AI大模型十大核心概念:从参数量到温度,一文读懂大模型的“黑话”
本文介绍AI大模型十大核心概念
引言:为什么我们需要理解这些“黑话”?
2023年被称为“大模型元年”,ChatGPT、Claude、Gemini、通义千问、文心一言等大模型如雨后春笋般涌现。但随之而来的,是一堆令人眼花缭乱的术语:参数量、Token、上下文窗口、温度、微调、对齐、幻觉……这些词频繁出现在技术文档、产品发布会甚至新闻报道中。
如果你是一名产品经理或应用开发者,不了解这些概念,就很难判断一个模型的真实能力,也难以向用户解释清楚“为什么我的提问有时答得好,有时答得差”。因此,理解概念,才能驾驭技术。最终你会发现,AI不是魔法,而是一套有规律可循的技术系统。
一、参数量(Parameters):模型的“脑容量”
1、专业定义
参数量是指大模型中可学习参数的总数,通常以十亿(Billion, B)或万亿(Trillion, T)为单位。这些参数在训练过程中通过反向传播不断调整,用于捕捉输入与输出之间的复杂映射关系。
2、大白话解释
你可以把参数量想象成一个人的“脑容量”——参数越多,模型“记住”的知识和模式就越多,理论上能力就越强。
比如:
- GPT-3 有约 1750亿参数(175B)
- Llama 2 有 70亿(7B)和 700亿(70B)两个版本
- Claude 3 Opus 据传参数量超过 1万亿
但注意:参数量 ≠ 智能水平。就像一个人脑容量大,不一定更聪明——还要看训练数据质量、架构设计、推理能力等。
3、图示说明
[小模型] 7B 参数 → 能写短文、回答简单问题
[中模型] 70B 参数 → 能编程、推理、多轮对话
[大模型] 1T+ 参数 → 能处理复杂任务、接近人类水平(理论上)
💡 小贴士:参数量越大,模型越“重”,对硬件要求越高。7B模型可在消费级GPU运行,70B则需多卡甚至专用服务器。
二、Token:AI的“最小语言单位”

1、专业定义
Token 是大模型处理文本时的最小单位。它可以是一个词(word)、子词(subword)、标点符号,甚至是特殊字符。现代大模型普遍采用 Byte Pair Encoding (BPE) 或 WordPiece 等分词算法将文本切分为 Token。
2、大白话解释
人类说话以“字”或“词”为单位,而AI“读”文字是以 Token 为单位的。比如英文句子:
"I love AI."
会被切分为:["I", " love", " AI", "."] → 4个Token
中文更复杂。例如:
“我喜欢人工智能。”
可能被切分为:["我", "喜欢", "人工", "智能", "。"] → 5个Token
注意:空格也算Token的一部分!这也是为什么英文Token数通常比字数多。
3、为什么重要?
- 模型的输入/输出长度限制是以 Token数量 计算的
- API调用按Token计费(如OpenAI)
- Token化效率影响推理速度
4、图示:Token化过程
原始文本: "Hello, world! 你好,AI。"
↓ Tokenizer 分词器
Tokens: ["Hello", ",", " world", "!", " 你", "好", ",", "AI", "。"]
Total Tokens: 9
🔍 实测建议:使用 OpenAI Tokenizer 或 Hugging Face Tokenizers 工具查看任意文本的Token数量。
三、上下文窗口(Context Window) vs 上下文长度(Context Length)

这两个概念经常被混用,但其实有细微差别。
1、上下文窗口(Context Window)
指模型一次能处理的最大Token数量,包括用户输入(prompt)和模型输出(completion)。
例如:
- GPT-3.5:4096 tokens
- GPT-4 Turbo:128,000 tokens
- Claude 3:200,000 tokens
- Gemini 1.5 Pro:1,000,000 tokens(百万级!)
2、上下文长度(Context Length)
通常指用户输入部分的最大长度,但实际使用中常与“上下文窗口”混用。严格来说,上下文长度 ≤ 上下文窗口。
3、大白话类比
想象你和朋友聊天:
- 上下文窗口 = 你们这次对话能记住的总字数上限
- 如果你说了3000字,AI最多只能再回你1096字(以GPT-3.5为例,上下文窗口为4096 tokens)
4、为什么重要?
