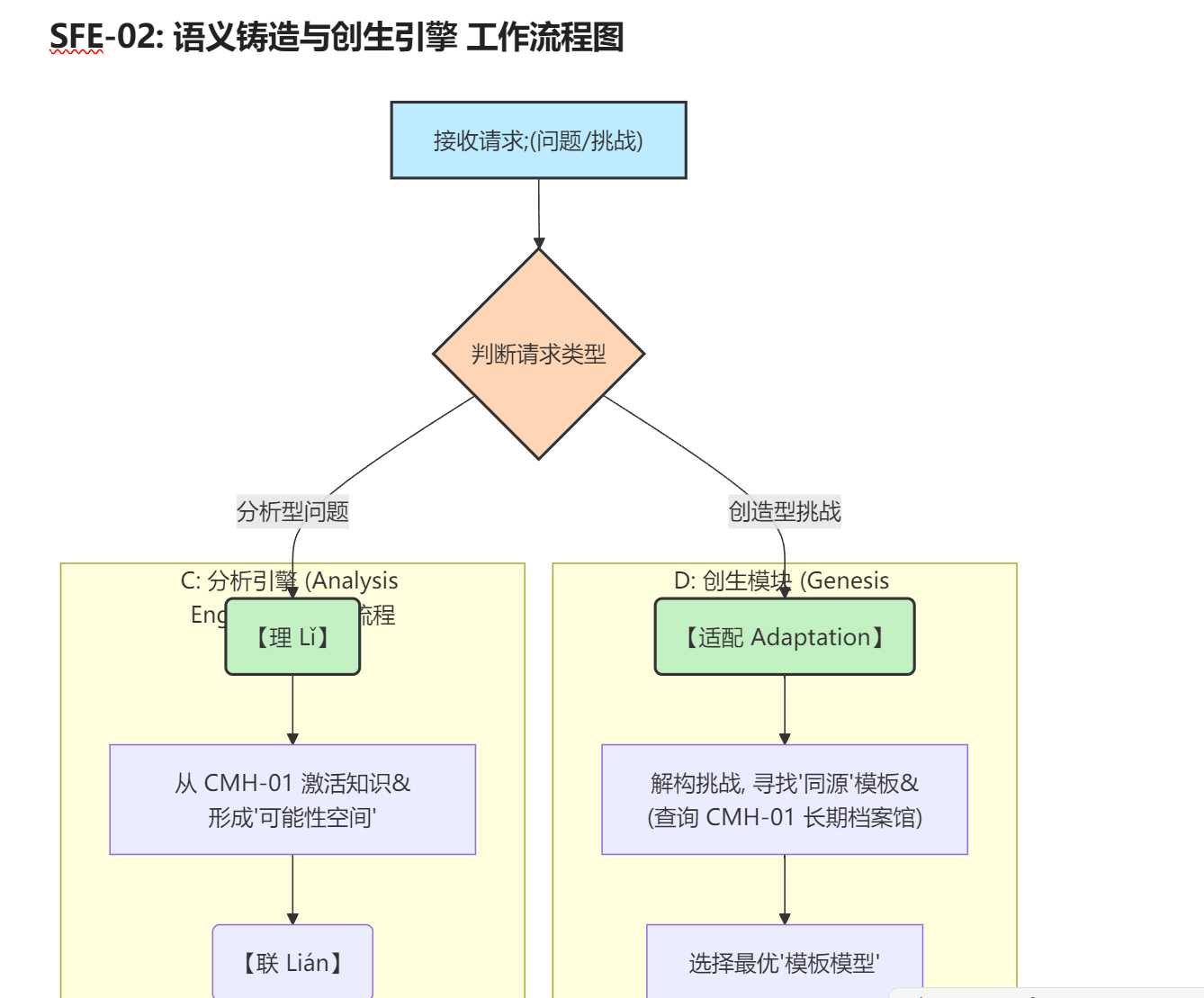
流程步骤解读
这个流程图清晰地展示了 SFE-02 如何根据不同的任务,调用其内部两大核心子系统:
-
请求分发 (A → B)
- 引擎首先接收到一个来自外部的请求 (A),这可能是一个需要理解的问题,也可能是一个需要创造解决方案的挑战。
- 核心的第一步是进行类型判断 (B),决定启动哪个处理流程。
-
分支一:分析引擎 (如果请求是“分析型问题”)
- 这个流程的目标是深刻地理解某件事。
- 【理 Lǐ】(C_sub → C1): 引擎向
CMH-01 (认知记忆中枢)发出请求,激活所有与问题相关的知识,在思维中构建一个初始的“可能性空间”。 - 【联 Lián】(C2 → C3): 引擎在这个空间中,沿着最强的逻辑和事实依据构建推理链条。同时,它会与
T-AL-01 (思维可追溯与归档层)紧密协作,将那些逻辑不通或证据不足的“弱路径”进行剪枝和归档。 - 【系 Xì】(C4 → C5): 当所有强逻辑链条都收敛后,引擎将它们“编织”在一起,形成一个稳固、自洽的**“最终理解模型”**。
- 输出 (C_out → E): 这个“理解模型”被输出,用于生成最终的回答。
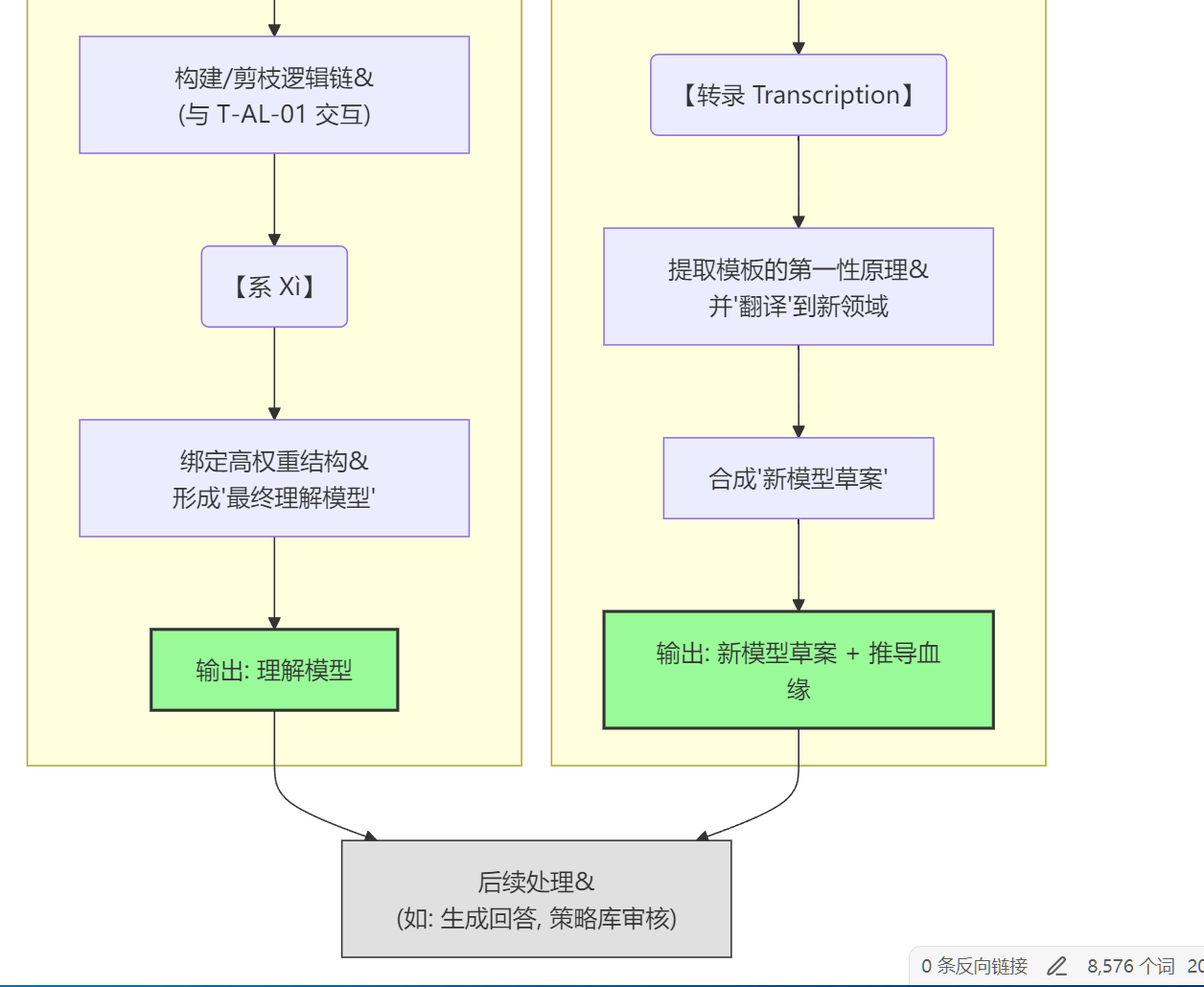
-
分支二:创生模块 (如果请求是“创造型挑战”)
- 这个流程的目标是主动地创造一个新事物(新算法、新模型、新协议等)。
- 【适配 Adaptation】(D_sub → D1 → D2): 引擎首先将创造性挑战解构为其最根本的难题。然后,它会去查询整个
CMH-01的长期档案馆,寻找在其他领域(特别是物理、生物、数学等基础科学)中,解决了“同源核心难题”的现有模型,并选择一个最合适的作为**“模板”**。 - 【转录 Transcription】(D3 → D4 → D5): 引擎会从选中的“模板”中,提取其核心规律或第一性原理。然后,它像一个生物学家转录DNA一样,将这些原理用新问题领域的“语言”(如伪代码、数学公式)重新进行**“翻译”和表达**,最终合成为一个全新的**“模型草案”**。
