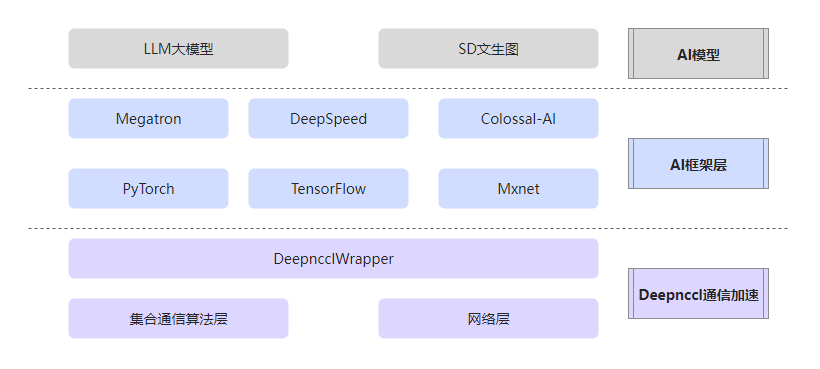
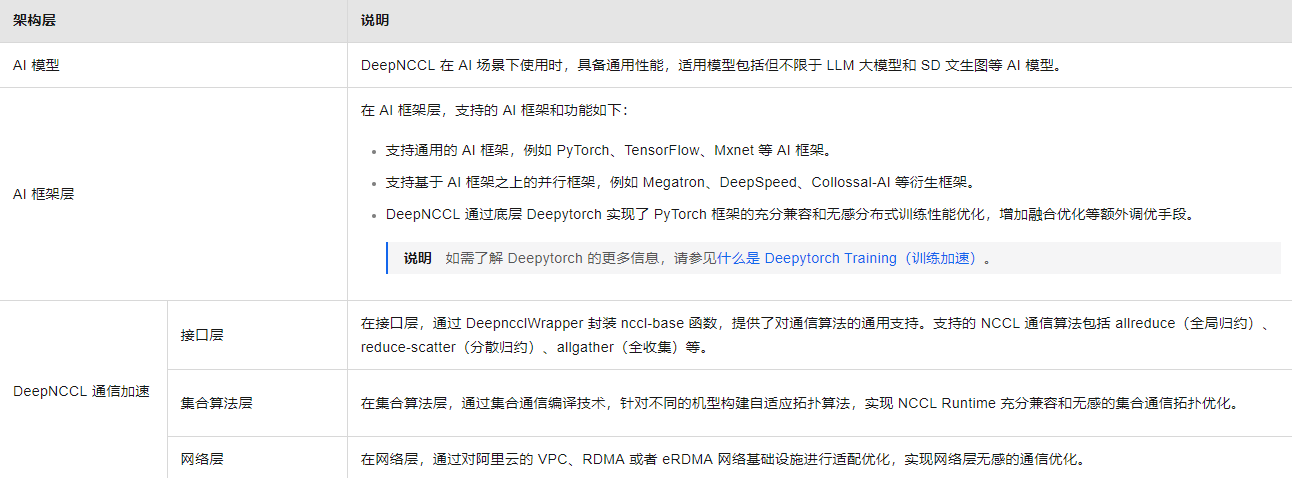
阿里云国际站GPU:什么是AI通信加速库DeepNCCL?
DeepNCCL是阿里云为神龙异构产品开发的AI通信加速库,通过优化NCCL通信算子提升多GPU互联效率。该库针对单机PCIe/NVLink拓扑提供特定优化方案(如CPU-Reduce流水线、N-Trees拓扑组合),性能提升达20%以上;多机场景则通过分层通信、TCP多流等技术实现50%的性能提升,特别适用于Transformer等大模型训练。DeepNCCL支持Allreduce、Allgat
目录
TG:@yunlaoda360
DeepNCCL是为阿里云神龙异构产品开发的一种用于多GPU互联的AI通信加速库,在AI分布式训练或多卡推理任务中用于提升通信效率。本文主要介绍DeepNCCL的架构、优化原理和性能说明。
产品简介
DeepNCCL基于NCCL(NVIDIA Collective Communications Library)通信算子的调用,能够实现更高效的多GPU互联通信,无感地加速分布式训练或多卡推理等任务。
DeepNCCL的关联架构布局图如下所示:
优化原理
DeepNCCL通信加速库在AI分布式训练或多卡推理任务中,具有显著的通信优化效果。具体说明如下:
单机优化
单机内的优化主要针对不同硬件拓扑机型的通信优化,以PCIe互连的机型和NVLink互连的机型为例,具体说明如下:
-
PCIe互连拓扑优化:该机型的多GPU卡之间共享PCIe带宽,通信容易受限于物理带宽。针对PCIe互连拓扑的通信优化特点,理论上,可以采用基于流水线的PS(Parameters Server:参数服务器)模式梯度规约算法CPU-Reduce大幅降低通信耗时。该算法按照GPU到CPU再到GPU的顺序构建流水线,将梯度规约的计算分散到多个设备上运行,来减少通信瓶颈。
例如,在通信数据量超过4 MB的场景,PCIe互连拓扑优化方案相比NCCL原生在性能上提升了20%以上。
-
