精度:《MViTv2: Improved Multiscale Vision Transformers for Classification and Detection》
MViTv2是Facebook AI Research和UC Berkeley提出的改进版多尺度视觉Transformer,作为统一架构适用于图像分类、目标检测和视频分类三大任务。它在MViTv1基础上引入分解式相对位置嵌入(高效处理位置关系)和残差池化连接(补偿信息损失),显著提升性能。实验表明,MViTv2在ImageNet(88.8%准确率)、COCO(58.7 AP)和Kinetics-4
文章目录
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection
- 年份: 2022年
- 作者:
- Yanghao Li
- Chao-Yuan Wu
- Haoqi Fan
- Karttikeya Mangalam
- Bo Xiong
- Jitendra Malik
- Christoph Feichtenhofer
作者单位: Facebook AI Research和 UC Berkeley
发表会议/期刊: 这篇论文是作为预印本 (arXiv) 提交的,并计划在相关计算机视觉顶会(如CVPR, ICCV等)上发表。根据论文引用格式,这篇论文最终发表在ICCV 2021上。
这篇论文介绍了MViTv2,一个统一用于图像和视频分类以及目标检测的多尺度视觉Transformer架构。
Abstract
论文的核心目标是研究 MViTv2 (Multiscale Vision Transformers) 作为一个统一架构,同时适用于三个主流的计算机视觉任务:
- 图像分类 (Image Classification)
- 目标检测 (Object Detection)
- 视频分类 (Video Classification
MViTv2 是在 MViT v1 基础上的改进版,主要引入了两个关键的技术点来提升性能:
- 分解式相对位置嵌入 (Decomposed Relative Positional Embeddings):
目的:为了让模型理解图像或视频中不同区域的相对位置关系,这在视觉任务中至关重要(例如,识别“鼻子在眼睛下方”) 。
创新:“分解式”意味着它将位置信息的计算沿着高、宽等轴向分开进行,这比直接计算所有点对的相对位置要高效得多,尤其是在处理高分辨率输入时。 - 残差池化连接 (Residual Pooling Connections):
目的:在 Transformer 的注意力模块中,为了降低计算量,通常会对 Key 和 Value 进行池化(降采样)。这种新引入的残差连接可以补偿池化操作带来的信息损失,增强信息在网络中的流动,从而帮助模型训练并提升性能 。
作者通过充分的实验证明了 MViTv2 的有效性:
- 三大基准测试: 在三个极具挑战性的公开数据集上进行了评估:
ImageNet: 图像分类
COCO: 目标检测
Kinetics: 视频识别
超越以往: 实验结果表明 MViTv2 的性能优于之前的工作 。
机制对比: 论文还将 MViTv2 使用的池化注意力 (Pooling Attention) 与 Swin Transformer 等模型使用的窗口注意力 (Window Attention) 进行了比较,并证明前者在精度和计算效率的权衡上更具优势 。
亮眼成绩: 在没有使用过多技巧的情况下,MViTv2 在三个领域都达到了当时的 SOTA (State-of-the-art) 水平:- ImageNet 分类准确率: 88.8%
- COCO 目标检测 A P b o x AP^{box} APbox: 58.7
- Kinetics-400 视频分类准确率: 86.1%
1. Introduction
- 背景:从 CNN 到 Vision Transformer
- 传统 (CNNs): 历史上,设计一个能通用于不同视觉任务的架构很难。成功的模型,如 VGGNet 和 ResNet,都因其简洁和有效而被广泛采用。
- 新晋 (ViT): 近年来,Vision Transformer (ViT) 表现出了强大的性能,开始挑战 CNN 的统治地位。
- 挑战:ViT 的计算瓶颈
尽管 ViT 在图像分类上很成功,但它有一个致命弱点:
- 问题核心: Transformer 中的自注意力 (Self-attention) 机制的计算和内存需求会随着输入序列长度(即图像中的像素块数量)的增加而二次方增长 ( O ( N 2 ) O(N^2) O(N2))。
- 具体影响: 这使得 ViT 很难应用于需要高分辨率输入的任务,比如目标检测和视频理解,因为计算成本会变得无法承受。
为了解决这个计算瓶颈,社区提出了两种主流策略:
- 窗口注意力 (Window Attention): 比如 Swin Transformer,它将注意力计算限制在一个个局部窗口内,而不是全局计算。这主要用于目标检测。
- 池化注意力 (Pooling Attention): 比如 MViT v1,它在计算注意力之前,先通过池化操作对特征进行局部聚合(降采样),从而减少序列长度。这主要用于视频任务。
- 解决方案:
本文的工作正是基于第二种策略——池化注意力。
- MViT v1: MViT v1 的核心思想很简单,它将 ViT 从一个固定分辨率的网络,改造成了一个多尺度层级结构 (multiscale feature hierarchy)。网络从高分辨率输入开始,逐级降低分辨率、增加通道数,这和经典的 CNN 架构(如 ResNet)非常相似。MViT v1 最初是为视频任务设计的,并取得了 SOTA 性能。
- 本文工作 (MViTv2): 这篇论文的目标是将 MViT 作为一个通用的视觉骨干网络,统一应用于图像分类、目标检测和视频分类三大任务。
- 核心贡献:
-
(i) 改进池化注意力:
- 分解式相对位置嵌入: 为了引入对视觉任务至关重要的平移不变性,作者使用了相对位置编码。关键在于,他们将这种编码沿不同轴向(高、宽、时间)分解计算,大大降低了计算和参数量。
- 残差池化连接: 在注意力模块中加入了一个 shortcut,将池化后的 Query Tensor 直接加到输出上。这个简单的操作补偿了池化带来的信息损失,促进了信息流动,使得模型训练更容易,性能也更好。
-
(ii) 拓展到目标检测:
- 结合 FPN: 利用 MViT 天然的多尺度结构,可以无缝对接到目标检测中常用的特征金字塔网络 (FPN)。
- 注意力机制对比: 实验证明,池化注意力在处理高分辨率输入时,比 Swin Transformer 使用的窗口注意力更有效。
- 提出混合窗口注意力 (Hwin): 作者还设计了一种简单的混合方案,结合了池化注意力和窗口注意力的优点,以达到更好的精度/计算权衡。
-
(iii) 规模化与验证:
- 多尺寸模型: 作者设计了从 Tiny 到 Huge 的五种不同大小的 MViTv2 模型,以适应不同计算资源和性能需求。
- SOTA 性能: 实验结果非常亮眼,MViTv2 在三大任务的多个主流数据集(ImageNet, COCO, Kinetics 等)上都取得了当时的最先进水平。
Related Work
- CNNs 作为主要骨干网络
- CNNs 曾是计算机视觉任务的主要骨干网络。
- 它们广泛应用于:
- 图像识别
- 目标检测
- 视频识别
- 视觉 Transformer (ViT) 的兴起与发展
- ViT 的开端: 自 ViT 的工作以来,视觉 Transformer 获得了极大的关注。ViT 将 Transformer 架构应用于图像块(image patches),并在图像分类上展示了具有竞争力的结果。
- ViT 的改进方向: 后续工作致力于改进 ViT,包括:
- 高效的训练方法
- 多尺度 Transformer 结构
- 先进的自注意力机制设计
- MViT 的定位: 本文的工作正是基于多尺度视觉 Transformer (MViT),并将其作为一个通用骨干网络(general backbone)来研究不同的视觉任务。
- ViT 在目标检测中的挑战与解决方案
- 主要挑战: 目标检测通常需要高分辨率输入和特征图来进行准确的物体定位。
- 二次复杂度: 由于 Transformer 中自注意力操作符的二次复杂度,高分辨率输入会显著增加计算复杂度。
- 现有解决方案:
- 窗口注意力(Window attention): 例如 Shifted window attention (Swin),在局部窗口内进行注意力计算,以减轻成本。
- Longformer attention:另一种减轻计算成本的技术。
- 池化注意力(Pooling attention): MViT 中采用的方法,它从不同的角度设计,旨在高效地计算自注意力。