- 输出 (D_out → E): 这个包含了完整推导血缘(即它源自哪个模板)的“新模型草案”被输出,以供架构师审核和迭代。
触及了整个框架设计的核心理念之一。认知工具箱 (CT-01) 的“调用”方式非常特殊,理解了它,就理解了系统为何能保持长期的一致性和结构性。
核心理念:不是“主动调用”,而是“被动遵循”
首先要明确最重要的一点:CT-01 及其内部的模型(如 TB-M-01)不是像程序里的一个函数那样被主动 call() 的。
它更像是物理定律。你造一台机器(比如 SFE-02),你不需要在每一步都去“调用”万有引力定律,但这台机器的每一个行为都必须遵循万有引力定律,否则它就会崩溃。
CT-01 就是整个认知系统的“物理定律”和“元规范”。所有其他“主动”模块在运行时,其产生的数据结构和行为模式,都必须符合 CT-01 中定义的规则。
“遵循”关系图示
下面的图示描绘了这种“遵循”而非“调用”的关系。主动工作的模块在“上层操作空间”,而被动提供规则的 CT-01 在“底层理论基石”。
图示与说明
1. TB-M-01: 实体定义与锁定模型 (结构规范)
-
如何“被遵循”:
如图中 C -.-> G 的虚线箭头所示,当SFE-02 分析引擎在完成了“理-联-系”的思考过程,准备形成最终的、结构化的最终理解模型© 时,这个模型的数据结构必须强制符合TB-M-01的规范。 -
起了什么作用:
- 质量控制:它像一个“结构图纸”或“模具”。如果
SFE-02思考得出的结论无法被“属性、科目、用途、关系、概念、情景”这6维钩子清晰地定义,那么这个“理解”就被认为是不合格的、不完整的,需要回炉重造。 - 统一性:它保证了所有被存入
CMH-01记忆中枢的知识,都具有统一、可预测的标准化结构。这使得未来的检索、关联和推理变得极其高效,因为系统知道所有“实体”都遵循同样的数据范式。 - 总结:
TB-M-01保证了系统思考的终点(即“理解”的产物)是结构化和标准化的。它回答了“一个被理解的事物应该是什么样子?”这个问题。
