强化学习---随便看看,
这是一个递归关系,当执行动作a之后,会以概率p(s'|s,a)到达不同的下一个状态s 在这个过程中,会得到即时奖励,在s'中继续采取最优动作。贝尔曼公式:价值函数的递推关系,当前状态的价值=即时奖励+未来状态的折扣价值(今天持仓的价值=今天的收益+明天持仓价值*折扣系数)策略函数:智能体的行动指南,定义在某个状态下选择不同动作的概率(比如在股价上涨5%的状态下,60%的概率卖出,40%的概率持仓)
强化学习系统主要包括环境、智能体、规则三大核心,涉及的概念:
观测:智能体从环境中获取的信息
状态:环境或智能体所处的具体情形
动作\决策:智能体在特定状态下采取的行为
奖励:环境对智能体动作的反馈(衡量动作好坏的指标)
状态转移:agent在状态s下采取动作a后转移到状态s'的概率
策略:指导agent选择动作的概率分布Π
轨迹与折扣返回:返回是轨迹中奖励的累加,折扣返回引入折扣率避免无限轨迹发散,控制agent的短期或长期视野
马尔可夫决策过程(MDP)强化学习的数学框架,包含状态空间、动作空间、奖励集合、状态转移概率、奖励概率和策略,具备马尔可夫性质
智能体通过试错迭代寻找最优策略,智能体执行动作,依据环境反馈的奖励判断动作效果;如果动作带来最大回报,智能体将重复该动作,如果效果不佳,调整动作继续尝试;上述试错过程持续进行,直到智能体找到能稳定获得最优奖励的策略
然后我们继续看其他的相关概念:
策略函数:智能体的行动指南,定义在某个状态下选择不同动作的概率(比如在股价上涨5%的状态下,60%的概率卖出,40%的概率持仓)
价值函数:智能体的收益评估工具,分为两种:
一个是状态价值函数(v(s)):评估处于状态s时,未来能获得的期望总奖励
一个是动作价值函数q(s,q):评估在状态s下做动作a,未来能获得的期望总奖励
贝尔曼公式:价值函数的递推关系,当前状态的价值=即时奖励+未来状态的折扣价值(今天持仓的价值=今天的收益+明天持仓价值*折扣系数)
贝尔曼最优公式:寻找最优价值的递推关系--当前状态的最优价值=选择“能带来最大即时奖励+未来折扣价值的动作(比如:今天最优选择是卖出,因为卖出的即时收益+未来价值比持仓更高)
基于贝尔曼公式可衍生出动态规划,在强化学习领域中的核心应用包括价值迭代和策略迭代两种算法
动态规划本质是一种算法设计与优化思想,而非具体的编程实现流程。
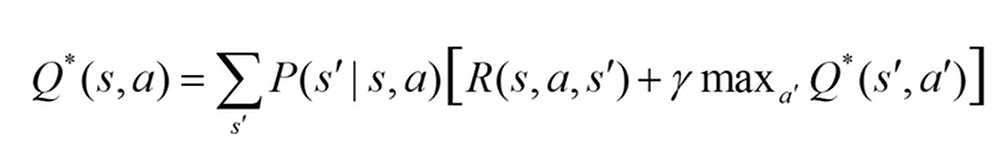
贝尔曼方程。状态s在执行动作a之后转移为状态s'的概率。环境不确定,需要加权求和。R表示在状态s通过执行a转移到s'之后可以立刻获得的回报。伽马表示的是一个折扣,位于0-1.
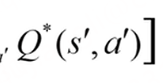 下一个状态的最大价值函数。也就是在到达s'之后,看所有执行的动作a',找到可以使用Q*最大的
下一个状态的最大价值函数。也就是在到达s'之后,看所有执行的动作a',找到可以使用Q*最大的
求期望=加权求和

