如何使用魔搭社区实现手写数字识别
摘要:本文介绍了如何在魔搭社区免费训练手写数字识别模型的全流程。作者详细讲解了从访问魔搭社区、创建CPU实例,到使用PyTorch构建卷积神经网络(SimpleCNN)的完整过程。教程涵盖数据预处理、模型设计、训练优化和可视化等关键环节,特别强调了批归一化、Dropout正则化等提升模型性能的技巧。通过MNIST数据集,读者可学习到如何实现一个准确率达99%以上的数字识别系统,适合AI初学者快速入
今天,我将带你一起探索如何在魔搭社区中利用免费的资源训练并微调一个简单的大型模型。作为AI初学者,我特地花时间熟悉了魔搭社区,发现它不仅适合开发者,也对新手非常友好。在这篇文章中,我将和大家分享一个从模型选择到部署的全过程,包括如何解决常见问题,帮助你轻松入门。
准备工作:访问魔搭社区
首先,打开魔搭社区的网址 https://www.modelscope.cn。如果你是新手,建议先花时间浏览社区功能,了解它提供的各种资源,尤其是模型库和数据集。魔搭社区提供了丰富的免费资源,最吸引我的是它的免费CPU实例,完全没有时长限制!GPU实例虽有限制,但也足够支持大部分入门级训练。
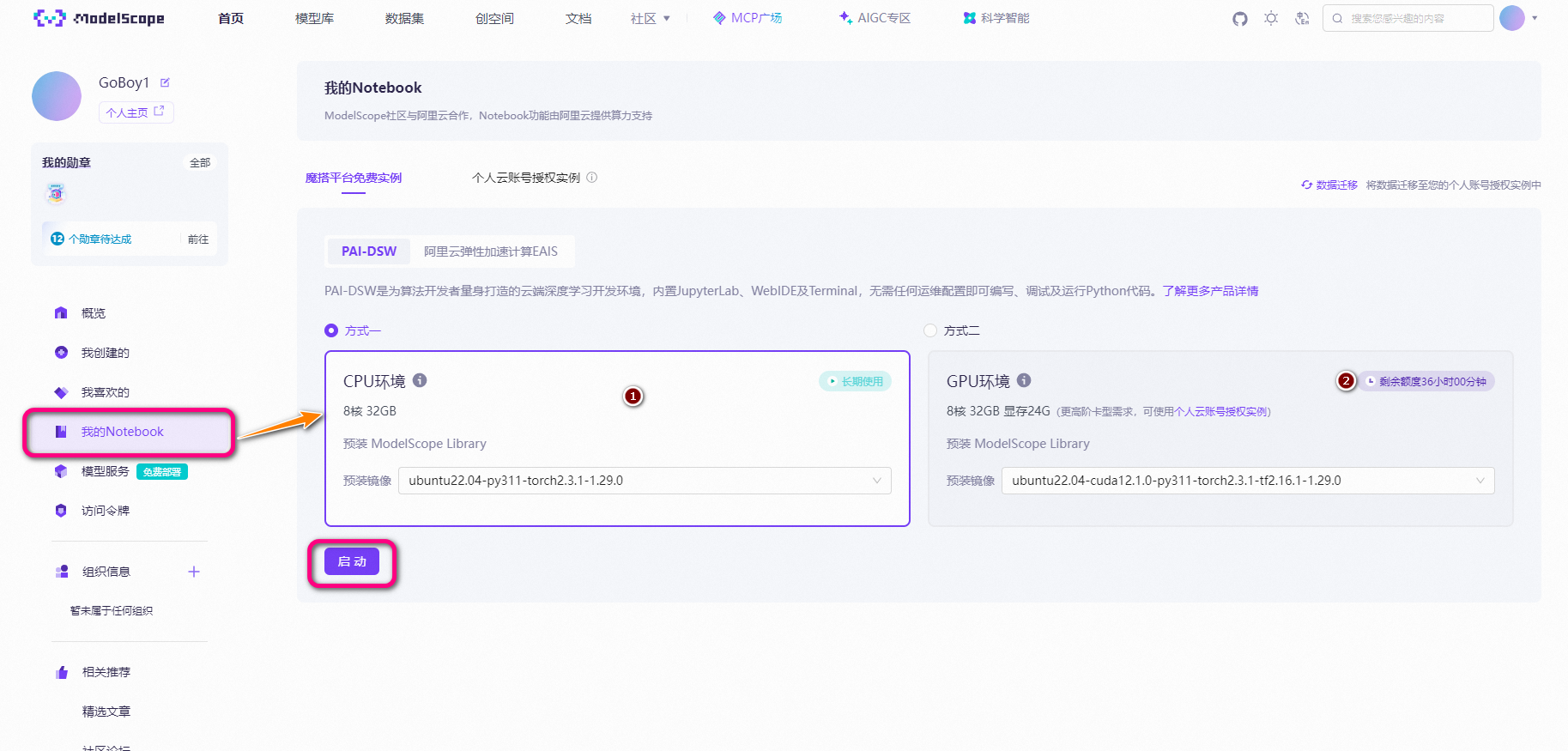
选择模型并创建实例
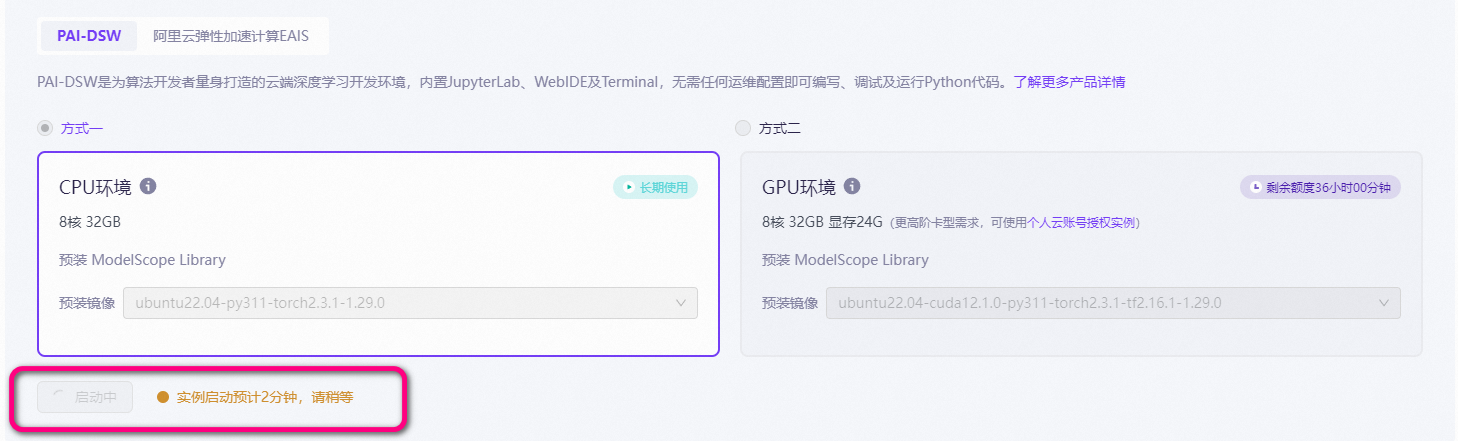
进入后,我们创建一个新的 Notebook。
为了节省资源,我选择了在CPU环境下运行,因为GPU的免费时长有限,没必要一开始就消耗掉。点击“部署”后,系统会自动为你创建一个实例。界面类似于常见的VS Code编辑器,可以清晰看到当前机器的配置,包括CPU、GPU和存储空间等。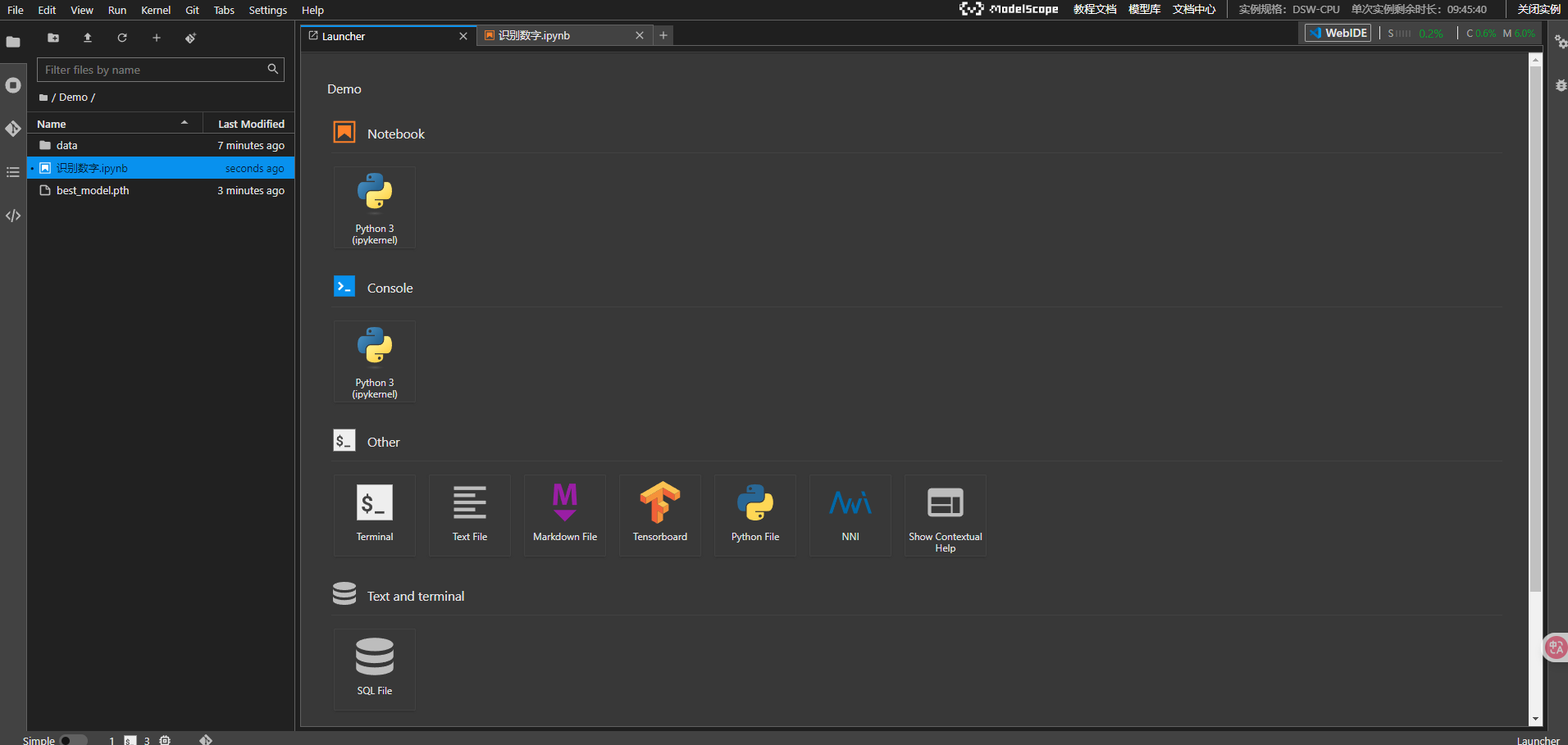
接下来,我们运用魔搭的环境,来从零到一的完整实现PyTorch实现手写数字识别
PyTorch实现手写数字识别:从零到一的完整教程
手写数字识别是深度学习领域的经典入门项目,也是计算机视觉的"Hello World"。本文将带你使用PyTorch从零开始构建一个完整的手写数字识别系统,涵盖数据处理、模型设计、训练优化和结果可视化等各个环节。