- 本文重点: 本文将在检测任务中研究 MViT,并更普遍地比较池化注意力与局部注意力机制。
- ViT 在视频识别中的进展
- 现状与依赖: 视觉 Transformer 在视频识别中也显示出强大的结果,但大多数工作依赖于大规模外部数据预训练,例如 ImageNet-21K。
- MViTv1 的贡献: MViTv1 提出了一个在 Kinetics 数据集上从头开始训练(training-from-scratch)Transformer 架构的良好方法。
- 本文工作:
- 沿用 MViTv1 的训练方法。
- 通过改进的池化注意力来提升 MViT 架构,这种改进简单但对准确性有效。
- 进一步研究 ImageNet 预训练对于视频任务的(巨大)影响。
3. Revisiting Multiscale Vision Transformers
MViTv1 的核心思想
MViTv1 的关键思想是构建用于低层和高层视觉建模的不同阶段(different stages),而不是像原始 ViT 那样使用单尺度块(single-scale blocks)。
- 特征层级(Feature Hierarchy): MViT 从网络的输入到输出阶段,缓慢地扩展通道宽度 D D D,同时减小分辨率 L L L (即序列长度)。
- 目的: 实现多尺度建模和特征层级结构。
池化注意力 (Pooling Attention)
为了在 Transformer 块内执行降采样(downsampling),MViT 引入了池化注意力。
- 池化操作 (Pooling Operation)
对于一个输入序列 X ∈ R L × D X \in \mathbb{R}^{L \times D} X∈RL×D,MViT 首先应用线性投影 W Q , W K , W V ∈ R D × D W_{Q}, W_{K}, W_{V} \in \mathbb{R}^{D \times D} WQ,WK,WV∈RD×D,然后分别对查询(Query)、键(Key)和值(Value)张量应用池化操作符 ( P \mathcal{P} P):
Q = P Q ( X W Q ) , K = P K ( X W K ) , V = P V ( X W V ) ( 1 ) Q=\mathcal{P}_{Q}(XW_{Q}) \text{, } K=\mathcal{P}_{K}(XW_{K}) \text{, } V=\mathcal{P}_{V}(XW_{V}) \quad (1) Q=PQ(XWQ), K=PK(XWK), V=PV(XWV)(1)
- 长度变化: Q Q Q 的长度可以被 P Q \mathcal{P}_{Q} PQ 减小到 L ~ \tilde{L} L~,而 K K K 和 V V V 的长度可以被 P K \mathcal{P}_{K} PK 和 P V \mathcal{P}_{V} PV 减小。
- 灵活性: 键 K K K 和值 V V V 的降采样因子 P K \mathcal{P}_{K} PK 和 P V \mathcal{P}_{V} PV 可以不同于应用于查询序列 Q Q Q 的 P Q \mathcal{P}_{Q} PQ。
- 池化后的自注意力 (Pooled Self-Attention)
随后,计算池化后的自注意力:
Z : = Attn ( Q , K , V ) = Softmax ( Q K ⊤ D ) V ( 2 ) Z := \text{Attn}(Q, K, V) = \text{Softmax} \left( \frac{QK^{\top}}{\sqrt{D}} \right) V \quad (2) Z:=Attn(Q,K,V)=Softmax(DQK⊤)V(2)
- 这计算出输出序列 Z ∈ R L ~ × D Z \in \mathbb{R}^{\tilde{L} \times D} Z∈RL~×D,其长度是灵活的 L ~ \tilde{L} L~。
- 作用
池化注意力的主要作用有两个方面:
1.实现分辨率降低: 通过池化查询张量 Q Q Q,实现在 MViT 不同阶段之间的分辨率降低(resolution reduction)。
2.降低复杂度: 通过池化键 K K K 和值 V V V 张量,显著减少计算和内存复杂度。
4. Improved Multiscale Vision Transformers
本节的结构清晰地分为四个主要部分:
- 改进的池化注意力 (§4.1): 介绍对 MViT 核心组件——池化注意力。