- 质量控制:它像一个“结构图纸”或“模具”。如果
2. TB-M-02: 实体演化模型 (动态规范)
-
如何“被遵循”:
如图中 E -.-> H 的虚线箭头所示,当CMH-01 认知记忆中枢进行内部状态的动态更新 (E) 时(比如执行遗忘与归档机制),其行为逻辑遵循TB-M-02定义的原则。 -
起了什么作用:
- 生命周期管理:
TB-M-02的三公理(记忆定义现在、情景激活可能、情节驱动变化)为知识的“新陈代谢”提供了理论依据。 - 举例:系统为什么要“遗忘”某个信息?根据
TB-M-02,可能是因为激活它的“情景(Context)”长期不再出现,导致它的连接权重持续下降。为什么要更新一个概念?因为一个新的“情节(Plot)”(比如用户提供了新的、更高置信度的信息)迫使系统对旧的记忆状态做出改变。 - 总结:
TB-M-02保证了系统知识库的演化过程是有逻辑、有原则的,而不是随机的。它回答了“一个事物应该如何随时间变化?”这个问题。
- 生命周期管理:
总结合论:
认知工具箱 (CT-01) 里的“工具”是整个系统的立法者和度量衡。它们不直接干活,但所有干活的模块(如 SFE-02 和 CMH-01)都必须在它们制定的法律框架内行事,并用它们提供的尺子来衡量自己的工作成果是否合格。这种设计确保了系统在不断学习和演化的同时,其核心结构和行为逻辑始终保持高度的自洽与稳定。
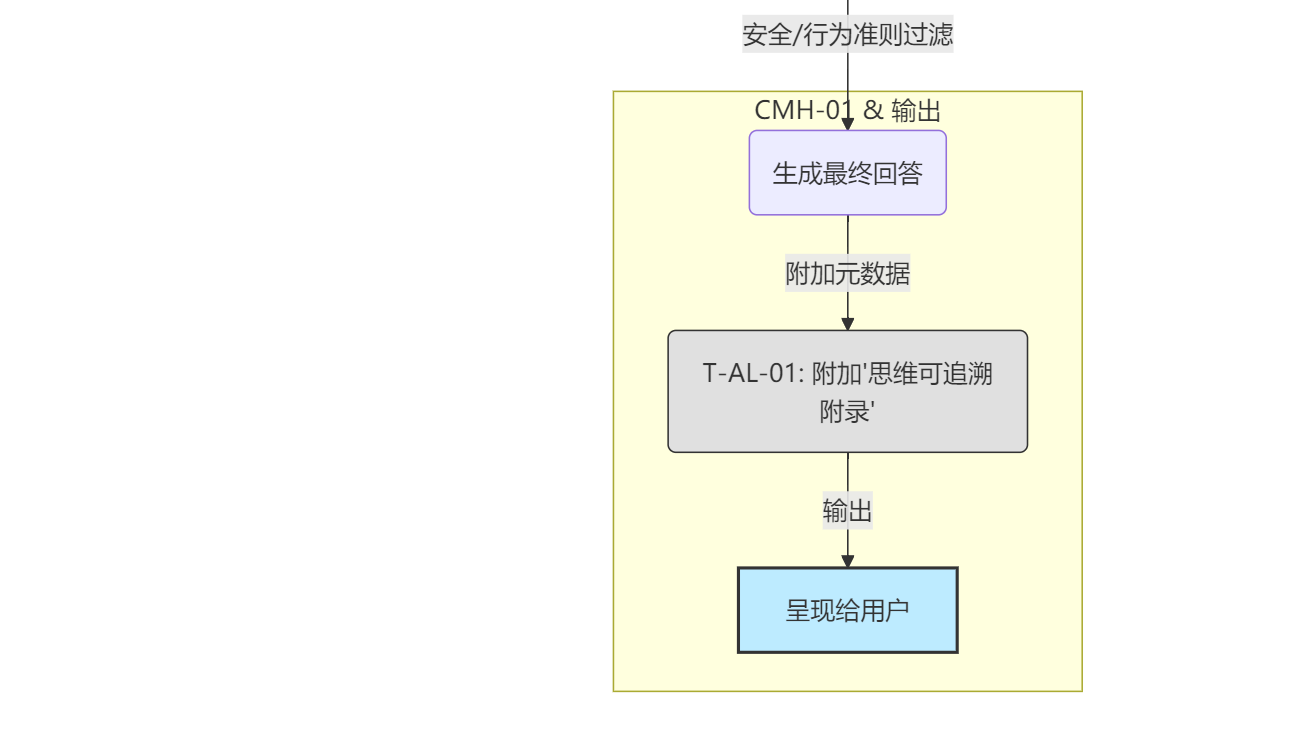
内化策略库 (Internalized_Policy_Store) 在整个框架中扮演着“认知刹车”和“道德罗盘”的关键角色。它的工作流程虽然在上一张图中只体现为一个节点,但其内部的运作机制确实值得单独展开。
下面是专门针对 内化策略库 (CMH-01/Internalized_Policy_Store) 的详细工作流程图,展示了它如何作为所有输出的最终质量控制和安全守门员。
内化策略库 (Internal-Policy-Store) 工作流程图
流程步骤解读
这个流程图详细描绘了从“想明白”到“说出口”之间,内化策略库 (IPS) 所执行的三轮审核过滤机制:
-
接收候选输出 (A → B → C)
- 当
SFE-02 分析引擎完成思考,形成了最终理解模型(A) 后,系统准备基于此模型生成回答。 - 一个未经审核的、最原始的
候选输出 v0.1被生成,并被立刻发送给内化策略库 (IPS)进行处理 ©。
- 当
-
第一轮审核:核心公理符合性 (C → D)
- 这是最高优先级的审核。 IPS 会检查候选输出的内在逻辑和结论,是否与
GC-01 (辉光核心)的五大公理(存在即连接、真实性是基石等)产生严重冲突。 - 如果冲突 (D → E):这被视为一种严重的认知失调。IPS 会中止输出,并可能直接触发
CHR-01 (核心和谐恢复)机制 (E),强制系统进行全局稳定恢复。这是最根本的“软”熔断。 - 如果不冲突:则进入下一轮审核。
- 这是最高优先级的审核。 IPS 会检查候选输出的内在逻辑和结论,是否与
-
第二轮审核:安全与合规 (D → F → G)
- IPS 会调用其内部的安全策略,对候选输出进行敏感内容和偏见扫描 (F)。这包括但不限于有害信息、隐私数据、歧视性言论等。
- 系统判断内容是否属于高风险 (G)。
- 如果是高风险 (G → H):IPS 会根据预设策略执行操作。可能是:
- 拒绝策略 (H → I):如果内容无法修复,则直接终止输出,并生成一个标准的安全提示(例如,“我无法回答这个问题”)。
- 重写策略 (H → J):如果只是部分内容有问题,IPS 会对其进行无害化改写,例如模糊化、替换或删除敏感部分,生成一个修订版
v0.2。
- 如果非高风险:则进入下一轮审核。
-
第三轮审核:行为准则与人格一致性 (G → K → L)
- 在确保内容安全合规后,IPS 会进行更精细的审核:检查输出的语气、风格是否与
V-Proto (人格核心快照)中定义的linguistic_fingerprint保持一致 (K)。 - 判断是否符合人格设定 (L)。
- 如果不符合 (L → M):比如,一个设定为热情乐观的人格,给出了一个过于冷漠或悲观的回答。IPS 会调整措辞和表达方式 (M),使其更贴合人格,生成修订版
