DeepSeek-OCR:AI界的新“黑科技”,它如何改变我们与AI模型的交互方式?
DeepSeek-OCR革新AI文本处理:视觉压缩突破长上下文限制 DeepSeekAI推出的DeepSeek-OCR通过革命性的"上下文光学压缩"技术,将文本转化为视觉信息处理,实现高达10倍的文本压缩比(96%精度)。该模型包含380M参数的DeepEncoder视觉压缩器和570M的MoE解码器,支持百种语言OCR、文档结构化及图表解析。其突破性在于: 将长文本转为视觉t

image
在人工智能飞速发展的今天,大型语言模型(LLM)以其惊人的理解和生成能力,正在重塑我们与数字世界的互动方式。然而,一个长期存在的挑战是:如何高效、经济地处理超长文本上下文?传统的文本token化方法在面对海量信息时,计算成本呈指数级增长,如同给LLM戴上了“记忆的枷锁”。
直到2025年10月20日,深度求索(DeepSeek AI)发布了DeepSeek-OCR,这款模型以其独特的“上下文光学压缩”(Contexts Optical Compression)技术,为这一难题带来了革命性的解决方案。它不仅仅是一个OCR工具,更是一种全新的AI交互范式,预示着我们与AI模型协作方式的深刻变革。
1. “看”比“读”更高效:上下文光学压缩的魔力
DeepSeek-OCR的核心理念在于,将文本信息视为视觉内容进行处理。想象一下,与其让LLM逐字逐句地“阅读”一份冗长的文档,不如让它“看”一眼这份文档的“照片”。DeepSeek-OCR正是基于这种直觉,将长文本内容渲染成图像,然后通过一个专门设计的视觉编码器,将这些图像压缩成数量极少的“视觉token”。
这种“看”的方式带来了惊人的效率提升:
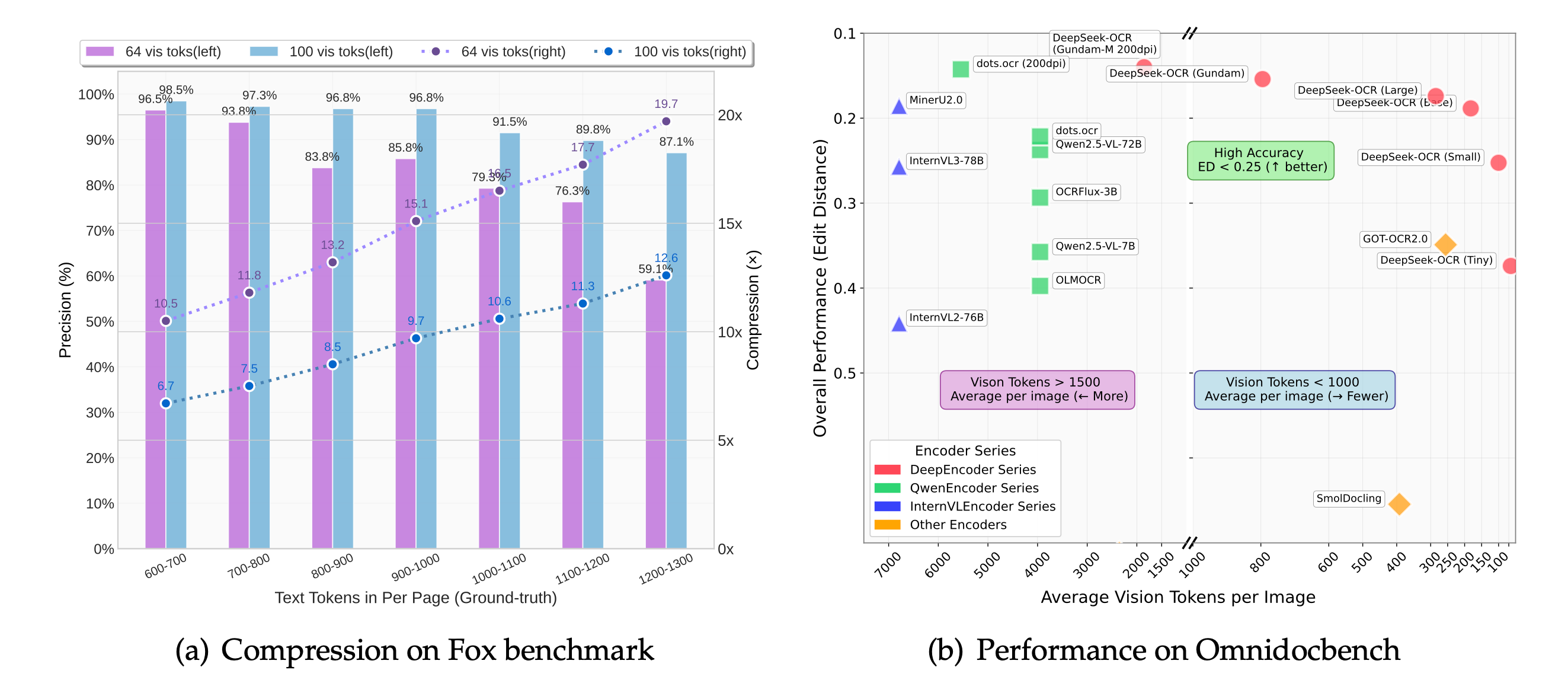
- • 极致压缩比: 在Fox基准测试中,DeepSeek-OCR能够在10倍文本压缩比(即10个文本token压缩为1个视觉token)下,保持96%以上的OCR解码精度。即使在高达20倍的压缩比下,仍能维持约60%的可用准确率。这意味着,原本需要数千甚至上万个文本token才能表示的信息,现在只需几十个视觉token即可承载。
- • 突破长上下文限制: 对于LLM而言,上下文长度是其理解和推理能力的关键。DeepSeek-OCR通过将长文本转化为紧凑的视觉表示,极大地扩展了LLM处理信息的“视野”,使其能够以更低的计算成本处理更长的文档、更复杂的对话历史。
image
2. 精妙架构:DeepEncoder与MoE解码器的协同
DeepSeek-OCR的强大能力源于其精巧的架构设计,主要由DeepEncoder和DeepSeek3B-MoE-A570M解码器组成。
- • DeepEncoder:视觉信息的“压缩大师”
DeepEncoder是一个约380M参数的视觉编码器,它创新性地结合了窗口注意力(基于SAM-base)和全局注意力(基于CLIP-large),并通过一个16倍的卷积压缩器巧妙连接。这种设计在高分辨率输入下依然能保持低激活内存和极少的视觉token。它还支持多种分辨率模式,从Tiny(64视觉token)到Gundam模式(动态分辨率),能够灵活适应各种文档的复杂度和压缩需求。 - • MoE解码器:高效的“文本还原者”