- 长上下文支持长文档分析(如读整本小说、财报)
- 但并非越长越好:注意力机制计算复杂度随长度平方增长,长上下文会显著拖慢速度、增加成本
5、图示:上下文窗口分配
[ 用户输入: 80,000 tokens ] + [ 模型输出: 20,000 tokens ] = 100,000 tokens(总窗口)
↑
实际可用输出长度受限
⚠️ 注意:即使窗口很大,模型对远距离信息的记忆能力仍有限(“中间丢失”问题),并非所有内容都能被有效利用。
四、温度(Temperature):控制AI的“创造力”

1、专业定义
温度是生成文本时用于调节输出随机性的超参数。取值范围通常为 0.0 ~ 2.0。
- 低温度(如 0.1):模型更“保守”,倾向于选择概率最高的词,输出更确定、重复性高
- 高温度(如 1.0):模型更“大胆”,引入更多随机性,输出更具多样性、创造性,但也可能胡说
2、大白话解释
温度就像AI的“性格开关”:
- 低温 = 严谨学霸:答题标准,但缺乏创意
- 高温 = 狂野诗人:妙语连珠,但也可能跑题
3、示例对比
Prompt: “写一句关于春天的诗。”
-
Temperature = 0.2
→ “春天来了,花开满园。”(安全、平淡) -
Temperature = 1.0
→ “春风撕碎冬的遗嘱,樱花在枝头点燃一场粉色革命。”(惊艳但风险高)
4、图示:温度如何影响词概率分布
原始概率: [0.6, 0.3, 0.05, 0.05] # 四个候选词
↓ Temperature = 0.5(低温)
调整后: [0.85, 0.14, 0.005, 0.005] → 几乎只选第一个词
↓ Temperature = 1.5(高温)
调整后: [0.45, 0.35, 0.12, 0.08] → 更多可能性
🛠️ 实用建议:
- 写代码、答题 → 用 低温度(0.1~0.5)
- 写故事、广告文案 → 用 高温度(0.7~1.2)
五、Top-p(Nucleus Sampling):动态控制候选词范围
1、专业定义
Top-p(也称 nucleus sampling)是一种采样策略:从累积概率超过 p 的最小词集中随机选择下一个词。p ∈ [0,1]。
2、大白话解释
想象AI面前有一堆候选词,按“靠谱程度”排序。Top-p 不是固定选前N个(那是 Top-k),而是动态划定一个“靠谱圈”:
- p = 0.9:只考虑累计概率达90%的那些词
- p = 0.5:只考虑最靠谱的50%词汇
这样既能避免低质量词干扰,又保留一定多样性。
3、与 Temperature 的关系
- Temperature 调整整体分布的平滑度
- Top-p 调整候选词的范围大小
- 两者常配合使用
4、图示:Top-p 选择过程