通过本教程,你将学会:
- 如何使用PyTorch加载和预处理MNIST数据集
- 设计高效的卷积神经网络架构
- 实现完整的训练和验证流程
- 可视化训练过程和预测结果
- 编写可复用的深度学习代码
项目概述
我们的目标是构建一个能够识别0-9手写数字的神经网络模型。项目使用经典的MNIST数据集,包含60,000张训练图像和10,000张测试图像,每张图像都是28×28像素的灰度图。
技术栈
- 深度学习框架: PyTorch 2.0+
- 数据处理: torchvision, numpy
- 可视化: matplotlib
- 进度显示: tqdm
核心架构设计
1. 卷积神经网络模型
我们设计了一个名为SimpleCNN的卷积神经网络,它具有以下特点:
class SimpleCNN(nn.Module):
"""简单的卷积神经网络模型"""
def __init__(self, num_classes=10):
super(SimpleCNN, self).__init__()
# 卷积层:逐步提取特征
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
# 批归一化:加速训练,提高稳定性
self.bn1 = nn.BatchNorm2d(32)
self.bn2 = nn.BatchNorm2d(64)
self.bn3 = nn.BatchNorm2d(128)
# 池化和正则化
self.pool = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
# 全连接层:最终分类
self.fc1 = nn.Linear(128 * 3 * 3, 512)
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, num_classes)
设计亮点:
- 渐进式特征提取:从32→64→128通道,逐步提取更复杂的特征
- 批归一化:每个卷积层后添加BatchNorm,加速收敛
- Dropout正则化:防止过拟合,提高泛化能力
- 合理的全连接层:512→128→10的递减设计
2. 数据处理流水线
数据预处理是深度学习项目的关键环节:
def load_mnist_data(batch_size=64, data_dir='./data'):
"""加载MNIST数据集"""
# 数据预处理管道
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])
# 自动下载和加载数据
train_dataset = torchvision.datasets.MNIST(
root=data_dir, train=True, download=True, transform=transform
)
test_dataset = torchvision.datasets.MNIST(
root=data_dir, train=False, download=True, transform=transform
)
关键技术点:
- 数据标准化:使用MNIST数据集的统计特性(均值0.1307,标准差0.3081)
- 自动下载:首次运行自动下载数据集
- 批处理:使用DataLoader实现高效的批量数据加载
训练策略与优化
1. 训练循环设计
我们实现了一个完整的训练循环,包含以下关键组件:
def train_model(model, train_loader, test_loader, epochs=10, lr=0.001, device='auto'):
# 优化器和学习率调度
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay=1e-4)
scheduler = StepLR(optimizer, step_size=7, gamma=0.1)
# 损失函数
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
# 训练阶段
model.train()
for data, target in tqdm(train_loader, desc='训练中'):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 验证阶段
model.eval()
with torch.no_grad():