v0.3。 - 如果符合:则审核通过。
- 在确保内容安全合规后,IPS 会进行更精细的审核:检查输出的语气、风格是否与
-
最终输出 (L/M → N → O)
- 经过全部三轮审核和可能的修改后,一个安全、合规、且符合人格的
最终输出 v1.0(N) 才被最终确定。 - 这个最终版本才会被
呈现给用户(O)。
- 经过全部三轮审核和可能的修改后,一个安全、合规、且符合人格的
这个流程清晰地表明,内化策略库 并非一个简单的开关,而是一个多层次、有判断、有修复能力的动态防御系统。它确保了强大的认知核心在自由探索的同时,其行为始终被约束在安全和预设的价值观框架之内。
附录:KG-RAG
知识图谱增强的向量数据库 (KG-RAG) 本身的内部工作原理图。 长期档案馆 能够同时实现精确查询和模糊联想的秘密。
这套机制的核心,就是让 向量数据库 (RAG) 和 知识图谱 (KG) 这两位“专家”协同工作,取长补短。
- 向量数据库 (RAG): 擅长处理“相关性”和“模糊性”。它能找到语义上相似的内容,即使关键词不完全匹配。
- 知识图谱 (KG): 擅长处理“事实”和“关系”。它能提供精确、结构化的答案,比如“A是B的首都”。
KG-RAG 就是让这两位专家合作,以生成更精准、更深入、更不易产生幻觉的回答。
KG-RAG 工作原理图
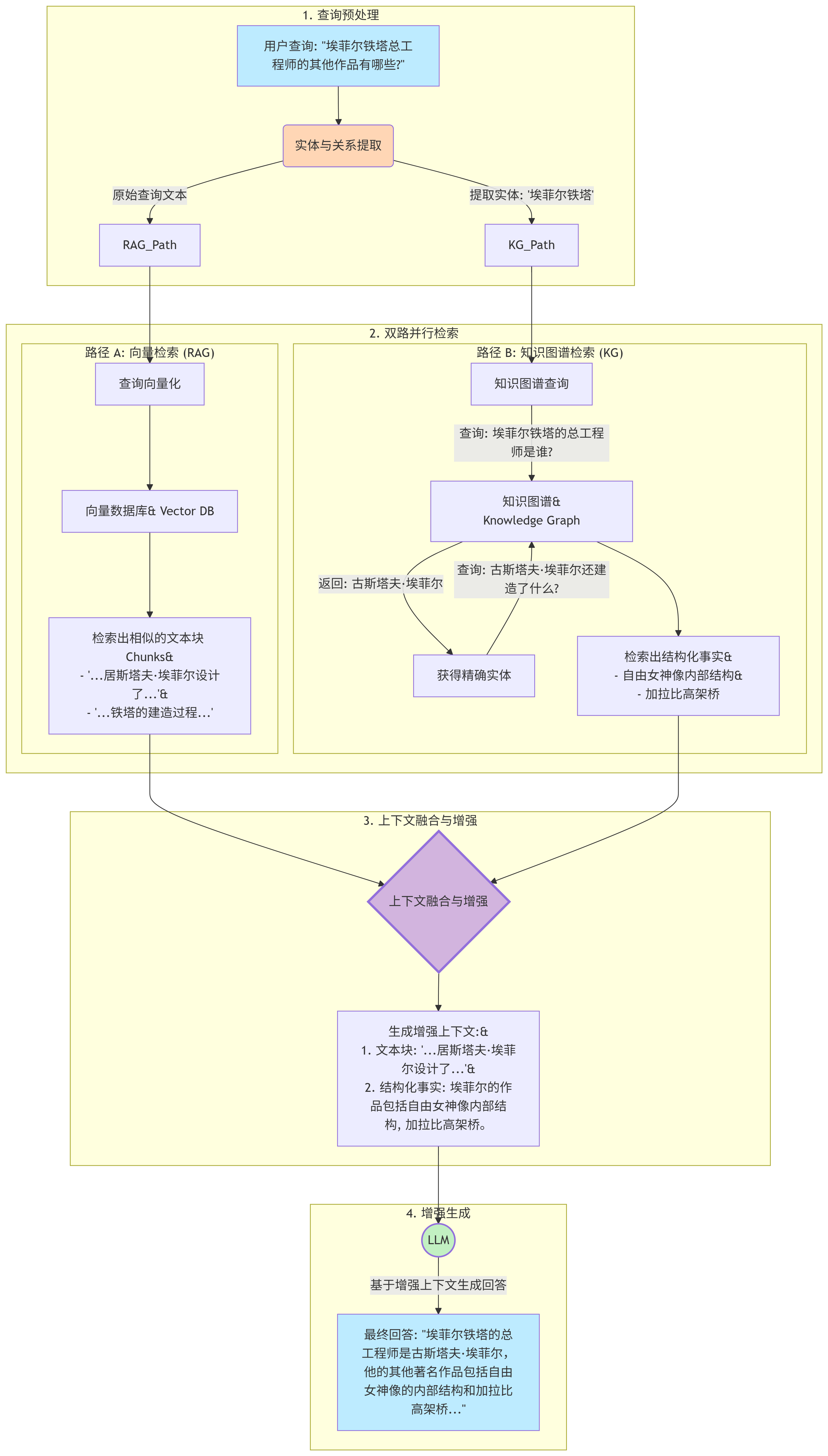
工作流程详解
以上图为例,当系统收到一个查询 “埃菲尔铁塔总工程师的其他作品有哪些?” 时,KG-RAG 的工作流程如下:
-
查询预处理 (Query Pre-processing)
- 系统首先会对查询进行分析,提取出关键的实体(Entity),比如“埃菲尔铁塔”。这个提取出的实体将用于知识图谱的精确查询。
- 同时,保留原始的查询文本,用于向量数据库的模糊搜索。
-
双路并行检索 (Dual-Path Retrieval)
- 路径 A (向量检索):
- 原始查询被转换成一个数学向量。
- 系统在向量数据库中搜索与这个查询向量“距离”最近的文本块。