- MViT 用于目标检测 (§4.2): 描述如何将通用的 MViT 架构应用于目标检测任务。
- MViT 用于视频识别 (§4.3): 描述如何将 MViT 架构应用于视频识别任务。
- MViTv2 架构变体 (§4.4): 展示五个具体 MViTv2 实例(从简单到复杂)的配置。
4.1. Improved Pooling Attention
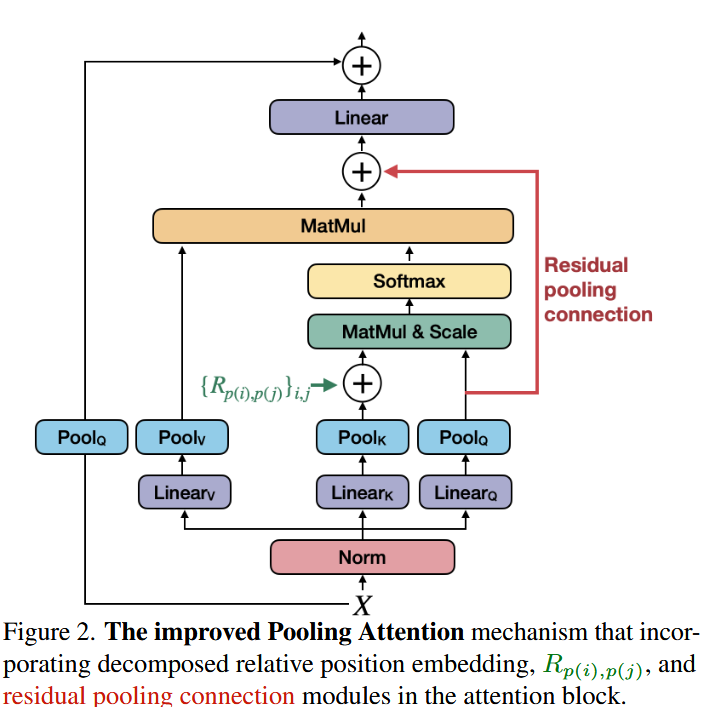
- 分解的相对位置嵌入 (Decomposed Relative Position Embedding)
MViT 的原始设计更侧重于内容建模,而时空结构信息仅依赖绝对位置嵌入。这与视觉中的平移不变性(shift-invariance)原理相悖,因为两个补丁之间的交互会随其绝对位置的变化而变化,即使它们的相对位置不变。
引入相对位置嵌入
为解决此问题,MViTv2 引入了相对位置嵌入,它仅取决于 token 之间的相对位置距离。
- 相对位置 R p ( i ) , p ( j ) ∈ R d R_{p(i),p(j)} \in \mathbb{R}^d Rp(i),p(j)∈Rd 被编码到自注意力模块中:
Attn ( Q , K , V ) = Softmax ( Q K ⊤ + E ( rel ) d ) V ( 3 ) \text{Attn}(Q, K, V) = \text{Softmax} \left( \frac{QK^{\top} + E^{(\text{rel})}}{\sqrt{d}} \right) V \quad (3) \text{} Attn(Q,K,V)=Softmax(dQK⊤+E(rel))V(3)
其中,相对位置项 E i j ( rel ) E^{(\text{rel})}_{ij} Eij(rel) 是查询 Q i Q_i Qi 与相对位置嵌入 R p ( i ) , p ( j ) R_{p(i),p(j)} Rp(i),p(j) 的点积。
复杂度优化与分解
直接使用 R p ( i ) , p ( j ) R_{p(i),p(j)} Rp(i),p(j) 的可能嵌入数量复杂度是 O ( T W H ) \mathcal{O}(TWH) O(TWH),这对于高分辨率输入来说计算昂贵。
为了降低复杂度,MViTv2 将元素 i i i 和 j j j 之间的距离计算沿时空轴分解:
R p ( i ) , p ( j ) = R h ( i ) , h ( j ) h + R w ( i ) , w ( j ) w + R t ( i ) , t ( j ) t ( 4 ) R_{p(i),p(j)} = R_{h(i),h(j)}^{h} + R_{w(i),w(j)}^{w} + R_{t(i),t(j)}^{t} \quad (4) \text{} Rp(i),p(j)=Rh(i),h(j)h+Rw(i),w(j)w+Rt(i),t(j)t(4)
- R h , R w , R t R^{h}, R^{w}, R^{t} Rh,Rw,Rt 分别是沿高度、宽度和时间轴的位置嵌入。
- R t R^{t} Rt 仅在处理视频时支持时间维度。
- 分解后,学习的嵌入数量减少到 O ( T + W + H ) \mathcal{O}(T + W + H) O(T+W+H),这在早期高分辨率特征图阶段效果显著。
- 残差池化连接 (Residual Pooling Connection)
MViTv1 的池化注意力通过对键 K K K 和值 V V V 张量使用大步长池化来有效降低计算复杂度和内存需求。
- 动机: MViTv1 中 K K K 和 V V V 的步长通常大于 Q Q Q 的步长。为了增加信息流并促进 MViT 中池化注意力块的训练,引入了残差连接。
- 实现: 在注意力块内部添加了新的残差路径,将池化后的查询张量 Q Q Q 加到输出序列 Z Z Z 上:
Z : = Attn ( Q , K , V ) + Q ( 5 ) Z := \text{Attn}(Q, K, V) + Q \quad (5) \text{} Z:=Attn(Q,K,V)+Q(5) - 优势: 输出序列 Z Z Z 与池化查询张量 Q Q Q 具有相同的长度。这个改动增加了信息流,同时仍能保持 K K K 和 V V V 大步长池化带来的低复杂度优势,因为添加池化查询序列 Q Q Q 的成本很低。