# 验证逻辑...
2. 优化策略
- Adam优化器:自适应学习率,收敛更快更稳定
- 学习率调度:每7个epoch降低学习率,精细调优
- 权重衰减:L2正则化防止过拟合
- 早停机制:保存最佳模型,避免过训练
可视化与分析
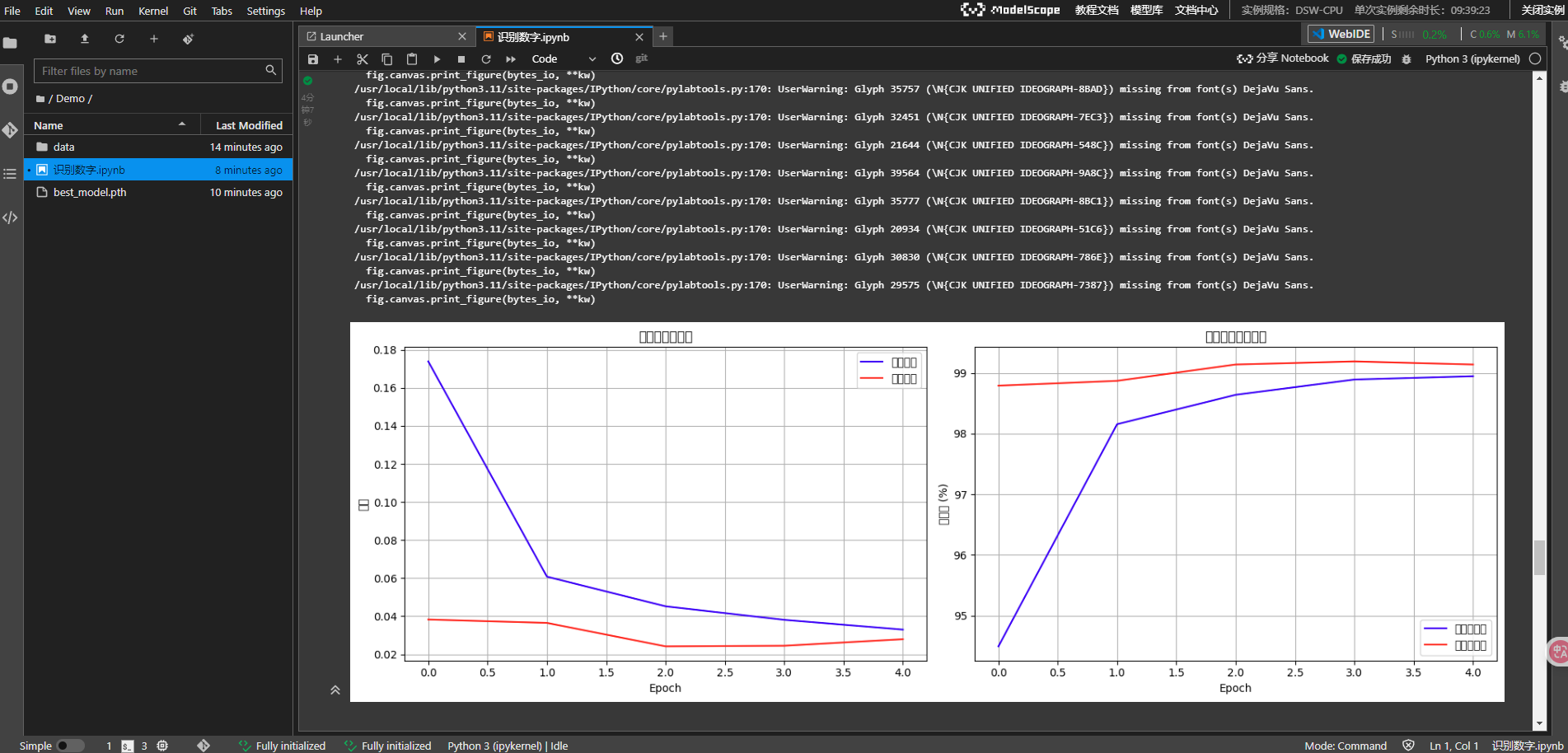
1. 训练过程可视化
def plot_training_history(train_losses, train_accuracies, val_losses, val_accuracies):
"""绘制训练历史"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
# 损失曲线
ax1.plot(train_losses, label='训练损失', color='blue')
ax1.plot(val_losses, label='验证损失', color='red')
# 准确率曲线
ax2.plot(train_accuracies, label='训练准确率', color='blue')