当前能获得的即时奖励+未来所有可能的新状态能获得的最大折扣奖励
如果我处在状态s,并执行动作a,那么我能获得的未来的最大的奖励是什么?
是当前执行这个动作获得的即时奖励+到达s’之后,s'执行动作a'可以获得的最大奖励的 根据概率和折扣因子计算
分析这个公式中什么是已知量?什么是未知量
已知量就是动作a,即时奖励函数、折扣因子
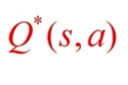 是真正的折扣因子,如果有|s|个状态,|A|个动作,那么有|s|*|A|个未知的
是真正的折扣因子,如果有|s|个状态,|A|个动作,那么有|s|*|A|个未知的
这是一个递归关系,当执行动作a之后,会以概率p(s'|s,a)到达不同的下一个状态s 在这个过程中,会得到即时奖励,在s'中继续采取最优动作。这是一个大的非线性方程组,解出它,就能得到最优Q函数,这样就知道在任何状态下每个动作的最优价值
现在假设状态空间中有两个状态、两个动作,现在一共有4个状态组合
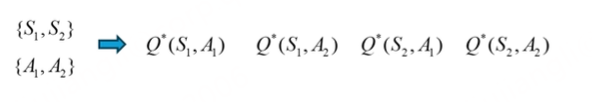
当前 奖励 做完这个动作到其他状态 状态转移函数和奖励函数

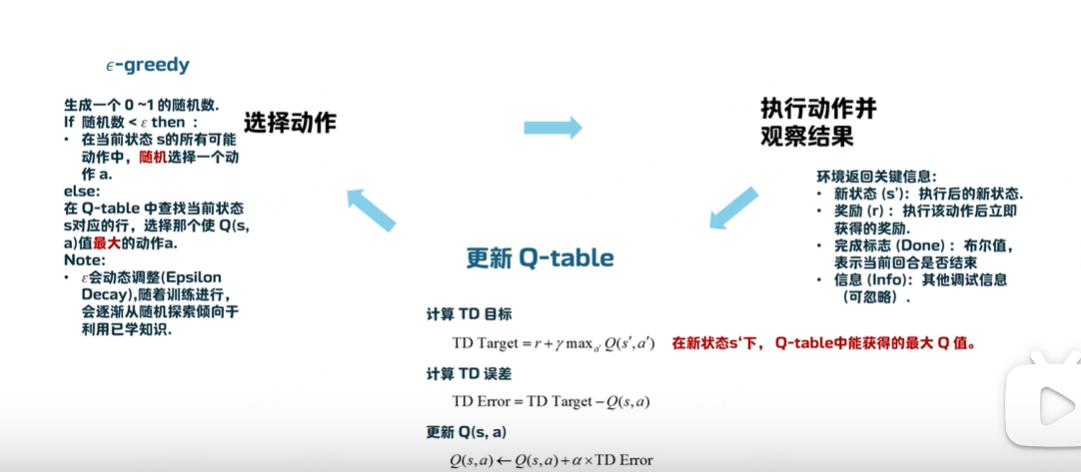
使用Q-learning来近似求解,不需要知道转移到另外一个状态的概率,也不需要知道奖励函数。而是在环境中实际探索、采样来学习
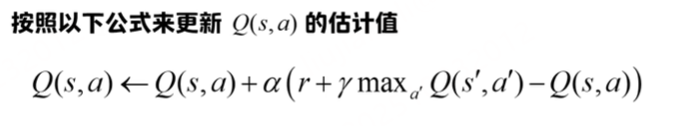
不计算期望,而是用实际观测到的样本来代替期望

阿尔法的作用,非常平滑的更新,学习率,在这里控制学习的步长

算法流程,首先是初始化,创建一个Q-table
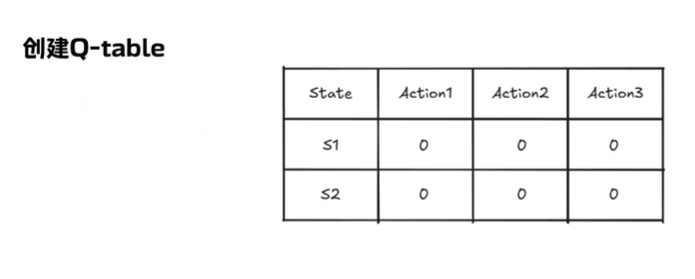
然后设置超参数:学习率,折扣因子,探索率(可选,用于依附斯洛greedy策略) 训练回合数:指定智能体在环境中训练的总回合数



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)