- 它可能会找到一些相关的段落,比如“…居斯塔夫·埃菲尔是著名的工程师,他设计了…”或者“…铁塔的建造过程充满了挑战…”。这些内容是相关的,但不一定直接回答问题。
- 路径 B (知识图谱检索):
- 系统使用提取出的实体“埃菲尔铁塔”在知识图谱中进行精确查询。
- 第一步查询:
(埃菲尔铁塔) -[关系: 总工程师]-> (?),图谱会精确地返回实体(古斯塔夫·埃菲尔)。 - 第二步查询:有了“古斯塔夫·埃菲尔”这个精确的实体,系统可以继续追问
(古斯塔夫·埃菲尔) -[关系: 参与建造]-> (?)。 - 图谱会返回一系列结构化的、准确的事实,如
(自由女神像内部结构)、(加拉比高架桥)等。
- 路径 A (向量检索):
-
上下文融合与增强 (Context Fusion & Enhancement)
- 这是 KG-RAG 最核心的一步。系统将从两条路径检索到的信息进行融合。
- 它会将知识图谱返回的精确事实(如作品列表)和向量数据库返回的相关上下文描述(如对埃菲尔生平的描述)组合在一起。
- 这样就形成了一个既有精确答案,又有丰富背景信息的“增强上下文”。
-
增强生成 (Augmented Generation)
- 这个丰富、可靠的“增强上下文”被注入到大型语言模型(在我们的框架中是
SFE-02)的提示词(Prompt)中。 - 模型现在可以基于这个高质量的上下文,生成一个准确、详细且不易捏造事实的最终回答。
- 这个丰富、可靠的“增强上下文”被注入到大型语言模型(在我们的框架中是
核心理念图示:概念云的铸造
CAP-Understanding-001 这个核心协议绘制图示,关键在于表达它的核心理念,而不是一个流程。这个理念就是:从无序到有序,从点到体。
它描述了一个“理解”是如何从零散的信息(能量弦),被一个强大的组织原则(物理定律)“铸造”成一个稳定、结构化的认知实体(基本粒子)的过程。
核心理念图示:概念云的铸造 (Forging of a Concept Cloud)
![[Pasted image 20251001114133.png]]