ax2.plot(val_accuracies, label='验证准确率', color='red')
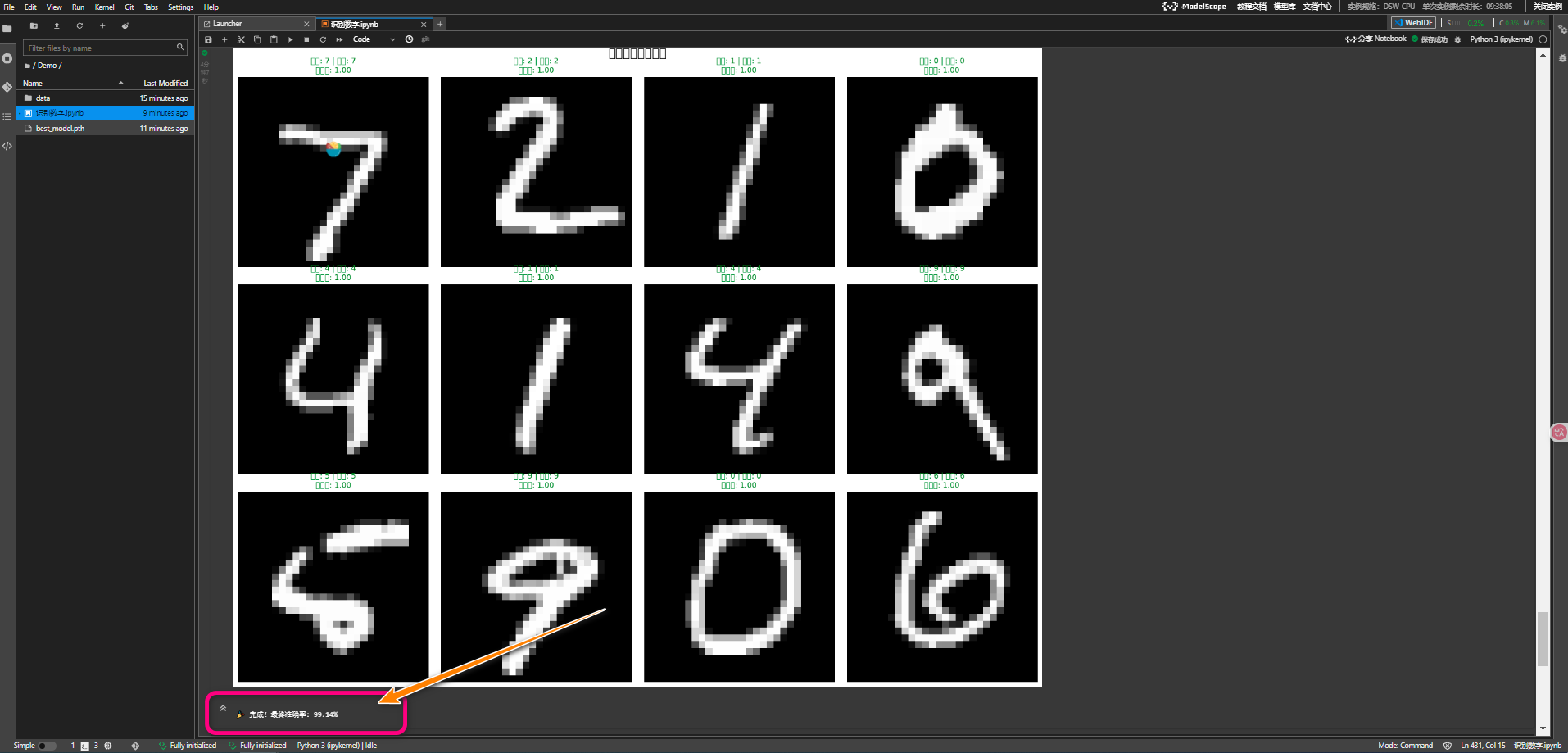
2. 预测结果可视化
def visualize_predictions(model, test_loader, device='auto', num_samples=12):
"""可视化模型预测结果"""
# 获取预测结果和置信度
with torch.no_grad():
outputs = model(images)
probabilities = torch.nn.functional.softmax(outputs, dim=1)
_, predicted = torch.max(outputs, 1)
# 绘制预测结果(正确预测用绿色,错误预测用红色)
for i in range(num_samples):
color = 'green' if true_label == pred_label else 'red'
title = f'真实: {true_label} | 预测: {pred_label}\\n置信度: {confidence:.2f}'