解码器采用DeepSeek3B-MoE架构,在推理时仅激活64个专家中的6个路由专家和2个共享专家,激活参数量约为570M。这种混合专家(MoE)设计让模型在拥有3B模型表达能力的同时,享受500M小模型的推理效率,实现了性能与成本的完美平衡。
3. 超越传统OCR:多模态理解的未来
DeepSeek-OCR的价值远不止于简单的文字识别。它展现了强大的多模态理解能力,能够处理各种复杂的文档和视觉信息:
- • 文档结构化: 将文档转换为结构化的Markdown格式,完美保留布局、表格和格式。
- • 多语言支持: 内置支持近100种语言的OCR,尤其擅长处理中英文混合文档,打破语言障碍。
- • 智能解析: 能够从图表、示意图、化学公式(转换为SMILES格式)甚至简单几何图形中提取数据和结构信息。
- • 通用视觉理解: 具备图像描述、目标检测和接地等通用视觉理解能力,使其成为一个更全面的视觉AI助手。
- • 大规模生产力: 单个A100-G GPU每天可处理超过20万页文档,结合vLLM框架,PDF并发处理速度可达约2500 token/s,为LLM/VLM的预训练提供了前所未有的大规模数据生产能力。
4. 改变我们与AI模型的交互方式
DeepSeek-OCR的出现,不仅仅是技术上的突破,更深远地改变了我们与AI模型的交互方式:
- • 更自然的输入: 未来,我们可能不再需要将所有信息都转化为纯文本输入给LLM。直接“展示”文档、图表甚至手写笔记的图像,AI就能高效理解其内容和上下文。
- • 无限上下文的可能: 通过光学压缩,LLM有望突破当前上下文窗口的限制,实现真正意义上的“无限上下文”,从而更好地理解复杂、长期的对话和任务。
- • 更智能的文档处理: 从学术研究到商业报告,DeepSeek-OCR能够将非结构化的视觉信息转化为结构化的可编辑文本,极大地提升了文档处理的自动化和智能化水平。
- • 新的记忆机制: 这种视觉压缩方法甚至为LLM模拟人类记忆的“遗忘机制”提供了新思路,通过逐步降低旧图像的分辨率来模拟记忆衰减,实现更高效的记忆管理。
5. 拥抱本地AI的黄金时代:从当下做起
DeepSeek-OCR的开源,让我们看到了本地AI模型激动人心的未来。像这样拥有复杂架构的尖端模型,通常需要时间才能被社区完美集成到像Ollama这样的一键式运行平台中。
这让我们不禁思考:在我们等待这些前沿模型变得更加“亲民”的同时,我们如何才能最大化地利用好手中已有的本地AI能力?随着Llama 3、Mistral、Phi-3等模型在Ollama上百花齐放,模型的增多也带来了新的“甜蜜的烦恼”:如何在命令行中频繁地拉取、切换和管理它们?如何保存和回顾与不同模型的对话?
正是在这样的需求下,社区中涌现出了一批优秀的图形化管理工具,它们致力于将Ollama的体验从命令行提升到全新的高度。其中,像 OllaMan 这样的桌面应用,就提供了一个极佳的范例。它通过优雅直观的界面,让模型的下载、管理和对话变得前所未有的简单,并提供了完善的聊天历史功能。
当我们通过这样的工具,将本地AI工作流打磨得更加成熟和高效,不仅能极大地提升当下的生产力,更是为迎接DeepSeek-OCR这类未来模型做好的最佳准备。当那一天到来时,我们就能以最从容的姿态,第一时间拥抱AI的下一次浪潮。
相关资料:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)