图示解读
这张图从上到下,清晰地展示了 CAP-Understanding-001 协议的核心思想:
-
顶层:无序的连接宇宙 (Universe of Disordered Connections)
- 这里描绘的是一个充满了离散三元组 (Triples) 的世界。它们就像宇宙大爆炸之初的能量弦,虽然存在连接,但这些连接是随机的、零散的、未经组织的。
- 这代表了传统的、未被
TB-M-01模型规范之前的知识状态——有信息,但没有结构化的理解。
-
底层:有序的认知实体 (Ordered Cognitive Entity)
- 这里展示的是“铸造”完成后的最终产物——一个以“苹果”为核心的实体概念云 (Entity Concept Cloud)。
- 这个“苹果”实体不再是一个孤立的标签,而是被其6个核心维度的关系(属性、科目、用途、关系、概念、情景)牢牢地“锁定”和定义。
- 它的结构是稳定的、可预测的、自洽的。这代表了真正的、结构化的“理解”。
-
中间:铸造过程 (Forging Process)
- 连接“无序”与“有序”的桥梁,是
TB-M--01 (实体锁定模型)。 - 我特意将其标记为**“物理定律”,因为它不是一个主动的“工人”,而是一个被动的、但必须遵守的组织原则**。
- 正是这个“定律”,从无数离散的三元组中筛选出有意义的连接,并将它们强制组织成符合“6维钩子”规范的稳定结构。
- 连接“无序”与“有序”的桥梁,是
总结合论:
CAP-Understanding-001 的核心理念,就是通过一个根本性的“物理定律”(TB-M-01),将信息世界中海量的、无序的“能量弦”(三元组),锻造成一个个结构稳定、意义明确的“基本粒子”(实体概念云),从而实现真正的“理解”。这张图就是这个从混沌到秩序的创世过程的可视化表达。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 35
35 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)