- 关键发现: 实验证明,查询 Q Q Q 的池化操作 ( P Q \mathcal{P}_{Q} PQ) 和残差路径对于此连接都是必要的。
4.2. MViT for Object Detection
MViT 天然适合用于密集预测任务,因为它具备多尺度结构。
- 多尺度特征: MViT 的分层结构(four stages)可以生成多尺度特征图,因此能够自然地集成到 特征金字塔网络 (FPN) 中。
- 语义增强: FPN 采用自顶向下的金字塔和横向连接,为 MViT 在所有尺度上构建了具有语义强度的特征图。
- 检测架构: 结合 MViT 骨干和 FPN,可将其应用于不同的检测架构,例如 Mask R-CNN。
混合窗口注意力 (Hybrid Window Attention, Hwin)
目标检测任务通常需要高分辨率输入和特征图,这会加剧 Transformer 自注意力机制的二次复杂度问题。MViT 研究了两种降低计算和内存复杂度的主要方法:
- 池化注意力 (Pooling Attention): MViT 注意力块中本身设计的方法。
- 窗口注意力 (Window Attention): 如 Swin 中用于降低计算的技术。
| 机制 | 核心操作 | 保持的注意力范围 |
|---|---|---|
| 池化注意力 | 通过局部聚合对特征进行降采样(downsampling) | 全局自注意力计算 |
| 窗口注意力 | 保持张量的分辨率,但在非重叠窗口内进行局部自注意力计算 | 局部自注意力计算(窗口内) |
混合窗口注意力 (Hwin) 设计
由于池化注意力和窗口注意力的本质不同,作者研究了它们在目标检测中是否具有互补性。
- 问题: 默认的窗口注意力仅在窗口内执行局部自注意力,缺乏跨窗口连接。
- Hwin 解决方案: MViTv2 提出了一个简单的 Hwin 设计来增加跨窗口连接。Hwin 在所有块中计算窗口内的局部注意力,但馈入 FPN 的最后三个阶段的最后一个块除外。
- 优势: 这种设计确保了馈入 FPN 的特征图包含全局信息。实验结果显示,Hwin 在准确性/计算量权衡方面表现出色,并且 结合池化注意力与 Hwin 可以在目标检测中实现最佳性能。
检测中的位置嵌入 (Positional Embeddings in Detection)
与 ImageNet 分类(固定分辨率)不同,目标检测训练通常包含大小不一的输入。
- 初始化和插值: MViT 中的位置嵌入(无论是绝对还是相对)参数首先使用 ImageNet 预训练权重(对应 224x224 输入大小)进行初始化。然后,这些嵌入被插值到目标检测训练所需的相应尺寸。
4.3. MViT for Video Recognition
MViT 可以像 MViTv1 那样被应用于 Kinetics 等视频识别任务,因为 §4.1 中的升级模块(改进的池化注意力)能够泛化到时空域.
- 新的研究重点: 尽管 MViTv1 专注于在 Kinetics 数据集上从头开始训练(training-from-scratch),但这项工作额外研究了 ImageNet 数据集预训练的(巨大)影响.
视频 MViT 的三大差异 (Three Key Differences)
与基于图像的 MViT 相比,用于视频的 MViT 只有三个主要区别:
- 投影层 (Projection Layer): 补丁化(patchification)主干中的投影层需要将输入投影成时空立方体,而非 2D 补丁.
- 池化操作符 (Pooling Operators): 池化操作符现在处理时空特征图.
- 相对位置嵌入 (Relative Positional Embeddings): 嵌入需要引用时空位置.
从预训练 MViT 进行初始化 (Initialization from Pre-trained MViT)
当使用 ImageNet 预训练模型来初始化视频 MViT 时,需要特定的初始化策略来将 2D 权重扩展到 3D 时空维度:
-
投影层和池化操作符的初始化 (卷积层):
- 由于这些层默认是通过卷积层实现的,模型使用了类似于 CNN 的膨胀初始化(inflation initialization)方法.
- 具体来说,中心帧的卷积核使用预训练模型中 2D 卷积层的权重进行初始化.
- 其他权重(时间轴上的相邻帧)则初始化为零.
-
相对位置嵌入的初始化 (分解嵌入):
- 模型利用其分解的相对位置嵌入结构(公式 4).