NVLink互连拓扑优化:NCCL默认使用的Binary-Tree算法在V100机型上并不能充分发挥多通道性能。针对NVLink互连拓扑的通信优化,可以通过扩展单机内部不同的N-Trees拓扑结构组合,实现了拓扑调优并发挥多通道性能。
例如,在通信数据量超过128 MB的场景下,NVLink互连拓扑优化方案相比NCCL原生在性能上提升了20%以上。
多机优化
多机优化体现在通信算子编译优化、TCP多流优化、多机CPU-Reduce优化三个方面,具体说明如下:
-
通信算子编译优化:针对阿里云上不同机型,以及网卡与GPU的不同拓扑连接等特点,相比较基于全局拓扑结构实现的Allreduce、Allgather或Reduce-scatter等算法,Hybrid+算法支持单机和多机的分层通信,充分利用单机内部高速带宽的同时降低了多机之间的通信量,通信算子编译优化方案相比NCCL原生在性能上提升了50%以上。
-
通信多流优化:通常情况下,因网络带宽没有被充分利用,会导致上层集合通信算法的跨机性能无法达到最优。而采用基于TCP/IP的多流功能,提升分布式训练的并发通信能力,可以实现多机训练性能提升5%~20%。
-
多机CPU-Reduce:该优化继承了单机内CPU-Reduce高效的异步流水线,并将跨机Socket通信也设计为流水线形态,实现多机通信全过程流水化,有效减少通信延迟,提高整体训练性能。
例如,在通信量较大的Transformer-based模型的多机训练场景下,多机CPU-Reduce优化方案可将端到端性能提升20%以上。
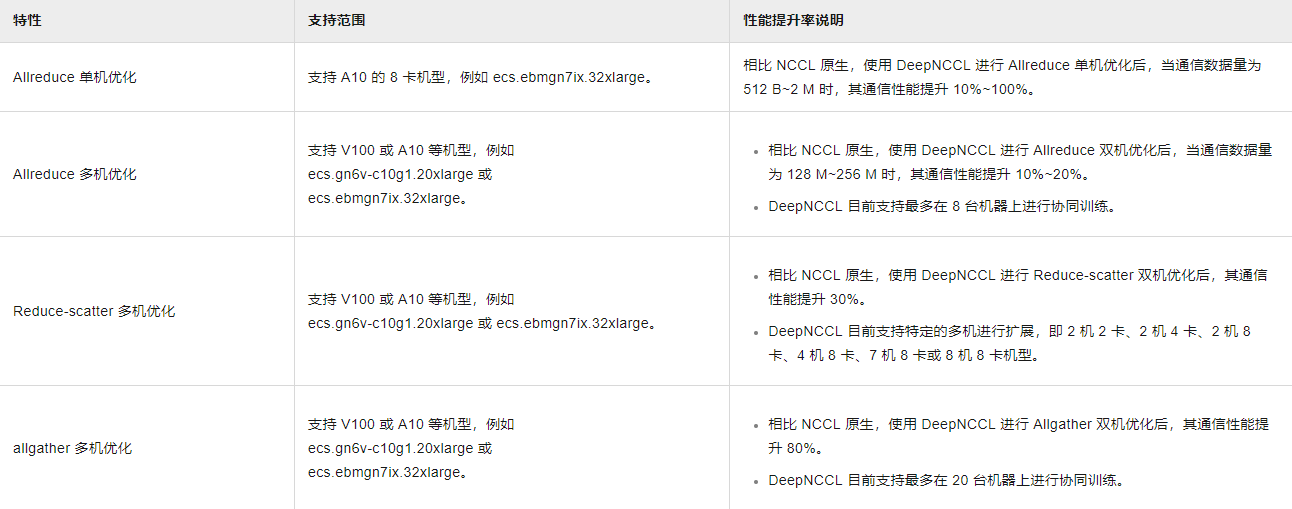
性能说明
DeepNCCL通信加速库具有Allreduce单机优化、Allreduce多机优化、Reduce-scatter多机优化以及Allgather多机优化性能,具体说明如下:
相关文档
针对分布式训练或者多卡推理中的AI通信场景,在不同的GPU云服务器上安装DeepNCCL通信库,可以加速分布式训练或推理性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)