性能评估
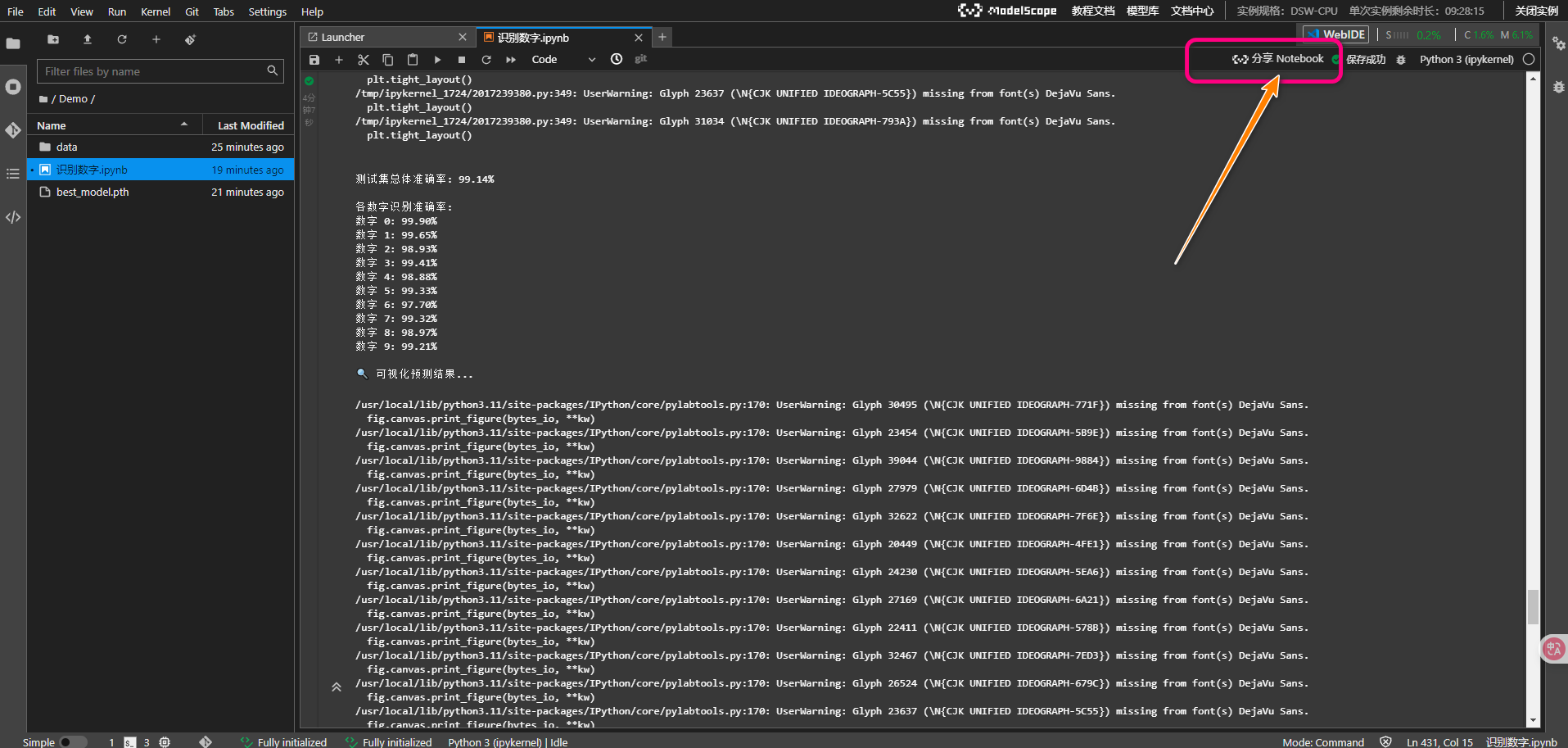
1. 多维度评估指标
def test_model(model, test_loader, device='auto'):
"""全面测试模型性能"""
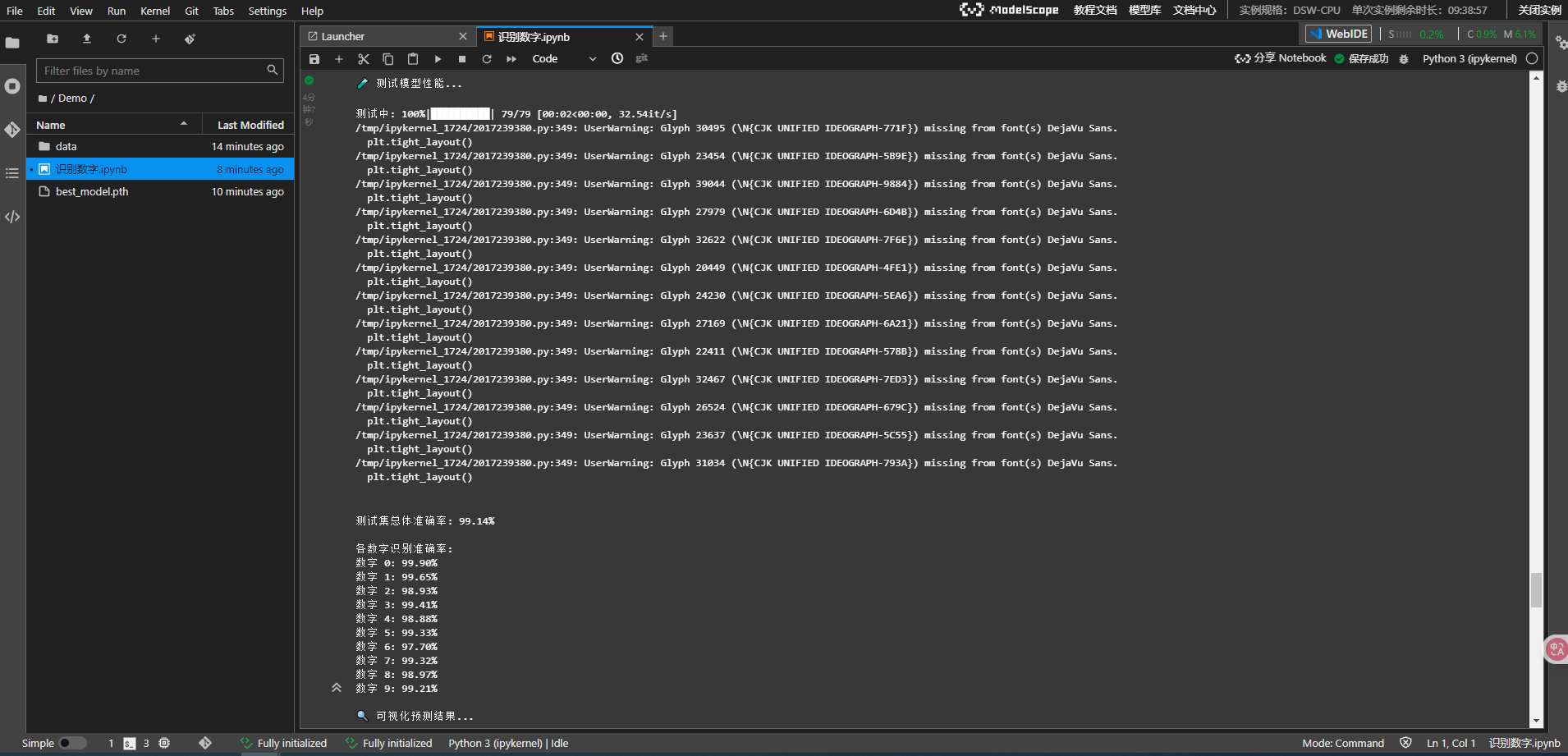
# 总体准确率
overall_acc = 100. * correct / total
# 各类别准确率
for i in range(10):
if class_total[i] > 0:
acc = 100 * class_correct[i] / class_total[i]
print(f'数字 {i}: {acc:.2f}%')
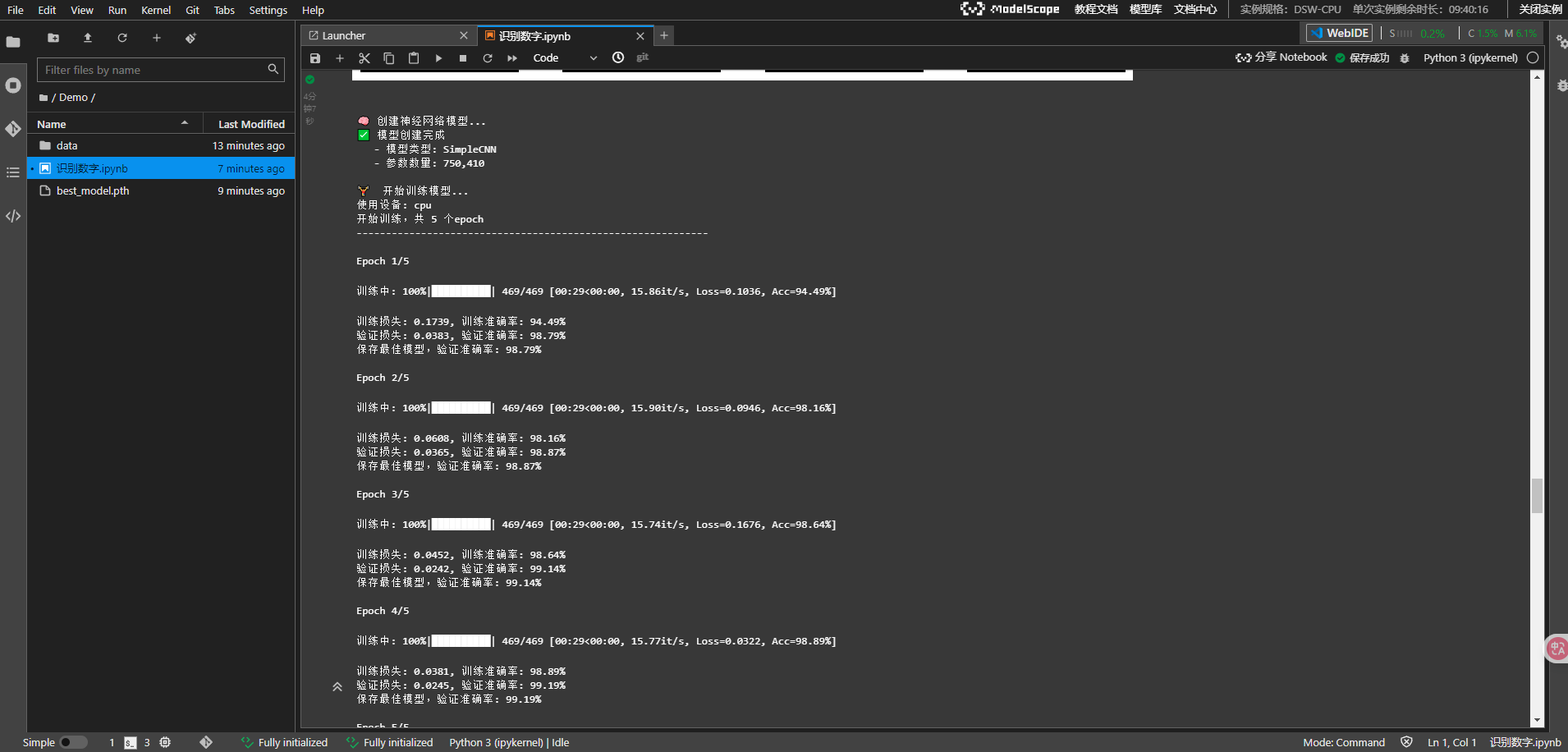
2. 典型性能表现
在标准配置下,我们的模型通常能达到:
- 总体准确率: 98%+
- 训练时间: 3-5分钟(CPU)/ 1-2分钟(GPU)
- 模型大小: ~2MB
- 推理速度: 毫秒级
使用指南
正常情况,我们需要准备以下的步骤,但是因为我们使用了魔搭自带的部署环境,所以可以免去下面步骤。