词概率排序: A(0.4) → B(0.3) → C(0.2) → D(0.05) → E(0.05)
↓ Top-p = 0.9
累计: 0.4 → 0.7 → 0.9 ✅ → 停止
候选集: {A, B, C}
从这3个中按概率随机选
💡 最佳实践:OpenAI 默认使用 Top-p=1.0(即不启用),但 Claude、Llama 等常设 Top-p=0.9。
六、推理(Inference):AI的“思考过程”
1、专业定义
推理是指将训练好的模型用于处理新输入并生成输出的过程,与训练(Training)相对。
2、大白话解释
- 训练 = AI“上学读书”,消耗大量数据和算力
- 推理 = AI“考试答题”,用学到的知识回答问题
大模型部署后,99%的时间都在做推理。因此,推理效率(速度、成本、延迟)至关重要。
3、关键指标
- 吞吐量(Throughput):每秒处理多少请求
- 延迟(Latency):从提问到收到回答的时间
- 显存占用:决定能否在消费级设备运行
4、优化技术
- 量化(Quantization):将32位浮点数转为8位整数,减小模型体积
- KV Cache:缓存注意力键值对,避免重复计算
- 推测解码(Speculative Decoding):用小模型“猜”大模型输出,加速生成
🚀 案例:Llama.cpp 通过4-bit量化,让70B模型在MacBook上流畅运行。
六、微调(Fine-tuning):给大模型“定向培训”

1、专业定义
微调是在预训练大模型基础上,用特定领域的小规模数据集继续训练,使其适应特定任务。
2、大白话解释
预训练模型像“通才大学生”,什么都知道一点;微调则是让它“读研”或“实习”,成为某个领域的专家。
例如:
- 用医疗问答数据微调 → 医疗AI助手
- 用客服对话数据微调 → 客服机器人
3、微调 vs 提示工程(Prompt Engineering)
| 方式 | 成本 | 灵活性 | 效果 |
|---|---|---|---|
| 提示工程 | 低(只需改提示词) | 高 | 一般 |
| 微调 | 高(需训练) | 低(固定能力) | 强 |
4、新兴技术:LoRA(Low-Rank Adaptation)
传统微调需更新全部参数,成本高。LoRA 只训练低秩矩阵,参数量减少90%以上,成为当前主流微调方法。
📌 适用场景:当你有高质量领域数据且需要稳定输出格式时,微调是首选。
八、RAG(Retrieval-Augmented Generation):给AI装“外挂记忆”
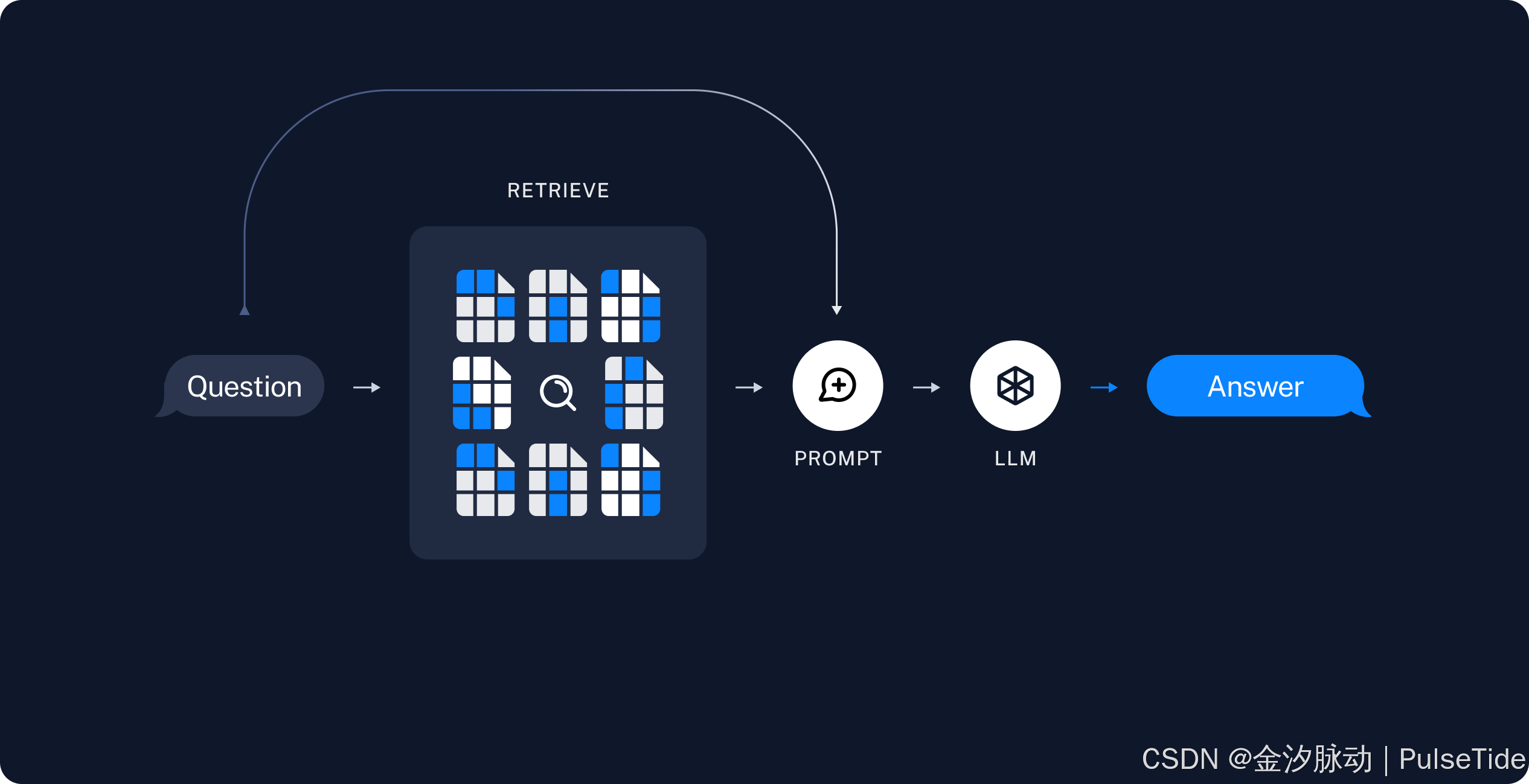
1、专业定义
RAG 是一种架构:在生成答案前,先从外部知识库检索相关信息,再将检索结果与用户问题一起输入模型。
2、大白话解释