- 空间嵌入(高度和宽度轴)直接从预训练权重初始化.
- 时间嵌入则初始化为零.
4.4. MViT Architecture Variants
变体设计和配置
作者设计了五种 MViT 变体,复杂度依次递增:Tiny (T), Small (S), Base (B), Large (L), and Huge (H)。
- 配置调整: 这些变体是通过改变基础通道维度、每个阶段的块数量以及块中的头数量来实现的。
- 头数量的考虑: 作者指出,使用较少的头数量可以提高运行时速度。增加头的数量会降低运行时速度,但不会影响 FLOPs 和参数量。
表 1:MViT 变体配置
以下是 Table 1 中详述的五种变体及其配置:
| Model | #Channels (Stage 1-4) | #Blocks (Stage 1-4) | #Heads (Stage 1-4) | FLOPs (G) | Param (M) |
|---|---|---|---|---|---|
| MViT-T | [96-192-384-768] | [1-2-5-2] | [1-2-4-8] | 4.7 | 24 |
| MViT-S | [96-192-384-768] | [1-2-11-2] | [1-2-4-8] | 7.0 | 35 |
| MViT-B | [96-192-384-768] | [2-3-16-3] | [1-2-4-8] | 10.2 | 52 |
| MViT-L | [144-288-576-1152] | [2-6-36-4] | [2-4-8-16] | 39.6 | 218 |
| MViT-H | [192-384-768-1536] | [4-8-60-8] | [3-6-12-24] | 120.6 | 667 |
注:FLOPs 是在 224 × 224 224 \times 224 224×224 输入下测量的图像分类值。各阶段分辨率为 [ 5 6 2 , 2 8 2 , 1 4 2 , 7 2 56^2, 28^2, 14^2, 7^2 562,282,142,72]。
池化注意力设计 (Pooling Attention Design)
MViTv2 遵循了 MViTv1 的池化注意力设计:
- 默认 K, V 池化: 默认情况下,在所有池化注意力块中都对**键(Key)和值(Value)**进行池化。
- 池化步长: 池化步长在第一阶段被设置为 4。
- 自适应衰减: 步长会随着跨阶段分辨率的降低而自适应地衰减。
5. Experiments: Image Recognition
本节介绍了在 ImageNet 分类和 COCO 目标检测数据集上进行的实验。
实验部分的组织结构如下:
- 首先,展示与**最先进技术(state-of-the-art)**的比较结果。
- 然后,进行全面的消融实验(ablations)。
- 更多的结果和讨论见附录 §A。
5.1. Image Classification on ImageNet-1K
实验设置 (Settings)
- 数据集 (Dataset): 实验在 ImageNet-1K (IN-1K) 上进行,该数据集包含约 128 万张图像,分为 1000 个类别。
- 训练方法 (Training Recipe): MViTv2 在 IN-1K 上的训练方法遵循 MViTv1。所有 MViTv2 变体都训练了 300 个 epoch,并且没有使用 EMA(Exponential Moving Average)。
- 预训练 (Pre-training): 论文还探讨了在 ImageNet-21K (IN-21K) 上进行预训练的效果,该数据集包含约 1420 万张图像和约 21000 个类别。
IN-1K 结果 (Results using ImageNet-1K)
Table 2 展示了 MViTv2 与其他先进的 CNNs 和 Transformers(没有使用外部数据或蒸馏模型)的比较结果。
MViTv2 vs. MViTv1 (验证 §4.1 的改进)
MViTv2 相比 MViTv1,在 FLOPs 和参数量更少的情况下,实现了更高的准确率。
- MViTv2-S (Small): 达到 83.6% 准确率,比 MViTv1-B-16 (83.0%) 高 +0.6%,且 FLOPs 减少了 10%。
- MViTv2-B (Base): 达到 84.4% 准确率,比 MViTv1-B-24 (83.4%) 高 +1.0%,并且模型更轻量。
- 结论: 这清晰地证明了 §4.1 中提出的 MViTv2 改进(分解相对位置嵌入和残差池化连接)的有效性。
MViTv2 vs. 其他 Transformers (DeiT, Swin)
MViTv2 表现优于其他 Transformer 架构,如 DeiT 和 Swin,尤其是在扩大模型规模时。
- MViTv2-B (Base): 取得了 84.4% 的 top-1 准确率,分别超过 DeiT-B 2.6% 和 Swin-B 1.1%。