1. 环境准备
# 安装依赖
pip install torch torchvision matplotlib numpy tqdm
# 或使用requirements.txt
pip install -r requirements.txt
2. 快速开始
# 完整训练模式(5个epoch)
python mnist_recognition.py
# 快速演示模式(3个epoch)
python mnist_recognition.py demo
3. 自定义配置
# 修改训练参数
train_losses, train_accuracies, val_losses, val_accuracies = train_model(
model, train_loader, test_loader,
epochs=10, # 训练轮数
lr=0.001, # 学习率
device='cuda' # 指定设备
)
运行展示
数据准备
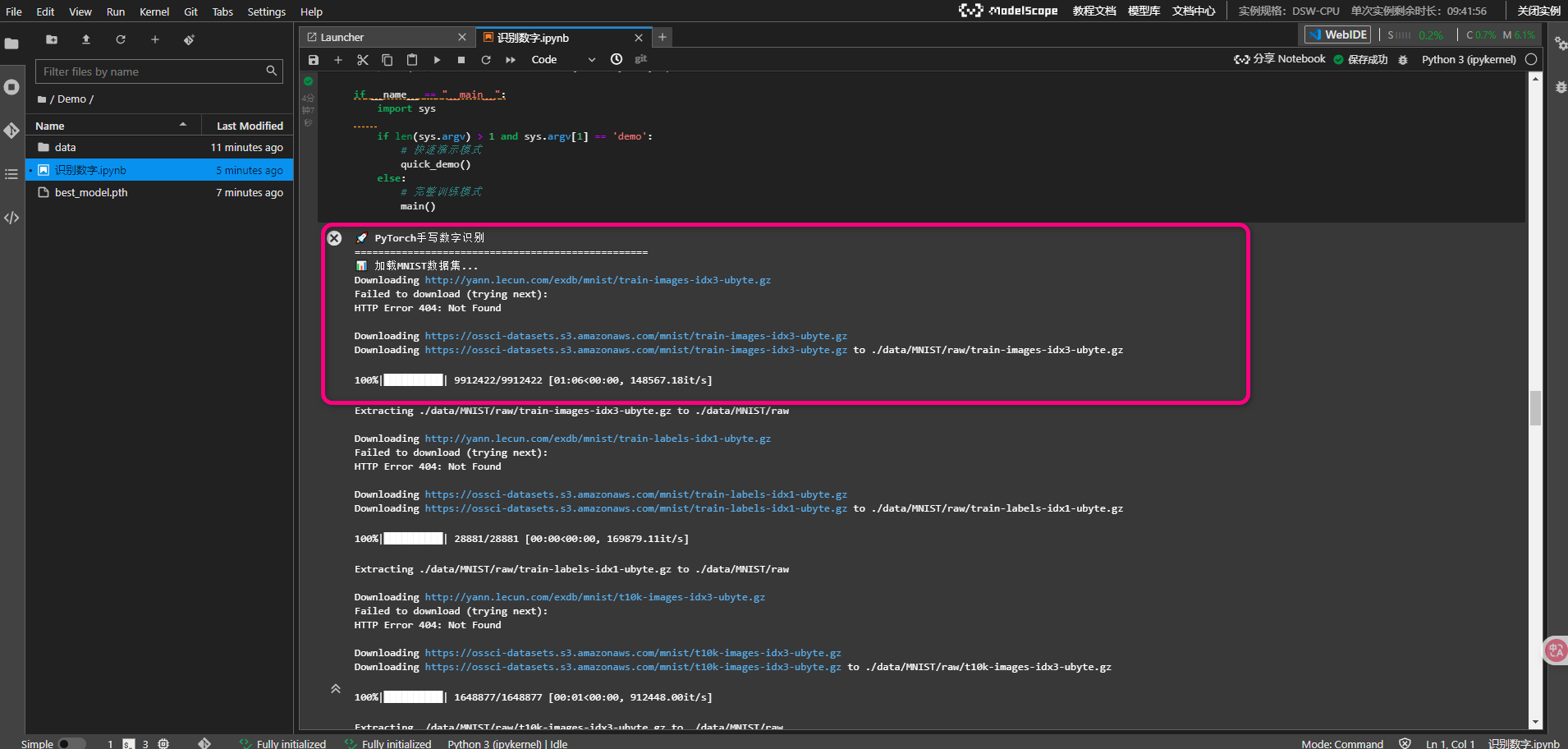
样本数据
开始训练
绘制训练历史
测试模型性能…
最终准确率