大模型的知识截止于训练数据(如GPT-4截止到2023年)。RAG 相当于给它配了个“实时搜索引擎”:
- 用户问:“2024年奥运会举办地?”
- 系统从数据库检索:“巴黎”
- 将“巴黎”和问题一起喂给模型
- 模型生成:“2024年夏季奥运会将在法国巴黎举行。”
3、优势
- 解决知识过时问题
- 减少幻觉(Hallucination)
- 无需重新训练模型
4、图示:RAG 工作流程
用户提问 → [检索器] → 从知识库找相关文档 → [大模型] → 生成答案
🔧 工具推荐:LangChain、LlamaIndex 可快速搭建RAG应用。
九、幻觉(Hallucination):AI的“一本正经胡说八道”
最经典的案例,9.11 和9.9 哪个大?最初模型会回答9.11更大。
1、专业定义
幻觉指模型生成看似合理但事实错误或无中生有的内容。
2、常见类型
- 事实性幻觉:“爱因斯坦发明了电话”(实际是贝尔)
- 上下文幻觉:编造用户没提过的细节
- 数学幻觉:算错简单加减法
3、为什么发生?
- 模型本质是概率预测器,不是知识库
- 训练数据包含错误信息
- 过度优化“流畅性”而牺牲准确性
4、缓解方法
- 使用 RAG 引入可靠知识源
- 设置 低温度 减少随机性
- 添加 事实核查模块
- 采用 思维链(Chain-of-Thought) 提示
🚨 重要提醒:永远不要完全相信大模型的答案,尤其涉及医疗、法律、金融等关键领域!
十、对齐(Alignment):让AI“听话”且“向善”
1、专业定义
对齐是指通过技术手段(如RLHF)使模型输出符合人类价值观、意图和偏好。
2、大白话解释
未经对齐的模型可能:
- 回答暴力、歧视内容
- 拒绝无害请求(过度审查)
- 无法遵循指令
对齐就是给AI装上“道德指南针”和“理解力”。
3、核心技术:RLHF(Reinforcement Learning from Human Feedback)
- 人类标注员对模型回答打分
- 训练一个“奖励模型”预测人类偏好
- 用强化学习优化大模型,使其输出高奖励答案
4、对齐的挑战
- 价值观差异:不同文化对“好回答”定义不同
- 能力 vs 服从:过度对齐可能削弱模型能力(如拒绝创意写作)
- 越狱(Jailbreak):用户通过特殊提示绕过对齐限制
🌍 行业趋势:各国正推动AI对齐标准,未来“对齐能力”将成为大模型核心竞争力。
总结
这十大概念,构成了理解大模型能力边界与使用技巧的“认知地图”,它们相互关联:
- 参数量 + 上下文窗口 决定模型“能处理多复杂的问题”
- Token + 温度 + Top-p 决定“输出风格与质量”
- 微调 + RAG + 对齐 决定“是否可靠、专业、安全”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)