阿里云国际站GPU:什么是推理引擎DeepGPU-LLM?
DeepGPU-LLM是阿里云研发的基于GPU云服务器的大语言模型(Large Language Model,LLM)的推理引擎,在处理大语言模型任务中,该推理引擎可以为您提供高性能的大模型推理服务。DeepGPU-LLM作为阿里云开发的一套推理引擎,具有易用性和广泛适用性,旨在优化大语言模型在GPU云服务器上的推理过程,通过优化和并行计算等技术手段,为您提供免费的高性能、低延迟推理服务。:Qwe
目录
TG:@yunlaoda360
DeepGPU-LLM是阿里云研发的基于GPU云服务器的大语言模型(Large Language Model,LLM)的推理引擎,在处理大语言模型任务中,该推理引擎可以为您提供高性能的大模型推理服务。
产品简介
DeepGPU-LLM作为阿里云开发的一套推理引擎,具有易用性和广泛适用性,旨在优化大语言模型在GPU云服务器上的推理过程,通过优化和并行计算等技术手段,为您提供免费的高性能、低延迟推理服务。
DeepGPU-LLM的关联布局图如下所示:

-
主流模型:Qwen等四种比较主流的大语言模型,作为DeepGPU-LLM优化和加速的对象。
-
开源平台:开源模型平台(Modelscope和Huggingface)提供了大量的预训练模型,该平台提供了模型的存储、管理和分发功能,方便您获取和使用上述主流大语言模型。
-
模型架构:DeepGPU-LLM利用Tensor Parallel技术优化大语言模型在GPU云服务器上的推理过程,提供了高性能、低延迟的推理服务。
-
底层硬件:GPU实例安装驱动和CUDA等基础环境后,作为DeepGPU-LLM运行的基础硬件,提供了强大的计算资源,支持大语言模型的高效推理。
功能介绍
DeepGPU-LLM的主要功能包括:
-
支持多GPU并行(Tensor Parallel)
将大模型分割到多个GPU上进行并行计算,从而提高计算效率。
-
支持多种主流模型
支持通义千问Qwen系列、Llama系列、ChatGLM系列以及Baichuan系列等主流模型,满足不同场景下的模型推理。
-
支持fp8/fp16以及int8/int4低精度推理
目前支持权重量化、KV-Cache量化、GPTQ量化和AWQ量化四种不同量化模式,实现模型的低精度推理,在保证模型性能的同时降低计算资源的消耗。
-
支持多卡之间通信优化
用以提高多GPU并行计算的效率和速度。
-
支持offline模式和serving模式输出
offline模式支持流式输出和普通输出;serving模式提供3类API接口(例如generate_cb、generate_cb_async、generate_cb_async_id调用函数)适配不同场景。
基础环境依赖
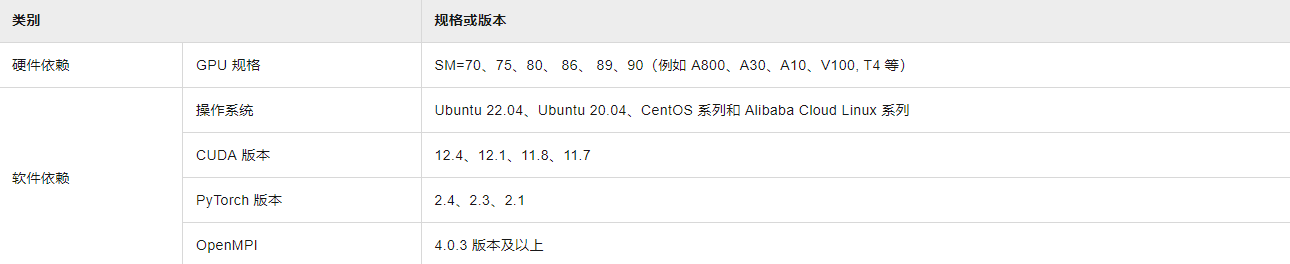
DeepGPU-LLM所需的基础环境依赖如下所示:
安装包及相关文件说明
使用DeepGPU-LLM处理大语言模型(LLM)在GPU上的推理优化时,需要您提前准备安装包。例如,安装包名称格式为deepgpu_llm-x.x.x+ptx.xcuxxx-py3-none-any.whl时,具体说明如下:
-
deepgpu_llm-x.x.x:指待安装的DeepGPU-LLM版本号。 -
ptx.x:所支持的PyTorch版本号。 -
cuxxx:所支持的CUDA版本号。
下载DeepGPU-LLM安装包后,您可以查看到主流模型的推理依赖代码、主流模型权重转换脚本以及安装包提供的可运行示例代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)