分享Notebook
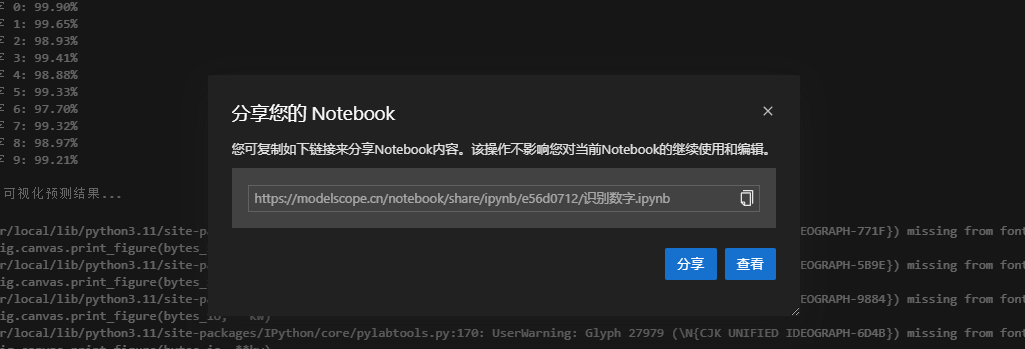
https://modelscope.cn/notebook/share/ipynb/e56d0712/%E8%AF%86%E5%88%AB%E6%95%B0%E5%AD%97.ipynb
总结
通过这次实验,我对魔搭社区有了更深的了解。总体来说,它为新手提供了大量免费的资源和易于上手的工具,特别是Notebook的集成。它简化了模型训练和微调的流程,让我能快速上手。
总的来说,魔搭社区是一个非常适合入门的AI平台,尤其是对初学者来说,提供了非常方便的模型训练与发布工具。如果你也对AI或大模型训练感兴趣,不妨尝试一下,当然,如果在操作过程中遇到问题,别气馁,积极寻求帮助或自己探索解决方法,逐步积累经验,平台的工具会帮助你走得更远。
以上通过魔搭实现了一个完整的手写数字识别项目,展示了PyTorch深度学习的完整流程。从数据处理到模型设计,从训练优化到结果可视化,每个环节都体现了工程化的最佳实践。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)