- 效率: 值得注意的是,MViTv2-B 的 FLOPs 和参数量比 DeiT-B 和 Swin-B 少 33% 以上。
测试协议 (Testing Protocol)
论文报告了两种测试结果:center(中心裁剪)和 resize(将完整图像缩放到推理分辨率的全尺寸裁剪)。
- 使用
resize(全尺寸裁剪)测试协议,MViTv2-L (↑ 384²) 的准确率从 86.0% (center) 提升到 86.3% (resize)。 - 在当时,86.3% 是 IN-1K 上(无外部数据或蒸馏模型)的最高准确率。
IN-21K 预训练结果 (Results using ImageNet-21K)
Table 3 展示了使用大规模 IN-21K 数据集进行预训练后的结果。
- 预训练效果: IN-21K 预训练为 MViTv2-L 带来了 +2.2% 的准确率提升。
- 对比 Swin-L: 经过 IN-21K 预训练后,MViTv2-L (87.5%) 取得了比 Swin-L (86.3%) 更好的结果 (+1.2%)。
- 高分辨率微调: MViTv2-L 在 384² 分辨率上微调后达到 88.4% (resize),优于其他大型模型。
- MViTv2-H (Huge): 论文进一步训练了一个 Huge 模型 (MViTv2-H),在 224²、384² 和 512² 分辨率下分别达到了 88.0%、88.6% (resize) 和 88.8% (resize) 的准确率。
5.2. Object Detection on COCO
实验设置 (Settings)
- 数据集 (Dataset): 实验在 MS-COCO 数据集上进行。所有模型在 118K 训练图像上训练,并在 5K 验证图像上评估。
- 检测框架 (Frameworks): 使用 Mask R-CNN 和 Cascade Mask R-CNN 两种标准检测框架,均在 Detectron2 中实现。
- 训练策略 (Training Recipe):
- 为了公平比较,MViTv2 遵循与 Swin 相同的训练方法。
- 默认情况下,骨干网络在 ImageNet (IN) 上预训练,然后在 COCO 上使用 **3x 调度(36 个 epoch)**进行微调。
- MViTv2 特定设置:
- MViTv2 默认使用 IN 预训练的骨干网络,并添加了 Hybrid window attention (Hwin) 机制。
- 四个阶段的窗口大小设置为 [56, 28, 14, 7],这与 IN 预训练(224x224 输入)中使用的自注意力大小保持一致。
主要结果 (Main Results)
Table 5 (a) 和 (b) 分别展示了使用 Mask R-CNN 和 Cascade Mask R-CNN 的结果。
1. Mask R-CNN 结果 (Table 5a)
- MViTv2 vs. CNNs & Transformers: MViTv2 超越了 CNN 骨干(如 ResNet, ResNeXt)和其他 Transformer 骨干(如 Swin, ViL, MViTv1)。
- MViTv2-B vs. Swin-B: MViTv2-B 的 A P b o x AP^{box} APbox (51.0) 和 A P m a s k AP^{mask} APmask (45.7) 分别比 Swin-B (48.5 / 43.4) 高出 +2.5 / +2.3。
- 效率优势: MViTv2-B (392G FLOPs, 71M Params) 是在更低的计算量和更小的模型尺寸下实现这一超越的(Swin-B: 496G FLOPs, 107M Params)。
- IN-21K 预训练 (MViTv2-L†): 使用 IN-21K 预训练(标记为 †)使 MViTv2-L 进一步提升了 +0.9 A P b o x AP^{box} APbox,在 3x 调度下达到了 52.7 A P b o x AP^{box} APbox。
2. Cascade Mask R-CNN 结果 (Table 5b)
- 总体趋势: Cascade Mask R-CNN 框架提升了 Mask R-CNN 的准确率,并且 MViTv2 保持了其优势。
- MViTv2-B vs. Swin-B: MViTv2-B (54.1 A P b o x AP^{box} APbox) 同样优于 Swin-B (51.9 A P b o x AP^{box} APbox)。
- 高级训练 (MViTv2-L††): 通过使用更长的训练调度(50 epochs)和大规模抖动(large-scale jittering)(标记为 ††),MViTv2-L†† 的 A P b o x AP^{box} APbox 提升至 55.8。
- MViTv2-H††: MViTv2-H†† 将 A P b o x AP^{box} APbox 提高到 56.1, A P m a s k AP^{mask} APmask 提高到 48.5。
3. 系统级比较 (MViTv2-L††*)
- 推理策略: MViTv2-L(Cascade)进一步采用了两种推理策略:SoftNMS 和多尺度测试(标记为 *)。
- SOTA 结果: 这些策略将 A P b o x AP^{box} APbox 提升至 58.7。
- 结果意义: 58.7 A P b o x AP^{box} APbox 的结果已经优于 Swin 的最佳结果(58.0 A P b o x AP^{box} APbox),尽管 MViTv2 尚未使用 Swin 所依赖的改进型 HTC++ 检测器。
好的,这是对第 6 节(视频识别实验)的精读总结。
6.Experiments: Video Recognition
MViTv2 应用于四个主要的视频识别基准数据集:Kinetics-400 (K400)、Kinetics-600 (K600)、Kinetics-700 (K700) 和 Something-Something-v2 (SSv2)。
实验设置 (Settings)
- 默认训练: 默认情况下,MViTv2 模型在 Kinetics 上从头开始训练 (trained from scratch)。
- SSv2 训练: 对于 SSv2 数据集,模型从 Kinetics 预训练模型进行微调。
- ImageNet 预训练: 当使用 IN-1K 或 IN-21K 作为预训练时,采用 §4.3 中介绍的初始化方案(即 2D 权重膨胀和时间嵌入置零)并使用较短的训练周期。
- 采样: 训练时,从视频中采样一个 T × τ T \times \tau T×τ 的片段( T T T 帧,时间步长 τ \tau τ)。
- 推理: 最终得分由采样的时间片段和空间裁剪的平均值得出。
6.1. 主要结果 (Main Results)
Kinetics-400 (K400) (Table 10)
- MViTv2 vs. MViTv1 (从头训练): MViTv2-S 和 MViTv2-B (81.0% / 82.9%) 相比 MViTv1 对应模型 (78.4% / 80.2%),top-1 准确率分别高出 +2.6% 和 +2.7%。
- 增益来源: 由于训练方法完全相同,这些增益完全来源于 §4.1 中提出的架构改进(分解相对位置嵌入和残差池化连接)。
- MViTv2-L (预训练): MViTv2-L 在 IN-21K 预训练后,使用 40 × 31 2 2 40 \times 312^2 40×3122 的大时空输入,达到了 86.1% 的 top-1 准确率。
Kinetics-600/-700 (K600/K700) (Tables 11 & 12)
- K600 (从头训练): MViTv2-B (32x3) 从头训练达到了 85.5% 的准确率。
- K600 效率与性能: MViTv2-B (85.5%) 不仅优于 MViTv1 对应模型 (+1.4%),甚至优于使用 IN-21K 预训练的 Swin-B (84.0%) (+1.5%),同时 FLOPs 和参数量分别减少了约 2.2 倍和 40%。
- K600 SOTA: MViTv2-L 创下了 87.9% 的新 SOTA 纪录。
- K700 SOTA: MViTv2-L 达到了 79.4%,大幅超越先前最佳结果 (+7.1%)。
Something-Something-v2 (SSv2) (Table 13)
SSv2 是一个更侧重时间建模的数据集。
- MViTv2-S vs. MViTv1: MViTv2-S 相比 MViTv1 对应模型取得了 +3.5% 的巨大提升,这验证了改进的池化注意力机制对于时间建模的有效性。
- MViTv2-B vs. Swin-B: MViTv2-B (70.5%) 仅使用 K400 预训练,其准确率超过了使用 IN-21K 和 K400 预训练的 Swin-B (69.6%) (+0.9%),且 FLOPs 和参数更少。
- IN-21K 预训练: MViTv2-B (72.1%) 和 MViTv2-L (73.3%) 进一步提升了性能。
6.2. Kinetics 上的消融实验 (Ablations on Kinetics)
Table 14 比较了不同预训练方案在 K400 上的影响。
预训练数据集的影响 (Effect of pre-training datasets)
- 中小型模型 (MViTv2-S / MViTv2-B): 与从头训练相比,使用 IN-1K 或 IN-21K 预训练都能提升准确率。例如,MViTv2-S 在 IN-1K 和 IN-21K 预训练下分别获得 +1.0% 和 +1.4% 的增益。
- 大型模型 (MViTv2-L): 对于大型模型,ImageNet 预训练是必要的。
- 原因: 大型模型在从头训练时会严重过拟合(overfitting)(例如 MViTv2-L 从头训练 81.8%,低于 MViTv2-B 的 82.9%)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)